当前位置:网站首页>ICML 2022 | 探索语言模型的最佳架构和训练方法
ICML 2022 | 探索语言模型的最佳架构和训练方法
2022-07-05 14:48:00 【智源社区】
本文介绍两篇发表于 ICML 2022 的论文,研究者都主要来自于 Google。两篇论文都是很实践性的分析论文。和常见的论文在模型做创新不一样,两篇论文都是针对现有 NLP 语言模型的架构和训练方法、探索其在不同场景下的优劣并总结出经验规律。
在这里笔者优先整理一下两篇论文的主要实验结论:
1. 第一篇论文发现了虽然 encoder-decoder 占据了机器翻译的绝对主流,但在模型参数量较大时,合理地设计语言模型 LM 可以使其与传统的 encoder-decoder 架构做机器翻译任务的性能不相上下;且 LM 在 zero-shot 场景下、在小语种机器翻译上性能更好、在大语种机器翻译上也具有 off-target 更少的优点。
2. 第二篇论文发现在不做 finetuning 的情况下,Causal decoder LM 架构+full language modeling 训练在 zero-shot 任务上表现最好;而在有多任务 prompt finetuning 时,则是 encoder-decoder 架构+masked language modeling 训练有最好的 zero-shot 性能。
论文1:Examining Scaling and Transfer of Language Model Architectures for Machine Translation
链接:https://arxiv.org/abs/2202.00528
论文2:What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
边栏推荐
- 选择排序和冒泡排序
- 【招聘岗位】软件工程师(全栈)- 公共安全方向
- 【NVMe2.0b 14-9】NVMe SR-IOV
- 机器学习笔记 - 灰狼优化
- 729. My schedule I: "simulation" & "line segment tree (dynamic open point) &" block + bit operation (bucket Division) "
- Isn't it right to put money into the external market? How can we ensure safety?
- Differences between IPv6 and IPv4 three departments including the office of network information technology promote IPv6 scale deployment
- Photoshop插件-动作相关概念-非加载执行动作文件中动作-PS插件开发
- Postgresql 13 安装
- [C question set] of Ⅷ
猜你喜欢
CyCa children's physical etiquette Ningbo training results assessment came to a successful conclusion
![[12 classic written questions of array and advanced pointer] these questions meet all your illusions about array and pointer, come on!](/img/d2/c0a19c85b2011ecd07c9944d996c4d.png)
[12 classic written questions of array and advanced pointer] these questions meet all your illusions about array and pointer, come on!
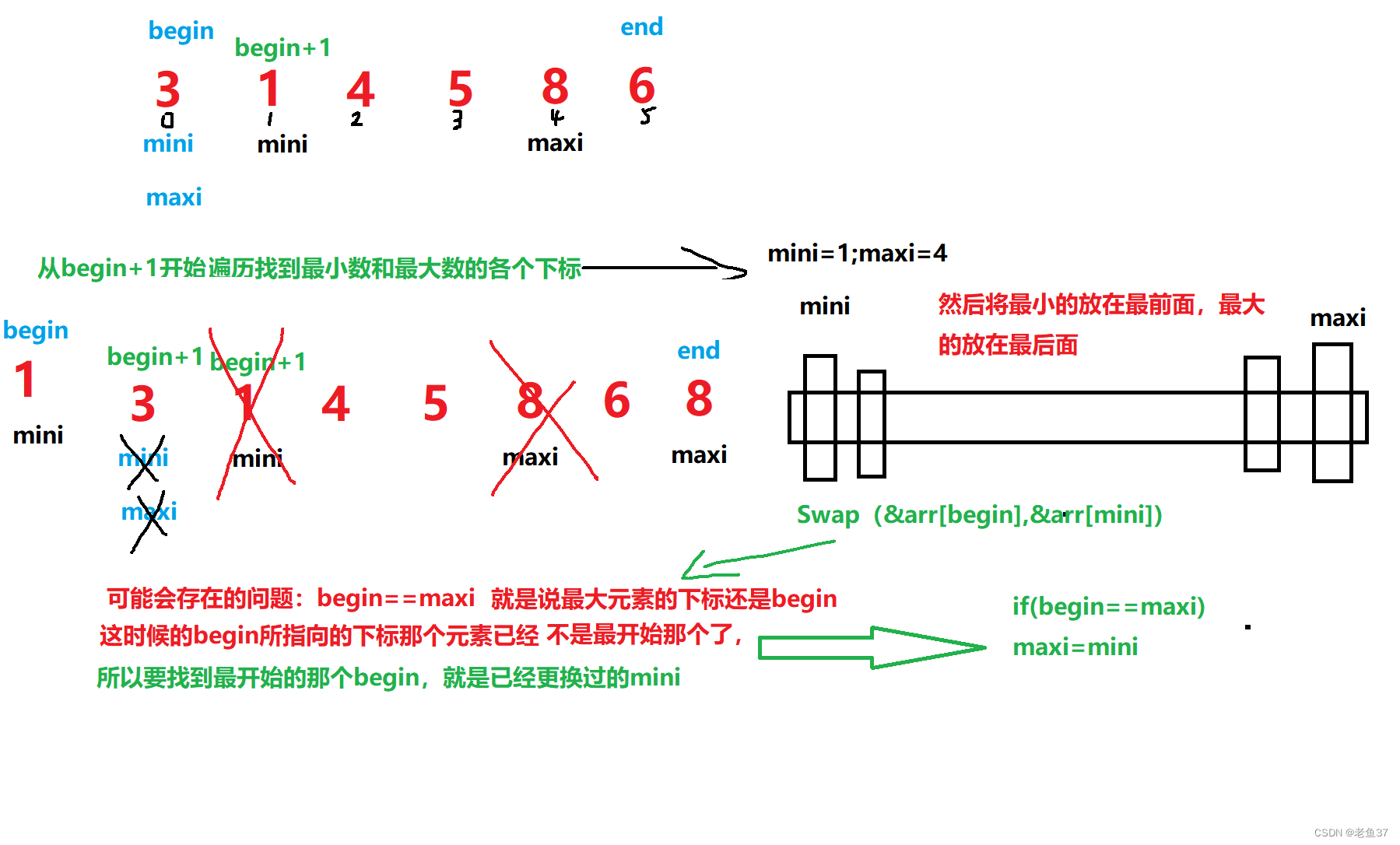
选择排序和冒泡排序

