当前位置:网站首页>Advantageous distinctive domain adaptation reading notes (detailed)
Advantageous distinctive domain adaptation reading notes (detailed)
2022-07-03 10:19:00 【Innocent^_^】
My first online paper reading notes -Adversarial Discriminative Domain Adaptation
A quick tour of
Why take this form
One afternoon (2021.10.16) Thinking about , Read a paper , I write notes and notes in the original , Then I have to send the marked papers to QQ Or on wechat , This is convenient for the next computer to watch . At first, there seems to be no problem , But for a long time , I don't know where the latest annotated version of the paper went , I don't know which version is the latest , So why not put it in the blog of the network , In this way, you can share , It can also be easily stored !
Attitude towards this article
I will from my own point of view , A zero foundation entry point of transfer learning , Explain clearly the overall structure and some details of this article , Including technical terms 、 Contrast, etc .
Data sets and completed tasks
According to the article Introduction part ( The penultimate line on the left side of the second page ), The data set of the validation model is MNIST, USPS, and SVHN digits datasets. Later, it was also said that in order to test ADDA Cross morphological detection capability , It's still used NYUD dataset(RGB
and HHA encoded depth images as source and target domains respectively Their respective )
The tasks completed are : Realize visual adaptive results on the above data sets , Test the model unsupervised by moving the target classifier from RGB The potential of color image conversion to depth in reducing the impact of more complex cross morphological data drift
A term is used to explain
When reading literature, you will inevitably encounter professional terms that you don't understand . I am a beginner , There are still too many people I don't know . I hope this can help people like me get started quickly , I also hope that energetic leaders can carry on .
title
My Chinese title for this article is “ Antagonistic discrimination domain adaptation ”,Domain Adaptation It is a transfer learning algorithm .
Abstract part ( first page ):
| name | meaning | Location |
|---|---|---|
| Domain Shift Domain drift | Data sets are different , The data distribution is also different , Like a pig's tail ( Very short ) And horse tail ( For a long ), The reason is that the distribution of sample data is different from that of the sample to be predicted | In the fourth row |
| Database Bias Data set bias | Existing data sets always have some / Some factors are relied on , and domainshift It also leads to misjudgment | In the fourth row |
| tied weights | Weight sharing , Directly take the trained model and put it into your own use , Take the white face recognition model to recognize the black | Line 12 |
| GAN-based Loss | GAN Of loss The formula , The core is the maximization discriminator 、 Minimize the generator's loss | Line 13 |
| untied weight sharing | Unconstrained weight sharing , The weight can be changed during migration | Line 19 |
| domain-adversarial methods | Domain confrontation method , This should not be a specific term , Is a general method , Similar thinking GAN | Count down to five lines |
Introduction part ( First of all 、 Two pages )
For page changing, side changing and section changing , Will write it out , The following paragraph on the same side of the same page will not be explained in detail .
