当前位置:网站首页>Py06 字典 映射 字典嵌套 键不存在测试 键排序
Py06 字典 映射 字典嵌套 键不存在测试 键排序
2022-07-06 06:22:00 【江船夜雨听笛】
F1 字典
1.字典不是序列,而是一种映射,映射同样是一个其他对象的集合,但是它通过键值对而非相对位置来存储对象。
2.字典没有可靠的从左到右的顺序,而是将键映射到值上,形成键值对。
3.字典是Python核心数据类型中唯一的一种映射类型,具有可变性。
4.同列表一样,可以根据需求增大或减少。
5.集合分为有序集如列表,无序集如字典,易于记忆的键更适用于集合中元素被命名或被标记的情况。
S2 映射操作
1.字典用字面量编写时,编写在大括号中,并包含一系列的“键:值”对,将键与值相关联。
2.字典索引与序列相同,但是方括号中是键不是相对位置 同时注意是字符串,
>>>A={'卫宫士郎':'saber','间桐樱':'rider','伊莉雅':'berserker'}
>>>A={'卫宫士郎':'saber','间桐樱':'rider','伊莉雅':'berserker','time':4}
>>>A[伊莉雅]
>>>A['伊莉雅']
'berserker'
>>>A['time']+1
5
>>>A
{'卫宫士郎': 'saber', '间桐樱': 'rider', '伊莉雅': 'berserker', 'time': 4}
>>>A['time']+=1
>>>A
{'卫宫士郎': 'saber', '间桐樱': 'rider', '伊莉雅': 'berserker', 'time': 5}+=x 操作等价于 A['']=A['']+x ,原地赋值操作证明其可变性
只是A['']+x,式子中的两项都是不变的
3.尽管可以用上面大括号字面量的形式建立字典,还有通过新键赋值会创建该键,这点与列表禁止在边界外赋值相反,字典允许使用此种方式创建键值对。
>>>A
{'卫宫士郎': 'saber', '间桐樱': 'rider', '伊莉雅': 'berserker', 'time': 5, '卫宫切嗣': 'saber'}4.字典可以用来代替搜索操作,通过使用键来索引,是Python中编写搜索的最快方法,
5. 另一种创建字典的方式,通过向dict类型名中传递键值参数对(一种语法),或传递在运行时将将键和值的序列进行zip配对来创建字典(以上一共四种创建字典的方式 字面量、新键赋值、dict、 dict+zip)
>>>A=dict(卫宫士郎='saber', 间桐樱='rider', 伊莉雅= 'berserker')
>>>A
{'卫宫士郎': 'saber', '间桐樱': 'rider', '伊莉雅': 'berserker'}
>>>A=dict(zip(['卫宫士郎','间桐樱','伊莉雅'],['saber','rider','berserker']))
>>>A
{'卫宫士郎': 'saber', '间桐樱': 'rider', '伊莉雅': 'berserker'}注意使用dict时 键没有引号了,中间也不再用冒号而是等号,使用dict+zip时语法 dict(zip([列表1],[列表二])),因为创建时列表有序,所以会前后两个列表相互对应成键,前为键,后为值。
6.字典本质是键值对的无序集合。
T3重访嵌套
1.所谓键值对,值可以对应更多种类型 如字典 列表 数字等
data={'name':{'姓':'小','名':'明'},'job':['主播','IT'],'age':40}
>>>data
{'name': {'姓': '小', '名': '明'}, 'job': ['主播', 'IT'], 'age': 40}
在这里,在顶层再次使用了三个键的字典(键分别是“name” “job”和“age” ),但是 值的更复杂了: 一个嵌套的字典作为name的值,并用一个嵌套的列表作 为job的值
>>>data['name']['名']
'明'
>>>data['job'][-1]
'IT'
>>>type(data['job'])
<class 'list'>
>>>data['job'].append('教师')
>>>data['job']
['主播', 'IT', '教师']
>>>data
{'name': {'姓': '小', '名': '明'}, 'job': ['主播', 'IT', '教师'], 'age': 40}
因为job列表是字典所包含的一部 分独立的内存,它可以自由地增加或减少,学习了后面动态类型我们可以把键的引用看作一个特殊变量,而一个变量其实没有类型而是一个指针(后面会讲到)。
2.可以看到Python核心数据类型的灵活性,嵌套允许直接并轻松地建立复杂的信息结构,所有这一切都是自动完成的一 行表达式创建了 整个的嵌套对象结构。
3.
底层语言
当我们不再需要该对象时
必须小心地释放掉所有对象空间
Python中,当最后一次引用对象后(例如将这个变量用其他的值进行赋值),这个对象 所占用的内存空间将会自动清理掉(与引用计数部分有关(后面会讲到))
4.
