当前位置:网站首页>【深度学习】mmclassification mmcls 实战多标签分类任务教程,分类任务
【深度学习】mmclassification mmcls 实战多标签分类任务教程,分类任务
2022-08-05 10:40:00 【XD742971636】
文章目录
官方的教程https://mmclassification.readthedocs.io/zh_CN/latest/install.html过于官方,还没csdnhttps://blog.csdn.net/litt1e/article/details/125315752?spm=1001.2014.3001.5502写得好。我也需要做一个多标签任务,百度paddlecls暴露了一些缺点(转推理有BUG、训练过程可视化不是很理想)给我所以尝试用这个mmclassification框架来做一做这个任务。
一、 环境
python3.7
matplotlib 3.5.2
onnx 1.12.0
onnx-simplifier 0.4.3
onnxruntime-gpu 1.12.0
opencv-contrib-python 4.5.2.52
opencv-python 4.5.2.52
thop 0.1.1.post2207130030
threadpoolctl 3.1.0
torch 1.12.0
torchaudio 0.12.0
torchvision 0.13.0
tqdm 4.64.0
mmcls 0.23.2 /ssd/xiedong/workplace/mmclassification
mmcv-full 1.6.1
MNN 2.0.0
单机4显卡Ubuntu 22.04.
二、自定义数据集
Multi-class多类别分类任务
一般的分类任务其实是Multi-class多类别分类任务。举例来说,我们类别有【“猫”,“狗”,“马”】这三个类别,需要模型分别出图像属于某一个类别且只能属于某一个类别。比如下图就应该属于“狗”这个类别,模型输出的是【0 1 0】.
但多类别分类任务有局限性。比如下图的时候,模型就难分了。
而多标签分类任务Multi-Label其实是想表达一张图可能有多个标签类别。那么上图中Multi-Label模型输出的就是【0 1 1】.
如何制作数据集
官方有一些介绍:https://mmclassification.readthedocs.io/zh_CN/latest/api/datasets.html。
还是推荐给出训练文件train.txt,且在这个train.txt中不关有相对图片路径,还有对应标签。
应该保证所有的图片名称是唯一且不动的,当一张图片分属于多个类别,那么多个类别下应该都含有这张图。
这种数据存储方式有助于数据管理,但不知道那些标注平台支持的数据保存样式是怎么样的,我暂时还没接触过。
我的文件夹是这样,每个带数字的文件夹名字都是我的标签:
/images
├── multilabels_new
│ ├── 10103trafficScene
│ ├── 10105scenery_mountain
│ ├── 10106scenery_nightView
│ ├── 10107scenery_snowScene
│ ├── 10108scenery_street
│ ├── 10109scenery_forest
│ ├── 10110scenery_grassland
│ ├── 10111scenery_glacier
│ ├── 10112scenery_deserts
│ ├── 10113scenery_buildings
│ ├── 10114scenery_sea
│ ├── 10115sky_sunriseSunset
│ ├── 10116sky_blueSky
│ ├── 10117sky_starryMoons
│ ├── 10118plant_flower
│ ├── 10119events_perform
│ ├── 10120events_wedding
│ ├── 10121place_restaurant
│ ├── 10122place_bar
│ ├── 10123place_gym
│ ├── 10124place_museum
│ ├── 10125place_insideAirport
│ ├── 10162electronic_mobilePhone
│ ├── 10163electronic_computer
│ ├── 10164electronic_camera
│ ├── 10165electronic_headset
│ ├── 10166electronic_gameMachines
│ ├── 10167electronic_sounder