| name | meaning | Location |
|---|---|---|
| maximum mean discrepancy | The largest average difference , For specific principles, see MMD Introduce , As the last Loss Function to optimize | The fourth line on the left of the second page |
| correlation distances | Correlation distance =1- The correlation coefficient | The fifth row |
| depth observation | Observe Image depth , Determine the number of colors of the color image | The fifth row |
Related work part ( On the right side of the second page )
| name | meaning | Location |
|---|---|---|
| domain invariance | Invariance of fields , It is a concept in topology , Prove two topological spaces Homeomorphism | The penultimate line of the third paragraph |
| latent space | Hidden space , Learning its fundamental characteristics after dimensionality reduction | The last word on the second page |
3.1 Source and target mappings
| name | meaning | Location |
|---|---|---|
| LeNet model | Recognize handwritten characters neural network , There are convolutions and pooling Operation from input To extract from feature map | The eighth line of the second paragraph |
| mapping consistency | It is written here to prevent and consistent mapping Mix up , The original expression means that the source and target should be mapped to the same space | The third line of the sixth paragraph |
| partial alignment | Partially aligned , Personal understanding , Let me give you an example : The source image is black and white dot digit , The target image is a color continuous HD version , Use the number recognition model trained by the former to recognize the latter ,“alignment" Original intention " alignment ”, This should mean doing mapping After the results of the , That is to find out two kinds of images " Digital skeleton " | The third line of the sixth paragraph |
3.2 Adversarial losses
| name | meaning | Location |
|---|---|---|
| fixed-point properties | I don't know | Page 5 formula 7 below |
| cross-entropy loss | Cross entropy loss function , Commonly used for classification problems , For details, please refer to : Loss function | Cross entropy loss function | Page 5 formula 8 above |
4. Adversarial discriminative domain adaptation part ( Bottom left of page 5 )
| name | meaning | Location |
|---|---|---|
| degenerate solution | Degenerate solution , It means a feasible non unique solution | The sixth line of the second paragraph on the right side of page 5 |
| the inverted label GAN loss | I don't know | Page 5 formula 9 Top right |
5. Experiments( Page 6 left )
| name | meaning | Location |
|---|---|---|
| ReLU activation function | Linear rectification , The activation function of the neural network | At the end of the first paragraph on the right side of page 6 |
| Source Only | There is no model before adaptation | Tabel 2 first |
Focus on sentence analysis ( Some words are annotated in Chinese )
My English level is not very high , Some words have to be annotated in Chinese , Maybe this will also save you time to look up words . The key sentences basically include the introduction of the model in the article , This article is believed to be of no benefit to speed .
Abstract part ( first page )
1. Criticism of previous models ( The first 9 That's ok ):
Prior generative approaches show compelling Fascinating visualizations, but are not optimal on discriminative tasks and can be limited to smaller shifts. Prior discriminative approaches could handle larger domain shifts, but imposed tied weights Parameters of the Shared on the model and did not exploit a GAN-based loss.
It can be seen from this passage that , The previous model mentioned in the article has some disadvantages :
(1) Generation method : Visualization is well done , But the discrimination task is not well optimized , It is vulnerable to small-scale ( field ) Limitation of drift
(2) Discrimination method : Able to handle large-scale field drift tasks , But in the model, only weight sharing is used
2. The general idea of the proposed model ( The first 13 Line back ):
We first outline a novel all-new generalized framework for adversarial adaptation Adversarial adaptation , which subsumes inductive recent state-of-the-art advanced approaches as special cases, and we use this generalized General view to better relate And … Connect the prior approaches.
It should not be surprising that this paragraph is written in the summary , Although it seems to be boasting , But it's normal in the summary .
Basically, I will start to talk about the characteristics and exaggeration of this model —— It is characterized by combining the discriminant model (discriminative modeling)、 Unconstrained weight sharing (untied weight sharing) and GAN Loss. The advantage is that it is simpler than the competitive domain confrontation method , In cross domain word analysis ( All kinds of strange 1、2、3、4) And cross morphological object classification are more promising than the most advanced unsupervised adaptive algorithms .
Introduction part ( First of all 、 Two pages )
1. Traditional solutions and dilemmas to the problem of domain drift :
The typical solution is to further fine-tune fine-tuning these networks on task-specific datasets— however, it is often prohibitively difficult Too difficult and expensive to obtain enough labeled data to properly fine-tune the large number of parameters employed by deep multilayer networks.
Since parameters cannot be used directly , That is, of course, “ fine-tuning ” La . But it's easy to say , Want to have enough tagged data to make fine adjustments ( That's almost learning again ) It's still too difficult ( One of the goals of transfer learning is to use the trained model to identify unlabeled data ).
2. Introduce Adversarial adaptation The general principle of , and GAN similar :
Adversarial adaptation methods have become an increasingly popular incarnation avatar of this type of approach which seeks to minimize an approximate domain discrepancy differences distance through an adversarial objective with respect to a domain discriminator On the antagonism target of domain discriminator ( It means maximizing the difference between discriminators , This is the meaning of antagonism ).
