当前位置:网站首页>Generate confrontation network
Generate confrontation network
2022-07-05 08:59:00 【Wanderer001】
Reference resources Generative antagonistic network - cloud + Community - Tencent cloud
Generative adversary network (generative adversarial network,GAN) It is another generative modeling method based on differentiable generator network . Generative confrontation networks are based on game theory scenarios , Among them, the generator network must compete with its competitors . Generate network and directly generate samples  . Its opponent , Discriminator network (dircriminator network) Try to distinguish between samples extracted from training data and samples extracted from generators . Discriminator starting from
. Its opponent , Discriminator network (dircriminator network) Try to distinguish between samples extracted from training data and samples extracted from generators . Discriminator starting from  Given probability value , instructions x It is the probability of real training samples rather than pseudo samples extracted from the model .
Given probability value , instructions x It is the probability of real training samples rather than pseudo samples extracted from the model .
The simplest way to formally represent learning in a generative confrontation network is a zero sum game , The function  Determine the benefits of the discriminator . The generator accepts
Determine the benefits of the discriminator . The generator accepts  As its own benefit . During study , Each player tries to maximize their benefits , Therefore, it converges on
As its own benefit . During study , Each player tries to maximize their benefits , Therefore, it converges on

v The default choice for is

This drives the discriminator to try to learn to correctly classify samples as true or false . meanwhile , The generator tries to trick the classifier into believing that the sample is true . In convergence , The sample of the generator is indistinguishable from the real data , And the discriminator outputs everywhere 1/2. Then the discriminator can be discarded . Design GNA The main motivation is that the learning process does not require approximate inference , There is no need to approximate the gradient of the partition function . When  stay
stay  The middle is convex ( for example , The case of directly executing optimization in the space of probability density function ) when , The process guarantees convergence and is asymptotically consistent . Unfortunately , In practice, it is represented by neural network g and d as well as When not convex ,GAN Learning in can be difficult .Goodfellow It is believed that non convergence may cause GAN Under fitting problem of . Generally speaking , At the same time, the cost gradient reduction for two players cannot guarantee a balance . for example , Consider the value function v(a,b)=ab, The declining cost gradient of one player cannot guarantee balance . for example , Consider the value function v(a,b)=ab, One of the players controls a And generate costs ab, And another player controls b And receive the cost -ab. If we model each player as an infinitesimal gradient step , Each player and another player reduce their own costs at the cost , be a and b Prototype trajectory into stable mode , Instead of reaching the equilibrium point at the origin . Be careful , The balance of minimax games is not v The local minimum of . contrary , They are the points that minimize the cost of two players at the same time . This means that they are v The saddle point of , The parameter relative to the first player is a local minimum , The parameter relative to the second player is the local maximum . Two players can take turns to increase and then decrease forever v, Instead of just stopping at the saddle point where players are unable to reduce their costs . At present, it is not known to what extent this non convergence problem will affect GAN.
The middle is convex ( for example , The case of directly executing optimization in the space of probability density function ) when , The process guarantees convergence and is asymptotically consistent . Unfortunately , In practice, it is represented by neural network g and d as well as When not convex ,GAN Learning in can be difficult .Goodfellow It is believed that non convergence may cause GAN Under fitting problem of . Generally speaking , At the same time, the cost gradient reduction for two players cannot guarantee a balance . for example , Consider the value function v(a,b)=ab, The declining cost gradient of one player cannot guarantee balance . for example , Consider the value function v(a,b)=ab, One of the players controls a And generate costs ab, And another player controls b And receive the cost -ab. If we model each player as an infinitesimal gradient step , Each player and another player reduce their own costs at the cost , be a and b Prototype trajectory into stable mode , Instead of reaching the equilibrium point at the origin . Be careful , The balance of minimax games is not v The local minimum of . contrary , They are the points that minimize the cost of two players at the same time . This means that they are v The saddle point of , The parameter relative to the first player is a local minimum , The parameter relative to the second player is the local maximum . Two players can take turns to increase and then decrease forever v, Instead of just stopping at the saddle point where players are unable to reduce their costs . At present, it is not known to what extent this non convergence problem will affect GAN.
Goodfellow Another alternative formal income formula is determined , The game is no longer zero sum , Whenever the discriminator is optimal , It has the same expected gradient as maximum likelihood learning . Because the maximum likelihood training converges , such GAN The restatement of the game should also converge when sufficient samples are given . Unfortunately , The formalization of this substitution does not seem to improve the convergence in practice , It may be due to the suboptimal nature of the discriminator or the high variance around the desired gradient .
In a real experiment ,GAN The best form of game is neither zero sum , Nor is it equal to maximum likelihood , It is Goodfellow Different forms of heuristic motivation introduced . In this form of optimal performance , The generator is designed to increase the logarithmic probability of a discriminator error , It is not intended to reduce the logarithmic probability of correct prediction by the discriminator . This restatement is only the result of observation , Even if the discriminator is sure to reject all generator samples , It can also cause the derivative of the generator cost function to remain large relative to the logarithm of the discriminator .
