当前位置:网站首页>Model evaluation and selection
Model evaluation and selection
2022-07-03 10:23:00 【Fully automatic learning robot】
Model evaluation and selection
- 1. Empirical error and over fitting
- 2. Evaluation methods
- 3. Performance metrics (performance measure)
- 4. deviation (bias) And variance (variance)
1. Empirical error and over fitting
error (error): The difference between the actual predicted output of the learner and the real output of the sample
- Training error (training error)/ Experience in error (empirical error): The error of the learner on the training set
- The generalization error (generalization error): The error of the learner on the new sample
Over fitting (overfitting): Overmatch , Some characteristics of the training sample itself are regarded as the general properties of all potential samples , Big trouble , Can't completely avoid
Under fitting (underfitting): I don't deserve it , The general nature of the training sample has not been learned well , It's caused by low learning ability , Easier to solve
2. Evaluation methods
We usually evaluate the generalization error of the learner through experimental tests and then make a choice . So , A test set needs to be used to test the discriminative ability of the learner to new samples , Then take the test error on the test set as the approximation of the generalization error .
Attention should be paid to , The test set shall be mutually exclusive with the training set as far as possible . By properly processing the total data set , From which a training set is generated S And test set T
2.1 Set aside method (hold-out)
Definition : Put the dataset directly D Divided into two mutually exclusive sets , One of these sets is the training set , Another as a test set .
Be careful :
- Training / The partition of test set should keep the consistency of data distribution as much as possible , The sampling method that preserves the proportion of categories is usually called “ Stratified sampling ”(stratified sampling)
- Given training / After the sample proportion of the test set , There are still many ways to divide . Therefore, the estimation results obtained by using the set aside method alone are not stable and reliable , In general, several random partitions are used 、 After repeated experimental evaluation, the average value is taken as the evaluation result of the retention method
- Test set hours , The variance of the evaluation results is large ; Training set hours , The deviation of the evaluation results is large
- A common practice is to put about 2/3~4/5 A sample of is used for training , The rest is used for testing
- generally speaking , The test set should contain at least 30 A sample
2.2 Cross validation (cross validation)/ k Crossover verification (k-fold cross validation)
Definition : First set the total data D Divided into k A mutually exclusive subset of similar size , Each subset keeps the consistency of data distribution as much as possible ( From D Obtained by stratified sampling ). Then every time I use K-1 Union of subsets as training set , The rest of yourself as a test set . In this way we can get K Group training / Test set , So as to carry out k Training and testing , And finally back here k The average of the test results .
Be careful :
- The stability and fidelity of the evaluation results of cross validation method depend on K The value of ,K Usually take 10, Commonly used 5,20 etc.
- Given k value , There are still many ways to divide . Therefore, it is usually necessary to use different partitions randomly p Time , The final assessment is this p Time k The mean value of fold cross validation results , There are common 10 Time 10 Crossover verification
special case : Keep one (Leave-One-Out, abbreviation LOO)
Definition : Suppose the dataset D Contained in the m Samples , Make k=m
advantage : The evaluation result is accurate
shortcoming : When the data set is large , The computational cost of the training model is too high
2.3 Self help law (bootstrapping)/ There is a return sample / Repeatable sampling
Definition : For a given include m The data set of 2 samples D Sample to produce a data set D’: Every time, randomly from D Pick a sample from , Put a copy of it in D’, Then put the sample back into the initial data set D in , So that the sample will still have a chance to be collected at the next sampling . The above process is repeated m thereafter , Get the results , Which contains m The data set of 2 samples D’.
advantage : In datasets smaller 、 It's hard to divide training effectively / The test set is excellent ; The self-help method can generate multiple different training sets from the initial data set , It is friendly to integrated learning and other methods
shortcoming : The data set generated by self-service method changes the distribution of the initial data set , It introduces estimation bias , So if the initial data volume is enough , Set aside method and cross validation method are more commonly used
Be careful :
- D Some of the samples will be in D‘ Repeated in , Some samples will not appear . Through self-help sampling , Initial data set D About 36.8% The sample of does not appear in the sampling dataset D‘ in
- Can be D‘ Used as a training set ,D\D’(\ Represents set subtraction ) Use as test set . In this way, both the actual evaluation model and the expected evaluation model are used m Training samples , The total amount of data is still about 1/3 Samples that do not appear in the training set are used for testing , The test result is also called “ Out of the bag estimate ”(out-of-bag estimate)
2.4 Adjustable parameter (parameter tuning) And the final model
Machine learning often involves two types of parameters :
- Parameters of the algorithm ( Hyperparameters ), The number is always 10 within
- Parameters of the model , Maybe a lot
Same as : The two methods of parameter adjustment are similar , They are selected based on some evaluation method after generating multiple models .
different : The former is usually generated by manually setting multiple parameter candidate values ; The latter generates multiple candidate models through learning
3. Performance metrics (performance measure)
Performance measurement is the evaluation standard of model generalization ability , Reflects the mission requirements .
