当前位置:网站首页>基于模板配置的数据可视化平台
基于模板配置的数据可视化平台
2022-07-05 09:27:00 【百度Geek说】

导读:在大数据智能时代,数据分析的价值越来越重要,而数据分析可视化平台的能力要求也越来越高。本文从百度数据中心的数据可视化平台出发,介绍了配置化的数据可视化平台的应用价值,并对数据可视化平台的整体处理架构进行了拆解。基于可配置的数据可视化平台,可以高效支持复杂的数据分析场景,提升分析效率,强化数据的价值。
全文6999字,预计阅读时间13分钟。
一、背景与目标
1.1背景分析
在数据智能时代,BI(Business Intelligence,商业智能)已经是现代数据运营的基础能力。以数据支撑业务,一方面需要我们基于数据仓库建设业务相关的全面、权威、稳定的基础数据,另一方面也需要我们建立数据分析的能力,通过图表对数据进行展示,从而提高数据展示的信息密度,然后辅以各种对比方式,让数据业务化、升华数据意义,赋能业务增长。
因此一个数据可视化平台的搭建就变得尤为重要,但由于复杂业务之间的差异使得平台的设计及开发过程难度大且复杂。考虑到人群、业务的分析习惯与业务各异的分析方法,数据可视化平台在报表的呈现、数据的计算、数据的发布效率等方面都面临着重大的挑战。
1.2问题与目标
以一个典型的广告商业化案例举例,客户基于投放目的选择不同的广告商业产品形式(如微博热搜榜单,百度的搜索置顶,各类视频网站的兴趣推荐等等),哪些形式能促进客户更好的触达用户;客户提供的样式(如视频、图片、内容等物料特性)让浏览内容的用户产生什么样的偏差等问题,都需要数据做支撑进行分析。结合分析师、看板用户的习惯和众多分析场景构建数据可视化平台生成数据报表时会出现以下问题:
1. 长期报表独立开发导致部分能力重复建设、重复开发;
2. 每个报表独立开发使得用户需要习惯多种样式、风格导致的体验差异;
3. 业务出现变动时调整、匹配成本较大,导致一段时间内无法有效赋能业务;
4. 平台计算能力不足导致的构建数据报表的时间、人力成本较大;
5. 平台稳定性保障难度高,需测试、排查层出不穷的异常。
为了能够满足用户的报表需求,即使投入大量的人力也仅能解决上述开发成本带来的问题。系统化的打造BI与数据之间的桥梁,需要深入到数据表达的各个环节,结合业务的特性,模块化、组件化各项能力,这样既能减少重复开发的成本,同时也能提高代码复用、可扩展性、报表管理以及容错等各方面的能力,保障用户的使用体验及业务适配性。
因此,一个优秀的数据可视化平台应满足以下几点:
1. 敏捷:能够快速响应需求;
2. 准确:能够保证平台数据的准确性,做到「所见即所得,所得皆所用」;
3. 多元:面向不同的业务属性、用户特性,例如对比计算、查询等方式能够通过模块组合、展现类型调整等方式满足需求;
