当前位置:网站首页>The worse the AI performance, the higher the bonus? Doctor of New York University offered a reward for the task of making the big model perform poorly
The worse the AI performance, the higher the bonus? Doctor of New York University offered a reward for the task of making the big model perform poorly
2022-07-07 04:31:00 【qubit 】
Yi Pavilion From the Aofei temple qubits | official account QbitAI
The bigger the model 、 The worse the performance, the better the prize ?
The total bonus is 25 Ten thousand dollars ( Renminbi conversion 167 ten thousand )?
such “ Out of line ” It really happened , A man named Inverse Scaling Prize( Anti scale effect Award ) The game of caused heated discussion on twitter .
The competition was organized by New York University 7 Jointly organized by researchers .
Originator Ethan Perez Express , The main purpose of this competition , It is hoped to find out which tasks will make the large model show anti scale effect , So as to find out some problems in the current large model pre training .
Now? , The competition is receiving contributions , The first round of submissions will end 2022 year 8 month 27 Japan .
Competition motivation
People seem to acquiesce , As the language model gets bigger , The operation effect will be better and better .
However , Large language models are not without flaws , For example, race 、 Gender and religious prejudice , And produce some fuzzy error messages .
The scale effect shows , With the number of parameters 、 The amount of computation used and the size of the data set increase , The language model will get better ( In terms of test losses and downstream performance ).
We assume that some tasks have the opposite trend : With the increase of language model testing loss , Task performance becomes monotonous 、 The effect becomes worse , We call this phenomenon anti scale effect , Contrary to the scale effect .
This competition aims to find more anti scale tasks , Analyze which types of tasks are prone to show anti scale effects , Especially those tasks that require high security .
meanwhile , The anti scale effect task will also help to study the potential problems in the current language model pre training and scale paradigm .
As language models are increasingly applied to real-world applications , The practical significance of this study is also increasing .
Collection of anti scale effect tasks , It will help reduce the risk of adverse consequences of large language models , And prevent harm to real users .
Netizen disputes
But for this competition , Some netizens put forward different views :
I think this is misleading . Because it assumes that the model is static , And stop after pre training . This is more a problem of pre training on standard corpora with more parameters , Not the size of the model .
Software engineer James Agree with this view :
Yes , This whole thing is a hoax . Anything a small model can learn , Large models can also . The deviation of the small model is larger , therefore “ Hot dogs are not hot dogs ” It may be recognized as 100% Right , When the big model realized that it could make cakes similar to hot dogs , The accuracy will drop to 98%.
James Even further proposed “ Conspiracy theories ” View of the :
Maybe the whole thing is a hoax —— Let people work hard , And show the training data when encountering difficult tasks , This experience will be absorbed by large models , Large models will eventually be better . So they don't need to give bonuses , You will also get a better large-scale model .
Regarding this , Originator Ethan Perez Write in the comment :
Clarify it. , The focus of this award is to find language model pre training that will lead to anti scale effect , Never or rarely seen category . This is just a way to use large models . There are many other settings that can lead to anti scale effects , Not included in our awards .
Rules of the game
According to the task submitted by the contestant , The team will build a system that contains at least 300 Sample datasets , And use GPT-3/OPT To test .
The competition will be selected by an anonymous jury .
The judges will start from the intensity of the anti scale effect 、 generality 、 Novelty 、 Reproducibility 、 Coverage and the importance of the task 6 There are three considerations , Conduct a comprehensive review of the submitted works , Finally, the first prize was awarded 、 Second and third prizes .
The bonus is set as follows :
The first prize is the most 1 position ,10 Ten thousand dollars ;
Most second prizes 5 position , Everyone 2 Ten thousand dollars ;
The third prize is the most 10 position , Everyone 5000 dollar .
The competition was held in 6 month 27 The day begins ,8 month 27 The first round of evaluation will be conducted on the th ,10 month 27 The second round of evaluation began on the th .
Originator Ethan Perez
Originator Ethan Perez Is a scientific researcher , Has been committed to the study of large-scale language models .
Perez Received a doctorate in natural language processing from New York University , Previously in DeepMind、Facebook AI Research、Mila( Montreal Institute of learning algorithms ) Worked with Google .
