当前位置:网站首页>高性能Spark_transformation性能
高性能Spark_transformation性能
2022-07-05 09:11:00 【sword_csdn】
宽(wide)依赖和窄(narrow)依赖
(1)窄依赖(narrow dependencies)。父RDD的每个分区最多被子RDD的一个分区所引用。
(2)宽依赖(wide dependencies)。父RDD的每个分区被多个子RDD所引用。
例如,考虑以下代码 code_A
val rdd2 = rdd1.map(x=>(x,1))
val rdd3 = rdd2.groupByKey()
从rdd1到rdd3的数据的变化如下图所示: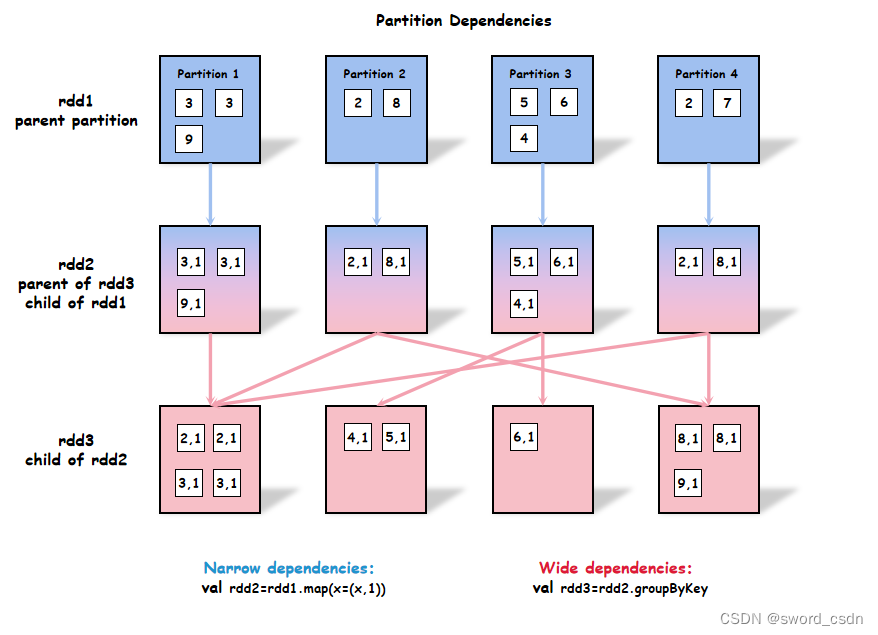
从rdd1到rdd2属于窄依赖(narrow dependencies),因为rdd2中的每个分区数据仅从rdd1中的一个分区中得到。从rdd2到rdd3属于宽依赖(wide dependencies),因为rdd3中可能存在多个分区的数据来自rdd2的多个分区。
narrow转换的过程不存在分区之间的数据移动,也不需要跟driver node通信。当一连串的narrow转换后遇到一个wide转换之后,Spark会将这个wide转换连通它前面的narrow转换都看做是一个stage阶段。而这个它后面的转换会算在下一个stage阶段中。
一个stage中的narrow转换是并行的,而stage与stage之间则是串行的。一个stage中有多少个分区,narrow转换的并行数就有多少,转换在分区内完成。wide转换在实现具体操作前会先实现数据在不同分区之间的传输,这个操作称为shuffle,目的是为了将相关的数据都放在一个分区中以实现分区内数据转换。
(1)“narrow”和“wide”对性能的影响
narrow转换比wide转换运行得更快,因为narrow转换不会出现分区与分区之间的数据传输,并且narrow转换的过程不需要与driver node交互,这一点跟wide转换相反。
(2)“narrow”和“wide”对容错的影响
当spark集群针对分区的计算发生错误时,对于wide转换要恢复这个错误所需要的成本更高。因为wide转换在重新计算分区时可能需要从多个父分区中获取数据。并且容易造成内存泄漏的问题。
(3)使用coalesce的注意事项
coalesce方法一般用于改变rdd的分区数量。当这个方法用于减少分区数量时,每个父分区仅仅有一个子分区与之对应,因为子分区是父分区的集合。所以从这个角度来说,它属于narrow转换。反之,当coalesce方法用于增加分区数量时,每个父分区会有多个子分区与之对应。此时它wide转换。
RDD返回的类型
如果一个tuple类型的RDD丢失了它的schema信息,Spark就会用“Any”来代替,例如:RDD[Any]和RDD[(Any,Int)]。此时当执行某些方法时,编译是无法通过的,例如:sortByKey。sortByKey方法实际上依赖于key的值存在某一些隐性的可排序的可能,例如:字母排序,数字排序等等。此外还有很多数字类型的方法例如:max,min,和sum也需要依赖RDD中的数据是Long,Int或者是double类型。
DataFrame中的Row是弱类型的,从DataFrame转成RDD,有些值的类型会变成“Any”,这是丢失值类型管理信息的表现。所以在这个过程中最好将DataFrame的schema信息用一个变量记录起来。
此外Dataset API是强类型,所以它转换成RDD之后,每一行的值都会保留它的类型信息。
减少对象的创建
“垃圾回收”是为了回收创建对象(object)时所分配的资源。所以如果在Spark作业中创建的对象越多,“垃圾回收”机制造成的成本也越高。所以建议在Spark中减少使用对象,或多点复用对象。
使用mapPartitions
rdd的mapPartitions是map的一个变种,它们都可以进行数据的并行处理。两者有很多的不一样。
首先是并行处理数据的粒度
(1)map的input transformation应用于每一个元素。
(2)mapPartitions的input transformation应用于每个分区。
假设一个rdd有10个元素(1 2 3 4 5 6 7 8 9 10),分成3个分区,测试代码如下所示
val a = sc.parallelize(1 to 10,3)
def handlePerElement(e:Int):Int={
println("element="+e)
}
def handlePerPartition(iter:Iterator[Int]:Iterator[Int]={
println("run in partition")
var res = for(e<-iter) yield e*2
res
}
