当前位置:网站首页>Data visualization platform based on template configuration
Data visualization platform based on template configuration
2022-07-05 09:45:00 【Baidu geek said】

Reading guide : In the era of big data intelligence , The value of data analysis is becoming more and more important , And the demand for the ability of data analysis visualization platform is getting higher and higher . This paper starts from the data visualization platform of Baidu data center , The application value of the configurable data visualization platform is introduced , The overall processing architecture of the data visualization platform is disassembled . Based on configurable data visualization platform , It can efficiently support complex data analysis scenarios , Improve analysis efficiency , Strengthen the value of data .
The full text 6999 word , Estimated reading time 13 minute .
One 、 Background and objectives
1.1 Background analysis
In the age of data intelligence ,BI(Business Intelligence, business intelligence ) It has become the basic capability of modern data operation . Support the business with data , On the one hand, we need to build a comprehensive system related to business based on data warehouse 、 authority 、 Stable basic data , On the other hand, we also need to establish the ability of data analysis , Display the data through charts , So as to improve the information density of data display , And then supplemented by various ways of comparison , Make data business 、 Sublimate the meaning of data , Enabling business growth .
Therefore, the construction of a data visualization platform becomes particularly important , However, due to the differences between complex businesses, the design and development process of the platform is difficult and complex . Considering the crowd 、 Business analysis habits and different business analysis methods , The data visualization platform is used for report presentation 、 Calculation of data 、 Data release efficiency and other aspects are facing major challenges .
1.2 Problems and goals
Take a typical case of advertising commercialization as an example , Customers choose different forms of advertising commercial products based on the purpose of delivery ( Such as Weibo hot search list , Baidu's search is at the top , Interest recommendation of various video websites, etc ), What forms can promote customers to better reach users ; Customer supplied styles ( Video frequency 、 picture 、 Content and other material characteristics ) What kind of deviation does the user browsing the content have , All need data to support analysis . Combined with analysts 、 Kanban users' habits and many analysis scenarios will cause the following problems when building a data visualization platform to generate data reports :
1. The independent development of long-term statements leads to repeated capacity building 、 Redevelopment ;
2. Each report is developed independently so that users need to get used to a variety of styles 、 Experience differences caused by style ;
3. Adjust when business changes 、 The matching cost is large , As a result, the business cannot be effectively enabled for a period of time ;
4. The time to build data reports caused by insufficient computing power of the platform 、 The labor cost is high ;
5. It is difficult to guarantee the stability of the platform , To be tested 、 Check the emerging exceptions .
In order to meet users' report requirements , Even if a large amount of manpower is invested, it can only solve the problems caused by the above development costs . Systematic creation BI The data between , It needs to go deep into all aspects of data expression , Combined with the characteristics of the business , modularization 、 Componentized capabilities , This can reduce the cost of repeated development , It can also improve code reuse 、 Extensibility 、 Report management and fault tolerance , Ensure user experience and business adaptability .
therefore , An excellent data visualization platform should meet the following requirements :
1. agile : Be able to respond quickly to requirements ;
2. accuracy : It can ensure the accuracy of platform data , Achieve 「 What you see is what you get , All the gains are used 」;
3. multivariate : For different business attributes 、 User features , For example, comparative calculation 、 Query and other methods can be combined through modules 、 Display type adjustment and other methods to meet the needs ;
4. flexible : For business expansion or change , The platform can change flexibly to be close to the business structure ;
5. Simple and easy to use : Whether the user is reading 、 Writing data , Can quickly meet ; Support business processes to 「 To configure 」 replace 「 Development 」;
6. Easy to expand : Covering most business analysis scenarios , At the same time, it supports the front and back end code of configuration based secondary development , extensible .
1.3 A term is used to explain
1. Derivatives :
Based on basic indicators , The index calculated twice by the formula , Common examples are recent 10 Average number of users per day , Or the day on month ratio calculated by comparing the number of users of the day with the number of users of yesterday .
2. Run in :
Generally, it means that the business needs to be split 、 Refine to mine or locate business pain points , There is a certain correlation between businesses , Layer by layer disassembly through correlation is called tripping during analysis . Tree structure is often used to express similar hierarchical relationships in visual scenes .
3. Scroll up :
In the visualization scenario, multiple business data constitute a total , Through the system, the correlation between businesses is used for total calculation .
4. Dimensional analysis :
Common baseline comparison methods , Based on one or more businesses , Analyze the current business situation through numerical comparison .
5. Time comparison analysis :
After segmenting the time , Compare the current time period with the history ( Or baseline ) Numerical changes between time periods , So as to judge the business status .
Two 、 Overall design and thinking
2.1 Demand analysis and conception
2.1.1 Scene analysis
A complete closed loop of data analysis starts from analyzing requirements , Including data acquisition 、 Data cleaning 、 Data modeling 、 Data presentation 、 Data applications 、 Conclusion output , Use the conclusion of output to implement or improve the business . We can see two roles in the whole process :
1. Builder :
When analyzing a proposition or business scenario , First, find data support based on business , Data collection is required during this process 、 Organize data into expressions with business implications 、 Extract the content with business relevance to form a collection with analytical significance , It's more intuitive 、 Display the data in an image way . Secondly, in order to fully express the business , In the process, some data need to be combined to build derivative indicators or establish the relationship between dimensions . When this is done , A complete business scenario will be digitized 、 Show it in a graphic way .