4. 灵活:对于业务拓展或者变更,平台能够灵活变化以贴近业务的结构;
5. 简单易用:用户无论是在读、写数据,均能快速满足;支持业务过程以「配置」取代「开发」;
6. 易拓展:覆盖大部分业务分析场景,同时支持基于配置的二次开发前后端代码,易于扩展。
1.3 名词解释
1. 衍生指标:
基于基础指标,利用公式二次计算出来的指标,常见的例如以最近10天用户数计算出来的平均用户数,或利用当天用户数量对比昨日用户数量计算出来的日环比等。
2. 下钻:
一般指业务需要通过拆分、细化来挖掘或定位业务痛点,业务之间存在一定的关联性,透过关联逐层的拆解在分析时称之为下钻。在可视化场景中常用树状结构表达类似的层级关系。
3. 上卷:
在可视化场景中指多个业务数据构成一个总数时,通过系统利用业务间的关联性进行合计计算。
4. 维度分析:
常见的基线对比方式,以一项或多项业务为基准,通过数值对比分析当前业务状况。
5. 时间对比分析:
将时间进行分段处理后,对比当前时间段与历史(或基线)时间段之间的数值变化,从而判断业务状况。
二、整体设计与思路
2.1 需求分析与构思
2.1.1 场景分析
一个完整的数据分析闭环从分析需求开始,包含了数据采集、数据清洗、数据建模、数据呈现、数据应用、结论输出,利用产出的结论落地或提升业务。整个环节我们可以看到两种角色:
1.建设者:
进行分析一个命题或业务场景时,首先基于业务寻找数据支撑,在此过程中需要采集数据、将数据整理成具有业务含义的表达方式、提取出具有业务关联性的内容形成具有分析意义的集合,用更直观、形象的方式将数据进行展示等几部分工作。其次为了能更充分的表达业务,过程中需要将一些数据进行组合构建成衍生指标或者建立维度之间的联系。这些工作完成后,一个完整的业务场景会通过数字化、图像化的方式展示出来。
2.分析者:
针对业务的情况,透过数据开始剥离问题,以一个APP某商业化场景收入下降为例,分析师需要从APP的用户数开始逐层漏斗查看哪些环节导致的影响较大,也需要从各个维度进行下钻分析定位业务根结,还有可能利用类比分析、基线对比的方式横向比较相似场景下影响的差异。
面对相同的业务问题,不同方向的数据使用者可能也会有不同的行为,对业务理解的动向,分析的数据层级等也会有所不同。当然,用户也可以同时承担这两种角色,本质上简单易用的平台更便于分析型用户独立完成数据建设到分析的闭环,从而减少并释放人力,更快的解决业务问题。在当前数据无法满足业务分析时,分析者又会进入到建设型场景,继续寻找量化支撑所需的数据论据。
2.1.2 业务抽象与思考