>>>data
{'name': {'姓': '小', '名': '明'}, 'job': ['主播', 'IT', '教师'], 'age': 40}
>>>data=0此时我们重新声明,data变量由原来的字典变为数字0,之前的字典对象会被python的垃圾回收机制自动清理掉,实际上对于不可变类型一般不会立即清理,而是类似于放到一个特殊的队列等待再次使用。
F4 不存在的键:if测试
1.字典只支持通过键访问对象
尽管我们能够通过给新的键赋值来扩展字典,访问一个不存在的键值仍然是一个错误
我们编写程序时并不是总知道当前存在什么键。在这种情况下
一个技巧就是在这之前进行测试
字典的in关系表达式允许我们查询字典 中一个键是否存在
并可以通过Python的if语句对查询的结果进行分支处理
>>>data={'name': {'姓': '小', '名': '明'}, 'job': ['主播', 'IT', '教师'], 'age': 40}
'小红'in data
False
>>>if 'name'in data:
...print(data['name'])
{'姓': '小', '名': '明'}
如果你在一个语句块中有多于一个动作要 执行
你只需把它们进行相同的缩进
不仅可以增强代码的可读性,还能减少你所要 输入的字符
2.
除了 in测试
还有很多其他方法避免在我们创建的字典中获取不存在的键
get方法
以及if/else三元表达式(实质上是挤在一行中的一条if语句)
>>>x=data.get('i',0)
>>>x
0
>>>y=data.get('name',0)
>>>y
{'姓': '小', '名': '明'}
>>>z=data['name']if'name'in data else 0
>>>z
{'姓': '小', '名': '明'}后面这个if语句是不是类似于英语中的后置定语
F5 键的排序:for循环
1.因为字典不是序列
它们并不包含任何可靠的从左至右的顺序
将它打印出来,它的键也许会以与输入时不同的顺序出现
2.如果在一个字典的元素中我们确实需要强调某种顺序
解决办法就是通过字典的keys方法收集一个键的列表
使用列表的sort方法进行排序
然后使用Python的for循环逐个进行显示结果
x=list(data.keys())
x
['name', 'job', 'age']
for y in x:
print(data[y])
{'姓': '小', '名': '明'}
['主播', 'IT', '教师']
40使用了list()后,我们就创建了一个只有键的列表,列表的左右相对顺序是固定的,也是可变的,我们可以改成我们需要的顺序后,再按照此键顺序进行输出对应的值
我们例子的实际效果就是 以排好序的键的顺序,打印这个本身是无序的字典的键和值。
3.for循环并不仅仅是序列操作,它们是迭代操作
边栏推荐
- leetcode 24. 两两交换链表中的节点
- Still worrying about how to write web automation test cases? Senior test engineers teach you selenium test case writing hand in hand
- 「 WEB测试工程师 」岗位一面总结
- Database isolation level
- Remember the implementation of a relatively complex addition, deletion and modification function based on jeecg-boot
- LeetCode 731. 我的日程安排表 II
- Qt:无法定位程序输入点XXXXX于动态链接库。
