当前位置:网站首页>代码重构:面向单元测试
代码重构:面向单元测试
2022-08-04 05:15:00 【软件测试网】
作者 | 杜沁园(悬衡)
重构代码时,我们常常纠结于这样的问题:
- 需要进一步抽象吗?会不会导致过度设计?
- 如果需要进一步抽象的话,如何进行抽象呢?有什么通用的步骤或者法则吗?
单元测试是我们常用的验证代码正确性的工具,但是如果只用来验证正确性的话,那就是真是 “大炮打蚊子”--大材小用,它还可以帮助我们评判代码的抽象程度与设计水平。本文还会提出一个以“可测试性”为目标,不断迭代重构代码的思路,利用这个思路,面对任何复杂的代码,都能逐步推导出重构思路。为了保证直观,本文会以一个 “生产者消费者” 的代码重构示例贯穿始终。最后还会以业务上常见的 Excel 导出系统为例简单阐述一个业务上的重构实例。阅读本文需要具有基本的单元测试编写经验(最好是 Java),但是本文不会涉及任何具体的单元测试框架和技术,因为它们都是不重要的,学习了本文的思路,可以将它们用在任意的单测工具上。
不可测试的代码
程序员们重构一段代码的动机是什么?可能众说纷纭:
- 代码不够简洁?
- 不好维护?
- 不符合个人习惯?
- 过度设计,不好理解?
这些都是比较主观的因素,在一个老练程序员看来恰到好处的设计,一个新手程序员却可能会觉得过于复杂,不好理解。但是让他们同时坐下来为这段代码添加单元测试时,他们往往能够产生类似的感受,比如
- “单测很容易书写,很容易就全覆盖了”,那么这就是可测试的代码;
- “虽然能写得出来,但是费了老大劲,使用了各种框架和技巧,才覆盖完全”,那么这就是可测试性比较差的代码;
- “完全不知道如何下手写”,那么这就是不可测试的代码;
一般而言,可测试的代码一般都是同时是简洁和可维护的,但是简洁可维护的代码却不一定是可测试的,比如下面的“生产者消费者”代码就是不可测试的:
上面这段代码做的事情非常简单,启动两个线程:
- 生产者:将 0-9 的每个数字,分别加上 [0,100) 的随机数后通过阻塞队列传递给消费者;
- 消费者:从阻塞队列中获取数字并打印;
这段代码看上去还是挺简洁的,但是,算得上一段好代码吗?尝试下给这段代码加上单元测试。仅仅运行一下这个代码肯定是不够的,因为我们无法确认生产消费逻辑是否正确执行。我也只能发出“完全不知道如何下手”的感叹,这不是因为我们的单元测试编写技巧不够,而是因为代码本身存在的问题:1、违背单一职责原则:这一个函数同时做了 数据传递,处理数据,启动线程三件事情。单元测试要兼顾这三个功能,就会很难写。2、这个代码本身是不可重复的,不利于单元测试,不可重复体现在
需要测试的逻辑位于异步线程中,对于它什么时候执行?什么时候执行完?都是不可控的;
逻辑中含有随机数;
消费者直接将数据输出到标准输出中,在不同环境中无法确定这里的行为是什么,有可能是输出到了屏幕上,也可能是被重定向到了文件中;
因为第 2 点的原因,我们就不得不放弃单测了呢?其实只要通过合理的模块职责划分,依旧是可以单元测试。这种划分不仅仅有助于单元测试,也会“顺便”帮助我们抽象一套更加合理的代码。
可测试意味着什么?
所有不可测试的代码都可以通过合理的重构与抽象,让其核心逻辑变得可测试,这也重构的意义所在。本章就会详细说明这一点。
首先我们要了解可测试意味着什么,如果说一段代码是可测试的,那么它一定符合下面的条件:
- 可以在本地设计完备的测试用例,称之为 完全覆盖的单元测试;
- 只要完全覆盖的单元测试用例全部正确运行,那么这一段逻辑肯定是没有问题的;
第 1 点常会令人感到难以置信,但事实比想象的简单,假设有这样一个分段函数:

f(x) 看起来有无限的定义域,我们永远无法穷举所有可能的输入。但是再仔细想想,我们并不需要穷举,其实只要下面几个用例可以通过,那么就可以确保这个函数是没有问题的:
- <-50
f(-51) == -100
- [-50, 50]
f(-25) == -50
f(25) == 50
- >50
f(51) == 100
- 边界情况
f(-50) == -100
f(50) == 100
日常工作中的代码当然比这个复杂很多,但是没有本质区别,也是按照如下思路进行单元测试覆盖的:
- 每一个分段其实就是代码中的一个条件分支,用例的分支覆盖率达到了 100%;
- 像 2x 这样的逻辑运算,通过几个合适的采样点就可以保证正确性;
- 边界条件的覆盖,就像是分段函数的转折点;
但是业务代码依旧比 f(x) 要复杂很多,因为 f(x) 还有其他好的性质让它可以被完全测试,这个性质被称作引用透明:
- 函数的返回值只和参数有关,只要参数确定,返回值就是唯一确定的
现实中的代码大多都不会有这么好的性质,反而具有很多“坏的性质”,这些坏的性质也常被称为副作用:
- 代码中含有远程调用,无法确定这次调用是否会成功;
- 含有随机数生成逻辑,导致行为不确定;
- 执行结果和当前日期有关,比如只有工作日的早上,闹钟才会响起;
- 好在我们可以用一些技巧将这些副作用从核心逻辑中抽离出来。
高阶函数
“引用透明” 要求函数的出参由入参唯一确定,之前的例子容易让人产生误解,觉得出参和入参一定要是数据,让我们把视野再打开一点,出入参可以是一个函数,它也可以是引用透明的。
普通的函数又可以称作一阶函数,而接收函数作为参数,或者返回一个函数的函数称为高阶函数,高阶函数也可以是引用透明的。
对于函数 f(x) 来说,x 是数据还是函数,并没有本质的不同,如果 x 是函数的话,仅仅意味着 f(x) 拥有更加广阔的定义域,以至于没有办法像之前一样只用一个一维数轴表示。
对于高阶函数 f(g) (g 是一个函数)来说,只要对于特定的函数 g,返回逻辑也是固定,它就是引用透明的了, 而不用在乎参数 g 或者返回的函数是否有副作用。利用这个特性,我们很容易将一个有副作用的函数转换为一个引用透明的高阶函数。
一个典型的拥有副作用的函数如下:
它生成了随机数并且加 1,因为这个随机数,导致它不可测试。但是我们将它转换为一个可测试的高阶函数,只要将随机数生成逻辑作为一个参数传入,并且返回一个函数即可:
上面的 g 就是一个引用透明的函数,只要给 g 传递一个数字生成器,返回值一定是一个 “用数字生成器生成一个数字并且加1” 的逻辑,并且不存在分支条件和边界情况,只需要一个用例即可覆盖:
实际业务中可以稍微简化一下高阶函数的表达, g 的返回的函数既然每次都会被立即执行,那我们就不返回函数了,直接将逻辑写在方法中,这样也是可测试的:
这里我虽然使用了 Lambda 表达式简化代码,但是 “函数” 并不仅仅是指 Lambda 表达式,OOP 中的充血模型的对象,接口等等,只要其中含有逻辑,它们的传递和返回都可以看作 “函数”。
因为这个例子比较简单,“可测试” 带来的收益看起来没有那么高,真实业务中的逻辑一般比 +1 要复杂多了,此时如果能构建有效的测试将是非常有益的。
面向单测的重构
第一轮重构
我们本章回到开头的生产者消费者的例子,用上一章学习到的知识对它进行重构。那段代码无法测试的第一个问题就是职责不清晰,它既做数据传递,又做数据处理。因此我们考虑将生产者消费者数据传递的代码单独抽取出来:
这一段代码的职责就很清晰了,我们给这个方法编写单元测试的目标也十分明确,即验证数据能够正确地从生产者传递到消费者。但是很快我们又遇到了之前提到的第二个问题,即异步线程不可控,会导致单测执行的不稳定,用上一章的方法,我们将执行器作为一个入参抽离出去:
这时我们就为它写一个稳定的单元测试了:
只要这个测试能够通过,就能说明生产消费在逻辑上是没有问题的。一个看起来比之前的分段函数复杂很多的逻辑,本质上却只是它定义域上的一个恒等函数(因为只要一个用例就能覆盖全部情况),是不是很惊讶。如果不太喜欢上述的函数式编程风格,可以很容易地将其改造成 OOP 风格的抽象类,就像上一章提到的,传递对象和传递函数没有本质的区别:
此时单元测试就会像是这个样子:
看到这些类,熟悉设计模式的读者们一定会想到 “模板方法模式”,但是我们在上面的过程从来没有刻意去用任何设计模式,正确的重构就会让你在无意间 “重新发现” 这些常用的设计模式,一般这种情况下,设计模式的使用都是正确的,因为我们一直在把代码往更加可测试的方向推荐,而这也是衡量设计模式是否使用正确的重要标准,错误的设计模式使用则会让代码更加的割裂和不可测试,后文讨论“过度设计”这个主题时会进一步深入讨论这一部分内容。
很显然这种测试无法验证多线程运行的情况,但我故意这么做的,这部分单元测试的主要目的是验证逻辑的正确性,只有先验证逻辑上的正确性,再去测试并发才比较有意义,在逻辑存在问题的情况下就去测试并发,只会让问题隐藏得更深,难以排查。一般开源项目中会有专门的单元测试去测试并发,但是因为其编写代价比较大,运行时间比较长,数量会远少于逻辑测试。
经过第一轮重构,主函数变成了这个样子(这里我最终采用了 OOP 风格):
在第一轮重构中,我们仅仅保障了数据传递逻辑是正确的,在第二轮重构中,我们还将进一步扩大可测试的范围。
第二轮重构
代码中影响我们进一步扩大测试范围因素还有两个:
- 随机数生成逻辑
- 打印逻辑
只要将这两个逻辑像之前一样抽出来即可:
这次采用 OOP 和 函数式 混编的风格,也可以考虑将 numberGenerator 和 numberConsumer 两个方法参数改成抽象方法,这样就是更加纯粹的 OOP。它也只需要一个测试用例即可实现完全覆盖:
此时主函数变成:
经过两轮重构,我们将一个很随意的面条代码重构成了很优雅的结构,除了更加可测试外,代码也更加简洁抽象,可复用,这些都是面向单测重构所带来的附加好处。
你可能会注意到,即使经过了两轮重构,我们依旧不会直接对主函数 producerConsumer 进行测试,而只是无限接近覆盖里面的全部逻辑,因为我认为它不在“测试的边界”内,我更倾向于用集成测试去测试它,集成测试则不在本篇文章讨论的范围内。下一章则重点讨论测试边界的问题。
单元测试的边界
边界内的代码都是单元测试可以有效覆盖到的代码,而边界外的代码则是没有单元测试保障的。
上一章所描述的重构过程本质上就是一个在探索中不断扩大测试边界的过程。但是单元测试的边界是不可能无限扩大的,因为实际的工程中必然有大量的不可测试部分,比如 RPC 调用,发消息,根据当前时间做计算等等,它们必然得在某个地方传入测试边界,而这一部分就是不可测试的。
理想的测试边界应该是这样的,系统中所有核心复杂的逻辑全部包含在了边界内部,然后边界外都是不包含逻辑的,非常简单的代码,比如就是一行接口调用。这样任何对于系统的改动都可以在单元测试中就得到快速且充分的验证,集成测试时只需要简单测试下即可,如果出现问题,一定是对外部接口的理解有误,而不是系统内部改错了。
清晰的单元测试边界划分有利于构建更加稳定的系统核心代码,因为我们在推进测试边界的过程中会不断地将副作用从核心代码中剥离出去,最终会得到一个完整且可测试的核心,就如同下图的对比一样:

重构的工作流
好代码从来都不是一蹴而就的,都是先写一个大概,然后逐渐迭代和重构的,从这个角度来说,重构别人的代码和写新代码没有很大的区别。从上面的内容中,我们可以总结出一个简单的重构工作流:

按照这个方法,就能够逐步迭代出一套优雅且可测试的代码,即使因为时间问题没有迭代到理想的测试边界,也会拥有一套大部分可测试的代码,后人可以在前人用例的基础上,继续扩大测试边界。
过度设计
最后再谈一谈过度设计的问题。按照本文的方法是不可能出现过度设计的问题,过度设计一般发生在为了设计而设计,生搬硬套设计模式的场合,但是本文的所有设计都有一个明确的目的--提升代码的“可测试性”,所有的技巧都是在过程中无意使用的,不存在生硬的问题。而且过度设计会导致“可测试性”变差,过度设计的代码常常是把自己的核心逻辑都给抽象掉了,导致单元测试无处可测。如果发现一段代码“写得很简洁,很抽象,但是就是不好写单元测试”,那么大概率是被过度设计了。另外一种过度设计是因为过度依赖框架而无意中导致的,Java 往往习惯于将自己的设计耦合进 Spring 框架中,比如将一段完整的逻辑拆分到几个 Spring Bean 中,而不是使用普通的 Java 类,导致根本就无法在不启动容器的情况下进行完整的测试,最后只能写一堆无效的测试提升“覆盖率”。这也是很多人抱怨“单元测试没有用”的原因。
和 TDD 的区别
本文到这里都还没有提及到 TDD,但是上文中阐述的内容肯定让不少读者想到了这个名词,TDD 是 “测试驱动开发” 的简写,它强调在代码编写之前先写用例,包括三个步骤:
- 红灯:写用例,运行,无法通过用例
- 绿灯:用最快最脏的代码让测试通过
- 重构:将代码重构得更加优雅
在开发过程中不断地重复这三个步骤。但是会实践中会发现,在繁忙的业务开发中想要先写测试用例是很困难的,可能会有以下原因:
代码结构尚未完全确定,出入口尚未明确,即使提前写了单元测试,后面大概率也要修改
产品一句话需求,外加对系统不够熟悉,用例很难在开发之前写好
因此本文的工作流将顺序做了一些调整,先写代码,然后再不断地重构代码适配单元测试,扩大系统的测试边界。不过从更广义的 TDD 思想上来说,这篇文章的总体思路和 TDD 是差不多的,或者标题也可以改叫做 “TDD 实践”。
业务实例 - 导出系统重构
钉钉审批的导出系统是一个专门负责将审批单批量导出成 Excel 的系统:

大概步骤如下:
- 启动一个线程,在内存中异步生成 Excel
- 上传 Excel 到钉盘/oss
- 发消息给用户
钉钉审批导出系统比常规导出系统要更加复杂一些,因为它的表单结构并不是固定的。而用户可以通过设计器灵活配置:

从上面可以看出单个审批单还具有复杂的内部结构,比如明细,关联表单等等,而且还能相互嵌套,因此逻辑很十分复杂。
我接手导出系统的时候,已经维护两年了,没有任何测试用例,代码中导出都是类似 patchXxx 的方法,可见在两年的岁月中,被打了不少补丁。系统虽然总体能用,但是有很多小 bug,基本上遇到边界情况就会出现一个 bug(边界情况比如明细里只有一个控件,明细里有关联表单,而关联表单里又有明细等等)。代码完全不可测试,完成的逻辑被 Spring Bean 隔离成一小块,一小块,就像下图一样:

我决定将这些代码重构,不能让它继续荼毒后人,但是面对一团乱麻的代码完全不知道如何下手(以下贴图仅仅是为了让大家感受下当时的心情,不用仔细看):

我决定用本文的工作流对代码进行重新梳理。
确定测试边界
首先需要确定哪些部分是单元测试可以覆盖到的,哪些部分是不需要覆盖到的,靠集成测试保证的。经过分析,我认为导出系统的核心功能,就是根据表单配置和表单数据生成 excel 文件:

这部分也是最核心,逻辑也最复杂的部分,因此我将这一部分作为我的测试边界,而其他部分,比如上传,发工作通知消息等放在边界之外:

图中 “表单配置” 是一个数据,而 “表单数据” 其实是一个函数,因为导出过程中会不断批量分页地去查询数据。
不断迭代,扩大测试边界到理想状态
我迭代的过程如下:
- 异步执行导致不可测试:抽出一个同步的函数;
- 大量使用 Spring Bean 导致逻辑割裂:将逻辑放到普通的 Java 类或者静态方法中;
- 表单数据,流程与用户的相关信息查询是远程调用,含有副作用:通过高阶函数将这些副作用抽出去;
- 导入状态落入数据库,也是一个副作用:同样通过高阶函数将其抽象出去;
最终导出的测试边界大约是这个样子:
- config:数据,表单配置信息,含有哪些控件,以及控件的配置
- dataService: 函数,用于批量分页查询表单数据的副作用
- statusStore: 函数,用于变更和持久化导出的状态的副作用

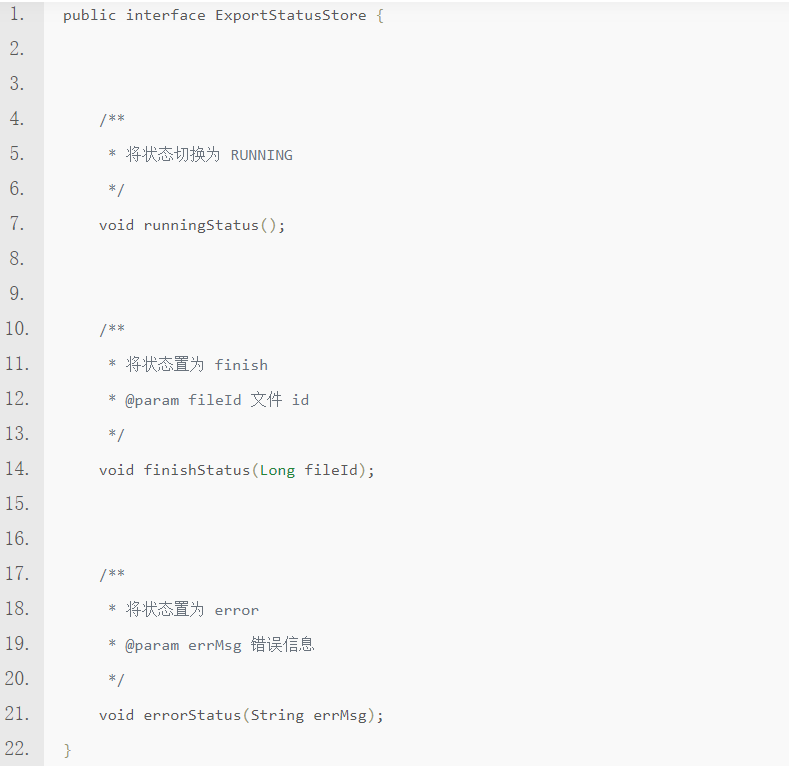
在本地即可验证生成的 Excel 文件是否正确(代码经过简化):
其中 LocalDataService,LocalStatusStore 分别是内存中的数据服务,和状态变更服务实现,用于进行单元测试。assertExcelContent 是我用 poi 写的一个工具方法,用于测试内存中的 excel 文件是否符合预期。所有边界的用例都可以直接在本地测试和沉淀用例。
最终的代码结构大约如下(经过简化):