完成多种业务场景的数据支持,需要技术为之创造条件,如果说建设者最终服务于分析者,以报表结果为导向,建设者是否可以在建设过程中充分表达分析者的数据需求呢?这些报表建设能力转嫁或拆解成程序化、模块化语言究竟是什么?平台配合建设者本身需要完成哪些工作、实现什么样的功能呢?同时,平台该如何保证为分析者提供准确、高效、全面的数据呢?接下来我们通过对数据的可视化过程拆解、抽象对上述问题一一解答。
2.2 架构设计
2.2.1 过程抽象
我们将分析者使用数据的全过程进行拆解,然后进行抽象化、组件化。分析者通过平台输入查询条件、指标、维度等等,服务端根据平台输入进行数据sql的组装并查询数据库,然后计算相关衍生指标整合计算结果,最终按照相应的样式呈现结果。整个逻辑过程拆解如图1所示。

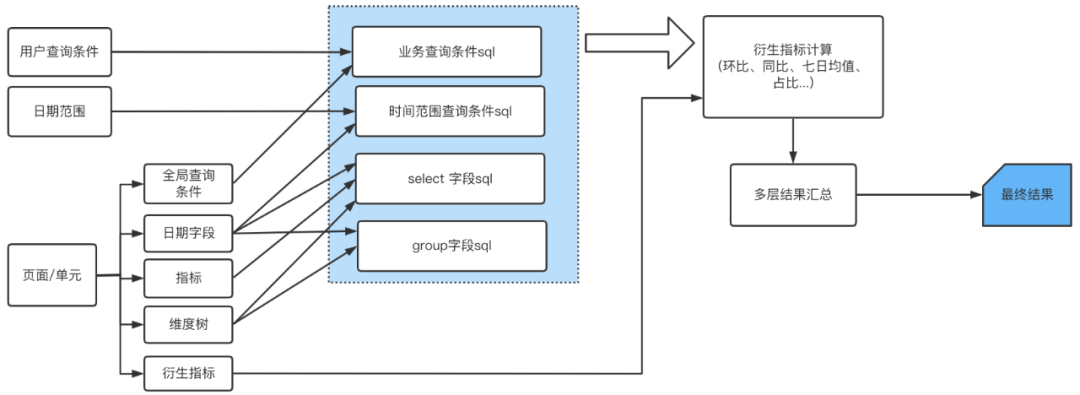
△图1 过程抽象逻辑
2.2.2 整体架构
根据数据可视化的过程抽象可知,一个完整的可视化平台需要包括数据获取、数据计算、数据呈现等几部分。数据如何获取、如何展示则需要进行统一配置管理,数据如何快速、准确的计算则由通用计算服务负责。同时可视化平台还需要保证数据的质量问题,在数据存在问题或者延迟时能够及时通知建设者去处理数据问题,这些则由运维看板负责。我们通过对数据可视化过程抽象和对此类平台的经验总结,将数据可视化平台架构拆解成如图2所示。
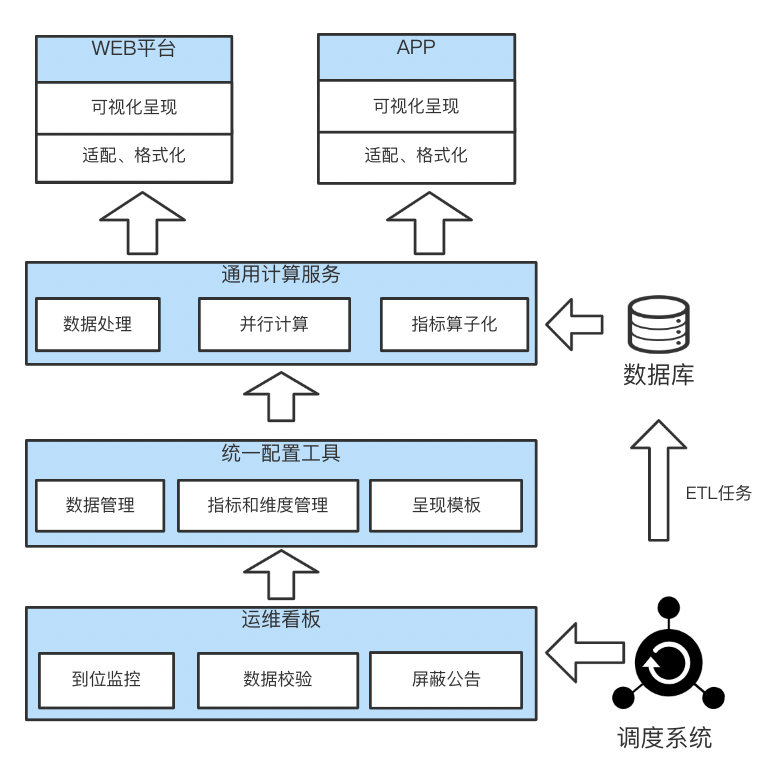
△图2 整体架构图
三、核心模块介绍
3.1 配置工具与报表呈现
在未进行配置化以前,建设一个报表需要后端开发人员基于数据库开发计算逻辑、分析、下载等功能,前端开发人员则基于数据以图表的形式进行渲染,代码冗余、开发成本高、周期长。统一配置工具是在数据库与报表呈现之间搭建起来的一座桥梁,数据建设者在熟悉数据逻辑的基础上通过配置工具的配置界面进行数据源、计算逻辑、呈现内容、样式等相关信息的配置,然后将其发布上线,各数据可视化平台的报表呈现模块根据配置的样式和内容渲染相应的组件,用户即可在对应的平台查看报表、分析或者下载数据。
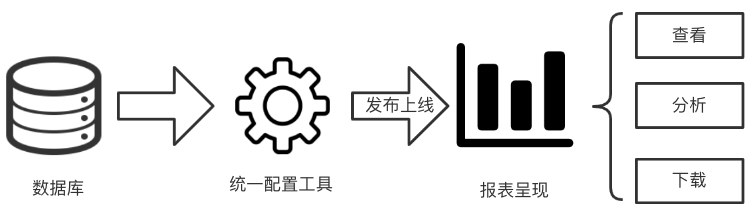
△图3 配置流程示意图
3.1.1统一配置工具
为了减少配置工具使用的复杂程度、降低用户学习成本,提高配置效率,针对业务以及数据需求相对稳定的分析场景设计固定的呈现模板,用户选择合适的模板配置相应的内容,且配置模板具备可扩展性,可灵活增删功能模块。
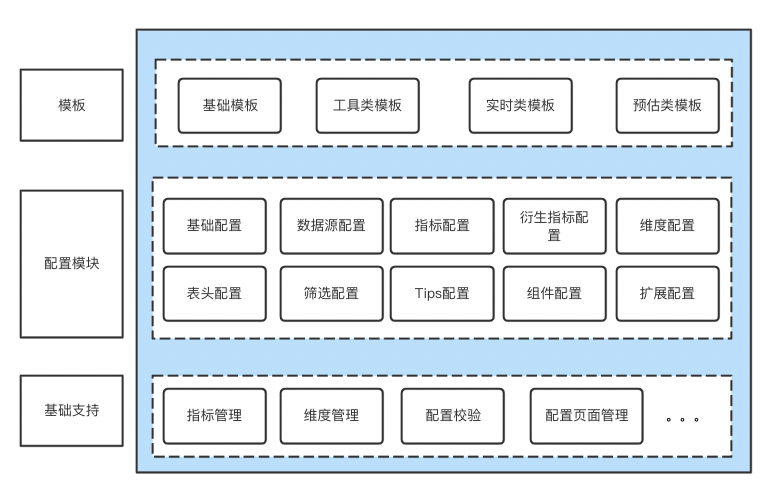
△图4 统一配置工具组成
配置工具页面根据用户选择的模板展示相应的配置内容,除了配置数据源、指标、维度等数据相关信息,还需要配置筛选控件、分析组件等内容。同时配置工具还支持通过扩展配置增加当前模板不支持的功能,从而基于模板进行二次开发。一个完整的配置工具除了基本的配置,还增加了指标管理、维度管理、配置校验等功能提高配置效率和用户体验的基础支持。