│ ├── 10172delicious_baking
│ ├── 10173delicious_snack
│ └── 10174delicious_westernstyle
├── multilabels_redundancy
│ ├── 10000temporaryPictures_healthCode
│ ├── 10001temporaryPictures_garage
│ ├── 10104cartoon_scene
│ ├── 10126doc_picchar
│ ├── 10127doc_table
│ ├── 10128doc_productInfo
│ └── 10129doc_textPlaque
而train.txt放于/images下,头几行长这样:
multilabels_new/10103trafficScene/carflow_000111.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/carflow_006468.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/carflow_002543.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img014175.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img008251.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/carflow_003503.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img011382.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img014707.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img014313.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
multilabels_new/10103trafficScene/img022747.jpg 0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
每一行都是文件名和对应label,对应位置的是1。文件名和对应label之间使用的是“\t”分隔。
修改所有图片文件的名字,保证唯一
改为父目录名字带下标:
import os
rootPath = r"/ssd/xiedong/datasets/multilabelsTask/multilabels_new"
cls_names = os.listdir(rootPath)
for cls_name in cls_names:
# 修改文件名称
prefix = cls_name
for k, name in enumerate(sorted(os.listdir(os.path.join(rootPath, cls_name)))):
os.rename(os.path.join(rootPath, cls_name, name),
os.path.join(rootPath, cls_name, prefix + "_" + str(k).zfill(6) + ".jpg"))
生成train.txt 和 val.txt
下面的程序会把所有图片使用opencv读一遍,读不出来就移动到别处。
必须保证没中文路径。
必须是linux系统。
这是个多进程程序,你的CPU可能会爆炸:
import multiprocessing
import os
import random
import re
import shutil
import cv2
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
def checkImageOrMove(img_path_list1, dstpath):
for img_path in img_path_list1:
if re.search(pattern='[\u4e00-\u9fa5]+', string=img_path):
raise Exception("中文文件名")
try:
img = cv2.imread(img_path)
if img is None:
# 移动文件
shutil.move(img_path, dstpath)
print("error:", img_path)
except:
# 移动文件
shutil.move(img_path, dstpath)