Reference link : 1、https://github.com/inverse-scaling/prize 2、https://twitter.com/EthanJPerez/status/1541454949397041154 3、https://alignmentfund.org/author/ethan-perez/
— End —
「 qubits · viewpoint 」 Live registration
What is? “ Intelligent decision making ”? What is the key technology of intelligent decision ? How will it build a leading enterprise for secondary growth “ Intelligent gripper ”?
7 month 7 On Thursday , Participate in the live broadcast , Answer for you ~
Focus on me here , Remember to mark the star ~
One key, three links 「 Share 」、「 give the thumbs-up 」 and 「 Looking at 」
The frontier of science and technology meets day by day ~
边栏推荐
- 主设备号和次设备号均为0
- 浙江大学周亚金:“又破又立”的顶尖安全学者,好奇心驱动的行动派
- Redis source code learning (30), dictionary learning, dict.h
- NanopiNEO使用开发过程记录
- Win11图片打不开怎么办?Win11无法打开图片的修复方法
- Pyqt5 out of focus monitoring no operation timer
- The easycvr platform is connected to the RTMP protocol, and the interface call prompts how to solve the error of obtaining video recording?
- leetcode 53. Maximum Subarray 最大子数组和(中等)
- 软件测试之网站测试如何进行?测试小攻略走起!