1. 指标管理:将指标、衍生指标的信息进行统一的管理,根据指标的属性特征提供各参数的默认值,配置人员在配置页面时可以直接使用指标管理模块的默认配置信息,实现了指标的一次配置多次使用。这不仅提高了配置人员的配置效率,提供指标参数默认值也有利于规范统一平台风格;
2. 维度管理:根据数据源配置信息,生成维度模板信息,配置人员只需要简单调整维度显示名称和顺序即可,方便高效;
3. 配置校验:校验用户配置的sql是否正确,快速定位错误配置。
3.1.2 报表呈现
数据可视化平台为用户提供丰富的图表组件(表格、趋势图、饼图、卡片、地图等等)和过滤条件(单选、多选、日期、输入框等等),丰富的图表样式充分满足复杂的可视化需求。
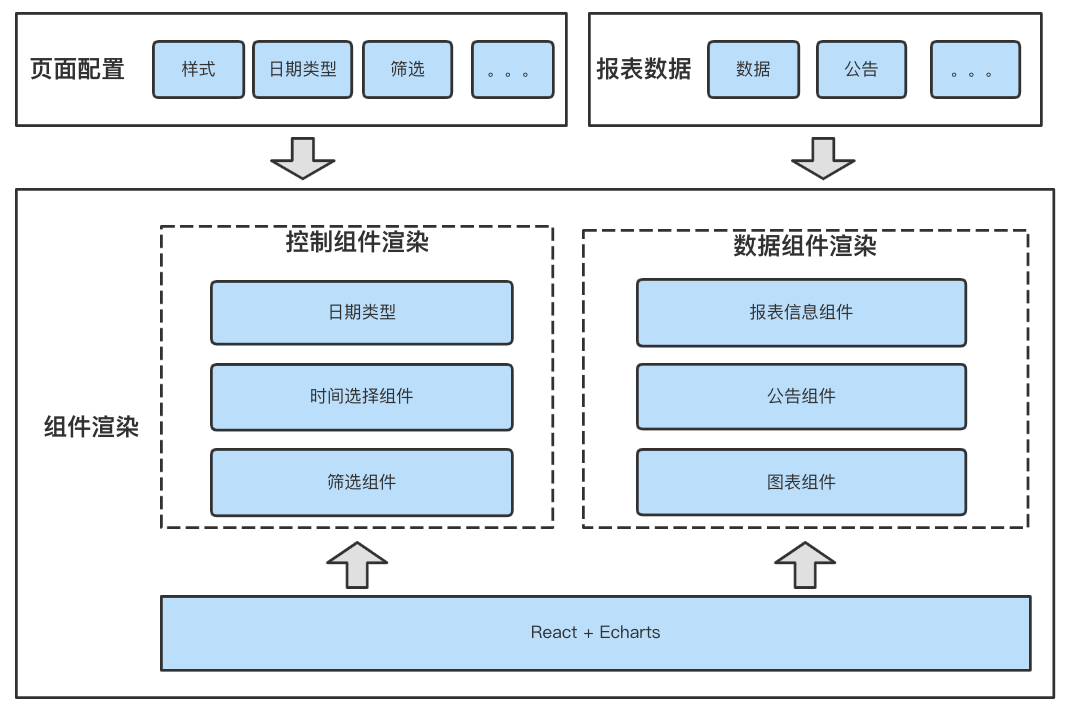
△图5 报表呈现的架构
报表呈现这部分的主要工作是将格式化后的数据以图表的形式渲染在浏览器中,供用户查询、分析数据。报表呈现的基础组件单元分为两类:
1. 控制组件:配置工具里配置的组件,比如筛选条件、日期类型等,这类组件在渲染组件时同时渲染组件内容;
2. 数据组件:需要渲染的具体数据,比如表格、折线图中的数据,这部分的数据是由通用计算模块来提供的。这类组件在渲染组件后,重新获取具体数据信息(数据来源不同)进行内容渲染。
为了满足复杂的分析场景,在报表呈现时往往是多个样式组合在一起使用。在进行设计时综合考虑代码的可复用性、通用性以及可扩展性将图表拆解成可以重复使用的最小单元,封装成组件。各组件最终如何组合排列呈现则由建设者根据需要的分析场景在配置工具里进行配置管理。
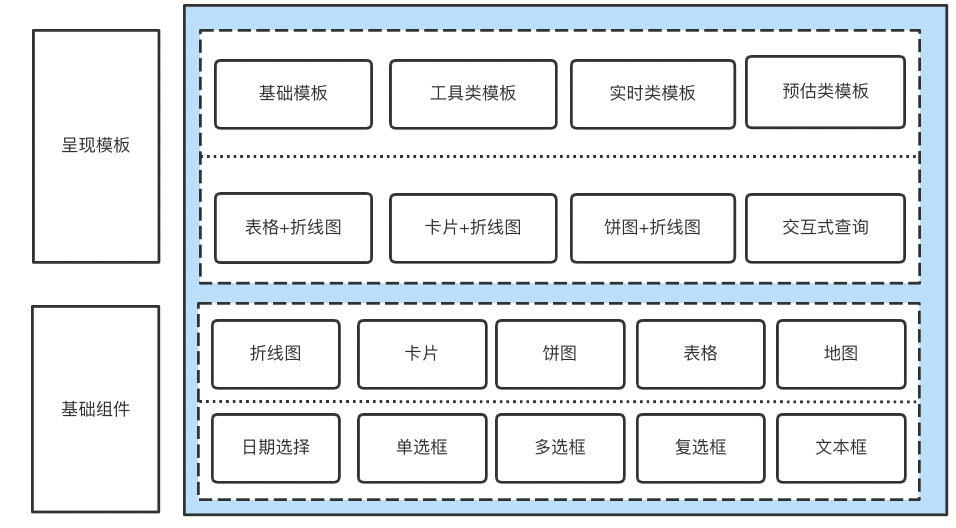
△图6 报表呈现的组成
针对业务以及数据需求相对稳定的分析场景报表呈现共设计实现了14种呈现模板,支持交互式查询、TOP排序、实时数据等业务场景的配置。对于更复杂的业务场景能够复用基础组件、开发上线。
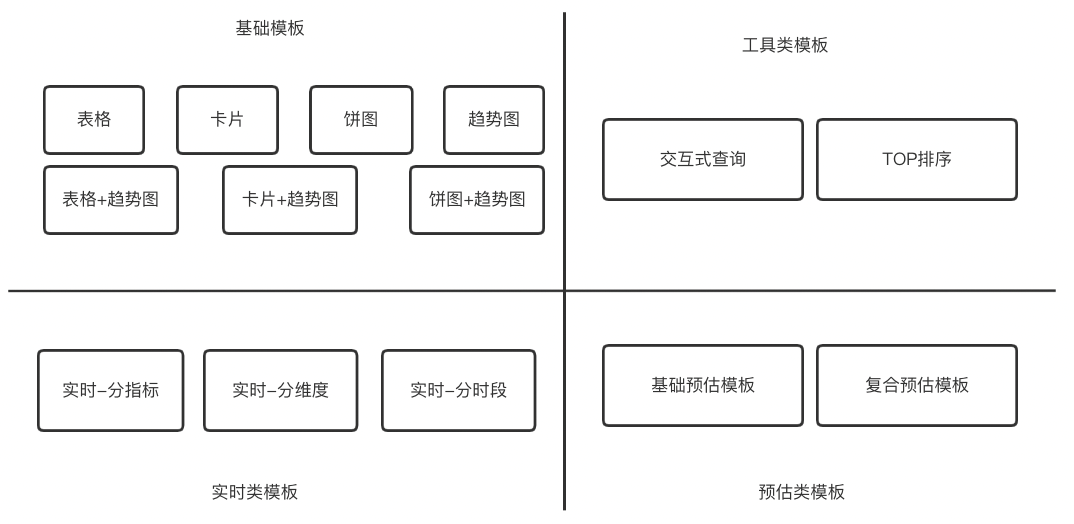
△图7 配置模板
3.2 通用计算服务
前面部分介绍了配置工具服务于计算和报表呈现,报表呈现图表的数据来源于计算服务。计算服务是整个数据可视化平台的大脑,主要负责将数据库中的原始数据根据不同的计算规则处理并生成用户需要的数据形式进行展示。不同的用户分析数据的维度、视角、场景存在差异,例如:在Top场景下,分析重点维度(如客户、产品等)数据的变化趋势;有的需要监控固定指标的波动,根据不同的筛选条件,交叉分析引起变化的原因、预测未来发展的方向;有的需要长时间范围的数据来分析指标随时间的变化规律;对于重点业务需要实时查看数据变化等等。计算服务除了要覆盖已知且复杂的业务场景,还需要考虑业务的不断扩展和对数据的深挖,快速跟进业务的发展,所以计算服务架构在设计时要充分考虑通用性和可扩展性。