print("error:", img_path)
if __name__ == '__main__':
# 统计当前文件夹每个文件的个数
from clsname import all_cls_names
restrain = []
resval = []
dirname = "/ssd/xiedong/datasets/multilabelsTask"
traintxt = os.path.join(dirname, "new_train_labels.txt")
valtxt = os.path.join(dirname, "new_val_labels.txt")
classtxt = os.path.join(dirname, "new_classes.txt")
file_list = listPathAllfiles(dirname)
img_path_list = list(filter(lambda x: str(x).endswith(".jpg") or str(x).endswith(".png"), file_list)) # 只保留图片文件
##--------------------------------------------------
# opencv读取图片,如果读取失败,则移动图片到别的目录去
dst_path = os.path.join("/ssd/xiedong/datasets", "error_img")
if not os.path.exists(dst_path):
os.makedirs(dst_path)
# 多进程
p = multiprocessing.Pool() # 创建一个包含2个进程的进程池
# split files to several parts
for i in range(0, len(img_path_list), 1000):
p.apply_async(func=checkImageOrMove, args=(img_path_list[i:i + 1000], dst_path,)) # 往池子里加一个异步执行的子进城
p.close() # 等子进程执行完毕后关闭进程池
p.join() # 主进程等待
##--------------------------------------------------
file_list = listPathAllfiles(dirname)
img_path_list = list(filter(lambda x: str(x).endswith(".jpg") or str(x).endswith(".png"), file_list)) # 只保留图片文件
classes_cls = sorted(set(map(lambda x: os.path.dirname(x).split("/")[-1], img_path_list))) # linux 类别名称
res = {
}
for name in img_path_list: # 图片路径
class_name = os.path.dirname(name).split("/")[-1] # 图片所属类别
res[class_name] = res.get(class_name, 0) + 1 # 统计每个类别的图片数量
new_class_names = []
for k in sorted(res.keys()):
if k[5:] not in all_cls_names: # 文件夹除了前几个数字就是真的类别名称,必须存在于all_cls_names中
print("不存在", k)
raise Exception("不存在")
else:
# print(k[5:])
new_class_names.append(k) # 总类别太多,这里只有部分类别。new_class_names是已有的类别名称
new_class_names = sorted(new_class_names) # new_class_names是真实存在的所有类别,且有序,带数字的
print("目前的类别数量:", len(new_class_names)) # new_class_names是真实存在的所有类别,且有序,带数字的
open(classtxt, "w").write("\n".join(new_class_names)) # 写到文件中
labels_list = [0 for i in range(0, len(new_class_names))] # label的样子
# 形成 {图片:标签,...}字典
imgLbDict = {
}