3.1 Error rate (error rate) And precision (accuracy)
Error rate : The proportion of the number of samples with wrong classification in the total number of samples
precision : The proportion of correctly classified samples in the total number of samples
precision =1- Error rate
3.2 Precision rate / Accuracy rate (precision)、 Recall rate / Recall rate (recall) And F1
For dichotomies , The examples can be divided into the following four situations according to the combination of real categories and learner prediction categories : Real examples (true positive)、 False positive example (false positive)、 True counter example (true negative)、 False counter example (false negative). The sum of the four is the total number of samples .
By definition :
- Precision rate P The proportion of examples that reflect the real situation and the prediction results are positive examples in the examples that the prediction results are positive examples
- Recall rate R The proportion of examples that reflect the real situation and the prediction results are positive examples in the examples that the real situation is positive
Be careful :
- Precision and recall are contradictory measures , In general , When the accuracy is high , Recall is low ; When recall is high , The accuracy rate is low
P-R curve

In many cases , According to the prediction results of the learner, we can use “ Is the possibility of positive example ” Sort from high to low , Start from high and take the samples one by one as positive examples to predict , The current total rate of each check can be calculated 、 Precision rate . Take the precision as the vertical axis 、 Recall is plotted on the horizontal axis , Get the accuracy - Recall curve , abbreviation P-R curve .P-R The curve intuitively shows the recall rate of the learner in the sample population 、 Precision rate .
Usually compare the area under the curve , Larger means better performance of the learner .
Balance point (Break-Even Point, abbreviation BEP) yes “ Precision rate = Recall rate ” The value of time , be based on BEP When comparing values ,BEP Larger means better performance .
F1 Measure
BEP Oversimplification , More often F1 Measure :

In some applications , The importance of precision and recall is different , Then there are F1 The general form of measurement Fβ, The definition for :
We hope that n Comprehensively investigate the precision and recall on two classification confusion matrices , There are two ways :
- macro : First, calculate the precision and recall on each confusion matrix , Then calculate the average , obtain “ Macro accuracy rate ”(macro-P)、“ Macro recall ”(macro-R) And corresponding “ macro F1”(macro-F1)
- tiny : First, average the corresponding elements of each confusion matrix , Then based on these averages, calculate “ Micro precision ”(micro-P)、“ Micro recall ”(micro-R) And corresponding “ tiny F1”(micro-F1)
3.3 ROC And AUC
Many learners generate a real value or probability prediction for the test sample , Then compare the predicted value with a classification threshold (threshold) Compare , If it is greater than the threshold, it is divided into positive classes , Less than, it is divided into inverse classes . The generalization ability of the learner is directly determined by the result of real value or probability prediction . Based on this real value or probability prediction result , We can sort the test samples ,“ Most likely ” At the top , such , The classification process is equivalent to a certain value in this sort “ Cut off point ”(cut point) Divide the sample into two parts , The previous part is a positive example , The latter part is a counter example .
In different application tasks, different cut-off points can be adopted according to task requirements , If more attention “ Precision rate ”, You can select the top position in the sorting to truncate ; If more attention “ Recall rate ”, You can select the last position in the sorting to truncate .
so , The quality of sorting itself , It reflects the comprehensive consideration of the learning machine under different tasks “ Expected generalization performance ” The stand or fall of , Or say ,“ In general ” Generalization performance is good or bad .ROC Curve is a powerful tool to study the generalization performance of learners from this point of view .
First, sort the samples according to the prediction results of the learner , In this order, take the examples one by one as positive examples to predict , Every time we calculate “ True case rate ”(True Positive Rate, abbreviation TPR) and “ The false positive rate is ”(False Positive Rate, abbreviation FPR), Take them separately 、 Horizontal axis drawing , Got it. ROC curve .TPR And FPR Defined as : so :
so :
- True case rate TPR Reflect the proportion of real examples in the examples with positive examples in the actual situation
- The false positive rate is FPR Reflect the proportion of false positive examples in examples where the actual situation is a counterexample
In real tasks, a limited number of test samples are usually used to draw ROC chart .
