当前位置:网站首页>Evolution of Baidu intelligent applet patrol scheduling scheme
Evolution of Baidu intelligent applet patrol scheduling scheme
2022-07-05 09:44:00 【Baidu geek said】

Reading guide : Baidu smart applet relies on Baidu APP Represents the global traffic , Connect users precisely . Now , Baidu smart applet has an online volume of nearly one million , It contains more than 10 billion content resources ; Under massive pages , How to be more efficient 、 Quickly find problematic pages , So as to ensure the security of online content and user experience , It will be a big challenge . This article will focus on the security inspection mechanism of applet online content , It also focuses on the evolution process of patrol scheduling scheme of applet .
The full text 6178 word , Estimated reading time 16 minute .
One 、 Business profile
1.1 Introduction to patrol inspection service
Baidu smart applet relies on Baidu's ecology and scene , Through Baidu APP“ Search for + recommend ” This way provides a convenient channel for developers to obtain traffic , It greatly reduces the cost for developers to get customers . As the number of applet developers increases , The content quality of online applets is uneven , Low quality content ( porn 、 Vulgar, etc ) If you show it online , Will greatly affect the user experience ; And some serious violations ( Politically sensitive 、 Gambling, etc ) It can even cause serious legal risks , At the same time, it threatens the ecological security of small programs . therefore , For online applets , Quality assessment capacity needs to be built 、 Patrol inspection and online intervention mechanism , Through the content of the applet 7*24 Hours of online patrol , For small programs that do not meet the standards , Timely carry out time limited rectification or forced offline and other treatment , So as to ultimately ensure the online ecological quality and user experience of applet .
1.2 Objectives and core constraints of patrol scheduling strategy
At present, baidu intelligent applet has hundreds of millions of page visits after day level de duplication , The total page resources on the applet line are as high as tens of billions . Ideally , In order to fully control the risk , It should be implemented for all pages “ Should be inspected ”, Call back online risks quickly and accurately .
But in practice , The following factors or limitations need to be considered :
Different applets ( Or subject ) The content security index under is different . Such as , The release of small programs in special categories such as government affairs itself needs to be subject to more strict review , There is little possibility of violations ; contrary , The risk index of violation of small programs under some other special categories is relatively high . When some small programs under some entities have violated more times in history , The possibility of illegal cheating in other small programs under the subject is also relatively large , wait , Lead to different applets ( Or subject ) The next page needs to be treated differently ;
The quota limit for the applet to be crawled . Every time you grab an applet page , In the end, it is equivalent to accessing the page , It will be converted into the pressure on the applet server , The patrol inspection itself should not affect the stability of developer services . In the applet development platform , Developers can express the quota that their applet is allowed to be crawled ; For applets that do not display expression quotas , We will also according to the traffic of the applet (PV、UV etc. ) Set a reasonable grab threshold ;
Resource constraints . Evaluate the content security of the page , First, rely on the page spider Grab 、 Rendering 、 Parse the text and pictures contained in it 、 Security detection for text and pictures ; And grab 、 Rendering 、 Detection and other processes need to consume a lot of machine resources ;
Other relevant factors and limitations include : Risk index corresponding to page traffic ( High traffic pages and pages with only one click have different impact surfaces when risks occur )、 Differentiation of different flow inlets, etc .
therefore , We need to consider all the above , Design patrol scheduling strategy , And according to the online call case The evaluation of , Constantly optimize and adjust strategies , Optimize resource utilization , To be more efficient 、 More accurately identify potential online risk issues , Reduce the exposure duration of risk online , Finally, ensure the ecological health of smart applets .
Two 、 The evolution process of patrol scheduling scheme
2.1 V1.0 Version inspection scheduling scheme
2.1.1 Top tier architecture
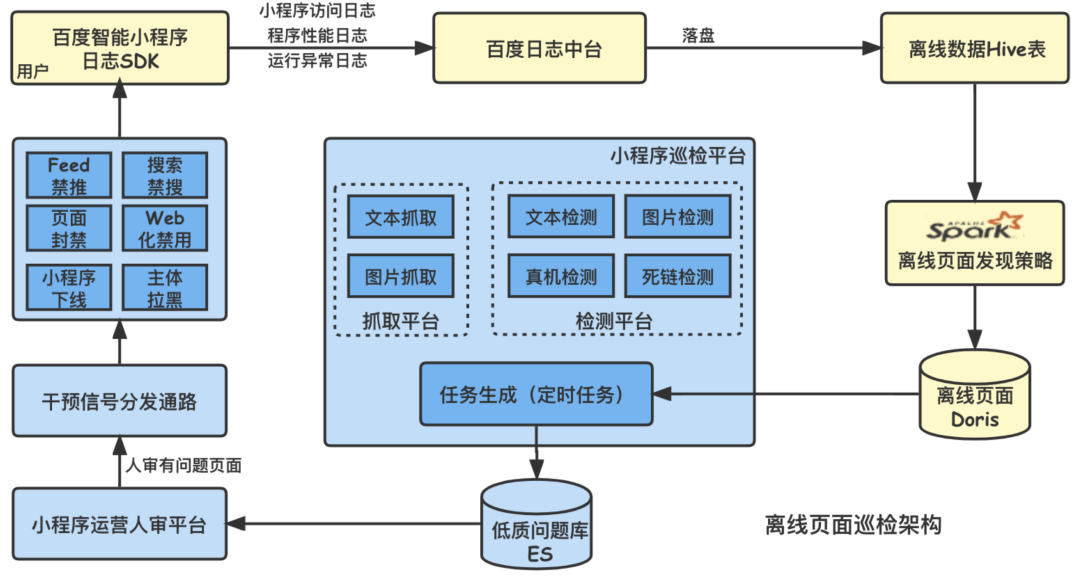
On-Site Inspection V1.0 The top-level design of is shown in the figure below , The key components included ( Or process ) as follows :
data source : Online users in the process of using Baidu intelligent applet , End sdk Will continuously collect relevant buried point logs ( Including applet access logs 、 Performance log 、 Exception log, etc ), Then report to Baidu log Zhongtai , And drop the disk for storage . These log data will be a very important data source for patrol page discovery strategy .( remarks : Based on Baidu security guidelines , We will not collect or obtain or store user privacy information such as confidential mobile phone number through login status )
Page discovery strategy : The applet clicks every day ( Or visit ) The number of duplicate pages is as high as hundreds of millions , Limited to grabbing 、 Rendering 、 Resource limitation of detection and other links , How to efficiently mine potential risk pages from these pages , Is the goal of patrol strategy .