2. Analyst :
Business specific , Start splitting problems through data , With a APP For example, the revenue of a commercial scenario is declining , Analysts need to learn from APP The number of users starts to funnel layer by layer to see which links have a greater impact , You also need to drill down from various dimensions to locate the business root node , It is also possible to use analogical analysis 、 Baseline comparison is used to horizontally compare the differences of impacts in similar scenarios .
Facing the same business problems , Data users from different directions may also have different behaviors , Trends in business understanding , The data level of analysis will also be different . Of course , Users can also play both roles , In essence, the simple and easy-to-use platform is more convenient for analytical users to independently complete the closed loop from data construction to analysis , So as to reduce and release manpower , Solve business problems faster . When the current data cannot meet the business analysis , The analyst will enter the constructive scenario again , Continue to look for data arguments needed to quantify support .
2.1.2 Business abstraction and thinking
Complete data support for various business scenarios , Technology is needed to create conditions for it , If the builder ultimately serves the analyst , Report results oriented , Can the builder fully express the data needs of the analyst in the construction process ? These statements build capacity to be transferred or disassembled into procedures 、 What is a modular language ? What needs to be done by the platform and the builder itself 、 What kind of functions are implemented ? meanwhile , How can the platform ensure the accuracy for analysts 、 Efficient 、 Comprehensive data ? Next, we disassemble the data through the visual process 、 The abstract answers the above questions one by one .
2.2 Architecture design
2.2.1 Procedural abstraction
We disassemble the whole process of using data by analysts , And then abstract it 、 Componentization . The analyst enters query criteria through the platform 、 indicators 、 Dimensions and so on , The server performs data processing according to the platform input sql Assemble and query the database , Then calculate the relevant derivative indicators and integrate the calculation results , Finally, the results are presented in the corresponding style . The whole logic process is disassembled as shown in the figure 1 Shown .

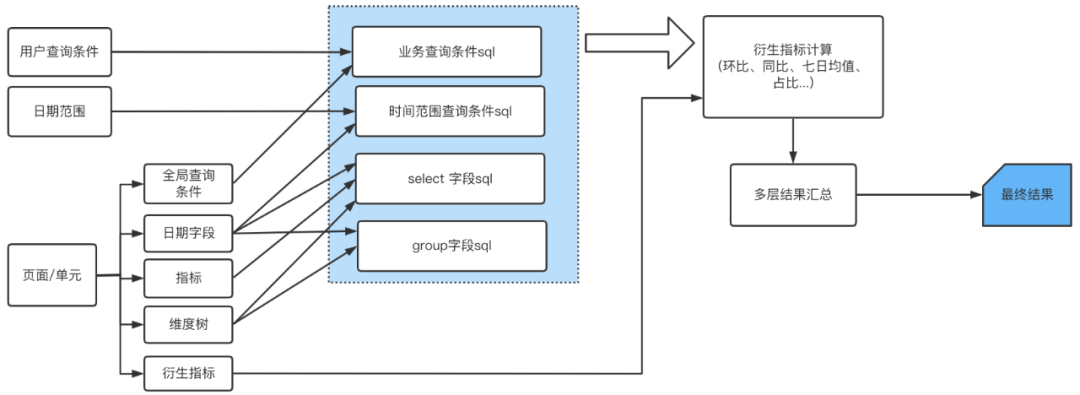
△ chart 1 Process abstract logic
2.2.2 The overall architecture
According to the process abstraction of data visualization , A complete visualization platform needs to include data acquisition 、 Data calculation 、 Data presentation, etc . How to obtain data 、 How to display requires unified configuration management , How fast data 、 Accurate calculations are the responsibility of the general computing service . At the same time, the visualization platform also needs to ensure the quality of data , In case of data problems or delays, the builder can be notified in time to deal with the data problems , These are the responsibility of the operation and maintenance kanban . We abstract the data visualization process and summarize the experience of this kind of platform , Disassemble the data visualization platform architecture into the following figure 2 Shown .
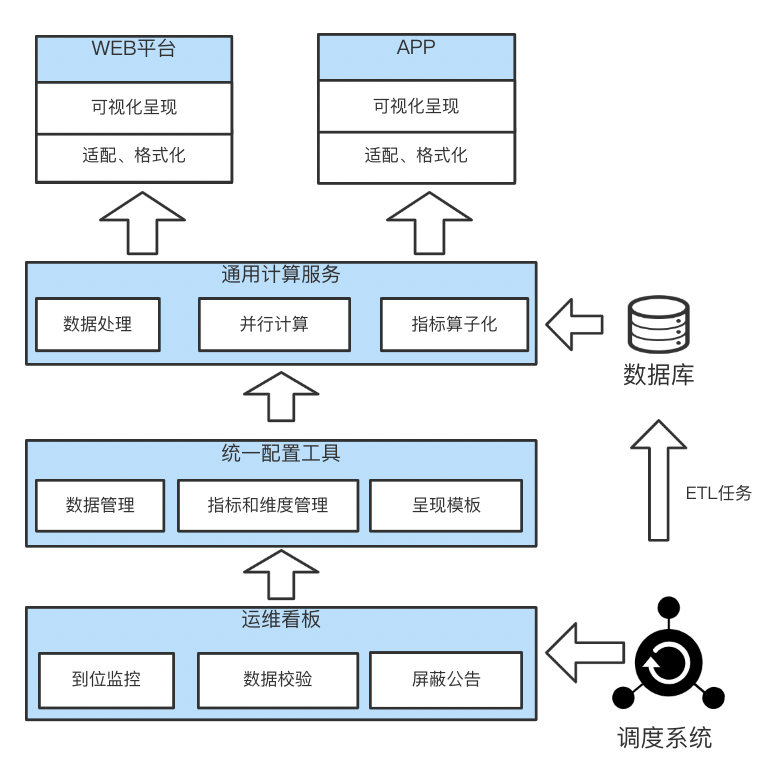
△ chart 2 Overall architecture
3、 ... and 、 Core module introduction
3.1 Configure tools and report rendering
Before configuration , Building a report requires back-end developers to develop computing logic based on the database 、 analysis 、 Download and other functions , Front end developers render data in the form of charts , Code redundancy 、 High development cost 、 Cycle is long . Unified configuration tool is a bridge between database and report presentation , On the basis of being familiar with the data logic, the data builder carries out the data source through the configuration interface of the configuration tool 、 Calculation logic 、 Present content 、 Configuration of style and other related information , And then release it online , The report presentation module of each data visualization platform renders corresponding components according to the configured style and content , Users can view reports on the corresponding platform 、 Analyze or download data .