3.2.1 架构实现
综合业务场景复杂性、代码复用性、服务通用性和可扩展性各方面的考量,我们对通用计算服务架构做了分层设计,每层各司其职,规范整体代码结构、逻辑清晰易读且能够快速支持新指标计算的扩展。
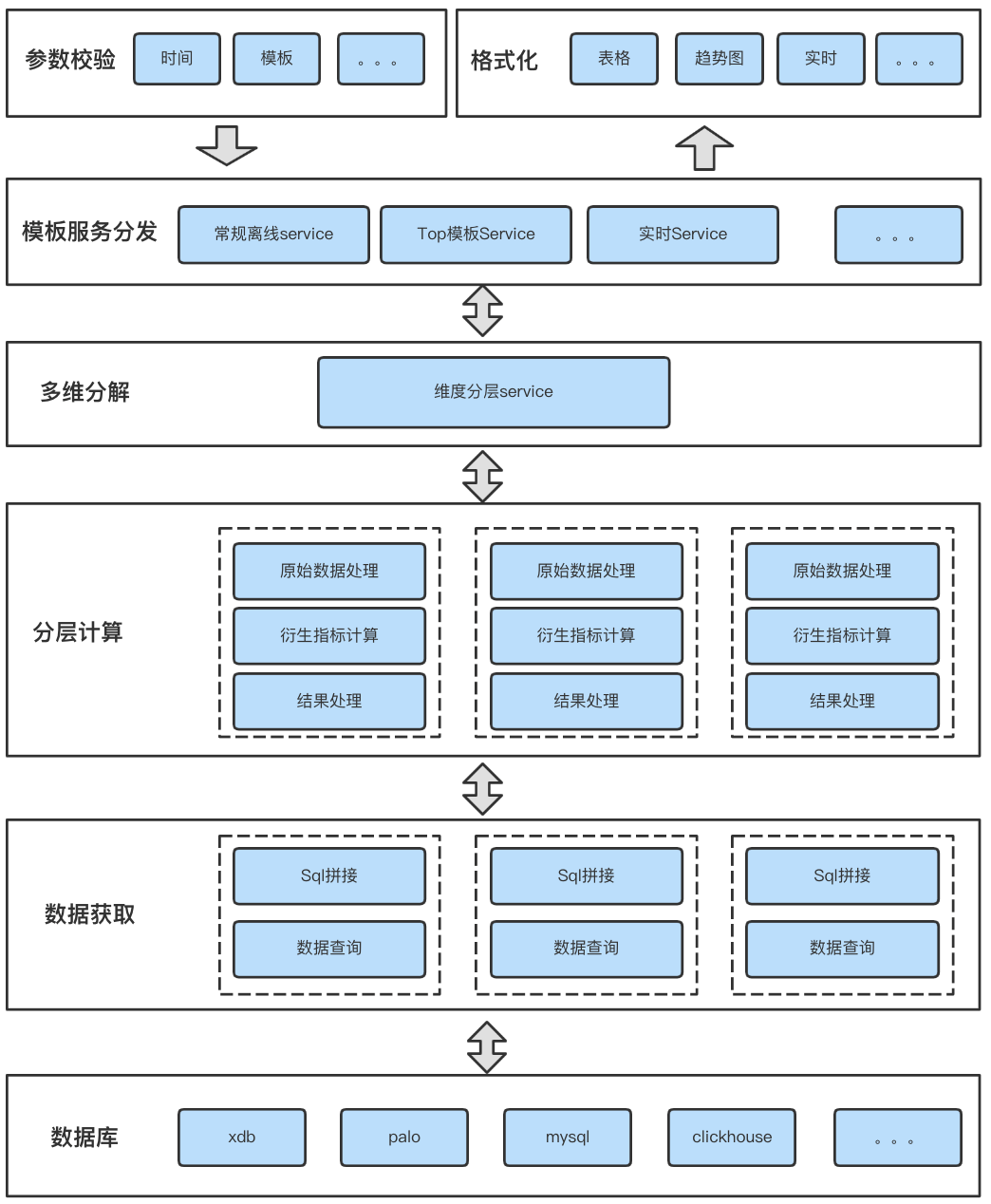
△图8 计算整体服务架构
1. 参数校验层
对于不同业务场景的数据请求,计算服务所要求的参数不尽相同,我们将参数校验部分独立出来,抽象出共同的参数校验逻辑,对于各模板独有的参数进行独立校验。
2. 模板服务分发层
为了满足不同的业务场景和数据展示需求,我们设置了模板服务分发层,按照业务场景进行分类,抽象出多个服务类服务于不同的数据场景。分发层根据用户在配置工具配置的信息为后续计算准备数据源、指标、维度等信息然后同计算请求一起分发到具体的服务类。
3. 多维分解层
为了支持数据上卷、下钻的数据分析维度之间的关系,我们设计了多维分解层,根据数据的层级分解出多个并行计算过程。多线程并行计算使得不同层级计算互不干扰、高效计算。
4. 数据获取层
为了能够支持多种类型的数据库且易于后续新增其他类型数据库,我们抽象了数据获取层,屏蔽上层数据获取逻辑、提供统一接口。底层数据库可以支持mysql、palo、xdb等,也能方便、快速的扩展支持新的数据库类型。
5. 分层计算层
由多维分解层拆解出来的多个计算过程,每个计算过程是独立的模块,在数据获取层提供的原始数据基础上并行计算周同、日环、七天均值等衍生指标,满足分析者多角度分析场景。衍生指标单独计算、互不影响,易扩展且不影响计算效率。最后根据延迟看板(该部分后边详细介绍)提供的数据延迟、屏蔽信息,将计算结果进行屏蔽处理,防止平台呈现异常数据。
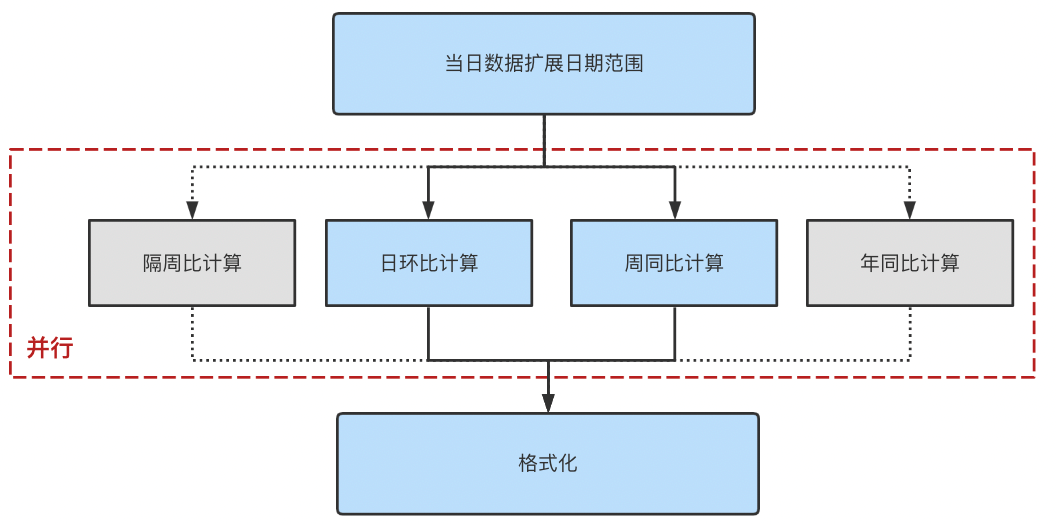
△图9 分层运算层
6.格式化层
格式化层主要负责根据不同呈现组件进行格式化,将数据处理操作放在服务端进行,前端拿来即用减少前端性能消耗,提高前端数据呈现和渲染效率。同时,格式化层屏蔽了底层计算逻辑,使得通用计算服务能够快速接入新的报表呈现平台,为其提供计算能力。
3.3 运维看板
数据可视化平台的核心是数据,平台底层维护了大量的数据流,这些数据来源于不同的上游,原始数据经过多层的数据抽取、加工、汇总,生成最终的前端表。在整个过程中可能出现各种问题,比如多数据源先后到位导致页面数据展示不全,上游数据异常、数据清洗过程中发生异常等。为了保证数据的准确性,在通用计算服务部分提到了需要对异常数据进行屏蔽处理,其屏蔽信息来源于运维看板。