3. Introduce The overall process of the model :
ADDA first learns a discriminative representation using the labels in the source domain and then a separate Different encoding that maps the target data to the same space using an asymmetric mapping learned through a domain-adversarial loss.
Learn a discriminant model with tags in the source domain , Then use a different coding method , It can use asymmetric mapping to map the target data to the same space through domain anti loss optimization .( My personal understanding is to try to make a pig's tail into a horse's tail )
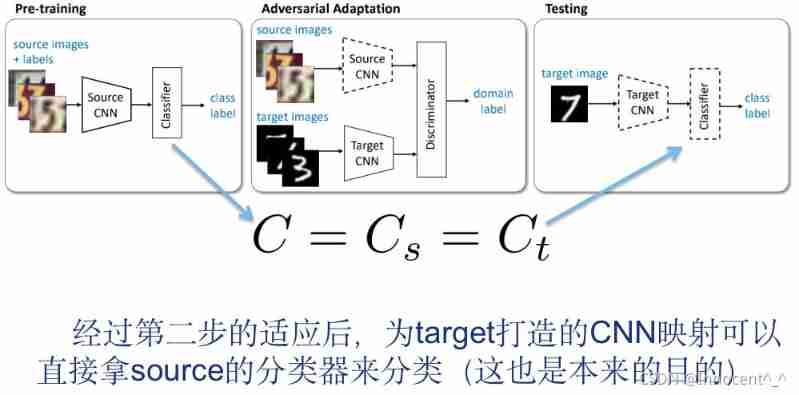
This passage can be said to be the main idea of the article , Combined with the flow chart on page 3, the effect is better :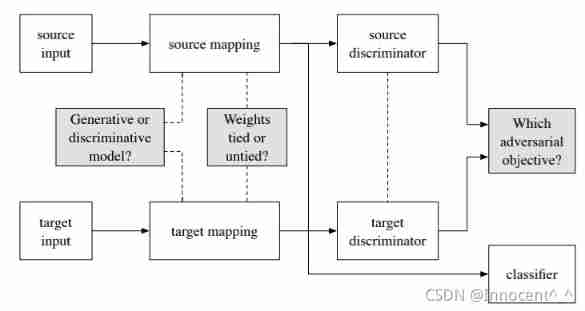 The following is the description of the above figure in the original text : The existing antagonistic adaptation method is a special case of our framework , According to the characteristics , The choices given to the questions in the dark box above are also different .
The following is the description of the above figure in the original text : The existing antagonistic adaptation method is a special case of our framework , According to the characteristics , The choices given to the questions in the dark box above are also different .
So for ADDA, What is the choice of this model ? From the above paragraph, we can see the answer ! Yes, of course , The table on the fourth page of the original directly pasted the answers .
It is obvious from the above table ,ADDA stay source and target The base model selected between the mappings of is discriminant , Use unconstrained weight sharing , The goal of confrontation is GAN Of loss
The fourth part is the original sentence :
Specifically, we use a discriminative base model, unshared weights, and the standard GAN loss
Related work part ( second 、 Three pages )
For several GAN After the comparison of variant models :
In this paper, we observe that modeling the image distributions is not strictly necessary to achieve domain adaptation, as long as the latent feature space is domain invariant
ADDA The model holds that , To achieve domain adaptation , It is not necessary to model the image distribution , Because hidden space is domain invariant .
Let's talk about models later , There is basically nothing behind the analysis of key sentences , But I also talked about many common practices of other transfer learning models , It's worth reading .
3.2 Adversarial losses( Right side of page 4 、 Left side of page 5 )
1. Indicates that in the model ,source and target The mapping of is independent , All you have to learn is M M Mt
Note that, in this setting, we use independent mappings for source and target and learn only Mt adversarially.