Drawing process : Given m+ A positive example and m- A counterexample , The samples are sorted according to the prediction results of learners , Then set the classification threshold to the maximum ( I.e. all samples are predicted as counterexamples ), here TPR And FPR All for 0, Mark a point at the coordinate origin , Then set the classification threshold to the predicted value of each sample in turn , Each example is divided into positive examples in turn , Let the coordinates of the previous marker point be (x,y), Now if it's a real example , Then the coordinates of the corresponding marking points are (x,y+1/m+); If the current is a false positive example , Then the coordinates of the corresponding marking points are (x+1/m-,y), Finally, connect adjacent points with line segments .
Add : draw P-R This is how the curve works
A more reasonable performance criterion is comparison ROC The area under the curve , namely AUC(Area Under ROC Curve)
3.4 Cost sensitive error rate and cost curve
In order to weigh the different losses caused by different types of errors , Give to mistakes “ Unequal costs ”(unequal cost)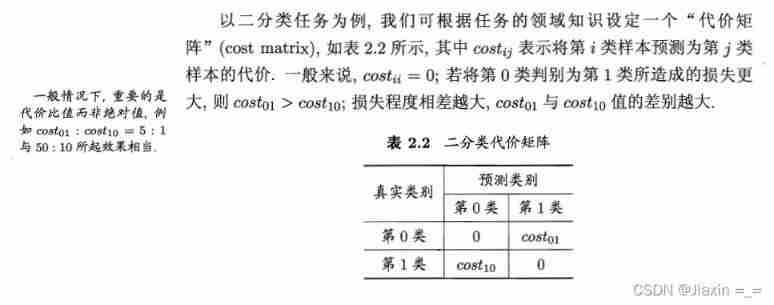
At unequal costs , We want to minimize “ The overall cost is ”(total cost). If table 2.2 No 0 Class as a positive class 、 The first 1 Class as anti class , Make D+ And D- Each represents a sample set D Positive and negative example sets , be “ Cost sensitive ”(cost-sensitive) Error rate for :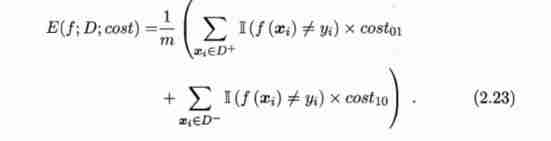
Similarly , The cost sensitive error rate based on distribution definition can be given , And some other cost sensitive versions of performance metrics . If order costij Medium i、j The value is not limited to 0 And 1, Then you can define a cost sensitive performance measure for multiple classification tasks .
At unequal costs , use “ The cost curve ”(cost curve) Reflect the expected total cost of the learner . The horizontal axis of the cost curve is the value range [0,1] The positive case probability cost of 
Drawing of cost curve :ROC Each point on the curve corresponds to a line segment on the cost plane . set up ROC The coordinate of a point on the curve is (FPR,TPR), Then we can calculate accordingly FNR, Then draw a line from (0,FPR) To (1,FNR) The line segment , The area under the line segment represents the expected total cost under this condition .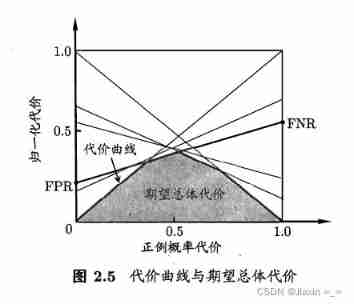
4. deviation (bias) And variance (variance)
“ deviation - Variance decomposition ”(bias-variance decomposition) It is an important tool to explain the generalization performance of learning algorithms .
deviation : A measure of the deviation between the expected prediction of the learning algorithm and the actual result , Immediately draw the fitting ability of learning algorithm itself
variance : The measurement of the change of learning performance caused by the change of the training set of the same size , Immediately draws the impact of data perturbation
noise : The lower bound of the expected generalization error that any learning algorithm can achieve in the current task is expressed , Immediately draw the difficulty of the learning problem itself
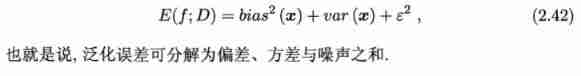
Thus we can see that , Generalization performance depends on the ability of learning algorithms 、 The adequacy of the data and the difficulty of the learning task itself jointly determine .
