当前位置:网站首页>揭秘百度智能测试在测试自动执行领域实践
揭秘百度智能测试在测试自动执行领域实践
2022-07-05 09:27:00 【百度Geek说】

上一篇,介绍了测试活动测试输入、测试执行、测试分析、测试定位和测试评估五个步骤中测试输入智能化研究和实践,包含异常单测生成、接口用例生成、动作集生成等研究与实践。本章节重点介绍测试执行环节的智能化实践。测试执行是指将测试生成的用例集、数据集利用手动和自动化的方式对这些集合运行,测试执行本质上不能提升揭错水平,但如何高效稳定的执行完测试集合也是影响测试效果的关键。
测试执行智能化通过将数据、算法、工程等相关技术有机结合,一般包含测试用例推荐、测试流量筛选、测试任务调度、智能构建、执行自愈等方面,在学术界和工业界均有非常优秀的研究和实践。方法论上一般包含基于覆盖率相关性选择算法、基于数据建模或两者结合的方式。本章节将从多个实践的角度,介绍相关领域的目标、思路、涉及到的技术点、效果,希望能给到大家一定参考。
01 基于风险的手工用例推荐
测试执行,因为代码变化、环境等因素,往往不需要执行全部的用例,如何在用例全集中找到最有可能揭错的用例,是本方向的研究领域,也是业绩研究最多的领域。
手工测试用例推荐主要指通过代码变更推荐出关联手工用例,一个关键目标是希望能精选覆盖度高的用例组合,尽早发现问题。直接使用代码覆盖率关联推荐,会出现公共函数关联的多个用例将被冗余推荐,执行效率低,也不利于问题的及时发现。因此引入基于风险的手工用例推荐,优先根据风险代码推荐用例,更为精准。首先,数字化度量代码,将代码抽象为语法树,抽取了代码环路、分支信等21个可以反映设计复杂度和程序开发难度的指标;其次,选取合适的模型进行推理,获取针对代码的有缺陷预测和无缺陷预测,获取关联的用例;最后,排序去重,选取预测有缺陷的结果和无缺陷中重要程度比较高的用例作为推荐结果。其中,缺陷推理可使用贝叶斯分类、SVM、KNN、逻辑回归等算法,也可以向深度学习转移,结合长短期记忆模型(LSTM)和深度神经网络(DNN)进行缺陷预测。落地该方案后,用例推荐比持续下降由50%压缩到20%,回归天数由3天降低到1天,推荐发现bug的用例比例持续提高。
02 基于并行覆盖率的流量筛选方案
在测试过程中,经常会遇到利用线上流量对系统进行diff、性能和压测,如何从线上海量的流量选取最合适的流量进行测试,是本课题研究的关键。
并行覆盖率的流量筛选方案,是为了能够从海量的线上流量中,找出覆盖最多测试场景较小的流量集,从而达到测试覆盖场景,减少问题的漏出,保障系统的稳定性的目的。在传统场景下,通常不可能把线上全流量的数据照搬到线下,因为量级太大,所以会有一些筛选方案;最常用的就是根据机房、时间等属性随机抽样,尽量提升抽样的覆盖面,但是这样随机性太强,不确定最终业务和场景的覆盖面。基于并行覆盖率的流量筛选方案主要在覆盖率的指引下,尽量减少流量的量级,提升业务的覆盖。主要分为两个步骤:通过对源日志进行分析,进行流量初筛,经典场景有通过设备,地域,用户属性等,筛选可以覆盖这些场景的最小集,在第一步可以通过日志初筛出大部分有意义的流量。第二步通过对于发压流量的覆盖率进行分析,使用贪心算法,针对不同流量的覆盖率进行分析,通过尽可能少的流量覆盖尽可能多的场景。以上两点,可以从业务实际场景和覆盖率两个方面结合一起提升流量筛选的覆盖面。目前已经多个产品线和模块应用,在覆盖率无损,甚至提升60%前提下,流量缩减了一半,提升效率的前提下也保证的流量的覆盖。