4. Adversarial discriminative domain adaptation part ( Bottom left of page 5 )
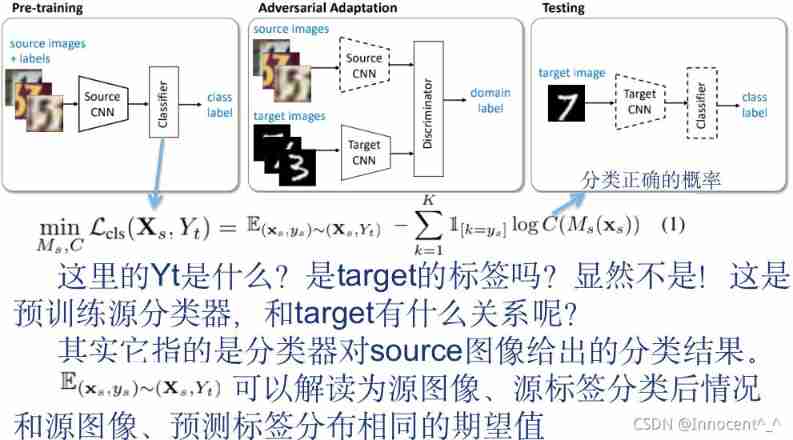
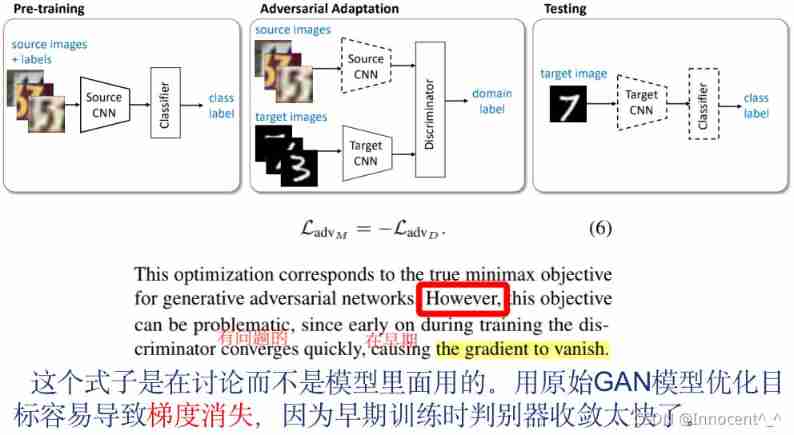
1. According to the original introduction , This paragraph explained below the flow chart illustrates the overall training process of the model (sequential training procedure)
First : Using the source image with label to train the convolutional neural network of coding source
then : Learn a convolutional neural network that can make the discriminator unable to accurately identify the coding target of the domain label ( For example : Now there is a model to judge whether animals have tails ,source It's a horse. ,target It's a pig. , This network hopes to put them “ tail ” Find common features of , Instead of taking the short tail as nothing )
In the test : The target image is mapped to the shared feature space by the target encoder and classified by the source classifier . The dotted line indicates that this is a fixed network parameter ( It means to apply directly ).
An overview of our proposed Adversarial Discriminative Domain Adaptation (ADDA) approach. We first pre-train a source encoder CNN using labeled source image examples. Next, we perform adversarial adaptation by learning a target encoder CNN such that bring a discriminator that sees encoded source and target examples cannot reliably accurately predict their domain label. During testing, target images are mapped with the target encoder to the shared feature space and classified by the source classifier. Dashed lines Dotted line indicate fixed network parameters.

In fact, similar words have been mentioned many times above , It's just about splitting , The details will continue in the fourth part .
2. Answer several detailed questions about the second part of the above process :
(1) Why share unconstrained weights ? This is a flexible learning mode , Can learn more domain characteristics .
This is a more flexible learning paradigm learning model as it allows more domain specific feature extraction to be learned
(2) Why keep some weights ? It is possible to produce degenerate solutions .