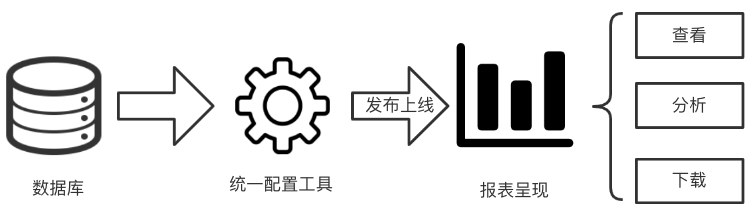
△ chart 3 Configuration flow diagram
3.1.1 Unified configuration tool
In order to reduce the complexity of configuration tools 、 Reduce user learning costs , Improve configuration efficiency , Design fixed presentation templates for analysis scenarios with relatively stable business and data requirements , The user selects the appropriate template to configure the corresponding content , And the configuration template is extensible , Flexible addition and deletion of functional modules .
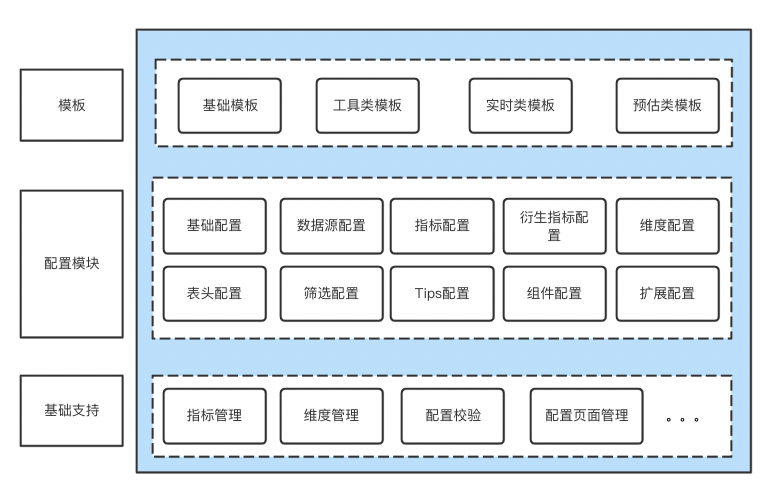
△ chart 4 The unified configuration tool consists of
The configuration tool page displays the corresponding configuration content according to the template selected by the user , In addition to configuring data sources 、 indicators 、 Dimension and other data related information , You also need to configure the filter control 、 Analyze components, etc . At the same time, the configuration tool also supports adding functions that are not supported by the current template through extended configuration , So as to carry out secondary development based on the template . A complete configuration tool in addition to the basic configuration , Index management is also added 、 Dimension management 、 Configuration verification and other functions improve configuration efficiency and basic support for user experience .
1. Index management : Put the index 、 The information of derived indicators shall be managed uniformly , The default values of each parameter are provided according to the attribute characteristics of the indicator , The configurator can directly use the default configuration information of the indicator management module when configuring the page , The indicator can be configured once and used many times . This not only improves the efficiency of configuring personnel , Providing default values for indicator parameters is also conducive to standardizing and unifying the platform style ;
2. Dimension management : According to the data source configuration information , Generate dimension template information , The configurator simply needs to adjust the dimension display name and order , Convenient and efficient ;
3. Configuration verification : Verify user configured sql Whether it is right , Quickly locate the wrong configuration .
3.1.2 Report presentation
The data visualization platform provides users with rich chart components ( form 、 Trend chart 、 The pie chart 、 card 、 Maps, etc ) And filter conditions ( The radio 、 multi-select 、 date 、 Input box and so on ), The rich chart styles fully meet the complex visualization requirements .