03 智能构建
智能构建致力于在静态CI任务编排中动态执行任务,实现任务精简、任务跳过、任务取消、结果复用、自愈、自动标注等功能,保障测试任务高效稳定构建完成。在日常的变更中,可能经常遇到以下场景:
1、变更仅修改了日志、格式或不重要的一些功能,这时是否有必要回归全量测试任务;
2、代码反复迭代,同一任务执行多次是否有必要;
3、同一次任务在分支和主干阶段是否有必要重复运行。
传统做法是执行全量任务,但会导致测试构建效率低,资源消耗大。
利用智能构建就可以根据变更场景动态调整构建任务,有效缩短构建时间,提升构建效率。具体来说,智能构建可拆分为分析和决策两部分,分析是针对业务代码库,以及本次变更(如git diff),利用工具算出进行本次变更的特征分析(变更代码行数、变更代码的具体函数、变更代码的调用链信息等等);决策任务是否执行/等待/重启/取消等行为,做出最终的决策,比如业务设置业务相关的的白名单,若分析特征全命中白名单则可跳过指定任务;智能构建是在保障测试用例揭错能力的前提下,利用有限的资源满足用户对时效性的需求。目前百度已创建包含策略开发、插件方、业务线在内的智能构建体系,其中策略开发者按照构建系统接口规范开发策略,并将策略注册进入构建系统,构建系统开放策略给业务方使用;插件通过构建策略进行响应操作,如无效任务的取消执行、偶发任务的自愈、流程管控任务的拦截等;业务方则通过构建系统进行流水线上策略的配置;目前智能构建已辐射3000+个模块。
04 基于任务优先级的算法调度
本方向研究的是如何在有限的资源情况下,根据稳定性和揭错能力调度测试任务。
在测试执行阶段,在有限的资源下大量的并行测试任务调度困难,由于用户感知的等待时间是所有测试任务的排队时间和执行时间,不合理的测试调度会导致测试效率的低下。因此探索一种基于任务优先级的算法调度策略用以解决上述问题。
在移动端测试中,针对大量并行任务提交,建立任务优先级队列。根据任务重要程度,等待时间,资源需求,生成了有益于降低重点任务排队时间的优先级公式。基于公式分析结果,优化测试任务调度。在保证平均排队时间的情况,降低重点任务的平均排队时间。
针对单个case任务的执行效率,最初我们基于离线历史任务分组的时长,单位时间覆盖率等数据,寻找最优收敛点用以预测任务的最佳停止时间,优化测试任务执行时长。效果上,核心产品线在覆盖率,问题发现数量未退化的情况下,执行时长缩短了10%,但仍存在无法感知任务实时状态问题,因此在此基础之上,建立停止决策模型,通过实时监控任务的执行情况,基于执行时间,截图数,测试控件覆盖变化率等特征,实时决策任务是否可达到停止状态,并识别出执行效果不佳的任务,提前终止,降低无效执行的耗时。在优化效果上,在测试覆盖率提高10%的同时,执行时长减少12%。
05 UI自动化自愈