Patrol platform : The platform itself contains patrol task generation 、 Page sending and grabbing 、 Various ability tests ( Corresponding to risk control class / Experience class 、 Red lines / Non red line and other low-quality problems ) And other sub service modules , There are many between modules Kafka Asynchronous interaction .
Low quality audit and signal issuance : Because some machine audit capabilities focus on high recall , The operation students' meeting will manually review the risk content of the machine review recall , The manually confirmed low-quality signal will be sent and applied to the downstream .
Online low-quality intervention ( Suppress ): For all kinds of low-quality risk problems , Combined with the characteristics of applet traffic 、 The risk level of the problem, etc , We have a perfect set of 、 Refined online intervention process , Small programs will be shielded from a single page 、 The flow is closed until the applet goes offline 、 Even the main body pull black and other punishment measures to varying degrees .
2.1.2 Implementation of patrol scheduling strategy
V1.0 The patrol inspection strategy of the version adopts offline scheduling , Combined with applet traffic distribution 、 Industry category characteristics 、 Online release cycle 、 Violation history and other characteristics , We abstract a variety of different strategies from online , Schedule different periods from hour level to week level .
To balance business demands and resource needs , The patrol dispatching scheme also considers the following factors :
Pages within the same strategy and between different strategies URL Accurate weight removal
Identification and de duplication of the same page from different channels
The pages of the applet are distributed by different channels , Such as Feed、 Search for 、 Dynamic forwarding, etc , Same page under different distribution channels URL There will be some difference , The content of the page itself is the same , Therefore, we have built a special strategy to identify the same page under different traffic channels . The above page is de duplicated , The purpose is to improve the effective utilization of resources .
2.1.3 Business challenges
However , With the rapid growth of the number of developers and small programs settled in Baidu intelligent small programs , The number of pages of small programs has soared from billions to tens of billions ; At the same time, the introduction of service business , The requirement for timeliness of risk control has been raised from day level to hour level . The current architecture can no longer meet the business requirements of business growth for online risk control .
2.2 V2.0 Version inspection scheduling scheme
2.2.1 Design objectives ( To optimize the direction )
V1.0 The architecture detection data is mainly offline data , have T+1 Time delay of , The risk control problems exposed the previous day can only be found the next day , In order to quickly discover the risk control problems exposed on the line , Reduce the exposure time of online problems ,V2.0 The ultimate goal of architecture design is to discover online risk page exposure . In order to achieve this goal , The inspection page is mainly based on real-time streaming data , Offline data as a supplement ; in addition , Applet page detection needs to grab the page content , It will put pressure on the applet server , Therefore, we should also ensure the uniformity of single applet page submission for inspection and the limitation of single day limit . The specific design criteria are as follows :
principle : Real time first 、 Offline supplement
Red thread : It does not exceed the limit of applet capture limit 、 Grab evenly , You can't grab the same applet
Product needs : Ensure high coverage of page detection
Limit : Page crawl resource limit
2.2.2 Top tier architecture
Evolved V2.0 The top-level architecture design of patrol strategy is as follows :
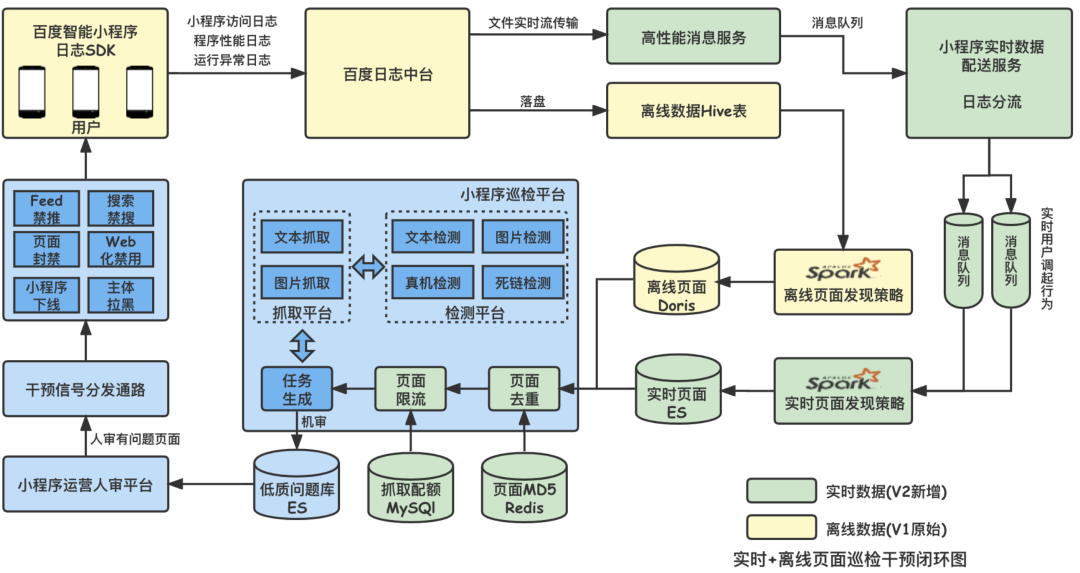
Comparison V1.0,V2.0 Real time data stream is introduced , And the capture quota of applet is made 5 Minute a window level finer grained control .