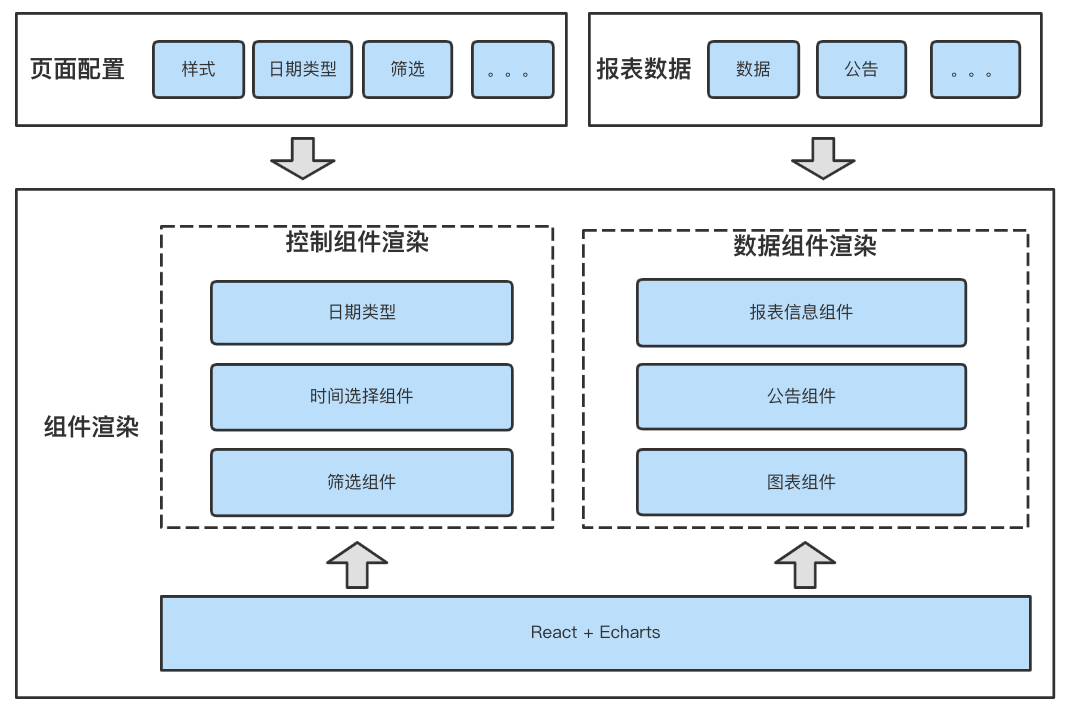
△ chart 5 The schema of report presentation
The main work of report rendering is to render the formatted data in the browser in the form of charts , For users to query 、 Analyze the data . The basic component units of report presentation are divided into two categories :
1. Control components : Components configured in the configuration tool , For example, filter conditions 、 Date type, etc , This type of component renders the content of the component while rendering the component ;
2. Data components : Specific data to be rendered , Like tables 、 Data in line chart , This part of the data is provided by the general computing module . Such components are rendered after the component , Retrieve specific data information ( Different sources of data ) Content rendering .
To meet complex analysis scenarios , When a report is rendered, multiple styles are often used together . Consider the reusability of code when designing 、 Commonality and extensibility disassemble the diagram into the smallest unit that can be reused , Packaged into components . The final composition, arrangement and presentation of each component is managed by the builder in the configuration tool according to the required analysis scenarios .
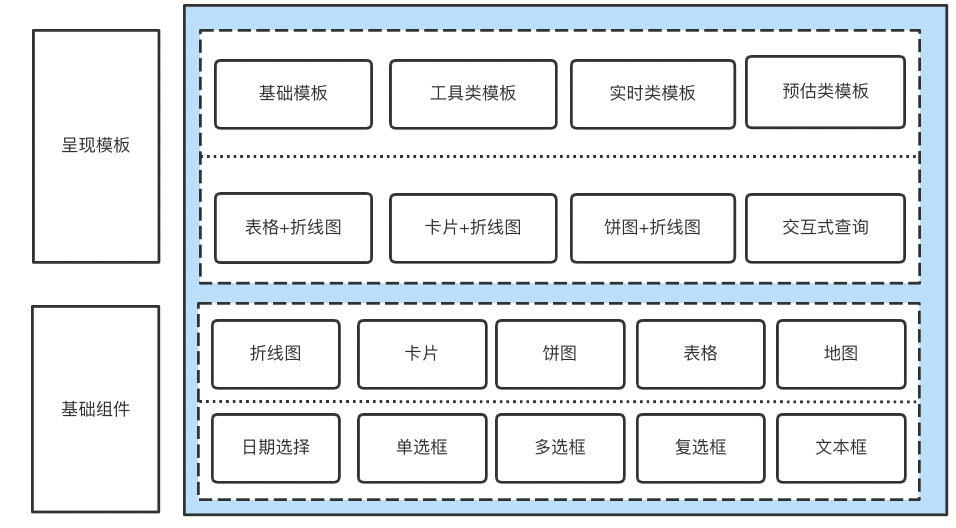
△ chart 6 Composition of report presentation
For analysis scenarios with relatively stable business and data requirements, report presentation is designed and implemented 14 A rendering template , Support interactive query 、TOP Sort 、 Configuration of real-time data and other business scenarios . For more complex business scenarios, basic components can be reused 、 The development of online .