可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成
【leetcode周赛总结】LeetCode第 81 场双周赛(6.25)

Differences between IPv6 and IPv4 three departments including the office of network information technology promote IPv6 scale deployment

PyTorch二分类时BCELoss,CrossEntropyLoss,Sigmoid等的选择和使用

【NVMe2.0b 14-9】NVMe SR-IOV
![P6183 [USACO10MAR] The Rock Game S](/img/f4/d8c8763c27385d759d117b515fbf0f.png)
P6183 [USACO10MAR] The Rock Game S
Visual task scheduling & drag and drop | scalph data integration based on Apache seatunnel
随机推荐
CPU design related notes
MySQL----函数
面试突击62:group by 有哪些注意事项?
开挖财上的证券账户可以吗?安全吗?
外盘入金都不是对公转吗,那怎么保障安全?
Photoshop plug-in - action related concepts - actions in non loaded execution action files - PS plug-in development
Total amount analysis accounting method and potential method - allocation analysis
PostgreSQL 13 installation
你童年的快乐,都是被它承包了
MongDB学习笔记
启牛证券账户怎么开通,开户安全吗?
Handwriting promise and async await
useMemo,memo,useRef等相关hooks详解
Interview shock 62: what are the precautions for group by?
Using tensorboard to visualize the training process in pytoch
There is a powerful and good-looking language bird editor, which is better than typora and developed by Alibaba
Section - left closed right open
裁员下的上海
anaconda使用中科大源
12 MySQL interview questions that you must chew through to enter Alibaba