2.2.3 V2.0 Disassembly and implementation of patrol scheduling strategy
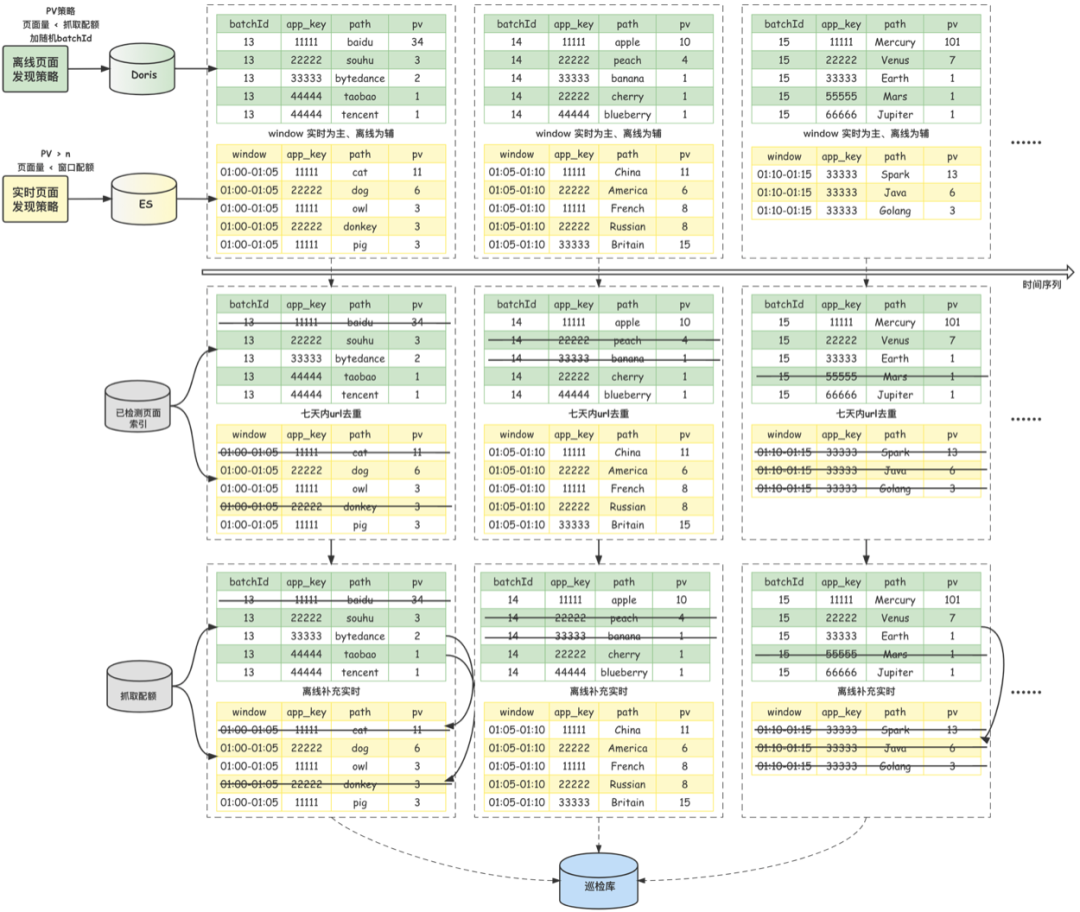
The overall implementation of real-time patrol inspection is shown in the figure below , It can be divided into three parts : Real time page discovery strategy 、 Offline page discovery strategy and page scheduling strategy . The strategy of real-time page discovery is compared with patrol V1.0 New strategy of Architecture , Directly receive real-time stream log data , Filter out the pages clicked by users according to certain strategies , It can realize minute level risk control problem discovery ; Offline page discovery strategy and patrol inspection V1.0 The architecture is similar , use T-1 Log data for , As the bottom of real-time data , Not all real-time data is used due to the use of small programs qps There are peaks and troughs , Use troughs in applets , Page discovery will be reduced , As a result, the ability of page capture and detection is not fully utilized , At this time, offline data is needed as a supplement ; Page scheduling policy aggregates real-time and offline policies , Realize offline data supplement real-time data , The function of real-time page de duplication , Capture the page and send it to the machine for examination and detection .