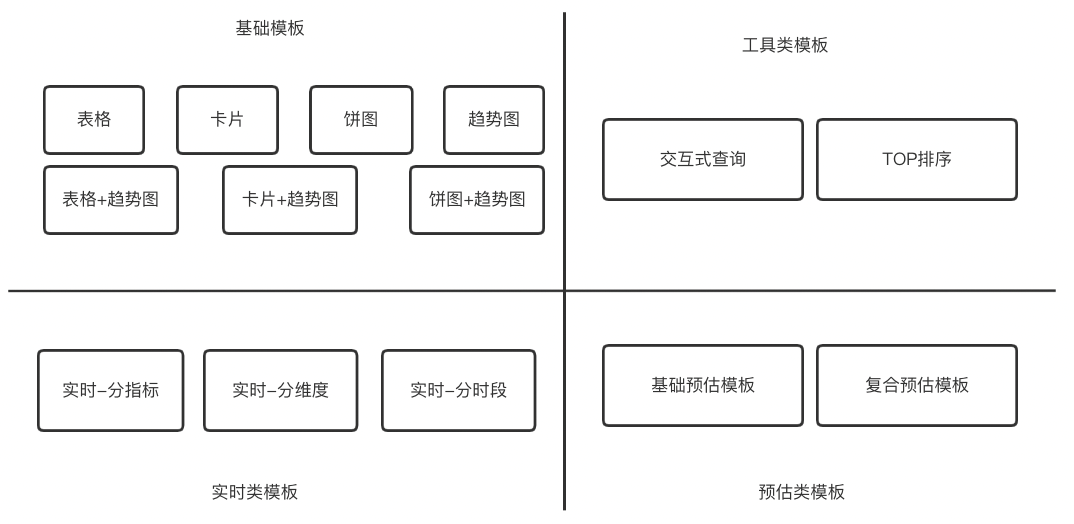
△ chart 7 The configuration template
3.2 General computing services
The previous section introduced the configuration tool for calculation and report presentation , The data of the report presentation chart comes from the calculation service . Computing service is the brain of the whole data visualization platform , It is mainly responsible for processing the original data in the database according to different calculation rules and generating the data form required by users for display . Different users analyze the dimensions of data 、 visual angle 、 The scene is different , for example : stay Top scenario , Analyze key dimensions ( Such as customers 、 Products, etc. ) Data trends ; Some need to monitor the fluctuation of fixed indicators , According to different screening conditions , Cross analyze the causes of the change 、 Predict the future development direction ; Some require long-term data to analyze the change law of indicators over time ; For key businesses, you need to view data changes in real time . In addition to covering the known and complex business scenarios , We also need to consider the continuous expansion of business and the deep excavation of data , Quickly follow up the business development , Therefore, the commonality and extensibility should be fully considered in the design of computing service architecture .
3.2.1 Architecture implementation
Complexity of integrated business scenarios 、 Code reusability 、 Service commonality and scalability , We have done a layered design for the general computing service architecture , Each floor performs its own duties , Standardize the overall code structure 、 The logic is clear and easy to read and can quickly support the expansion of new indicator calculation .
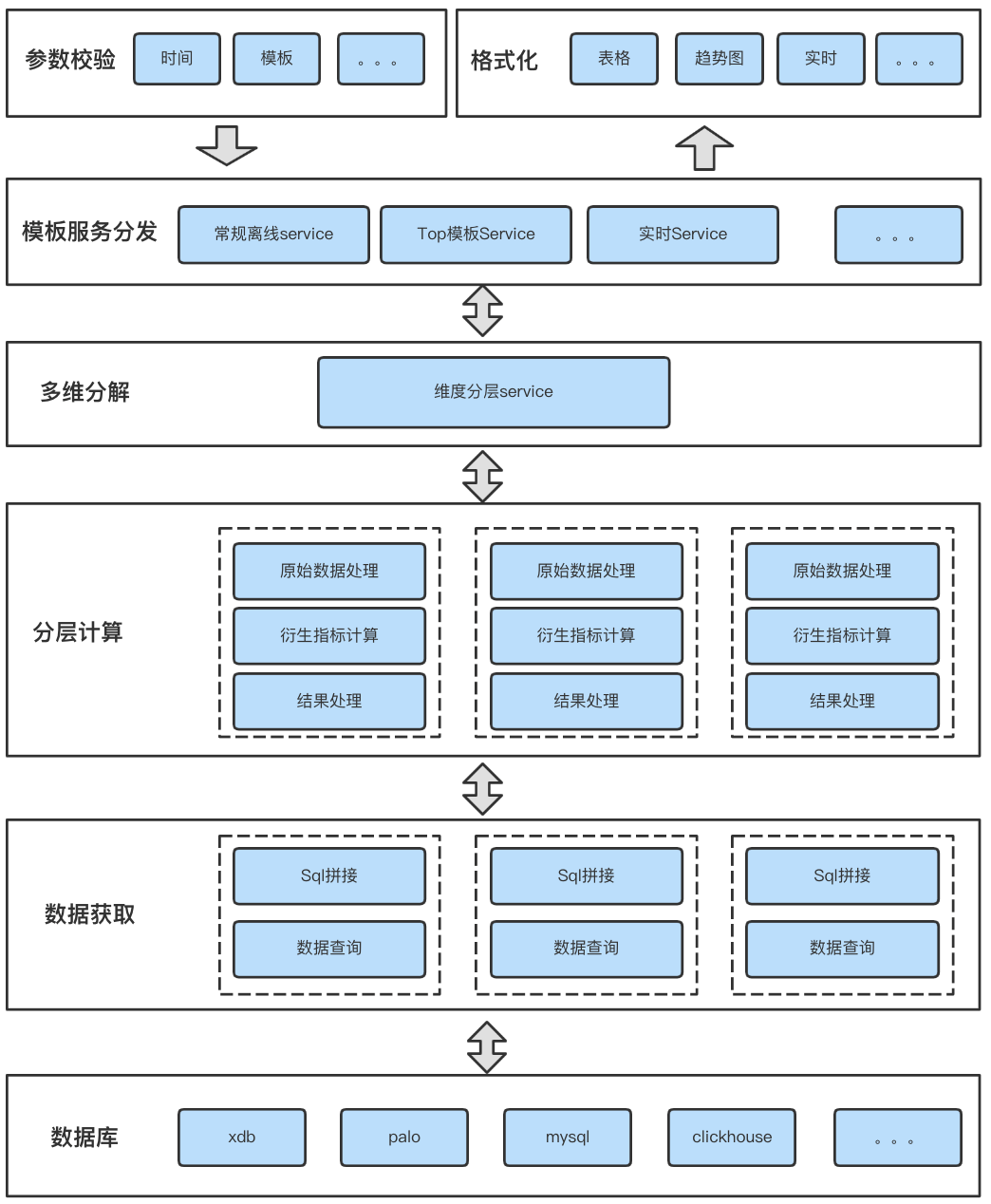
△ chart 8 Calculate the overall service architecture
1. Parameter verification layer
Data requests for different business scenarios , Computing services require different parameters , We separate the parameter verification part , Abstract out the common parameter verification logic , Independently verify the unique parameters of each template .