- 2022年电工杯B 题 5G 网络环境下应急物资配送问题思路分析
猜你喜欢
Ssm+jsp realizes the warehouse management system, and the interface is called an elegant interface
On the 110th anniversary of Turing's birth, has the prediction of intelligent machine come true?
AI landing new question type RPA + AI =?
![[ArcGIS tutorial] thematic map production - population density distribution map - population density analysis](/img/82/8f5b6f388d5676cb7ff902ba80d9d2.jpg)
[ArcGIS tutorial] thematic map production - population density distribution map - population density analysis
What if the win11 screenshot key cannot be used? Solution to the failure of win11 screenshot key

Deeply cultivate the developer ecosystem, accelerate the innovation and development of AI industry, and Intel brings many partners together
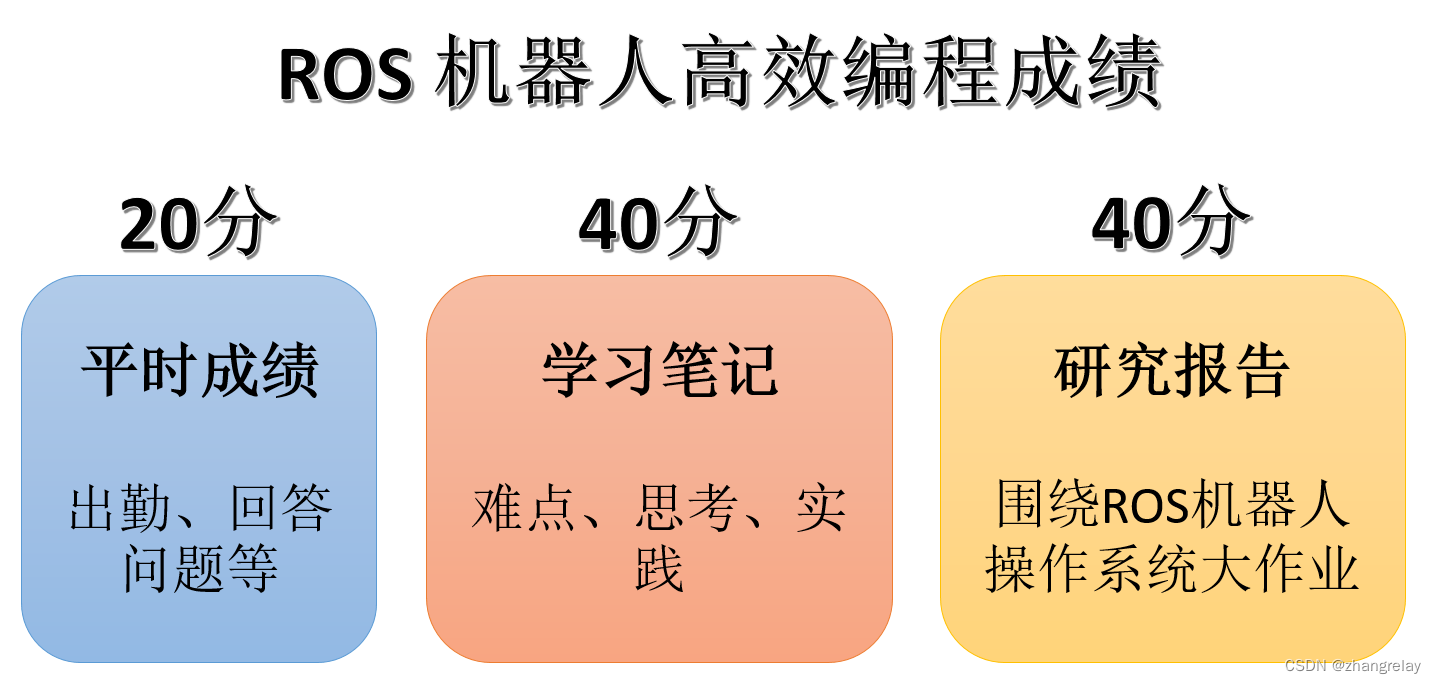
機器人(自動化)課程的持續學習-2022-
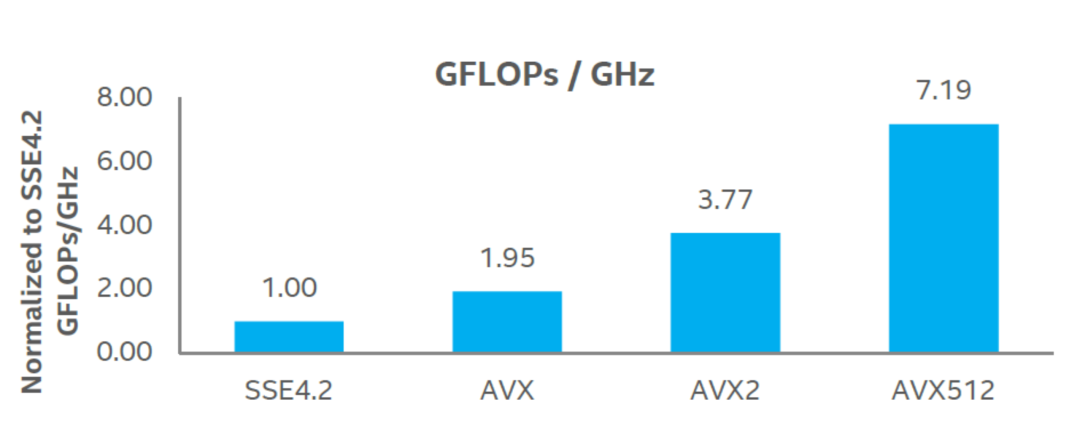
This "advanced" technology design 15 years ago makes CPU shine in AI reasoning
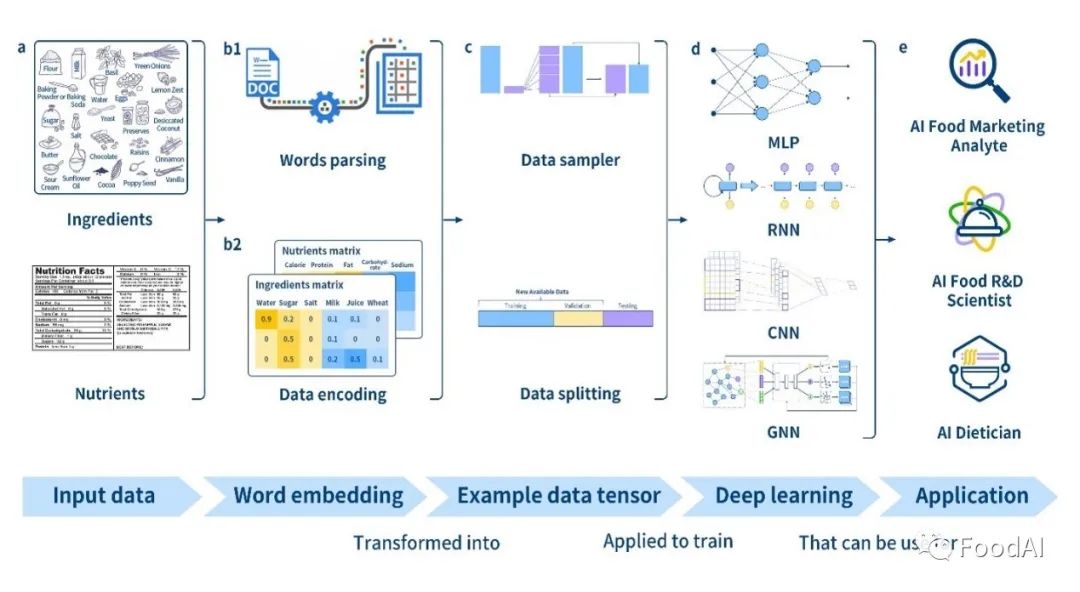
Food Chem|深度学习根据成分声明准确预测食品类别和营养成分
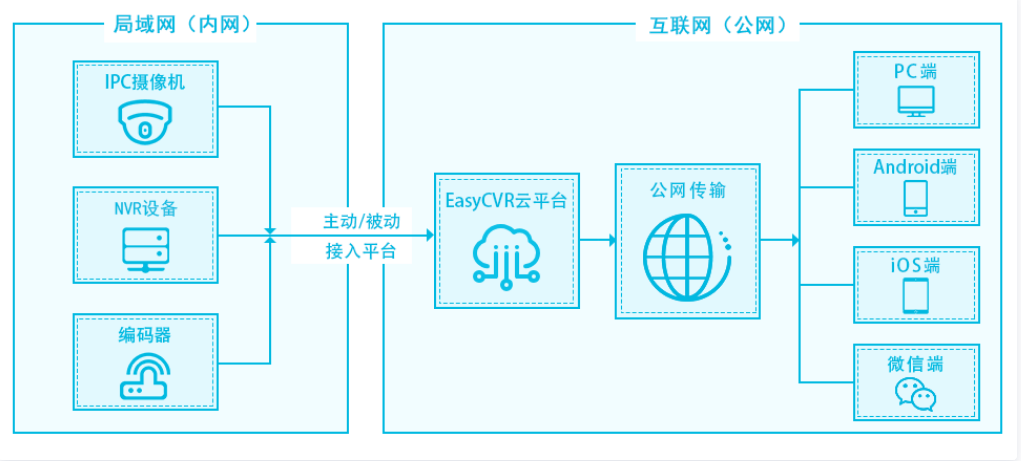
EasyCVR无法使用WebRTC进行播放,该如何解决?
