当前位置:网站首页>PyTorch Study Notes 08 - Loading Datasets
PyTorch Study Notes 08 - Loading Datasets
2022-07-31 06:32:00 【qq_50749521】
PyTorch学习笔记08——加载数据集

in the last diabetes dataset,We are using the entire datasetinput计算的.Consider this timemini_batch的输入方式.
三个概念:
epoch:All training samples are called one round at a timeepoch
Batch-Size:when batch training,The number of samples included in each batch
iteration:One pass per batch is called oneiteration
比如一个数据集有200个样本,divide him40块,Every piece has it5个样本.
那么batch = 40, batch_size = 5.
训练的时候,Train per block,put a piece5sample rounds,叫做1个itearion.
这40The blocks are all round again,就是200All samples are trained once,叫做1个epoch.
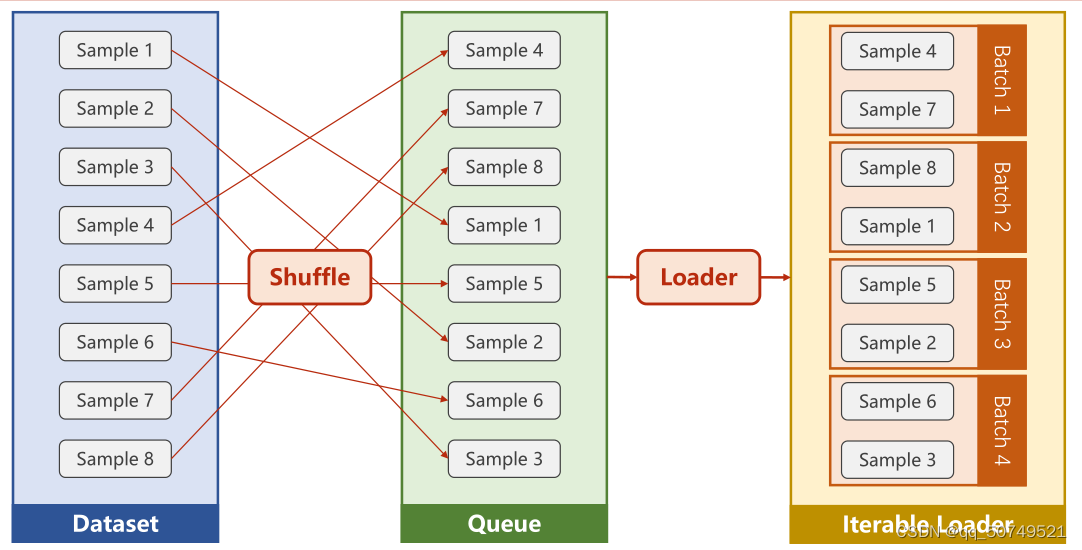
DataLoader:A way to load a dataset
What can he do for us?We are going to do mini-batch training,To improve the randomness of training,We can do it on the datasetshuffle.
When sending a dataset that supports index and length knowndataloader里,automatically correctdatasetGenerate small batches.
dataset -> Shuffle ->
Loader
How to define your datasetDataset?
Provide a conceptual code:
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 2)
Pytorch提供了一种Dataset类,This is an abstract class,We know that abstract classes cannot be instantiated,但可以被继承.
- 上面的DiabetesDatasetIt is an inheritance that we wrote ourselvesDataset的类.表达式getitem、lenAll are magic functions,Return the value and the length of the dataset, respectively.
- 实例化DiabetesDataset后,通过Dataloaderto automatically create mini-batch datasets. 这里用batch_size, shuffle,
process number来初始化.
batch_size = 32Determine the number of samples per batch,shuffle = TrueConfirm to scramble the dataset,num_workers = 2Indicates when this data will be read in the future,构成mini_batch的时候,Usually multithreading is used.Here, two threads are used to read data in parallel.CPUMore cores can be set a little more.
这样,We succeeded in getting the dataset the way we wantedtrain_loader,可以开始训练了~
for epoch in range(100):
for index, data in enumerate(train_loader, 0):
#index 返回的是batch(总样本数/batch_size)索引,data返回(inputs, labels)的张量数据
Mini-batch training on diabetes data,整个代码如下:
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter = ',', dtype = np.float32)#Directly read and store in memory
self.len = xy.shape[0] #样本数量
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]#返回元组
def __len__(self):
return self.len
dataset = DiabetesDataset('F:\ASR-source\Dataset\diabetes.csv.gz')
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 0)
batch_size = 32
batch = np.round(dataset.__len__() / batch_size)
batch
24.0
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
return x
mymodel = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(mymodel.parameters(), lr = 0.01)
epoch_list = []
loss_list = []
sum_loss = 0
if __name__ == '__main__':
for epoch in range(100):
for index, data in enumerate(train_loader, 0): #train_loader存的是分割组合后的小批量训练样本和对应的标签
inputs, labels = data #inputs labels都是张量
y_pred = mymodel(inputs)
loss = criterion(y_pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_loss += loss.item()
print('epoch = ', epoch + 1,'index = ', index+1, 'loss = ', loss.item())
epoch_list.append(epoch)
loss_list.append(sum_loss/batch)
print(sum_loss/batch)
sum_loss = 0
epoch = 1 index = 1 loss = 0.6523504257202148
epoch = 1 index = 2 loss = 0.6662447452545166
epoch = 1 index = 3 loss = 0.6510850191116333
epoch = 1 index = 4 loss = 0.622829794883728
epoch = 1 index = 5 loss = 0.6272122263908386
epoch = 1 index = 6 loss = 0.5990191102027893
epoch = 1 index = 7 loss = 0.6213780045509338
epoch = 1 index = 8 loss = 0.6761874556541443
epoch = 1 index = 9 loss = 0.6133689880371094
epoch = 1 index = 10 loss = 0.6413829326629639
epoch = 1 index = 11 loss = 0.6246744394302368
epoch = 1 index = 12 loss = 0.6163585782051086
epoch = 1 index = 13 loss = 0.599936306476593
epoch = 1 index = 14 loss = 0.6216733455657959
epoch = 1 index = 15 loss = 0.6504020094871521
epoch = 1 index = 16 loss = 0.6451072096824646
epoch = 1 index = 17 loss = 0.6215073466300964
epoch = 1 index = 18 loss = 0.6641662120819092
epoch = 1 index = 19 loss = 0.6364893317222595
epoch = 1 index = 20 loss = 0.6020426154136658
epoch = 1 index = 21 loss = 0.617006778717041
epoch = 1 index = 22 loss = 0.653681218624115
epoch = 1 index = 23 loss = 0.5835389494895935
epoch = 1 index = 24 loss = 0.6029499173164368
0.6296080400546392
epoch = 2 index = 1 loss = 0.6385740637779236
epoch = 2 index = 2 loss = 0.6440627574920654
epoch = 2 index = 3 loss = 0.6580216288566589
........