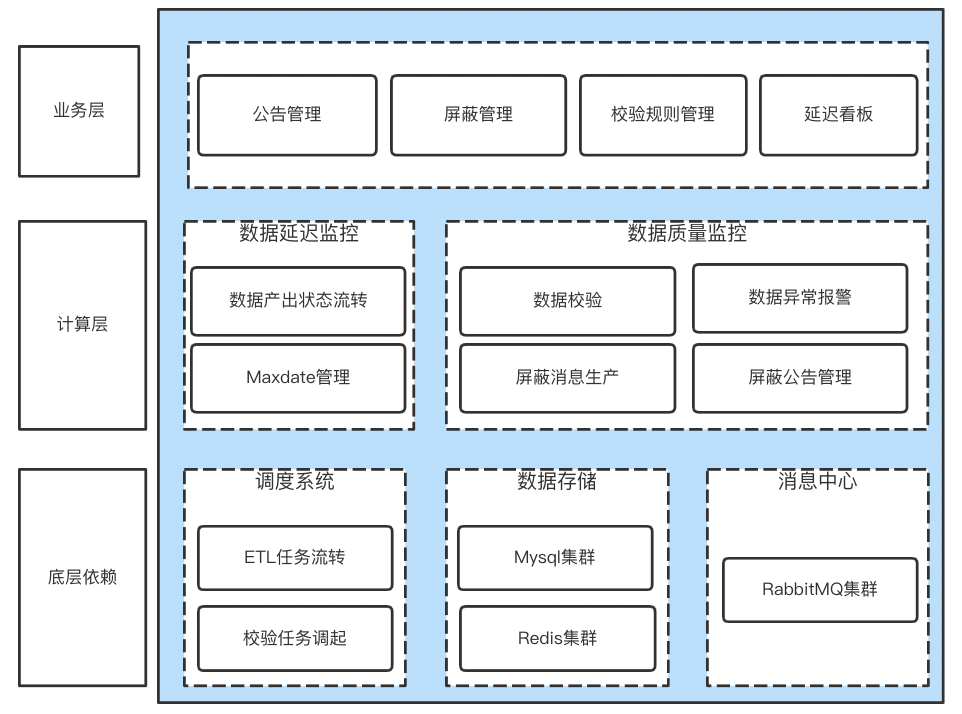
△图10 运维看板组成
运维看板监控数据到位情况、检验数据准确性,保障数据的正常产出,为整个平台数据的准确性和权威性保驾护航。其核心功能是数据延迟监控、数据质量校验、平台公告管理。整体的工作流程如下:
1. 调度系统负责所有ETL任务的调起和状态流转,在ETL任务运行完成后,通过消息队列通知到看板数据产出;
2. 看板调起数据校验服务执行校验任务,并将结果回传到看板;
3. 看板更新报表数据产出状态,根据校验规则校验数据波动是否超阈值,然后将数据到位情况、校验结果通过消息队列分发到对应的报表平台;
4. 各报表平台根据接收到的消息,重新计算数据更新数据缓存。
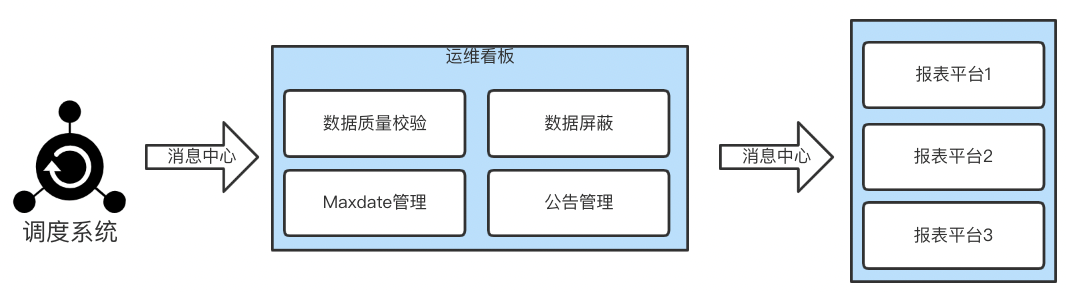
△图11 基于消息中心的运维看板工作流程
3.3.1数据延迟监控
为了保证例行化的数据任务在SLA时间内产出,延迟监控模块根据报表的ETL任务、SLA时间信息对数据到位情况进行监控、报警。数据到位时延迟监控模块第一时间将消息分发到各平台,保证数据缓存及时更新。对于多数据源的报表,延迟监控支持配置数据全部到位或部分到位呈现规则,看板基于配置规则进行数据屏蔽管理同时生成相应公告提示报表平台用户数据到位情况。如果数据在SLA时间内未产出则会通知报表负责人及时跟进数据运行状况。
为了方便监控报表产出情况,看板同时提供了界面化的数据产出监控界面,报表负责人通过界面查看、统计数据产出情况、ETL任务状态等。

△图12 数据产出监控界面
3.3.2数据质量校验
为保证数据的准确性和权威性,数据到位后运维看板会在平台数据呈现之前对数据进行质量校验,根据校验规则生成屏蔽信息,通过消息队列分发到各报表平台。当校验的数据异常时通过短信、电话、邮件等多种报警方式告知报表负责人,提醒跟进数据异常状况。
数据校验规则目前设计实现了三种类型:
1. 前端表校验:支持同环比、大小阈值等校验规则,在前端表数据到位后进行校验。
2. 数据源校验:支持同环比、大小阈值等校验规则,从上游拉取到数据后执行校验规则。
3. 自定义脚本扩展,支持用户自定义校验规则,提供openapi接口屏蔽数据。
3.3.3屏蔽和公告管理
除了数据延迟监控和数据质量校验能够屏蔽数据,运维看板还提供直接屏蔽数据功能,避免因为其他问题造成的异常数据呈现给用户。当数据异常或特殊事件造成数据波动较大时,公告管理模块上线公告告知用户数据波动原因。
四、总结