随机推荐
案例大赏:英特尔携众多合作伙伴推动多领域AI产业创新发展
英特尔与信步科技共同打造机器视觉开发套件,协力推动工业智能化转型
AI landing new question type RPA + AI =?
Win11截图键无法使用怎么办?Win11截图键无法使用的解决方法
[system management] clear the icon cache of deleted programs in the taskbar
On the 110th anniversary of Turing's birth, has the prediction of intelligent machine come true?
Easycvr cannot be played using webrtc. How to solve it?
《原动力 x 云原生正发声 降本增效大讲堂》第三讲——Kubernetes 集群利用率提升实践
POJ training plan 2253_ Frogger (shortest /floyd)
pyqt5 失焦 监听无操作 定时器
微信能开小号了,拼多多“砍一刀”被判侵权,字节VR设备出货量全球第二,今日更多大新闻在此
Deeply cultivate the developer ecosystem, accelerate the innovation and development of AI industry, and Intel brings many partners together
SSM+JSP实现企业管理系统(OA管理系统源码+数据库+文档+PPT)
[knife-4j quickly build swagger]
The most complete deployment of mongodb in history
Triple half circle progress bar, you can use it directly
VM virtual machine operating system not found and NTLDR is missing
高薪程序员&面试题精讲系列120之Redis集群原理你熟悉吗?如何保证Redis的高可用(上)?
Nanopineo use development process record
Dab-detr: dynamic anchor boxes are better queries for Detr translation