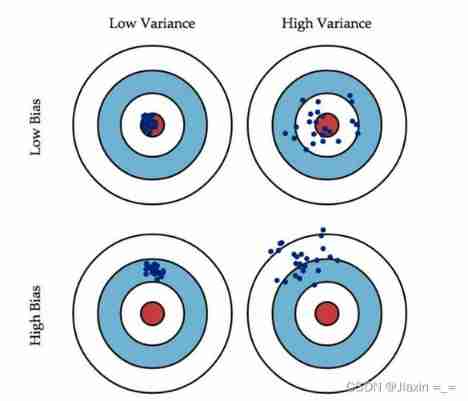
generally speaking , Deviation and variance are in conflict , It's called deviation - Variance dilemma (bias-variance dilemma)
Given a learning task , When training is insufficient , The fitting ability of the learner is not strong enough , The disturbance of training data is not enough to make the learner change significantly , At this time, the deviation dominates the generalization error rate ; As the training deepens , The fitting ability of the learner is gradually enhanced , The disturbance of training data can be gradually learned by the learner , Variance gradually dominates generalization error rate . After enough training , The fitting ability of the learner has been very strong , Slight disturbance of training data will lead to significant changes in the learner , If the training set itself 、 Non global features are learned by the learner , Fitting will happen .
边栏推荐
- ECMAScript--》 ES6语法规范 ## Day1
- 使用密钥对的形式连接阿里云服务器
- 20220609 other: most elements
- LeetCode - 5 最长回文子串
- Leetcode-100:相同的树
- Discrete-event system
- Synchronous vs asynchronous
- 20220603 Mathematics: pow (x, n)
- Powshell's set location: unable to find a solution to the problem of accepting actual parameters
- [LZY learning notes -dive into deep learning] math preparation 2.5-2.7
猜你喜欢
One click generate traffic password (exaggerated advertisement title)