App自动化用例在执行过程中,上下文环境会遇到各种非预期的复杂情况,如,App触发升级弹窗、页面加载缓慢出现白屏、页面xpath路径变更等。现有自动化运行机制,不具备处理这些异常边界情况的能力,导致Case执行中断而失败。这些自动化稳定性问题,带来自动化用例维护成本的增加,大大降低了自动化工作的ROI。我们分析现有自动化任务top失败原因,使用3类通用Case执行自愈技术,提升case执行稳定性,降低维护成本。
1、异常弹窗处理,当自动化执行遇到弹窗而失败后,使用弹窗检测技术去除弹窗后继续恢复执行。面对弹窗种类多样的难点,使用对象检测技术,实现泛化的弹窗及弹窗关闭控件的识别;面对不同语境下推荐动作不一致难点,利用基于页面文案进行弹窗分类的技术,实现不同场景下的弹窗都能够被准确理解,并推荐正确动作去除。
2、原子等待技术,自动化执行过程中的异步加载等待技术属于领域里公认技术瓶颈,我们利用视觉UI理解技术,在Case执行过程中,使用高效的视频流并行采集,以及图像识别算法对连续图片分析,实现页面稳定态和非稳定态的智能判定,指导Case实时的智能延迟等待和智能缩短等待时间,保证Case稳定高效执行。
3、通用Case自愈技术,提供基于时空上下文的Locator,去弹窗,图像等识别方式按顺序进行识别自愈,具体来讲,将历史执行成功时刻的xpath,icon图片等信息记录下来,当出现失败时,尝试用历史成功过的元素类型依次进行重试。
通过以上Case执行自愈的技术,在我们自动化执行实践过程中,实现了51%的Case自愈修复效果,有效提升自动化用例执行稳定性。
推荐阅读【技术加油站】系列:
边栏推荐
- 2311. Longest binary subsequence less than or equal to K
- Explain NN in pytorch in simple terms CrossEntropyLoss
- Principle and performance analysis of lepton lossless compression
- LeetCode 556. 下一个更大元素 III
- Newton iterative method (solving nonlinear equations)
- Kotlin introductory notes (V) classes and objects, inheritance, constructors
- Kotlin introductory notes (III) kotlin program logic control (if, when)
- A detailed explanation of the general process and the latest research trends of map comparative learning (gnn+cl)
- SQL learning - case when then else
- 基于STM32单片机的测温仪(带人脸检测)
猜你喜欢

LeetCode 556. 下一个更大元素 III