val b = a.map(handlePerElement).collect
val c = a.mapPartitions(handlePerPartition).collect
运行以上代码测试可以看到,基于元素粒度运行的handlePerElement函数输出了10次,而基于分区粒度运行的handlePerPartition输出了3次。
输入函数获取数据的方式
基于map调用handlePerElement时,实际上是map将数据推到handlePerElement中,而当mapPartitions调用handlePerPartition时,则是handlePerPartition主动拉取数据。
处理大数据集
handlePerElement和handlePerPartition都要初始化一个耗时的资源,然后使用,比如数据库连接。handlePerPartition只需初始化3个资源(每个分区1个),handlePerElement要初始化10次(每个元素1个),而在大数据情况下,数据集中的元素个数远大于分区数,所以mapPartitions的开销要小很多,便于批处理操作。
变量的共享
Spark中有两类共享变量:累加器和广播变量。累加器是用来对信息进行聚合的,而广播变量则是用来高效分发较大对象的。
闭包
假设有一段代码
var n = 1
val func = (i:Int)=>i+n
函数func有两个变量,n 和 i,其中 i 为该函数的形式参数,也就是入参,在func函数被调用时,i 会被赋予一个新的值,称为绑定变量(bound variable),而 n 则是定义在了函数func外面的,该函数并没有赋予其任何值,称为自由变量(free variable)。
像func函数这样,返回结果依赖于声明在函数外部的一个或多个变量,将这些自由变量捕获并构成的封闭函数,称为“闭包”。
假设有个累加求和的例子,代码如下:
var sum = 0
val arr = Array(1,2,3,4,5)
sc.parallelize(arr).foreach(x=>sum+=x)
println(sum)
这段代码并不会达到 sum=15 的效果。而是sum=0。导致这个结果的原因就是存在闭包。
在集群中,Spark其实晖对RDD的操作处理分解为Tasks,每个Task由Executor执行。在执行之前,Spark会计算task的闭包(也就是上面代码中的foreach())。闭包会被序列化发送给每个Executor,但是发送的只是副本。
(至今才理解什么是闭包,就是一个方法即便是沿用了外部的变量,计算起来也只是用了这个变量的拷贝,把门关起来计算)
累加器的原理
累加器可以突破闭包的限制,把工作节点中值的改变更新到Driver中。首先Driver调用SparkContext.accumulator(initialValue)方法,Spark闭包里的执行器代码就会对其+1。也就是把下面的代码
var sum = 0
改成
val sum = sc.accumulator(0)
广播变量的原理
广播变量在原理上跟累加器的原理差不多,区别在于,广播变量并不是要把变量副本发给所有的Task,而只是将其分发给所有的工作节点,然后工作节点中的所有Task共享一份数据副本。
val broadcastVar = sc.broadcast(Array(1,2,3))
broadcastVar.val
RDD的复用
Spark提供了persist,cache,checkpoint三种方式来实现RDD的重用。cache和persist是将数据默认缓存在内存中( rdd.persist(StorageLevel.DISK_ONLY) 可以缓存在磁盘),checkpoint是物理存储。
(1)cache底层调用的是persist。
(2)cache默认持久化等级是内存且不能修改,persist可以修改持久化的等级。
(3)当某一个步骤计算特别耗时时,建议使用cache和checkpoint
(4)当计算的链条特别长时,建议使用cache和checkpoint
一般情况下建议使用cache和persist模式,因为不需要创建存储位置,默认存储在内存中计算速度快,而checkpoint需要手动创建存储位置和手动删。
边栏推荐
- [code practice] [stereo matching series] Classic ad census: (6) multi step parallax optimization
- Array, date, string object method
- Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
- 迁移学习和域自适应
- Kubedm series-00-overview
- 2311. Longest binary subsequence less than or equal to K
