当前位置:网站首页>Pytorch model trains practical skills and breaks through the bottleneck of speed
Pytorch model trains practical skills and breaks through the bottleneck of speed
2022-07-07 14:31:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery Reading guide
One step by step Guide to , Very practical .

Let's face it , Your model may still be in the stone age . I bet you still use 32 Bit accuracy or GASP Even in one GPU Training .
I understand, , There are all kinds of neural network acceleration guides on the Internet , But one checklist None ( There is now a ), Use this list , Step by step, make sure you squeeze all the performance out of your model .
This guide ranges from the simplest structure to the most complex changes , Can make your network get the most benefit . I'll show you an example Pytorch Code and can be in Pytorch- lightning Trainer Related to the use of flags, So you don't have to write the code yourself !
** Who is this guide for ?** Any use Pytorch People who do in-depth learning model research , Like researchers 、 Doctor 、 Scholars, etc , The model we're talking about here may take you a few days of training , Even weeks or months .
We will talk about :
Use DataLoaders
DataLoader Medium workers Number
Batch size
Gradient accumulation
Reserved calculation chart
Move to a single
16-bit Mixed precision training
Move to multiple GPUs in ( Model replication )
Move to multiple GPU-nodes in (8+GPUs)
Thinking model acceleration techniques
Pytorch-Lightning

You can Pytorch The library of Pytorch- lightning Find every optimization I've discussed here .Lightning Is in Pytorch A package above , It can train automatically , At the same time, it gives researchers complete control over key model components .Lightning Use the latest best practices , And minimize where you might go wrong .
We are MNIST Definition LightningModel And use Trainer To train the model .
from pytorch_lightning import Trainer
model = LightningModule(…)
trainer = Trainer()
trainer.fit(model)1. DataLoaders

This is probably the easiest place to get speed gain . preservation h5py or numpy The era of files to speed up data loading is gone , Use Pytorch dataloader Loading image data is simple ( about NLP data , Please check out TorchText).
stay lightning in , You don't need to specify a training cycle , Just define dataLoaders and Trainer They will be called when they need to .
dataset = MNIST(root=self.hparams.data_root, train=train, download=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
x, y = batch
model.training_step(x, y)
...2. DataLoaders Medium workers The number of

Another amazing thing about acceleration is that it allows batch parallel loading . therefore , You can load nb_workers individual batch, Instead of loading one at a time batch.
# slow
loader = DataLoader(dataset, batch_size=32, shuffle=True)
# fast (use 10 workers)
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=10)3. Batch size

Before you start the next optimization step , take batch size Increase to CPU-RAM or GPU-RAM The maximum range allowed .
The next section focuses on how to help reduce memory usage , So that you can continue to add batch size.
remember , You may need to update your learning rate again . A good rule of thumb is , If batch size double , Then the learning rate will double .
4. Gradient accumulation

When you've reached the computing resource limit , Yours batch size Still too small ( such as 8), Then we need to simulate a larger batch size To make a gradient descent , To provide a good estimate .
Suppose we want to achieve 128 Of batch size size . We need to batch size by 8 perform 16 Forward and backward , Then perform the optimization step again .
# clear last step
optimizer.zero_grad()
# 16 accumulated gradient steps
scaled_loss = 0
for accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16
optimizer.step()
# loss is now scaled up by the number of accumulated batches
actual_loss = scaled_loss / 16 stay lightning in , It's all done for you , Just set up accumulate_grad_batches=16:
trainer = Trainer(accumulate_grad_batches=16)
trainer.fit(model)5. Reserved calculation chart

One of the easiest ways to burst your memory is to log your memory loss.
losses = []
...
losses.append(loss)
print(f'current loss: {torch.mean(losses)'})The question above is ,loss Still contains copies of the entire diagram . under these circumstances , call .item() To release it .
# bad
losses.append(loss)
# good
losses.append(loss.item())Lightning Will be very careful , Make sure that copies of the calculation diagram are not retained .
6. Single GPU Training