- 全程实现单点登录功能和请求被取消报错“cancelToken“ of undefined的解决方法
- 联合索引的左匹配原则
- Black cat takes you to learn UFS protocol Chapter 4: detailed explanation of UFS protocol stack
猜你喜欢
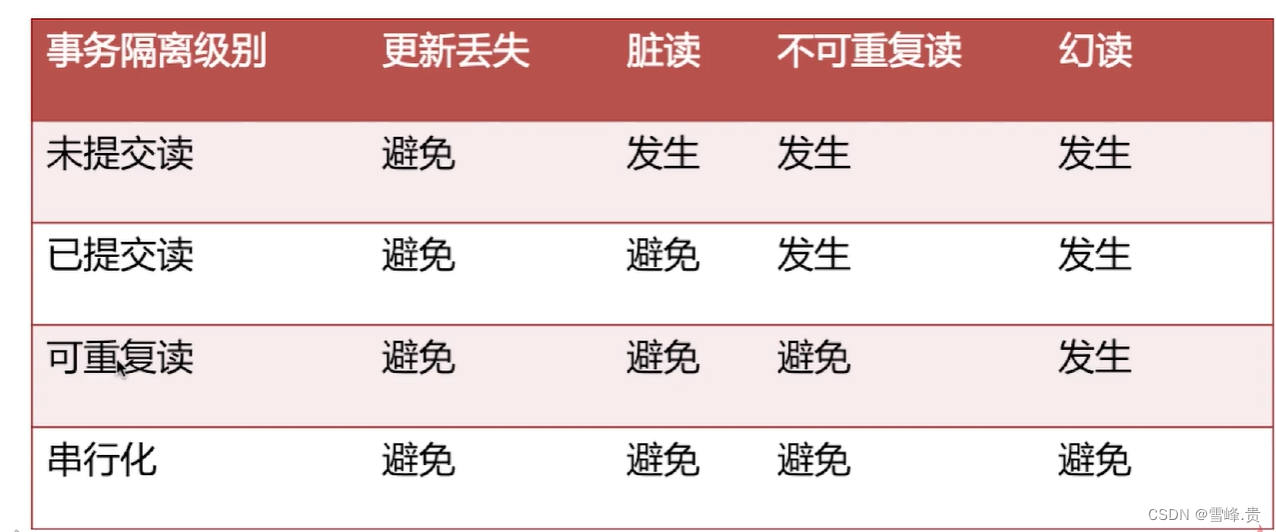
数据库隔离级别
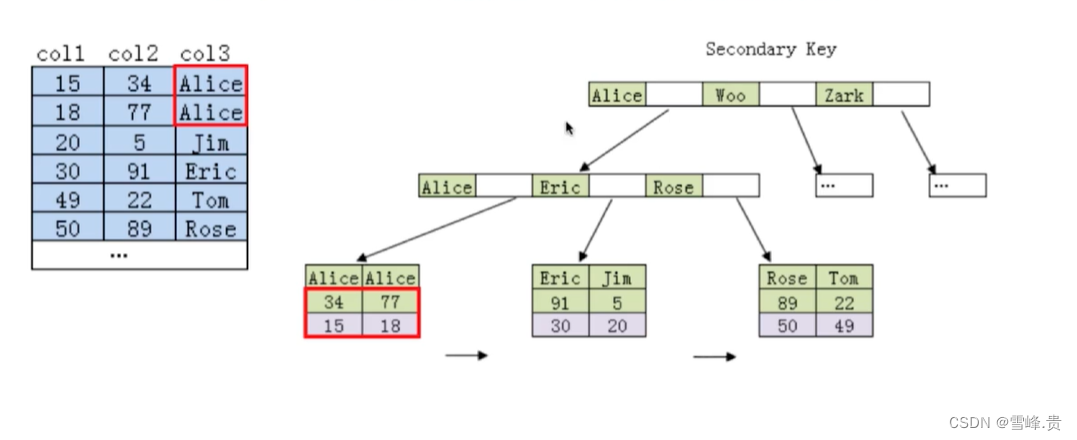
Left matching principle of joint index
D - How Many Answers Are Wrong
Error getting a new connection Cause: org. apache. commons. dbcp. SQLNestedException
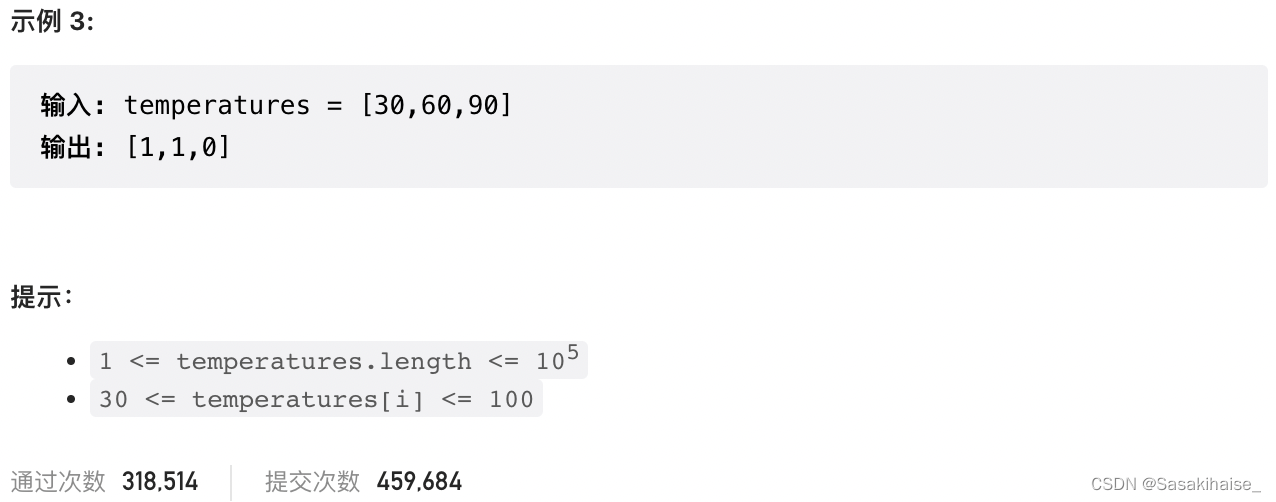
LeetCode 739. 每日温度
![[postman] collections - run the imported data file of the configuration](/img/85/7ac9976fb09c465c88f376b2446517.png)
[postman] collections - run the imported data file of the configuration
【无App Push 通用测试方案

JDBC Requset 对应内容及功能介绍

MySQL之数据类型

Basic knowledge of MySQL
随机推荐
模拟卷Leetcode【普通】1061. 按字典序排列最小的等效字符串
leetcode 24. 两两交换链表中的节点
Postman core function analysis - parameterization and test report
oscp raven2靶机渗透过程
Understanding of processes and threads
[C language] qsort function
测试周期被压缩?教你9个方法去应对
G - Supermarket
E - 食物链
Win10 cannot operate (delete, cut) files
The whole process realizes the single sign on function and the solution of "canceltoken" of undefined when the request is canceled
联合索引的左匹配原则
Delete the variables added to watch1 in keil MDK
Is the test cycle compressed? Teach you 9 ways to deal with it
Cannot create PoolableConnectionFactory (Could not create connection to database server. 错误
Manhattan distance sum - print diamond
Redis core technology and basic architecture of actual combat: what does a key value database contain?
JWT-JSON WEB TOKEN
LeetCode 732. My schedule III
[API interface tool] Introduction to postman interface