重写波士顿房价预测任务(使用飞桨paddlepaddle)

Connect Alibaba cloud servers in the form of key pairs
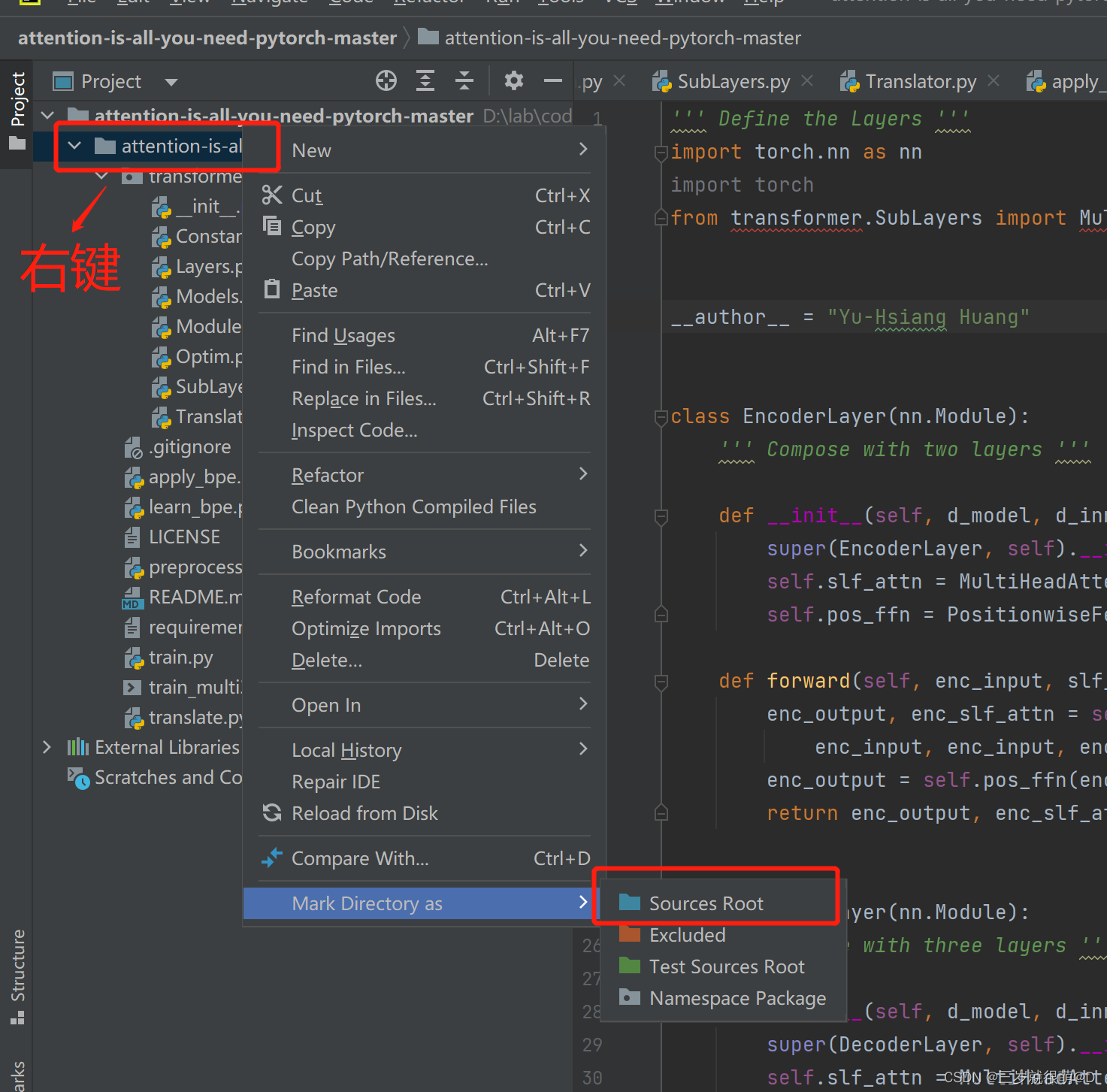
Pycharm cannot import custom package
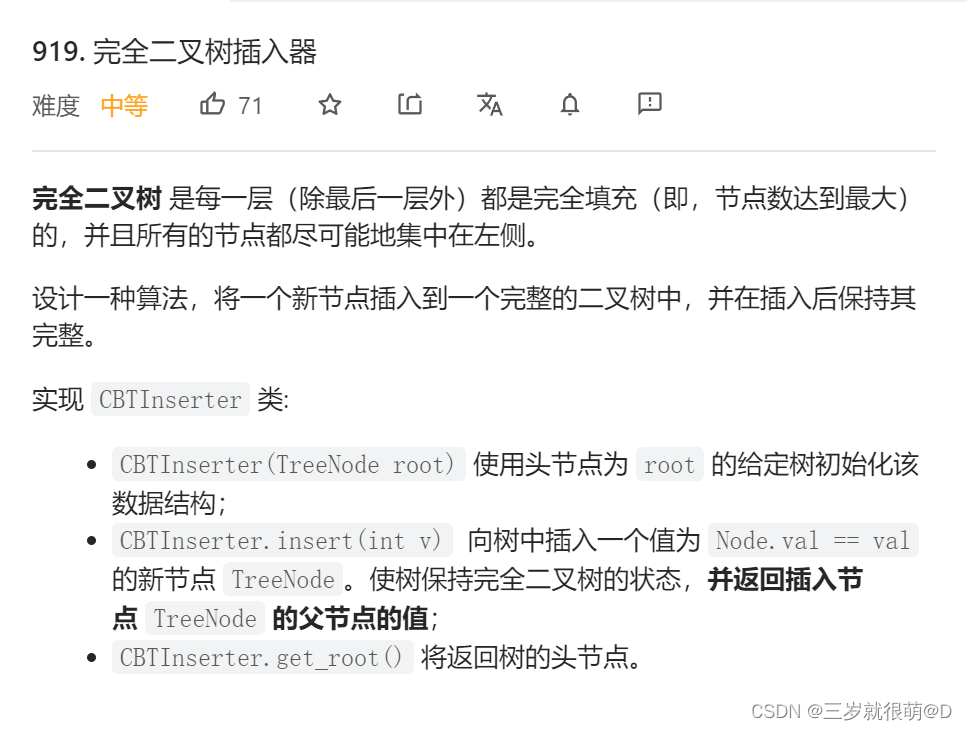
LeetCode - 919. Full binary tree inserter (array)

Leetcode-106:根据中后序遍历序列构造二叉树

Leetcode - 460 LFU cache (Design - hash table + bidirectional linked hash table + balanced binary tree (TreeSet))*
Leetcode-112: path sum
Vgg16 migration learning source code

YOLO_ V1 summary
随机推荐
QT setting suspension button
【C 题集】of Ⅵ
20220605 Mathematics: divide two numbers
Synchronous vs asynchronous
LeetCode - 5 最长回文子串
Policy gradient Method of Deep Reinforcement learning (Part One)
20220605数学:两数相除
LeetCode - 1172 餐盘栈 (设计 - List + 小顶堆 + 栈))
Leetcode interview question 17.20 Continuous median (large top pile + small top pile)
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)
2018 y7000 upgrade hard disk + migrate and upgrade black apple
LeetCode 面试题 17.20. 连续中值(大顶堆+小顶堆)
1. Finite Markov Decision Process
Leetcode - 1670 conception de la file d'attente avant, moyenne et arrière (conception - deux files d'attente à double extrémité)
Notes - regular expressions
LeetCode - 706 设计哈希映射(设计) *
20220602 Mathematics: Excel table column serial number
. DLL and Differences between lib files
CV learning notes - edge extraction
Retinaface: single stage dense face localization in the wild