Once you have completed the previous steps , It's time to enter GPU Trained . stay GPU Training on will make multiple GPU cores The mathematical computation between is parallelized . The acceleration you get depends on what you use GPU type . I recommend personal use 2080Ti, Company use V100.
At first glance , It can be overwhelming , But you really just need to do two things :1) Move your model to GPU, 2) Whenever you run data through it , Put the data in GPU On .
# put model on GPU
model.cuda(0)
# put data on gpu (cuda on a variable returns a cuda copy)
x = x.cuda(0)
# runs on GPU now
model(x) If you use Lightning, You don't have to do anything , Just set up Trainer(gpus=1).
# ask lightning to use gpu 0 for training
trainer = Trainer(gpus=[0])
trainer.fit(model)stay GPU When you're training on , The main thing to be aware of is the limitation CPU and GPU The number of transfers between .
# expensive
x = x.cuda(0)# very expensive
x = x.cpu()
x = x.cuda(0)If memory runs out , Don't move data back to CPU To save memory . Asking for help GPU Before , Try to optimize your code in other ways or GPU Between the memory distribution .
Another thing to note is call coercion GPU Synchronous operation . Clearing memory cache is an example .
# really bad idea. Stops all the GPUs until they all catch up
torch.cuda.empty_cache()however , If you use Lightning, The only thing that can go wrong is in defining Lightning Module when .Lightning You will pay special attention not to make such mistakes .
7. 16-bit precision
16bit Precision is an amazing technique for halving memory usage . Most models use 32bit Precision figures for training . However , Recent research has found ,16bit Models can also work well . Mixed precision means using 16bit, But keep the weight and so on in 32bit.
To be in Pytorch Use in 16bit precision , Please install NVIDIA Of apex library , And make these changes to your model .
# enable 16-bit on the model and the optimizer
model, optimizers = amp.initialize(model, optimizers, opt_level='O2')
# when doing .backward, let amp do it so it can scale the loss
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()amp The bag will handle most of the things . If the gradient explodes or tends to 0, It even zooms loss.
stay lightning in , Enable 16bit There is no need to modify anything in the model , You don't need to do what I wrote above . Set up Trainer(precision=16) That's all right. .
trainer = Trainer(amp_level='O2', use_amp=False)
trainer.fit(model)8. Move to multiple GPUs in
Now? , It became very interesting . Yes 3 Kind of ( Maybe more ?) Methods to do more GPU Training .
branch batch Training
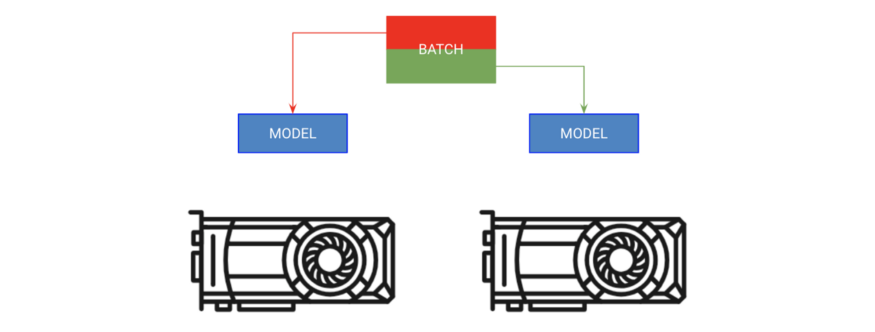
The first method is called “ branch batch Training ”. This policy copies the model to each GPU On , Every GPU get batch Part of .
# copy model on each GPU and give a fourth of the batch to each
model = DataParallel(model, devices=[0, 1, 2 ,3])
# out has 4 outputs (one for each gpu)
out = model(x.cuda(0))stay lightning in , You just need to add GPUs The number of , Then tell trainer, Nothing else to do .
# ask lightning to use 4 GPUs for training
trainer = Trainer(gpus=[0, 1, 2, 3])
trainer.fit(model)Model distribution training
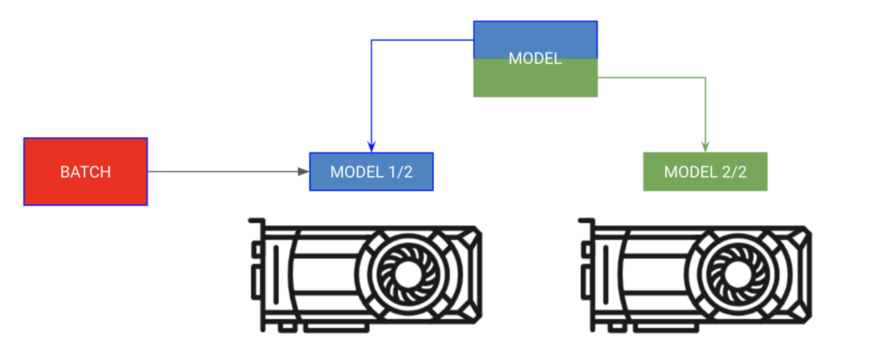
Sometimes your model may be too big to fit completely into memory . for example , Sequence to sequence models with encoders and decoders may take up 20GB RAM. In this case , We want to put the encoder and decoder in separate GPU On .
# each model is sooo big we can't fit both in memory
encoder_rnn.cuda(0)
decoder_rnn.cuda(1)
# run input through encoder on GPU 0
encoder_out = encoder_rnn(x.cuda(0))
# run output through decoder on the next GPU
out = decoder_rnn(encoder_out.cuda(1))
# normally we want to bring all outputs back to GPU 0
out = out.cuda(0)For this type of training , stay Lightning You don't need to specify any GPU, You should put LightningModule Put the module in the correct GPU On .
class MyModule(LightningModule):
def __init__():
self.encoder = RNN(...)
self.decoder = RNN(...)
def forward(x):
# models won't be moved after the first forward because
# they are already on the correct GPUs
self.encoder.cuda(0)
self.decoder.cuda(1)
out = self.encoder(x)
out = self.decoder(out.cuda(1))
# don't pass GPUs to trainer
model = MyModule()
trainer = Trainer()
trainer.fit(model)A mixture of the two
In the case above , Coders and decoders can still benefit from parallelization operations .
# change these lines
self.encoder = RNN(...)
self.decoder = RNN(...)
# to these
# now each RNN is based on a different gpu set
self.encoder = DataParallel(self.encoder, devices=[0, 1, 2, 3])
self.decoder = DataParallel(self.encoder, devices=[4, 5, 6, 7])
# in forward...
out = self.encoder(x.cuda(0))
# notice inputs on first gpu in device
sout = self.decoder(out.cuda(4)) # <--- the 4 hereThe use of multiple GPU What to consider when :
If the model is already in GPU Yes ,model.cuda() Will not do anything .