一篇文章带你走进cookie,session,Token的世界
Unity skframework framework (24), avatar controller third person control
C语言-从键盘输入数组二维数组a,将a中3×5矩阵中第3列的元素左移到第0列,第3列以后的每列元素行依次左移,原来左边的各列依次绕到右边
【数组的中的某个属性的监听】

AUTOSAR from getting started to mastering 100 lectures (103) -dbc file format and creation details
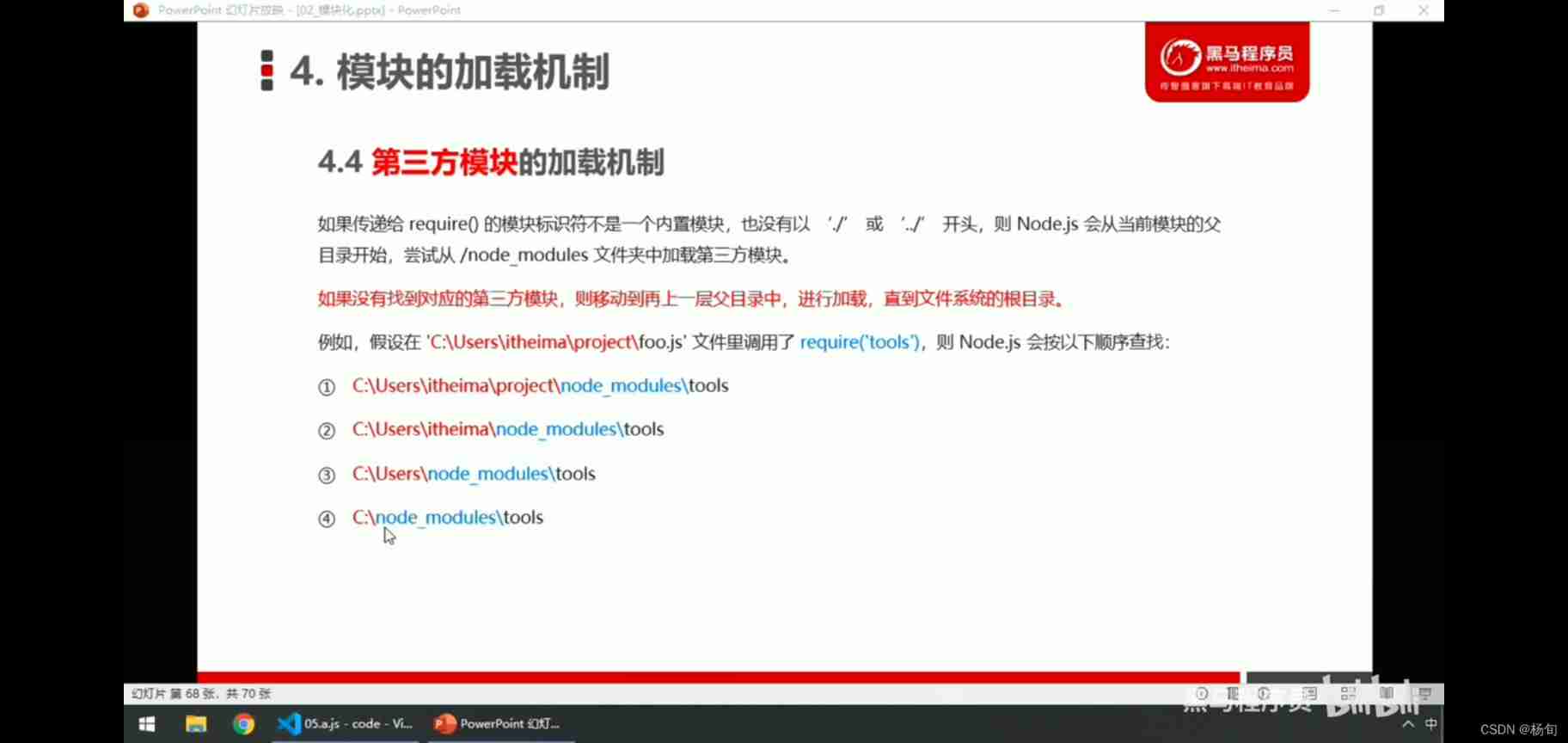
Nodejs modularization
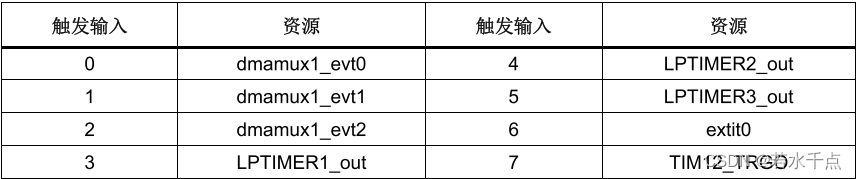
SMT32H7系列DMA和DMAMUX的一点理解
使用el-upload封装得组件怎么清空已上传附件
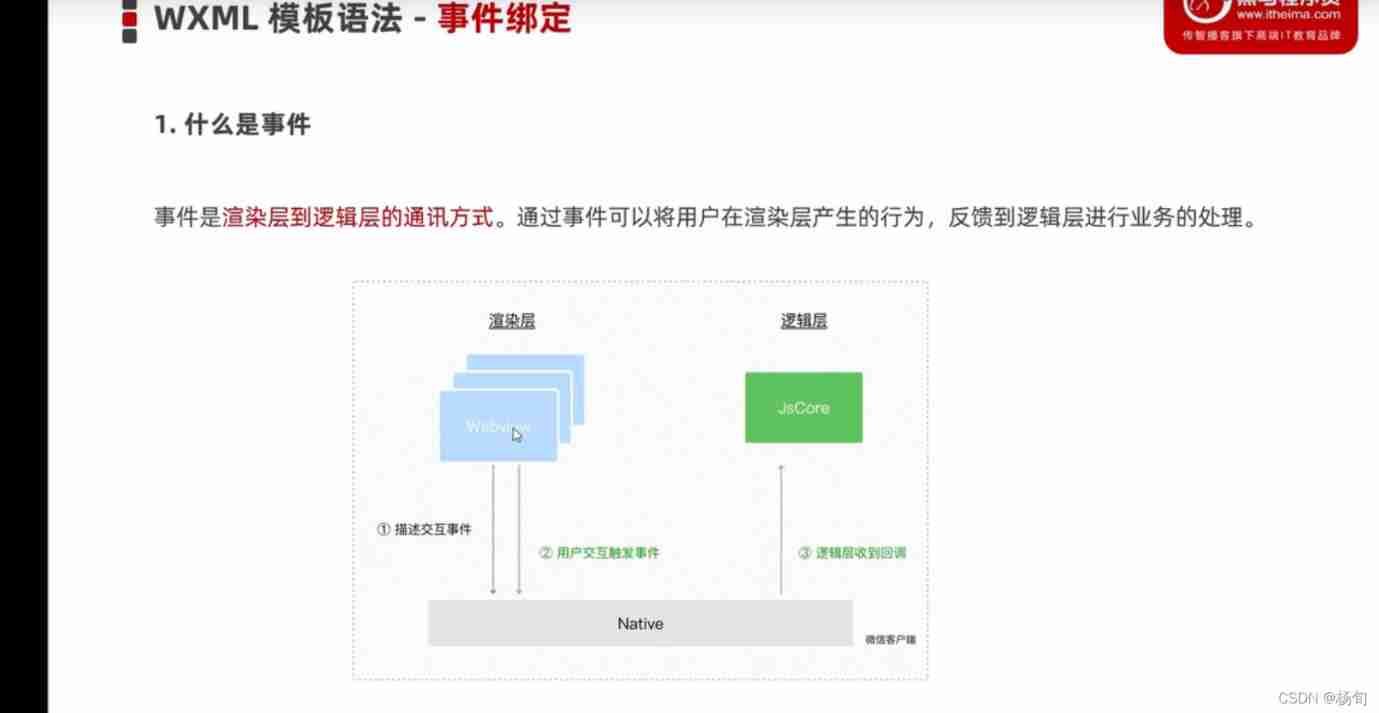
Wxml template syntax
随机推荐
Jenkins pipeline method (function) definition and call
High performance spark_ Transformation performance
Multiple solutions to one problem, asp Net core application startup initialization n schemes [Part 1]
Information and entropy, all you want to know is here
Can't find the activitymainbinding class? The pit I stepped on when I just learned databinding
Alibaba's ten-year test brings you into the world of APP testing
【js 根据对象数组中的属性进行排序】
Applet customization component
顶会论文看图对比学习(GNN+CL)研究趋势
Applet data attribute method
【对象数组的排序】
LeetCode 496. Next larger element I
LeetCode 31. Next spread
Progressive JPEG pictures and related
信息与熵,你想知道的都在这里了
22-07-04 西安 尚好房-项目经验总结(01)
Cloud computing technology hotspot
Huber Loss
Analysis of eventbus source code
Kotlin introductory notes (V) classes and objects, inheritance, constructors