虽然到现在为止我的目的都是提升代码的可测试性,但是实际上我一不小心也提升了代码的拓展性,在完全没有相关产品需求的情况下:
- 通过 DataService 的抽象,系统可以支持多种数据源导出,比如来自搜索,或者来自 db 的,只要传入不同的 DataService 实现即可,完全不需要改动和性逻辑;
- ExportStatusStore 的抽象,让系统有能力使用不同的状态存储,虽然目前使用的是 db,但是也可以在不改核心逻辑的情况下轻松切换成 tair 等其他中间件;
果然在我重构后不久,就接到了类似的需求,比如要支持从不同的数据源导出。我们又新增了一个导出入口,这个导出状态是存储在不同的表中。每次我都暗自窃喜,其实这些我早就从架构上准备好了。
单元测试的局限性
虽然本文是一篇单元测试布道文章,前文也将单元测试说得“神通广大”,但是也不得不承认单元测试无法解决全部的问题。
单元测试仅仅能保证应该的代码逻辑是正确的,但是应用开发中还有很多更加要紧的事情,比如架构设计,中间件选型等等,很多系统 bug 可能不是因为代码逻辑,而是因为架构设计导致的,此时单元测试就无法解决。因此要彻底保障系统的稳健,还是需要从单元测试,架构治理,技术选项等多个方面入手。
另外一点也不得不承认,单元测试是有一定成本的,一套工作流完成的话,可能会有数倍于原代码量的单元测试,因此并不是所有代码都需要这样的重构,在时间有限的情况下,应该优先重构系统中核心的稳定的代码,在权衡好成本与价值的情况下,再开始动手。
最后,单元测试也是对人有强依赖的技术,侧重于前期预防,没有任何办法量化一个人单元测试的质量如何,效果如何,这一切都是出于工程自己内心的“工匠精神” 以及对代码的敬畏,相信读到最后的你,也一定有着一颗工匠的心吧。
边栏推荐
- There is an 8 hour difference between the docker installation of mysql and the host.
- redis中常见的面试题
- How to dynamically add script dependent scripts
- go module的介绍与应用
- 【21天学习挑战赛】顺序查找
- [Cocos] cc.sys.browserType可能的属性
- 看DevExpress丰富图表样式,如何为基金公司业务创新赋能
- 路网编辑器技术预研
- centos 安装postgresql13 指定版本
- [Evaluation model] Topsis method (pros and cons distance method)
猜你喜欢
![[One step in place] Jenkins installation, deployment, startup (complete tutorial)](/img/f2/15fb546eb864d7ff40b5507d5c7aa5.png)
[One step in place] Jenkins installation, deployment, startup (complete tutorial)
FPGA学习笔记——知识点总结
day13--postman接口测试

深度学习21天——卷积神经网络(CNN):实现mnist手写数字识别(第1天)

附加:对于“与数据表对应的实体类“,【面对MongoDB时,使用的@Id等注解】和【以前面对MySQL时,使用的@Id等注解】,是不同的;
编程大杂烩(三)
el-Select 选择器 底部固定
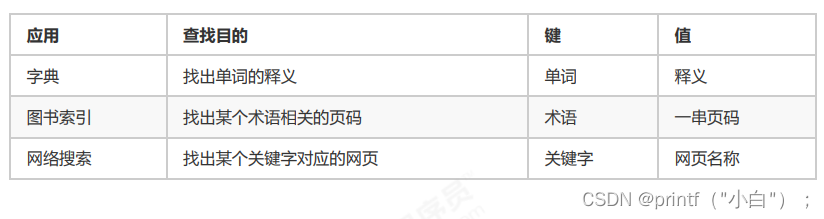
The symbol table
解决错误:npm WARN config global `--global`, `--local` are deprecated
Programming hodgepodge (4)
随机推荐
Typora 使用保姆级教程 | 看这一篇就够了 | 历史版本已被禁用
The 2022 PMP exam has been delayed, should we be happy or worried?
SLSA 框架与软件供应链安全防护
What are the steps for how to develop a mall system APP?
mysql index notes
深度学习21天——卷积神经网络(CNN):实现mnist手写数字识别(第1天)
结构体函数练习
ADC噪声全面分析 -03- 利用噪声分析进行实际设计
【一步到位】Jenkins的安装、部署、启动(完整教程)
[One step in place] Jenkins installation, deployment, startup (complete tutorial)
渗透测试(PenTest)基础指南
[Cocos 3.5.2]开启模型合批
解决错误:npm WARN config global `--global`, `--local` are deprecated
System design. Seckill system
烧录场景下开发如何进行源代码保密工作
share总结
System design. How to design a spike system (full version transfer)
心余力绌:企业面临的软件供应链安全困境
符号表
C专家编程 第4章 令人震惊的事实:数组和指针并不相同 4.1 数组并非指针