The target domain has no label access, and thus without weight sharing a target model may quickly learn a degenerate solution Degenerate solution
(3) How to solve ? Put right source The pre trained model is used as target The initial version of expression space can be improved through training .
We use the pre-trained source model as an intitialization for the target representation space and fix the source model during adversarial training.
3. Optimization steps :
We choose to optimize this objective in stages In stages . We begin by optimizing L c l s \mathcal{L}_{\mathrm{cls}} Lcls over M s M_s Ms and C C C by training, using the labeled source data, X s X_s Xs and Y s Y_s Ys. Because we have opted to leave M s M_s Ms fixed while learning M t M_t Mt, we can thus optimize L a d v D \mathcal{L}_{\mathrm{adv_D}} LadvD and L a d v M \mathcal{L}_{\mathrm{adv_M}} LadvM without revisiting the first objective term. A summary of this entire training process is provided in Figure 3.
5. Experiments( Page 6 left )
1. How to conduct experiments :
We use the simple modified LeNet architecture provided in the Caffe source code. When training with ADDA, our adversarial discriminator consists of 3 fully connected layers: two layers with 500 hidden units followed by the final discriminator output. Each of the 500-unit layers uses a ReLU activation function.
Symbol marking and formula interpretation
Format of first occurrence position :( The paragraph , Row number ) Negative numbers indicate the penultimate row
3.Generalized adversarial adaptation( The third page )
| name | meaning | The location of the first appearance |
|---|---|---|
| Xs | source images The source image | 1,3 |
| Ys | Label of the source image | 1,3 |
| ps(x,y) | source domain distribution Source domain distribution | 1,4 |
| Xt | target images Target image | 1,5 |
| pt(x,y) | target domain distribution Target domain distribution | 1,5 |
| Mt | target representation Target model | 1,7 |
| Ct | Target image K classifier | 1,7 |
| Ms | source representation mapping | 1,-3 |
| Cs | source classifier | 1,-2 |
| L L Ladv D _D D | The discriminator's loss | 4,-2 |
| L L Ladv M _M M | adversarial mapping loss | 6,-1 |
Formula position indicates (x,y):x= the number of pages ,y=0 Tense means on the left ,y=1 Hour means on the right
First understand the meaning , Understand the algorithm steps of the article, and then see how it is calculated
| The formula | explain | Location |
|---|---|---|
| C=Cs=Ct | The mapping distribution difference between the source image and the target image is very small , The classifier of the source image can be directly applied to the target image | 3,2 |
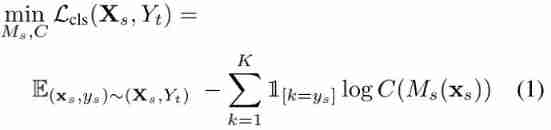 | Optimize the source classifier standrad supervised loss | 3,2 |
 | Domain Discriminator Of loss, It needs to maximize to ensure that it cannot see that the data comes from source still target | 3,2 |
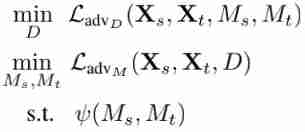 | The original text states that this is “Generic Formulation", It means the overall goal achieved : Maximize the... Of the discriminator loss, Minimize the difference between source and target after mapping , The bottom meaning is to implement a specific mapping structure | 3,2 |
3.1 Source and target mappings