基于模板配置的数据可视化平台由统一配置工具、通用计算服务、报表呈现、运维看板等几部分组成。统一配置工具负责管理报表如何获取数据、以哪些图表样式呈现报表;通用机算服务提供衍生指标(日环、周同、七天均值、QTD、MTD等等),对比分析,数据上卷、下钻等计算能力;运维看板提供延迟监控、质量校验、屏蔽管理等功能保证数据的准确性、时效性;报表呈现提供丰富的图表组件(表格、趋势图、饼图、地图等等)和过滤条件(单选、多选、日期、输入框等等)满足复杂的可视化需求。多种配置模板贴合业务需求,以配置取代开发快速响应需求,同时易于扩展的架构能够灵活跟进业务变更或拓展。简单来说我们的平台:
1. 相比自助BI,辅助功能更强大、数据质量有保证
借助组件化强大的能力,我们在保持页面高自由度、灵活支持业务的同时,也构建了多种辅助对比的能力帮助分析者完成分析。通过一个完整的报表页面,能有系统的分析思路,也能获得多元的自助能力,强化了对业务的认知。其次减少了用户对数据的置信问题,将异常数据前置管理,通过数据延迟监控、数据质量校验、屏蔽、公告等一系列手段保证数据的准确性,避免分析者对数据质量的质疑,做到「所见即所得,所得皆所用」。
2. 相比传统BI,更快速、高效
前文讲到,定制化的开发最大的缺点是开发效率时间长、成本高,影响数据输出和分析。我们将计算能力、展示能力组件化、配置化,丰富的衍生指标计算能力、呈现组件使其尽量贴近定制化平台能力。即便是平台不支持的新业务场景这些高可用的开发组件也能参与到其分析场景的搭建过程中。基于模板配置的数据可视化平台能够快速响应业务需求、支撑分析业务能力、为业务赋能。
推荐阅读
边栏推荐
- LeetCode 556. Next bigger element III
- Driver's license physical examination hospital (114-2 hang up the corresponding hospital driver physical examination)
- OpenGL - Lighting
- A keepalived high availability accident made me learn it again
- LeetCode 496. 下一个更大元素 I
- SQL learning - case when then else
- Uni app implements global variables
- Ministry of transport and Ministry of Education: widely carry out water traffic safety publicity and drowning prevention safety reminders
- 阿里云发送短信验证码
- [ManageEngine] how to make good use of the report function of OpManager