2. Template service distribution layer
To meet different business scenarios and data presentation needs , We set up the template service distribution layer , Classify according to business scenarios , Abstract multiple service classes to serve different data scenarios . The distribution layer prepares data sources for subsequent calculations according to the information configured by the user in the configuration tool 、 indicators 、 Dimension and other information are then distributed to specific service classes along with the calculation request .
3. Multidimensional decomposition layer
To support data rollup 、 The relationship between the data analysis dimensions of the drill down , We designed a multidimensional decomposition layer , According to the hierarchy of data, multiple parallel computing processes are decomposed . Multithreaded parallel computing makes different levels of computing do not interfere with each other 、 Efficient computing .
4. Data acquisition layer
In order to support multiple types of databases and facilitate the subsequent addition of other types of databases , We abstract the data acquisition layer , Shield the upper layer data acquisition logic 、 Provide a unified interface . The underlying database can support mysql、palo、xdb etc. , It's also convenient 、 Fast expansion to support new database types .
5. Layered computing layer
Multiple calculation processes disassembled from multidimensional decomposition layer , Each calculation process is an independent module , Based on the original data provided by the data acquisition layer, the cycle synchronization is calculated in parallel 、 Sun ring 、 Seven day mean and other derived indicators , Meet the analyst's multi angle analysis of the scene . Derived indicators are calculated separately 、 They don't influence each other , Easy to expand without affecting the computational efficiency . Finally, according to the delay Kanban ( This section will be described in detail later ) The data provided is delayed 、 Block information , Shield the calculation results , Prevent the platform from presenting abnormal data .
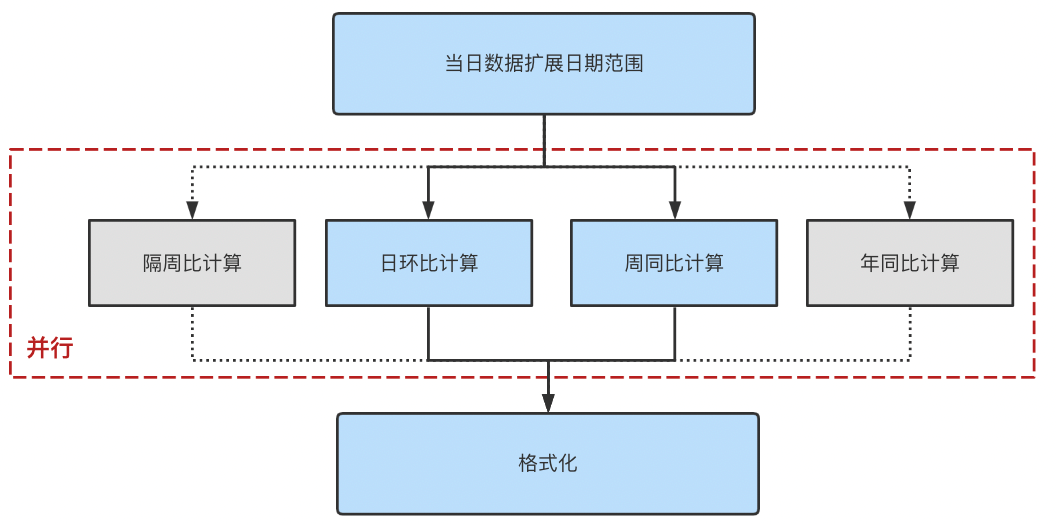
△ chart 9 Hierarchical operation layer
6. Format layer
The formatting layer is mainly responsible for formatting according to different rendering components , Put the data processing operation on the server , The front end is used immediately to reduce the performance consumption of the front end , Improve front-end data rendering and rendering efficiency . meanwhile , The formatting layer masks the underlying computing logic , It enables the general computing service to quickly access the new report presentation platform , Provide them with computing power .
3.3 Operation and maintenance Kanban
The core of data visualization platform is data , A large number of data streams are maintained at the bottom of the platform , These data come from different upstream , The original data is extracted through multiple layers 、 machining 、 Summary , Generate the final front-end table . Various problems may arise during the whole process , For example, multiple data sources are in place one after another, resulting in incomplete display of page data , Upstream data is abnormal 、 Exceptions occurred during data cleaning . In order to ensure the accuracy of the data , In the general computing service section, it is mentioned that abnormal data needs to be shielded , The shielding information comes from the operation and maintenance kanban .