Stable GAN Learning is still an open problem . Fortunately, , When carefully selecting model architecture and super parameters ,GAN The learning effect is very good ,Radford A deep convolution is designed GAN(DCGAN), It performs very well in the task of image synthesis , And shows that its potential representation space can capture important factors of change .GAN Learning problems can also be simplified by dividing the generation process into many levels of detail . We can train by conditions GAN, And learn from distribution p(x|y) In the sample , Instead of simply distributing from the edge p(x) In the sample .Denton Indicate a series of conditions GAN It can be trained to generate very low resolution images first , Then incrementally add details to the image . Because Laplacian pyramids are used to generate images with different levels of detail , This technology is called LAPGAN Model .LAPGAN The generator can not only cheat the discriminator network , And you can deceive human observers , The subject of the experiment will be as high as 40% The network output of is recognized as real data .
GAN The training process is an unusual ability that can fit the probability distribution that assigns zero probability to the training points . Generator network learning tracks specific points in a way similar to the popularity of training points , Instead of maximizing the logarithmic probability of the point . Somewhat paradoxically , This means that the model can assign the log likelihood of negative infinity to the test set , At the same time, it still represents the popularity that human observers judge to be able to capture the essence of generating tasks . This is not an obvious advantage or disadvantage , And just add Gaussian noise to all the values of the last layer of the generated network , It can ensure that the generator network assigns non-zero probability to all points . In this way, the generation network of Gaussian noise is added to sample from the same distribution , namely , Distribution samples obtained from the mean value of the conditional Gaussian distribution parameterized using the generator network .
Dropout It seems to be very important in the discriminator , When calculating the gradient of the generated network , Units should be discarded randomly . The gradient of the deterministic version of the discriminator using the weight divided by two does not seem to be so effective . Again , Never use Dropout It seems to produce bad results . although GAN The framework is designed for the differentiable generator network , But similar principles can be used to train other types of models . for example , Self supervision and improvement (self-supervised boosting) It can be used for training RBM The generator deceives the logistic regression discriminator .
边栏推荐
- MPSoC QSPI flash upgrade method
- 编辑器-vi、vim的使用
- 资源变现小程序添加折扣充值和折扣影票插件
- kubeadm系列-01-preflight究竟有多少check
- [beauty of algebra] solution method of linear equations ax=0
- 12、动态链接库,dll
- 2011-11-21 training record personal training (III)
- Understanding rotation matrix R from the perspective of base transformation
- Ros-10 roslaunch summary
- 3D reconstruction open source code summary [keep updated]
猜你喜欢
![[Niuke brush questions day4] jz55 depth of binary tree](/img/f7/ca8ad43b8d9bf13df949b2f00f6d6c.png)
[Niuke brush questions day4] jz55 depth of binary tree
Introduction Guide to stereo vision (6): level constraints and polar correction of fusiello method
Ros- learn basic knowledge of 0 ROS - nodes, running ROS nodes, topics, services, etc
nodejs_ fs. writeFile
![Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]](/img/ed/0483c529db2af5b16b18e43713d1d8.jpg)
Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]
Redis implements a high-performance full-text search engine -- redisearch
![Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]](/img/68/6bfa390b0bedcdbc4afba2f9bd9c0f.jpg)
Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]
Ros-10 roslaunch summary
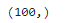
Numpy pit: after the addition of dimension (n, 1) and dimension (n,) array, the dimension becomes (n, n)
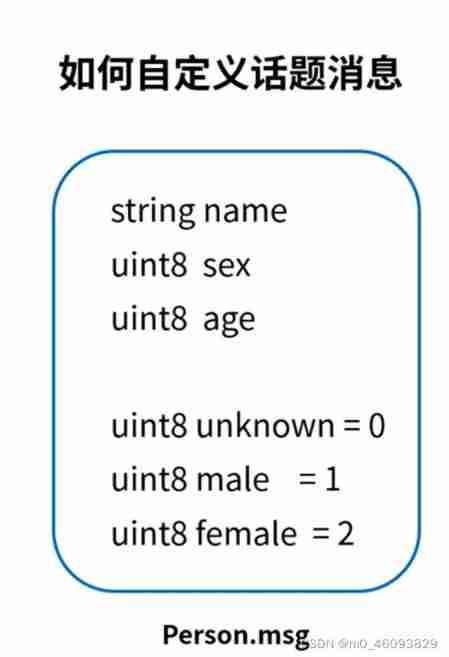
ROS learning 4 custom message
随机推荐
资源变现小程序添加折扣充值和折扣影票插件
Solutions of ordinary differential equations (2) examples
Codeforces Round #648 (Div. 2) E.Maximum Subsequence Value
[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis
Illustrated network: what is gateway load balancing protocol GLBP?
2011-11-21 training record personal training (III)
ABC#237 C
Blue Bridge Cup provincial match simulation question 9 (MST)
Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]
Attention is all you need
Dynamic dimensions required for input: input, but no shapes were provided. Automatically overriding
notepad++
Redis实现高性能的全文搜索引擎---RediSearch
[formation quotidienne - Tencent Selection 50] 557. Inverser le mot III dans la chaîne
Halcon blob analysis (ball.hdev)
编辑器-vi、vim的使用
微信H5公众号获取openid爬坑记
[matlab] matlab reads and writes Excel
Dynamic dimensions required for input: input, but no shapes were provided. Automatically overriding
Halcon affine transformations to regions