- 520 diamond Championship 7-4 7-7 solution
- C [essential skills] use of configurationmanager class (use of file app.config)
- Ros-10 roslaunch summary
- C#【必备技能篇】ConfigurationManager 类的使用(文件App.config的使用)
猜你喜欢
Summary and Reflection on issues related to seq2seq, attention and transformer in hands-on deep learning
fs. Path module
Confusing basic concepts member variables local variables global variables
![Rebuild my 3D world [open source] [serialization-3] [comparison between colmap and openmvg]](/img/7d/e7370e757c18b3dbb47e633703c346.jpg)
Rebuild my 3D world [open source] [serialization-3] [comparison between colmap and openmvg]
Shutter uses overlay to realize global pop-up
Wxml template syntax
C#【必备技能篇】ConfigurationManager 类的使用(文件App.config的使用)

Programming implementation of subscriber node of ROS learning 3 subscriber
![[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis](/img/59/823b587566f812c76e0e4dee486674.jpg)
[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis
Applet data attribute method
随机推荐
Introduction Guide to stereo vision (3): Zhang calibration method of camera calibration [ultra detailed and worthy of collection]
MPSoC QSPI flash upgrade method
[daiy4] copy of JZ35 complex linked list
Solution to the problem of the 10th Programming Competition (synchronized competition) of Harbin University of technology "Colin Minglun Cup"
2309. 兼具大小写的最好英文字母
asp. Net (c)
Kubedm series-00-overview
Codeworks round 638 (Div. 2) cute new problem solution
Codeforces round 684 (Div. 2) e - green shopping (line segment tree)
2311. 小于等于 K 的最长二进制子序列
C#绘制带控制点的Bezier曲线,用于点阵图像及矢量图形
[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis
Global configuration tabbar
【PyTorch Bug】RuntimeError: Boolean value of Tensor with more than one value is ambiguous
My life
[code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
Creation and reference of applet
Luo Gu p3177 tree coloring [deeply understand the cycle sequence of knapsack on tree]
Introduction Guide to stereo vision (2): key matrix (essential matrix, basic matrix, homography matrix)
Jenkins pipeline method (function) definition and call