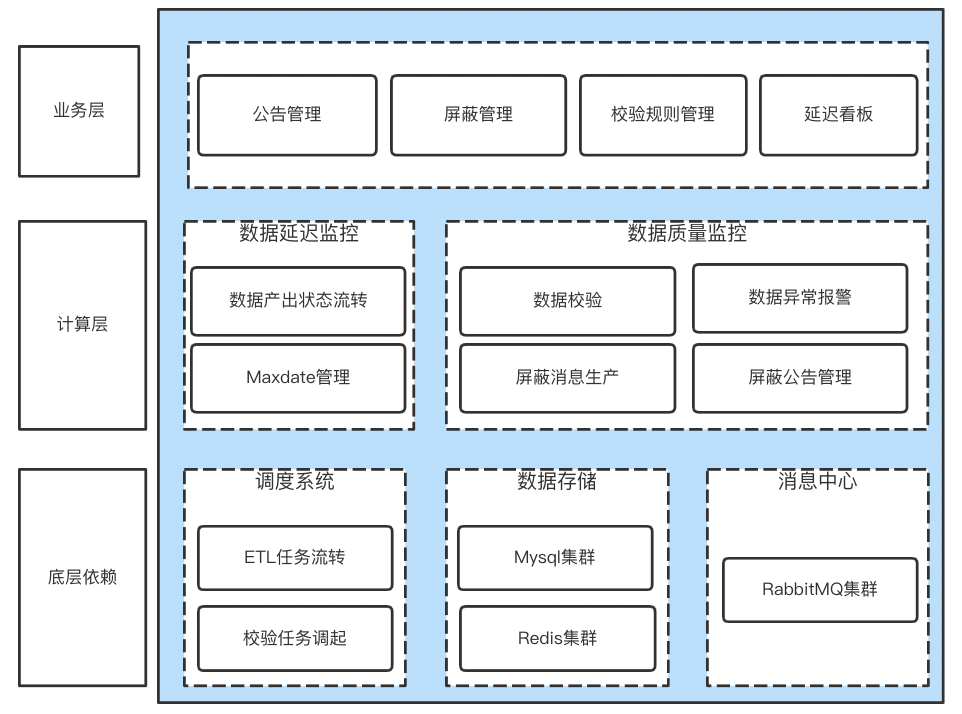
△ chart 10 The operation and maintenance Kanban consists of
Operation and maintenance Kanban monitoring data availability 、 Verify data accuracy , Ensure the normal output of data , Ensure the accuracy and authority of the data on the entire platform . Its core function is data delay monitoring 、 Data quality verification 、 Platform announcement management . The overall workflow is as follows :
1. The dispatching system is responsible for all ETL Task activation and status flow , stay ETL When the task is finished , Notify Kanban data output through message queue ;
2. Kanban calls up the data verification service to perform the verification task , And send the results back to the kanban ;
3. Kanban updates report data output status , Verify whether the data fluctuation exceeds the threshold according to the verification rules , Then put the data in place 、 The verification results are distributed to the corresponding report platform through the message queue ;
4. According to the received messages, each report platform , Recalculate data update data cache .
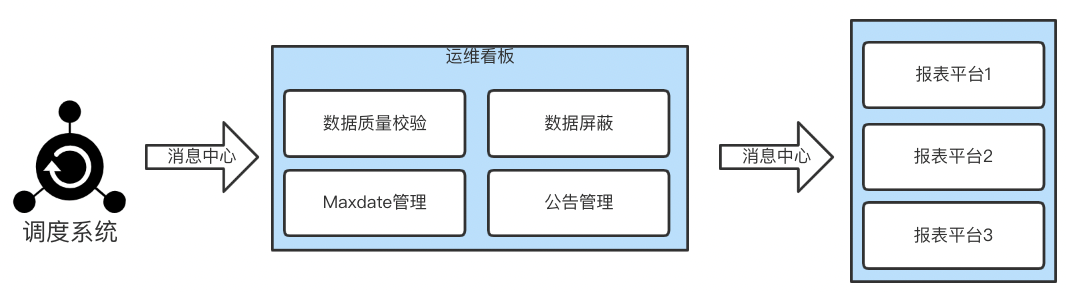
△ chart 11 Operation and maintenance Kanban workflow based on the message center
3.3.1 Data delay monitoring
In order to ensure that routine data tasks are performed in SLA Produce in time , The delay monitoring module is based on the ETL Mission 、SLA Time information monitors the availability of data 、 Call the police . When the data is in place, the delay monitoring module will distribute the message to each platform at the first time , Ensure that the data cache is updated in time . For reports with multiple data sources , Delay monitoring supports the presentation rules of all or part of the configuration data , Kanban performs data screening management based on configuration rules and generates corresponding announcements to prompt the user data availability of the report platform . If the data is in SLA If there is no output within the time, the person in charge of the report will be notified to follow up the data operation status in time .
To facilitate the monitoring of report output , Kanban also provides an interface for data output monitoring , The report owner can view through the interface 、 Statistical data output 、ETL Task status, etc .