2.2.3.1 Offline page discovery strategy
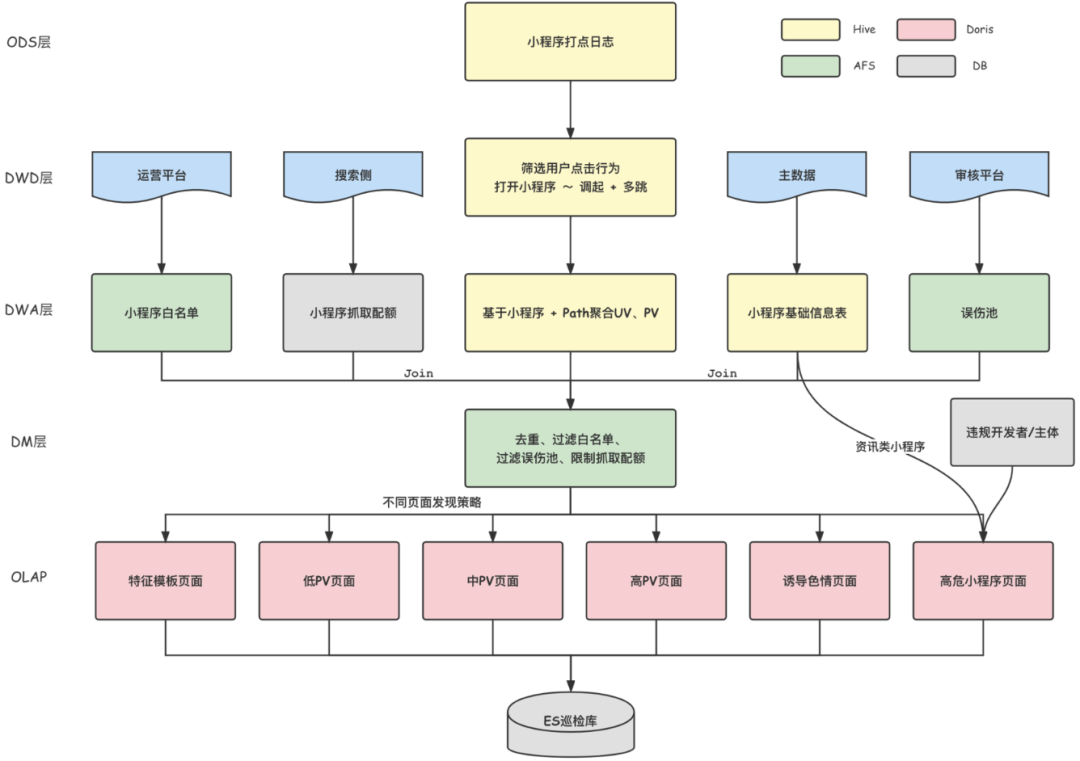
Offline page discovery strategy , Is to use the user of the previous day to browse the log of the applet page , Count the number of pages PV, And filtered through the accidental injury pool 、 Grab quota restrictions and other strategies , Compare the page to be inspected with the page PV Deposit in Doris in , For patrol inspection and dispatching .
The data flow is shown in the figure below , The data goes through ODS layer (Hive The table stores the original log of the applet )、DWD layer (Hive The table stores user call logs )、DWA layer (Hive The table stores each page PV)、DM layer (Doris The table stores the page information to be detected ), The calculation between the layers of the data warehouse passes Spark Realization .
2.2.3.2 Real time page discovery strategy
The data source of real-time page discovery strategy is the real-time distribution service of applet , Applet real-time distribution service is the basis of applet real-time data warehouse , The data user adds log diversion rules at the management end of the real-time data distribution service , The qualified data can be shunted to the specified message queue ( Baidu BigPipe) in , utilize Spark、Flink Or the program receives the message and calculates it . The overall architecture of real-time data service is shown in the figure below , At present, the second pole delay has been realized .
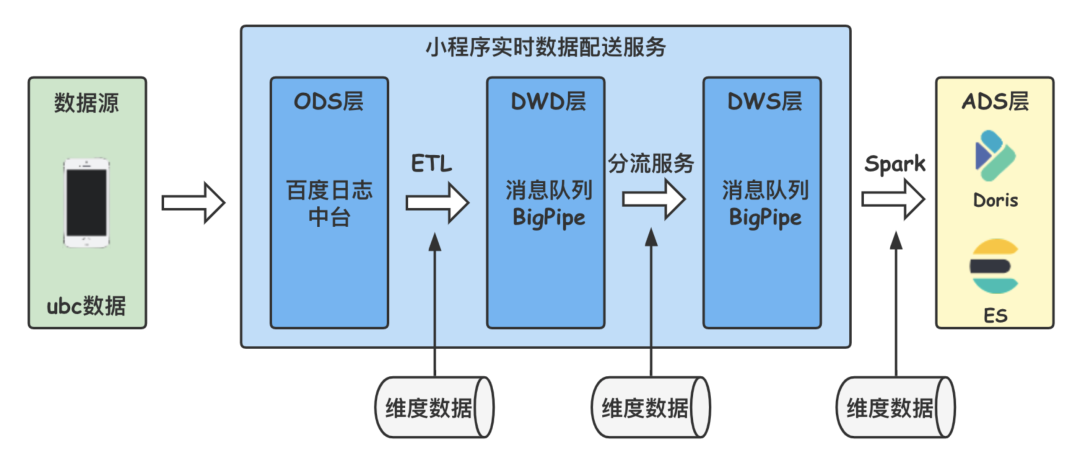
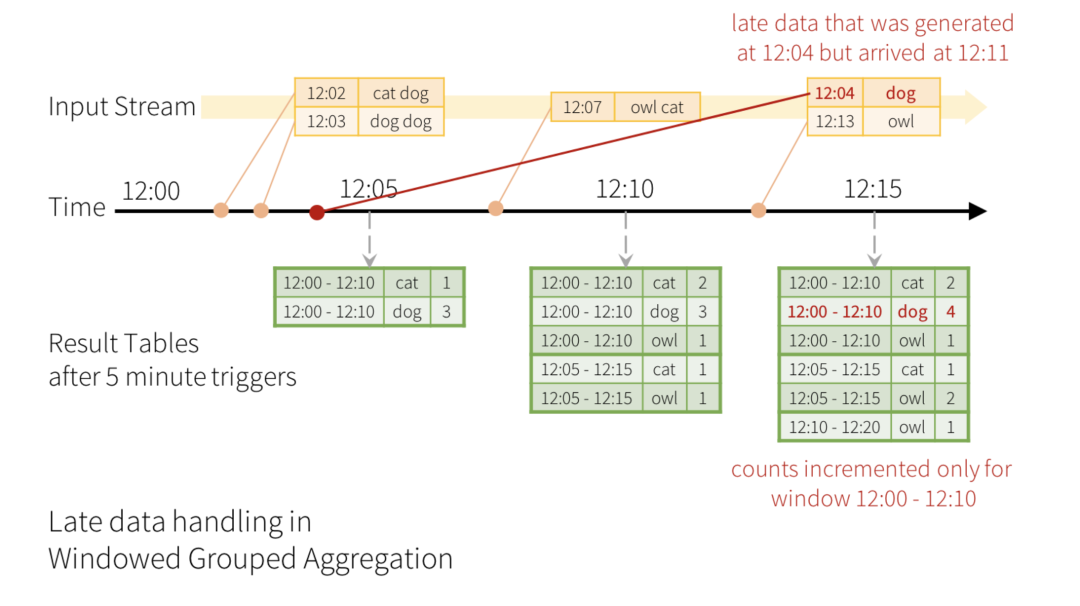
Configure the log diversion rules for filtering users to call up applets in the applet real-time data distribution service , utilize Structured Streaming Receive the corresponding message queue Topic, First, extract the key information in the log , Include : Applet ID、 page url、 Event time, etc . Small programs have hundreds of millions of pages clicked every day , It is unrealistic to detect that all pages are covered , So... Was screened out PV Higher page priority detection , real-time data PV The calculation of requires a time interval , And Structured Streaming micro-batch Corresponding , Take the time interval as 5min,Structured Streaming Of windowSize Set to 5 minute , The sliding step is also set to 5 minute , Windows do not overlap , Calculation 5 Within minutes , Of each page PV. For data with too long delay , Need to pass through watermark( watermark ) Abandon it , The time of taking watermark is 15 minute , namely 15 The data from minutes ago will be filtered . The data output adopts Append Pattern , Output only once per window , Output final results , Avoid repeated inspection of pages in a single window . The concept of specific window and watermark is shown in the figure below ( This drawing is quoted from Spark Structured Streaming Official website ,https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html).