猜你喜欢

顶会论文看图对比学习(GNN+CL)研究趋势
High performance spark_ Transformation performance

c语言指针深入理解
Unity skframework framework (24), avatar controller third person control

一篇文章带你走进cookie,session,Token的世界

Newton iterative method (solving nonlinear equations)
高性能Spark_transformation性能
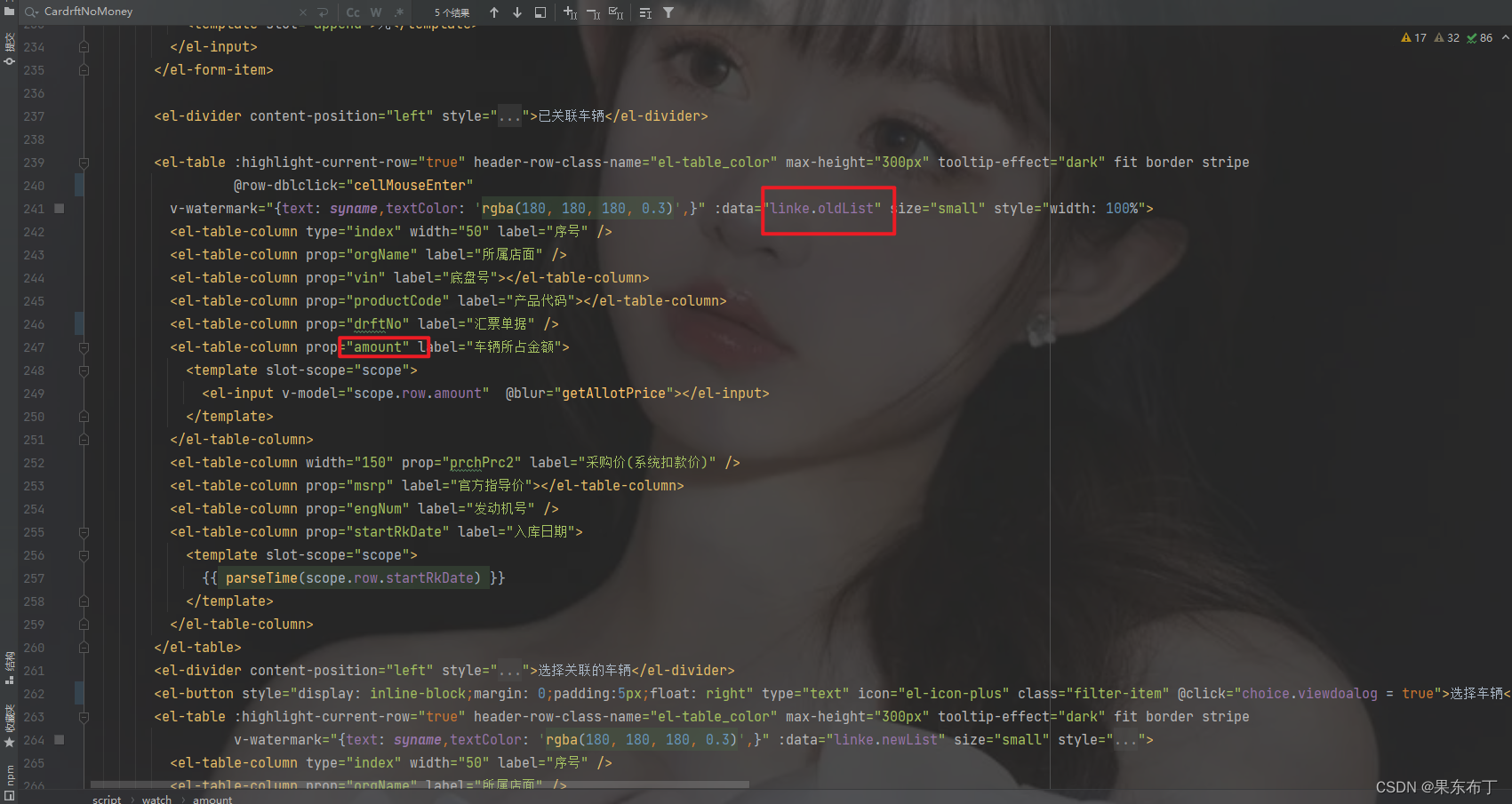
【数组的中的某个属性的监听】
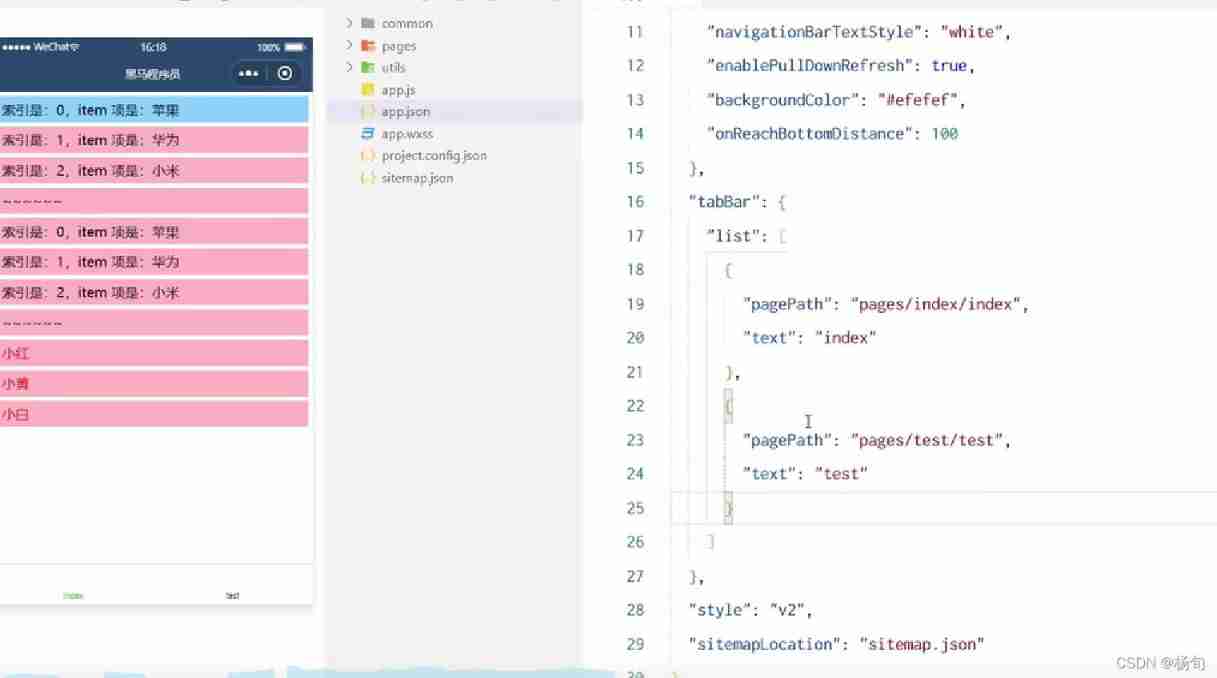
Global configuration tabbar
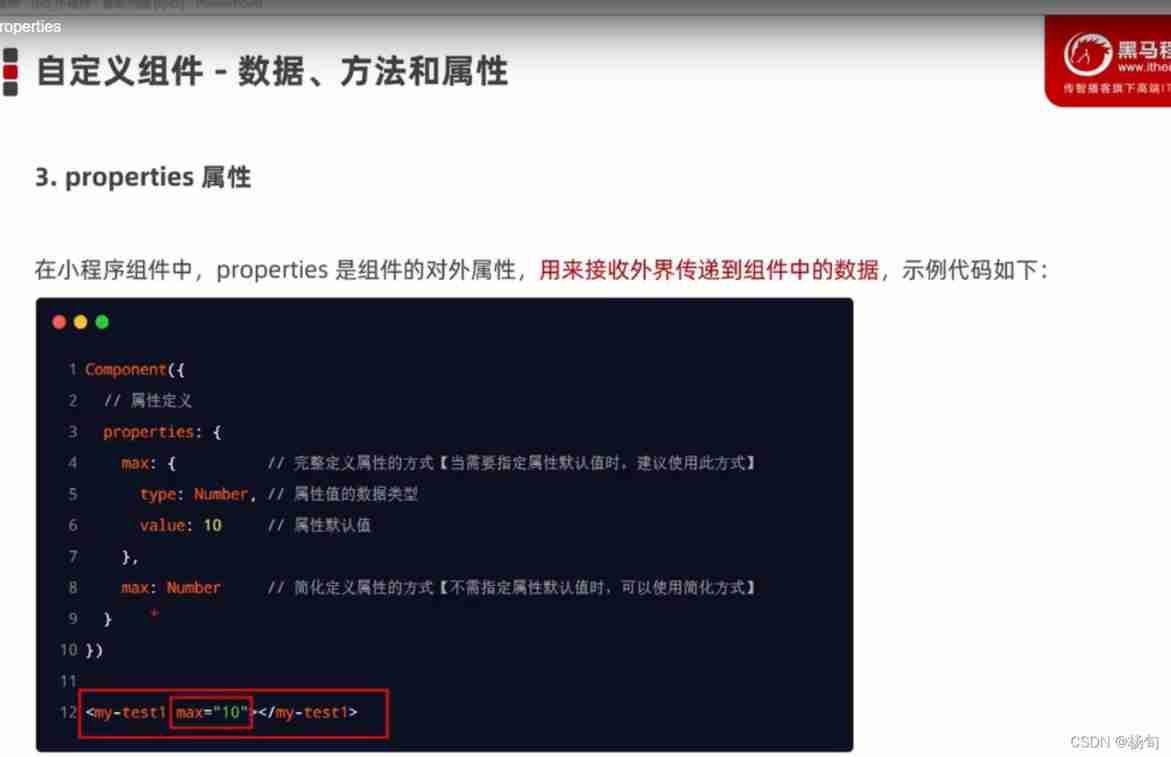
Applet data attribute method
随机推荐
High performance spark_ Transformation performance
我的一生.
【两个对象合并成一个对象】
Jenkins pipeline method (function) definition and call
微信小程序获取住户地区信息
【数组的中的某个属性的监听】
Analysis of eventbus source code
Kotlin introductory notes (II) a brief introduction to kotlin functions
2311. Longest binary subsequence less than or equal to K
[reading notes] Figure comparative learning gnn+cl
OpenGL - Coordinate Systems
2310. 个位数字为 K 的整数之和
fs. Path module
[hungry dynamic table]
Composition of applet code
np. allclose
[ManageEngine] how to make good use of the report function of OpManager
[JS sort according to the attributes in the object array]
2310. The number of bits is the sum of integers of K
高性能Spark_transformation性能