| Symbol name | meaning | The location of the first appearance |
|---|---|---|
| Mls | source images Of l Parameters of the layer | 4,2 |
| {l1,l2,…,ln} | l=layer, What layer means | 4,3 |
| The formula | explain | The location of the first appearance |
|---|---|---|
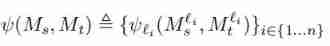 | The overall mapping structure is the combination of the mapping structures of each layer ( Words used in the original text constraints) | 4,1 |
 | The mapping structure of each layer can be expressed as the calculation parameters of the source or target image of the layer | 4,2 |
3.2 Adversarial losses
| The formula | explain | Location of occurrence |
|---|---|---|
 | adversarial mapping loss, Judge the advantages and disadvantages of mapping | 5,1 |
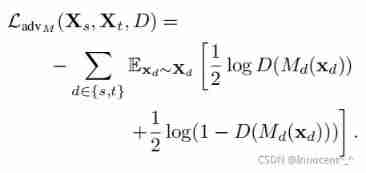 | The calculation formula of cross entropy loss ,D(Md(xd)) Represents a classifier D The first d Samples xd The probability of mapping to a class ,Md Meaning and taking 1 2 \frac{1}{2} 21 The reason is that label Only 1/0, The default accuracy is half | 5,1 |
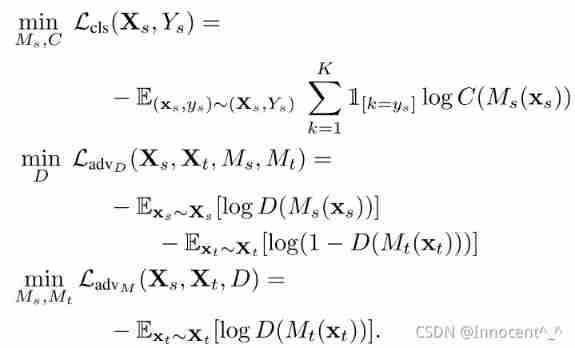 | ADDA Unconstrained optimization formula of the model (unconstrained optimization), See the following formula interpretation section for the specific calculation meaning | 5,2 |
The meaning of formula calculation











边栏推荐
- 20220603 Mathematics: pow (x, n)
- 3.3 Monte Carlo Methods: case study: Blackjack of Policy Improvement of on- & off-policy Evaluation
- 『快速入门electron』之实现窗口拖拽
- 20220610 other: Task Scheduler
- CV learning notes - scale invariant feature transformation (SIFT)
- 使用密钥对的形式连接阿里云服务器
- Leetcode-513:找树的左下角值
- When the reference is assigned to auto
- Opencv+dlib to change the face of Mona Lisa
- [graduation season] the picture is rich, and frugality is easy; Never forget chaos and danger in peace.
猜你喜欢
Leetcode-112:路径总和
Deep Reinforcement learning with PyTorch

LeetCode - 1172 餐盘栈 (设计 - List + 小顶堆 + 栈))

CV learning notes - clustering

Opencv histogram equalization

Leetcode - 933 number of recent requests
Leetcode - 1670 conception de la file d'attente avant, moyenne et arrière (conception - deux files d'attente à double extrémité)

2.2 DP: Value Iteration & Gambler‘s Problem

Opencv notes 20 PCA
CV learning notes convolutional neural network
随机推荐
What did I read in order to understand the to do list
使用sed替换文件夹下文件
Leetcode - 706 design hash mapping (Design)*
LeetCode - 900. RLE 迭代器
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
Leetcode-513: find the lower left corner value of the tree
QT detection card reader analog keyboard input
Opencv note 21 frequency domain filtering
20220531数学:快乐数
LeetCode - 673. 最长递增子序列的个数
20220603数学:Pow(x,n)
Anaconda安装包 报错packagesNotFoundError: The following packages are not available from current channels:
openCV+dlib实现给蒙娜丽莎换脸
[combinatorics] combinatorial existence theorem (three combinatorial existence theorems | finite poset decomposition theorem | Ramsey theorem | existence theorem of different representative systems |
MySQL root user needs sudo login
Leetcode - 933 number of recent requests
QT creator uses OpenCV Pro add
20220606 Mathematics: fraction to decimal
Anaconda installation package reported an error packagesnotfounderror: the following packages are not available from current channels:
Notes - regular expressions