Due to page content capture QPS Co., LTD. , Unable to grab all pages for inspection , For in window PV All larger pages are sent to crawl , For low PV page , Because there are too many pages , Sampling inspection is adopted ,Structured Streaming I won't support it Limit sentence , In order to realize data sampling , to PV = 1 A page of 0-9999 The random number rand, select rand < 100 The page of , I.e. low PV Page sampling 1%, Eventually it will be high PV Page and low after sampling PV page union Post output , Guarantee to submit for inspection qps Less than page crawl qps Limit .
The selected pages also need to be restricted by a series of product policies :
Some small programs are trial free small programs , Filter out the pages of these applets ;
The accidental injury pool was recalled by the machine Auditor , But the page with no problem in human review , Filtering the accidental injury pool can greatly improve the detection accuracy ;
A large number of page grabs will cause server-side pressure on small programs , Each applet has a crawl quota limit .
Page filtering adopts left join operation , Associate the real-time flow with the offline dimension table , Offline dimension data is also constantly updated , You need to ensure that the name of dimension data remains unchanged , The data content is constantly updated , Ensure that the real-time stream can get the latest dimension data in every window .
The final output data is output to Elasticsearch in , If all the data are written under the same index , All additions, deletions and changes are under the same index , The amount of data under the index is increasing day by day , Reduced query and insertion efficiency , And it's inconvenient to delete historical data ,delete_by_query Poor performance , And not physically deleted , It can't release space and improve performance . Index alias and time index segmentation are adopted here , The advantage is that the historical data can be deleted according to the historical index , Convenient operation , Can effectively free up space , Improve performance .ES Index segmentation needs to create index aliases in turn , Create index template , Create an index containing dates , Develop and configure rollover The rules , The scheduled task of creating a segmented index and deleting an old index .
PUT /%3Conline-realtime-risk-page-index-%7Bnow%2FH%7BYYYY.MM.dd%7C%2B08%3A00%7D%7D-1%3E/{ "aliases": { "online-realtime-risk-page-index": { "is_write_index" : true } }}POST /online-realtime-risk-page-index/_rollover{ "conditions": { "max_age": "1d", // Index by day "max_docs": 10000000, "max_size": "2gb" }}
2.2.3.3 Page scheduling policy
After the offline and real-time page discovery strategies introduced in the previous two parts , The offline page data set and real-time page data set to be inspected are obtained respectively . The final page scheduling strategy will be introduced in detail based on these two sets to be checked .