Always put input on the first device in the device list .
It's expensive to transfer data between devices , Use it as a last resort .
Optimizer and gradient will be saved in GPU 0 On , therefore ,GPU 0 The memory used on the GPU Much more .
9. multi-node GPU Training
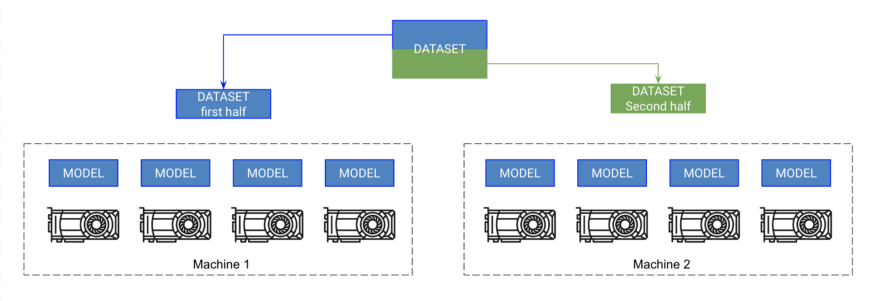
Every... On every machine GPU There's a copy of the model . Each machine gets part of the data , And only training in that part . Every machine can synchronize gradients .
If you've done that , So you can now train in a few minutes Imagenet 了 ! It's not as hard as you think , But it may require you to know more about computing clusters . These instructions assume that you are using SLURM.
Pytorch Allow multi node training , By copying each... On each node GPU On the model and synchronize the gradient . therefore , Every model is in every GPU Independently initialized on , Essentially train independently on a partition of the data , Except that they all receive gradient updates from all models .
At a high level :
At every GPU Initializes a copy of a model on ( Make sure to set the seed , Let each model be initialized to the same weight , Otherwise it will fail ).
Divide the data set into subsets ( Use DistributedSampler). Every GPU Only train on its own kid set .
stay .backward() On , All copies receive gradient copies of all models . This is the only communication between models .
Pytorch There's a good abstraction , be called DistributedDataParallel, It can help you achieve this function . To use DDP, You need to do 4 Things about :
def tng_dataloader():
d = MNIST()
# 4: Add distributed sampler
# sampler sends a portion of tng data to each machine
dist_sampler = DistributedSampler(dataset)
dataloader = DataLoader(d, shuffle=False, sampler=dist_sampler)
def main_process_entrypoint(gpu_nb):
# 2: set up connections between all gpus across all machines
# all gpus connect to a single GPU "root"
# the default uses env://
world = nb_gpus * nb_nodes
dist.init_process_group("nccl", rank=gpu_nb, world_size=world)
# 3: wrap model in DPP
torch.cuda.set_device(gpu_nb)
model.cuda(gpu_nb)
model = DistributedDataParallel(model, device_ids=[gpu_nb])
# train your model now...
if __name__ == '__main__':
# 1: spawn number of processes
# your cluster will call main for each machine
mp.spawn(main_process_entrypoint, nprocs=8)However , stay Lightning in , Just set the number of nodes , It will deal with the rest of the things for you .
# train on 1024 gpus across 128 nodes
trainer = Trainer(nb_gpu_nodes=128, gpus=[0, 1, 2, 3, 4, 5, 6, 7])Lightning And it comes with a SlurmCluster Manager , It can help you submit SLURM The correct details of the assignment .
10. welfare ! More on a single node GPU Faster training
The fact proved that ,distributedDataParallel Than DataParallel Much faster , Because it only performs gradient synchronous communication . therefore , A good hack It's using distributedDataParallel Replace DataParallel, Even if you train on a single machine .
stay Lightning in , It's easy to get distributed_backend Set to ddp And set up GPUs To achieve .
# train on 4 gpus on the same machine MUCH faster than DataParallel
trainer = Trainer(distributed_backend='ddp', gpus=[0, 1, 2, 3])Thinking about model acceleration
Although this guide will provide you with a series of tips for improving network speed , But I'm going to explain to you how to think through bottlenecks .
I divided the model into several parts :
First , I want to make sure there are no bottlenecks in data loading . So , I used the existing data loading solution I described , But if you don't have a solution that meets your needs , Consider offline processing and caching to high-performance data storage , such as h5py.
Next, let's see what you're going to do in the training steps . Make sure you move forward fast , Avoid too much computation and minimization CPU and GPU Data transfer between . Last , Avoid doing something that will reduce GPU The speed thing ( This guide introduces ).
Next , I try to maximize my batch size, This is usually due to GPU Memory size limit . Now? , Need to focus on using big batch size How to be in multiple GPUs Distribute and minimize latency ( such as , I might try to be in more than one gpu Upper use 8000 + Effective batch size).
However , You need to be careful with big batch size. For your specific problem , Please refer to the relevant literature , Look at what people are ignoring !
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- OAuth 2.0 + JWT protect API security
- Source code analysis of ArrayList
- Bashrc and profile
- Demis hassabis talks about alphafold's future goals
- Leetcode——剑指 Offer 05. 替换空格
- Leetcode - Sword finger offer 05 Replace spaces
- 设备故障预测机床故障提前预警机械设备振动监测机床故障预警CNC震动无线监控设备异常提前预警
- Multi merchant mall system function disassembly lecture 01 - Product Architecture
- ndk初学习(一)
- Simple use of websocket
猜你喜欢
EfficientNet模型的完整细节