Replace with the following model,Iterate two hundred times,结果是这样的
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.relu = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))#注意最后一步不能使用relu,避免无法计算梯度
return x

边栏推荐
- Wangeditor rich text editor to upload pictures and solve cross-domain problems
- 2021-09-30
- Tensorflow——演示
- Cholesterol-PEG-Azide CLS-PEG-N3 Cholesterol-PEG-Azide MW:3400
- 使用 OpenCV 提取图像的 HOG、SURF 及 LBP 特征 (含代码)
- MW:3400 4-Arm PEG-DSPE 四臂-聚乙二醇-磷脂一种饱和的18碳磷脂
- Jupyter内核正忙、内核挂掉
- VS2017 connects to MYSQL
- 词向量——demo
- ROS之service传输图片
猜你喜欢

二进制转换成十六进制、位运算、结构体

The solution to the IDEA console not being able to enter information
Introduction to CLS-PEG-FITC Fluorescein-PEG-CLS Cholesterol-PEG-Fluorescein

After unicloud is released, the applet prompts that the connection to the local debugging service failed. Please check whether the client and the host are under the same local area network.
Four common ways of POST to submit data
unicloud cloud development record

朴素贝叶斯文本分类(代码实现)

cv2.imread()

活体检测PatchNet学习笔记

mPEG-DSPE 178744-28-0 Methoxy-polyethylene glycol-phosphatidylethanolamine linear PEG phospholipids
随机推荐
Cholesterol-PEG-Thiol CLS-PEG-SH Cholesterol-Polyethylene Glycol-Sulfhydryl
CAS:474922-22-0 Maleimide-PEG-DSPE Phospholipid-Polyethylene Glycol-Maleimide Brief Description
About iframe
会话和饼干,令牌
Pytorch实现ResNet
YOLOX中的SimOTA
深度学习知识点杂谈
cocos2d-x implements cross-platform directory traversal
OpenCV中的图像数据格式CV_8U定义
Tensorflow——演示
qt:cannot open C:\Users\XX\AppData\Local\Temp\main.obj.15576.16.jom for write
Jupyter内核正忙、内核挂掉
CNN的一点理解
JS写一段代码,判断一个字符串中出现次数最多的字符串,并统计出现的次数JS
pytorch学习笔记10——卷积神经网络详解及mnist数据集多分类任务应用
Phospholipids-Polyethylene Glycol-Active Esters for Scientific Research DSPE-PEG-NHS CAS: 1445723-73-8
wangeditor编辑器内容传至后台服务器存储
opencv之图像二值化处理
虚拟机查看端口号进程
DSPE-PEG-Azide DSPE-PED-N3 磷脂-聚乙二醇-叠氮脂质PFG