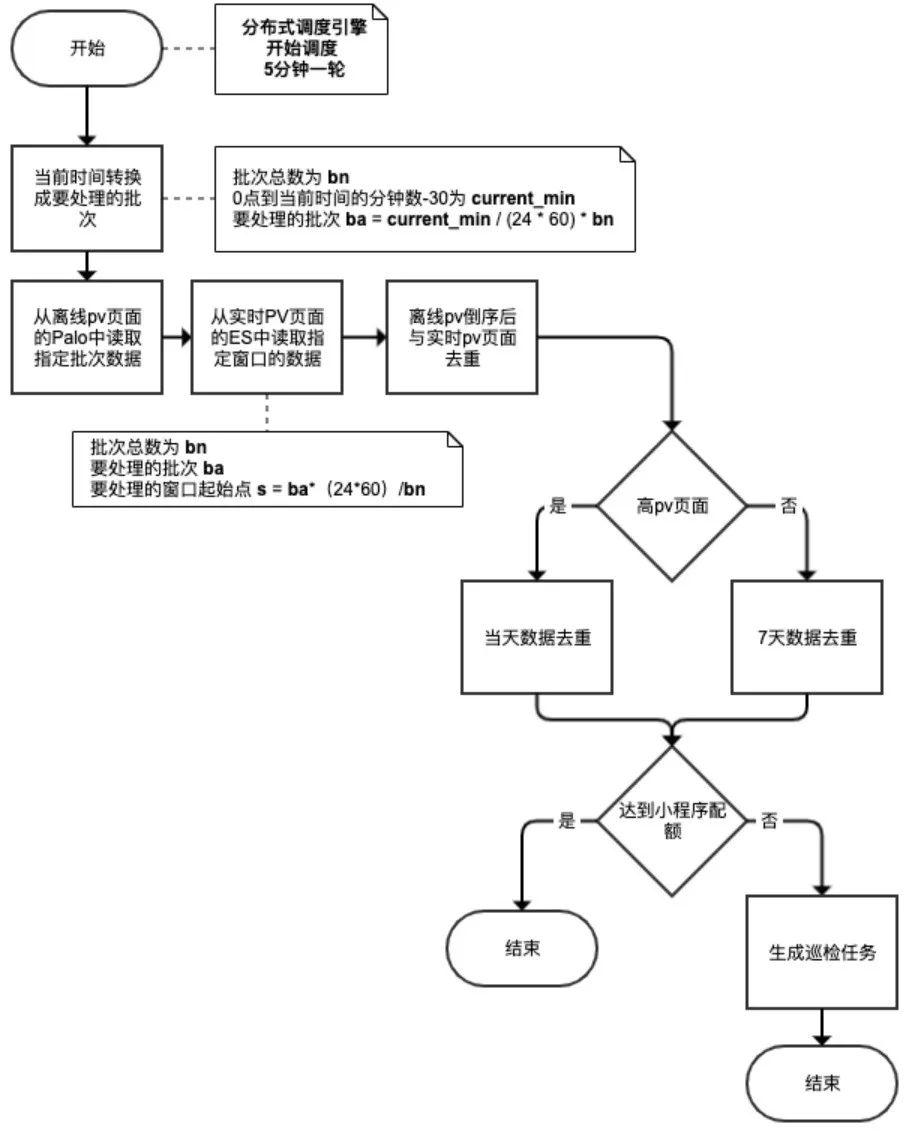
1、 Data partitioning , Periodic scheduling
For offline datasets , Use 【 batch 】 To divide multiple batches of data sets ; For real-time data sets , Use 【 window 】 To divide multiple batches of data sets . Use 【 Timing task 】 To periodically process these divided data sets . Divide the day into bn Lots , hypothesis 【 Timing task 】 The number of minutes of the day when the current running time is currentMinutes, that , Now we have to deal with 【 Offline data 】 Of 【 batch 】 batch = currentMinutes * bn / (24 * 60). Correspondingly , Now we have to deal with 【 real-time data 】 Of 【 Window start point 】 windowStart = batch * (24 * 60) / bn. Considering the watermark setting of real-time data processing and the scheduling cycle of timing tasks ,currentMinutes Not strictly taking the current time , But by the current time -30 Get... In minutes .
2、 Real time first , Offline supplement
Again, around the limitation of system resources 、 The pressure caused by grabbing a single applet 、 Design principles such as supplement between offline and real-time page collection , In a single cycle of page scheduling , If the limit is not reached , All real-time pages will be scheduled for detection ; If the real-time page still fails to reach the limit at this time , Then the offline page will be used to supplement , To ensure that the system runs at full load at all times , Make full, uniform and effective use of resources . meanwhile , This scheduling method can also ensure the mutual backup of real-time and offline strategies , When a single problem arises , The system can still find pages and send them for inspection through another strategy , Not to idle . Besides , The offline dataset page will be based on PV Proceed to reverse , Make the offline pages with more clicks be detected with higher priority .
3、 Page de duplication
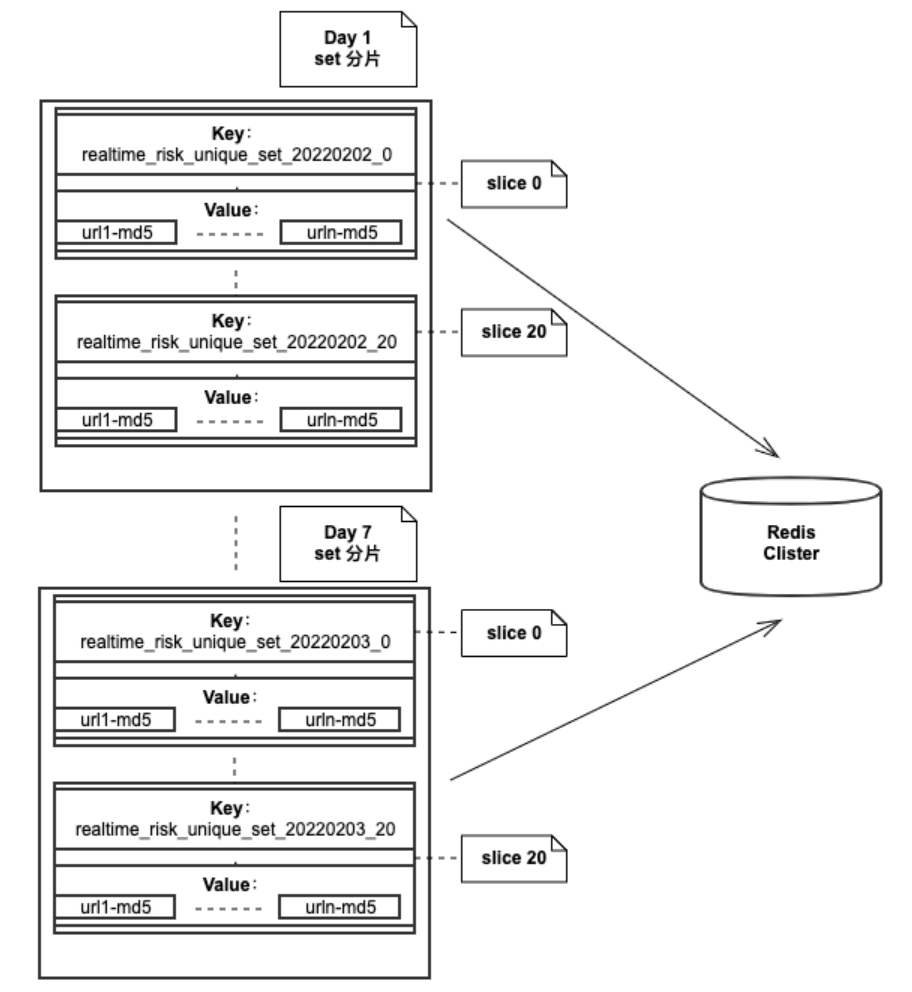
Based on online pages PV The law of distribution , In order to improve the efficiency of patrol inspection as much as possible PV coverage , The page scheduling strategy also adds high pv Page de duplication and medium low on the same day PV The logic of de duplication in the specified cycle of the page . Storage database selection Redis, Data structure and page url The corresponding slice calculation design is as follows :
data structure
aggregate , The collection stores the pages that have been detected URL Convert to 16 position md5, The amount of data stored in a single collection for one day is too large , Therefore, the data of a day is divided into multiple slices , Each fragment is a collection . If you divide a day 100 A shard , Then one day there will be 100 A collection of .