Cvpr2022 | backdoor attack based on frequency injection in medical image analysis

KITTI数据集简介与使用
gvim【三】【_vimrc配置】
PERT图(工程网络图)

Navigation - are you sure you want to take a look at such an easy-to-use navigation framework?

MicTR01 Tester 振弦采集模块开发套件使用说明
GAN发明者Ian Goodfellow正式加入DeepMind,任Research Scientist
Simple use of websocket
常用数字信号编码之反向不归零码码、曼彻斯特编码、差分曼彻斯特编码
随机推荐
JS get the current time, month, day, year, and the uniapp location applet opens the map to select the location
The longest ascending subsequence model acwing 1014 Mountaineering
Notes de l'imprimante substance: paramètres pour les affichages Multi - écrans et multi - Résolutions
小米的芯片自研之路
Instructions for mictr01 tester vibrating string acquisition module development kit
VSCode 配置使用 PyLint 语法检查器
SAKT方法部分介绍
[Reading stereo matching papers] [III] ints
Instructions d'utilisation de la trousse de développement du module d'acquisition d'accord du testeur mictr01
Démontage de la fonction du système multi - Merchant Mall 01 - architecture du produit
昇腾体验官第五期随手记I
最长上升子序列模型 AcWing 482. 合唱队形
Hands on Teaching: XML modeling
ARM Cortex-A9,MCIMX6U7CVM08AD 处理器应用
Es log error appreciation -maximum shards open
2022年13个UX/UI/UE最佳创意灵感网站
Source code analysis of ArrayList
Docker deploy Oracle
Navigation - are you sure you want to take a look at such an easy-to-use navigation framework?
Data flow diagram, data dictionary