△ chart 12 Data output monitoring interface
3.3.2 Data quality verification
To ensure the accuracy and authority of the data , After the data is in place, the operation and maintenance Kanban will verify the quality of the data before the platform data is presented , Generate shielding information according to the verification rules , It is distributed to each report platform through message queue . When the verified data is abnormal, send a message 、 Telephone 、 Inform the person in charge of the report by email and other alarm methods , Remind to follow up abnormal data conditions .
At present, three types of data verification rules are designed and implemented :
1. Front end table verification : Support the same month on month comparison 、 Size threshold and other verification rules , Verify the front-end table data after they are in place .
2. Data source verification : Support the same month on month comparison 、 Size threshold and other verification rules , After the data is pulled from the upstream, the verification rules are executed .
3. Custom script extension , Support user-defined verification rules , Provide openapi Interface mask data .
3.3.3 Shielding and announcement management
In addition to data delay monitoring and data quality verification, data can be shielded , The operation and maintenance Kanban also provides the function of directly shielding data , Avoid presenting abnormal data to users caused by other problems . When the data fluctuates greatly due to abnormal data or special events , The announcement management module goes online to inform users of the reason for data fluctuation .
Four 、 summary
The data visualization platform based on template configuration consists of a unified configuration tool 、 General computing services 、 Report presentation 、 The operation and maintenance Kanban is composed of several parts . The unified configuration tool is responsible for managing how reports get data 、 What chart styles are used to render the report ; General computing services provide derived metrics ( Sun ring 、 Zhou Tong 、 Seven day average 、QTD、MTD wait ), comparative analysis , Data roll up 、 Calculation ability such as running in the hole ; The O & M Kanban provides delay monitoring 、 Quality verification 、 Shielding management and other functions ensure the accuracy of data 、 timeliness ; Report rendering provides rich chart components ( form 、 Trend chart 、 The pie chart 、 Maps, etc ) And filter conditions ( The radio 、 multi-select 、 date 、 Input box and so on ) Meet complex visualization requirements . A variety of configuration templates fit the business requirements , Replace the development of rapid response requirements with configuration , At the same time, the extensible architecture can flexibly follow up business changes or expansion . Simply put, our platform :
1. Compared with self-help BI, More powerful auxiliary functions 、 Data quality is guaranteed
With the powerful ability of componentization , We are keeping the page high degree of freedom 、 While flexibly supporting the business , It has also built a variety of auxiliary comparison capabilities to help analysts complete the analysis . Through a complete report page , Be able to have systematic analysis ideas , You can also gain multiple self-help abilities , Enhanced understanding of the business . Secondly, it reduces the user's confidence in the data , Pre manage abnormal data , Monitoring by data delay 、 Data quality verification 、 shielding 、 Announcements and a series of other means to ensure the accuracy of data , Avoid analysts' doubts about data quality , Achieve 「 What you see is what you get , All the gains are used 」.
2. Compared with tradition BI, Faster 、 Efficient
As mentioned above , The biggest drawback of customized development is that it takes a long time to develop 、 The high cost , Affect data output and analysis . We will compute power 、 Demonstrate Componentization of capabilities 、 Configuration change , Rich calculation ability of derivative indicators 、 Render components as close as possible to the customized platform capabilities . Even for new business scenarios that the platform does not support, these highly available development components can participate in the construction of their analysis scenarios . The data visualization platform based on template configuration can quickly respond to business requirements 、 Support analysis business capability 、 Empowering business .
Recommended reading
How to correctly evaluate the video quality
Small program startup performance optimization practice
How do we get through low code “⽆⼈ District ” Of :amis The key design of love speed
Mobile heterogeneous computing technology -GPU OpenCL Programming ( The basic chapter )
Cloud native enablement development test
be based on Saga Implementation of distributed transaction scheduling
边栏推荐
- Tutorial on building a framework for middle office business system
- 初识结构体
- How to improve the operation efficiency of intra city distribution
- Tdengine connector goes online Google Data Studio app store
- Node の MongoDB Driver
- Principle and performance analysis of lepton lossless compression
- Viewpager pageradapter notifydatasetchanged invalid problem
- Figure neural network + comparative learning, where to go next?
- OpenGL - Model Loading
- [ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)
猜你喜欢


![[sourcetree configure SSH and use]](/img/9a/1cd4ca29e5b7a3016ed6d5dc1abbef.png)
随机推荐
Why don't you recommend using products like mongodb to replace time series databases?
Figure neural network + comparative learning, where to go next?
Community group buying exploded overnight. How should this new model of e-commerce operate?
Three-level distribution is becoming more and more popular. How should businesses choose the appropriate three-level distribution system?
Using request headers to develop multi terminal applications
OpenGL - Lighting
观测云与 TDengine 达成深度合作,优化企业上云体验
[technical live broadcast] how to rewrite tdengine code from 0 to 1 with vscode
[object array A and object array B take out different elements of ID and assign them to the new array]
The most comprehensive promotion strategy: online and offline promotion methods of E-commerce mall
TDengine可通过数据同步工具 DataX读写
A keepalived high availability accident made me learn it again
Vs code problem: the length of long lines can be configured through "editor.maxtokenizationlinelength"
What about wechat mall? 5 tips to clear your mind
[reading notes] Figure comparative learning gnn+cl
An article takes you into the world of cookies, sessions, and tokens
Android 隐私沙盒开发者预览版 3: 隐私安全和个性化体验全都要
LeetCode 31. 下一个排列
移动端异构运算技术-GPU OpenCL编程(进阶篇)
代码语言的魅力