url Corresponding slice calculation
1、 Applet url Middle letter to int Then add to get the number x
2、x mod The number of slices is key
Data structure diagram :
2.2.4 Revenue review
The intelligent applet inspection platform is evolving 、 In the process of optimization , The platform capability has been greatly improved :
The number of daily patrol pages has supported tens of millions , Page coverage has been greatly improved ;
A real-time inspection path based on real-time data is added , Greatly reduce the online exposure time of the problem page , The problem is found in minutes , Reduce the day level of sorting intervention chain route to the hour level ;
Scheduling strategy of offline data supplementing real-time data , Make full use of page capture and page detection resources , Use less resources , Detect more pages ;
Finally, a small program quality assurance system is established , Help better identify and deal with online problems , Control online risks , Reduce the proportion of online low quality , Protect the ecological health of small programs .
===
3、 ... and 、 Think and prospect
In this paper, we focus on the business objectives and background of patrol inspection , This paper focuses on the evolution of applet patrol scheduling strategy , It is enough to see that the inspection work of online quality needs to be continuously constructed and honed . With the continuous development of business , Online resources will be richer , More diverse content , Page resources will continue to grow , We are bound to face greater challenges . How to efficiently from massive page resources 、 Accurately call back the risk problems on the line , It is always the thinking goal of patrol dispatching strategy . We will continue to explore 、 Optimize , Unswervingly escort the growing smart applet business .
Recommended reading :
Mobile heterogeneous computing technology -GPU OpenCL Programming ( The basic chapter )
Cloud native enablement development test
be based on Saga Implementation of distributed transaction scheduling
Spark Design and implementation of offline development framework
Implementation of Aifan micro front-end framework
Baidu official technology number 「 Baidu Geek say 」 Online !
Technical dry cargo · Industry information · Online Salon · Industry Conference
Recruitment information · Push information inside · Technical books · Around Baidu
Welcome to Baidu Geek say !
边栏推荐
- [reading notes] Figure comparative learning gnn+cl
- Oracle combines multiple rows of data into one row of data
- TDengine 离线升级流程
- 一文读懂TDengine的窗口查询功能
- 百度评论中台的设计与探索
- [sorting of object array]
- C form click event did not respond
- 分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
- 【ManageEngine】如何利用好OpManager的报表功能
- LeetCode 556. 下一个更大元素 III
猜你喜欢
![[ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)](/img/78/d9d1a66fc239e7c62de1fce426d30d.jpg)
[ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)
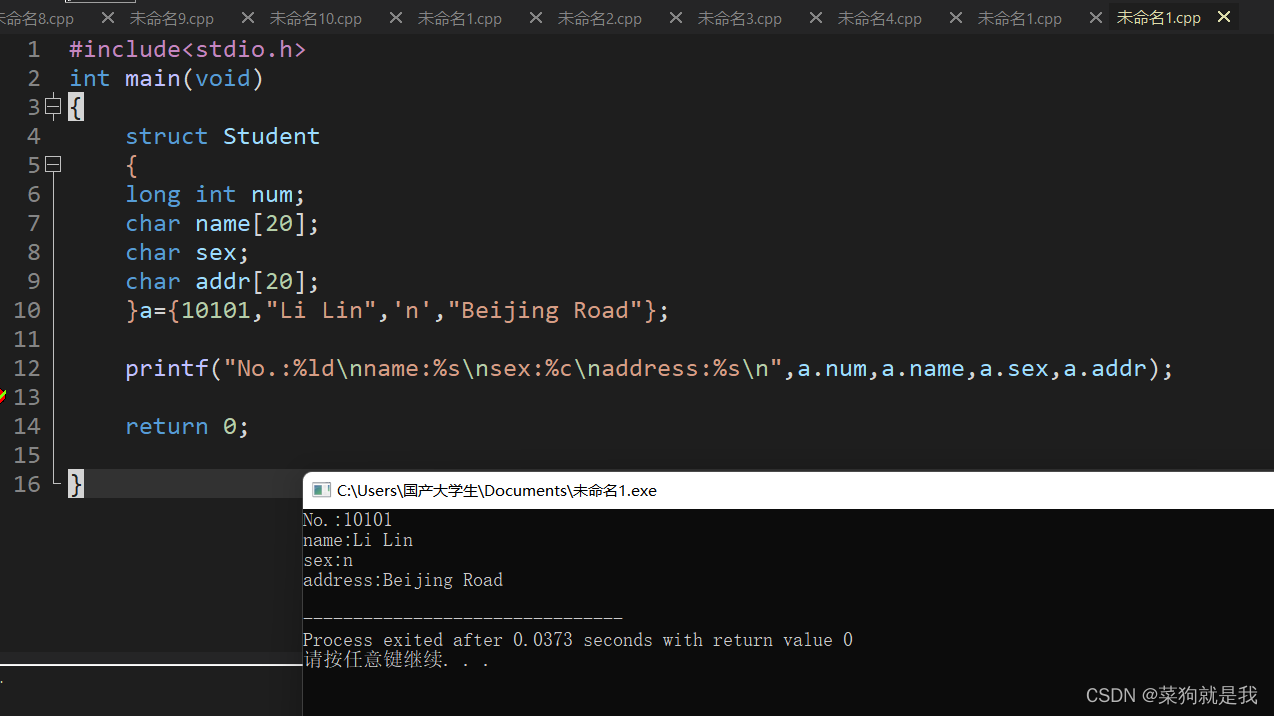
初识结构体
![[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details

Community group buying exploded overnight. How should this new model of e-commerce operate?
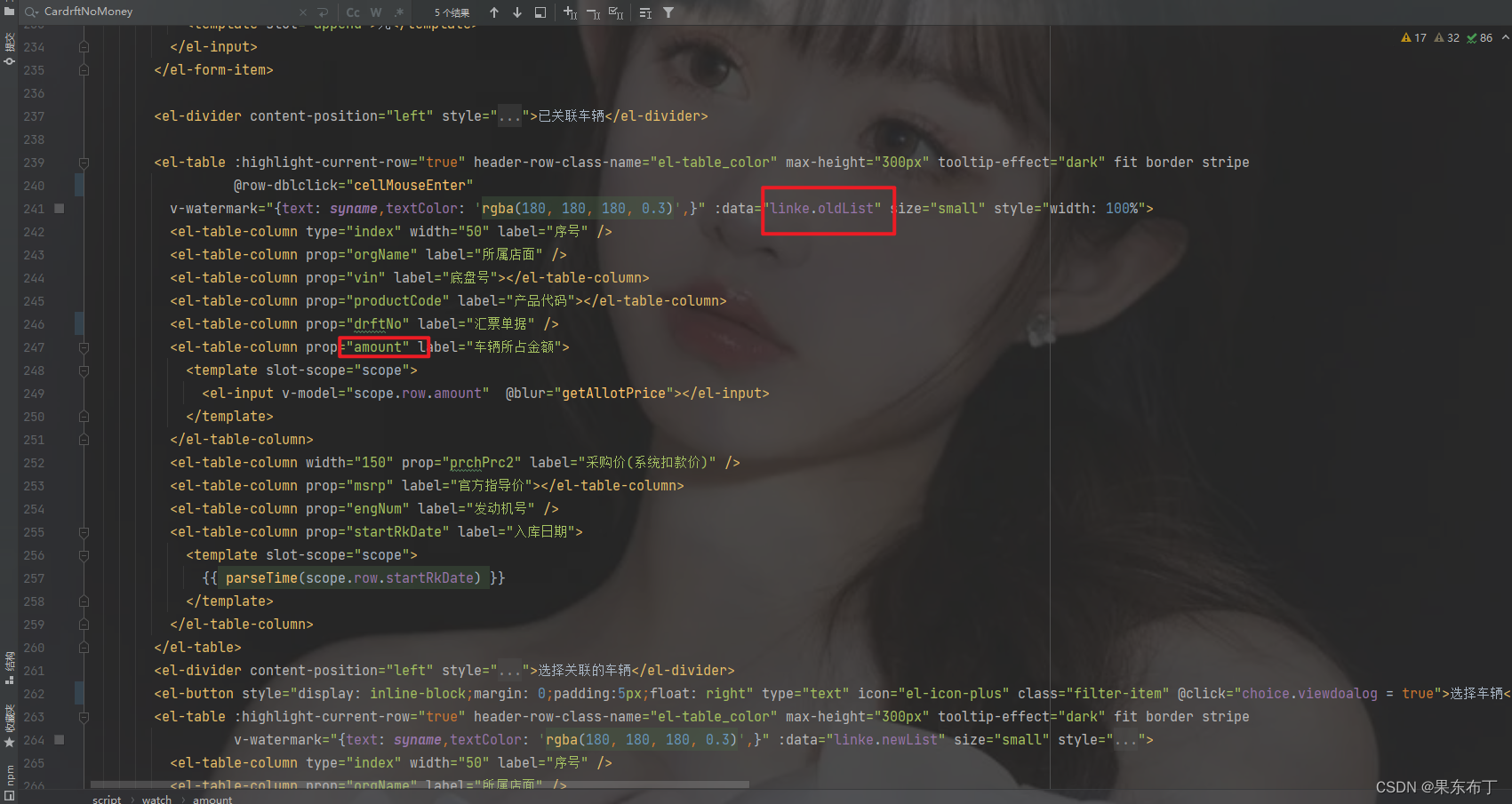
【数组的中的某个属性的监听】
A keepalived high availability accident made me learn it again

How do enterprises choose the appropriate three-level distribution system?
使用el-upload封装得组件怎么清空已上传附件

H.265编码原理入门

顶会论文看图对比学习(GNN+CL)研究趋势
随机推荐
Kotlin introductory notes (III) kotlin program logic control (if, when)
一篇文章带你走进cookie,session,Token的世界
How to improve the operation efficiency of intra city distribution
写入速度提升数十倍,TDengine 在拓斯达智能工厂解决方案上的应用
[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details
搞数据库是不是越老越吃香?
【ManageEngine】如何利用好OpManager的报表功能
LeetCode 496. 下一个更大元素 I
正式上架!TDengine 插件入驻 Grafana 官网
Online chain offline integrated chain store e-commerce solution
Unity SKFramework框架(二十四)、Avatar Controller 第三人称控制
移动端异构运算技术-GPU OpenCL编程(进阶篇)
Cloud computing technology hotspot
[hungry dynamic table]
The popularity of B2B2C continues to rise. What are the benefits of enterprises doing multi-user mall system?
【两个对象合并成一个对象】
TDengine 连接器上线 Google Data Studio 应用商店
Idea debugs com intellij. rt.debugger. agent. Captureagent, which makes debugging impossible
STM32简易多级菜单(数组查表法)
TDengine 已经支持工业英特尔 边缘洞见软件包