for path1 in list(filter(lambda x: not str(x).endswith(".txt"), sorted(os.listdir(dirname)))):
for path2 in sorted(os.listdir(os.path.join(dirname, path1))): # 二级目录是类别名称
files = os.listdir(os.path.join(dirname, path1, path2))
imgFileNames = list(filter(lambda x: str(x).endswith(".jpg") or str(x).endswith(".png"), files))
print(path1, path2, "图片数量:", len(imgFileNames))
for index, imgFileName in enumerate(imgFileNames):
if imgFileName not in imgLbDict:
labels_list_copy = labels_list.copy()
labels_list_copy[new_class_names.index(path2)] = 1 # 对应类别给到1
imgLbDict[imgFileName] = {
"path1": path1, "clsName": path2,
"labels": labels_list_copy}
else:
labels_list_copy = imgLbDict[imgFileName]["labels"]
labels_list_copy[new_class_names.index(path2)] = 1
imgLbDict[imgFileName]["labels"] = labels_list_copy
# 有的类别样本太多不合适,这里抽取训练集和验证集
maxlen = 1200 # 每个类别最多的训练集和验证集的总和样本数量
cls_num_stat = {
}
for imgname in random.sample(imgLbDict.keys(), len(imgLbDict)):
cls_name = imgLbDict[imgname]["clsName"]
if cls_num_stat.get(cls_name, 0) < maxlen:
cls_num_stat[cls_name] = cls_num_stat.get(cls_name, 0) + 1
labStr = imgLbDict[imgname]["path1"] + "/" + imgLbDict[imgname][
"clsName"] + "/" + imgname + "\t" + ",".join(list(map(str, imgLbDict[imgname]["labels"])))
if cls_num_stat.get(cls_name, 0) < maxlen * 0.9:
restrain.append(labStr)
else:
resval.append(labStr)
open(traintxt, 'w').write("\n".join(restrain))
open(valtxt, 'w').write("\n".join(resval))
三、如何开启训练,看看源码
官网写了https://mmclassification.readthedocs.io/zh_CN/latest/getting_started.html使用单台机器多个 GPU 进行训练的指令是:./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments] :
dist_train.sh中依旧是在执行train.py:
#!/usr/bin/env bash
CONFIG=$1
GPUS=$2
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--launcher pytorch ${@:3}
train.py中含有:
parser.add_argument('config', help='train config file path')
cfg = Config.fromfile(args.config)
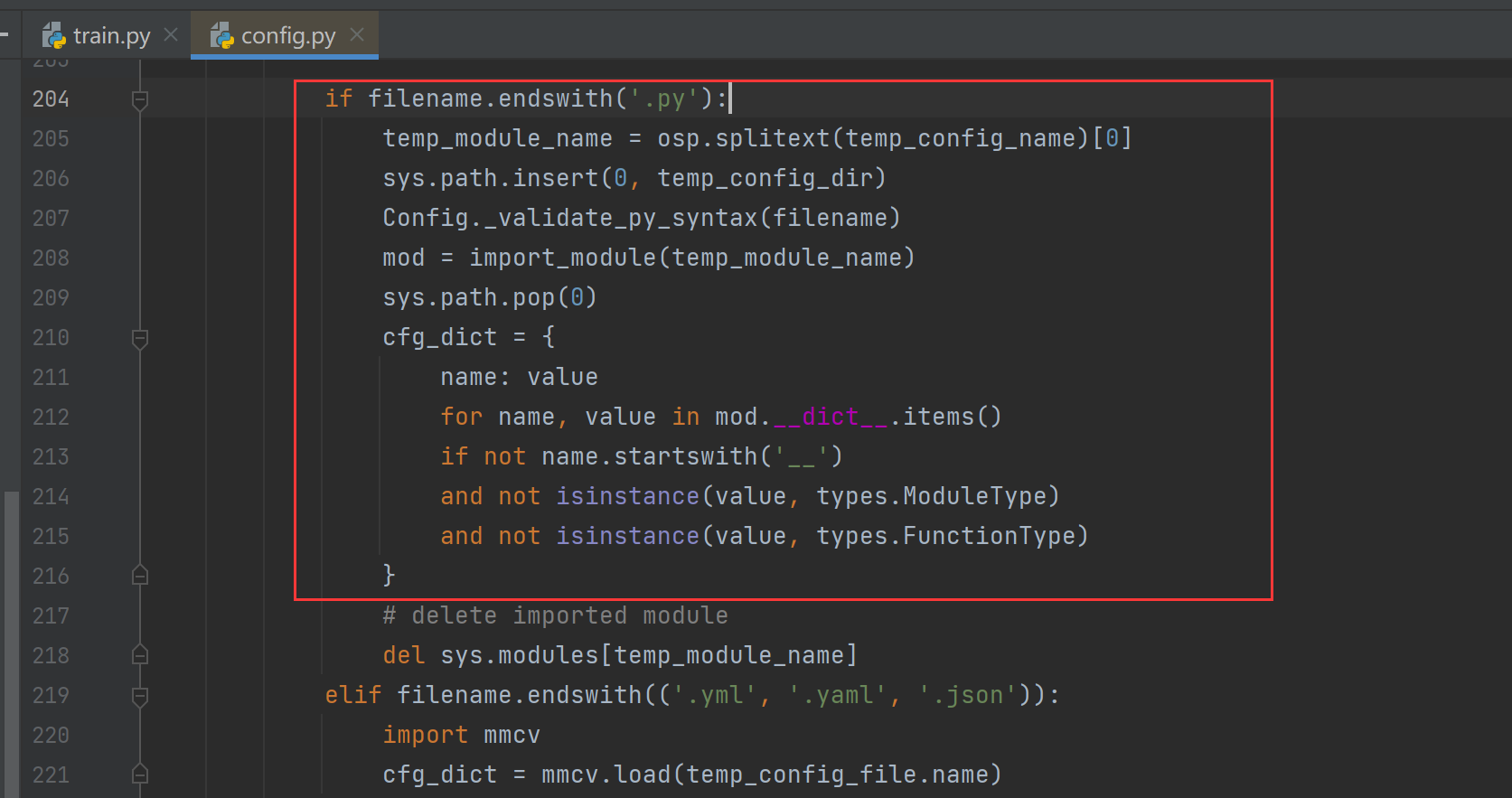
传入到train.py的还是总体配置里的文件,但里面的文件基本依赖_base_中的四个关键文件。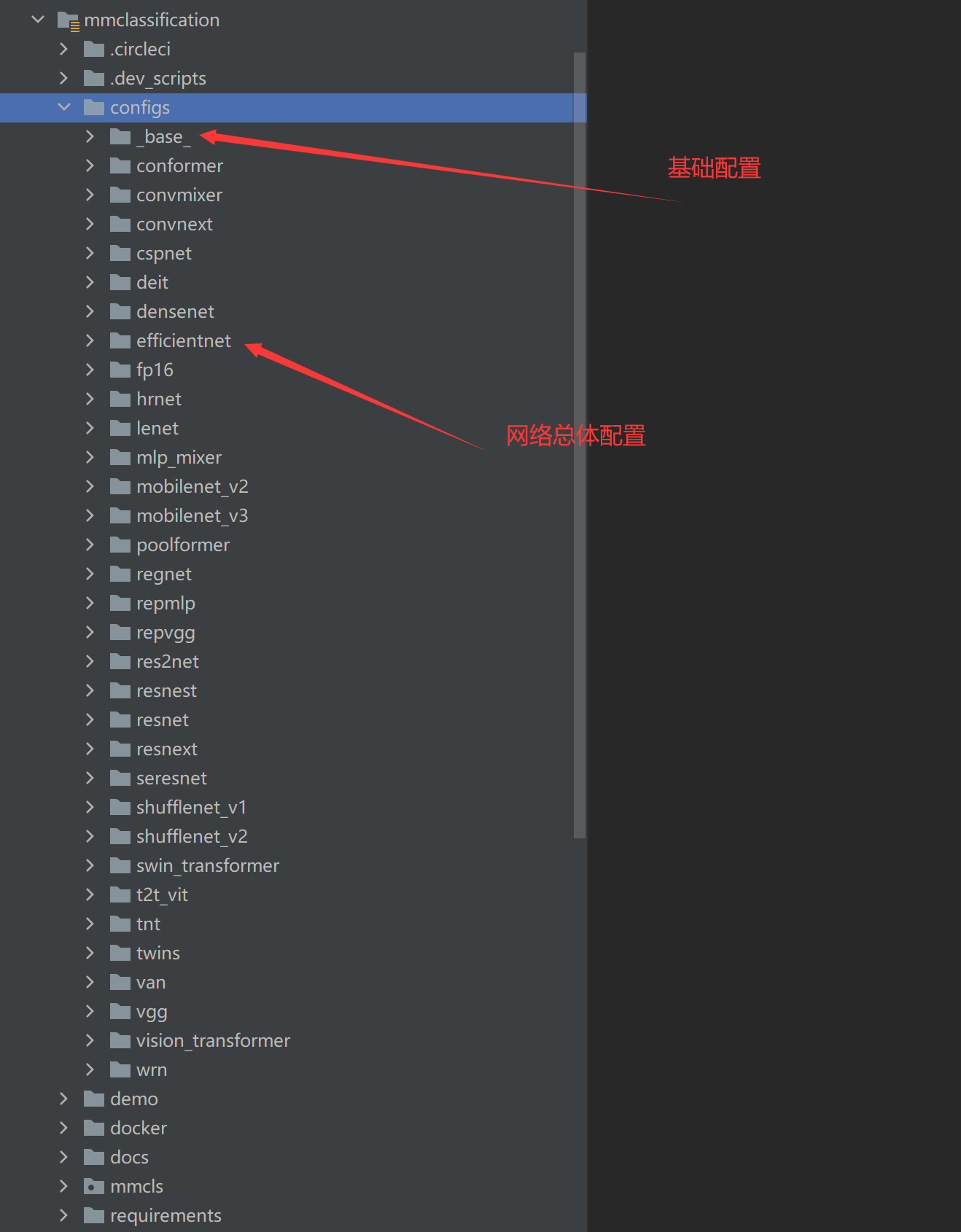
四、如何开启训练,改写文件
选用这个模型
https://mmclassification.readthedocs.io/zh_CN/latest/model_zoo.html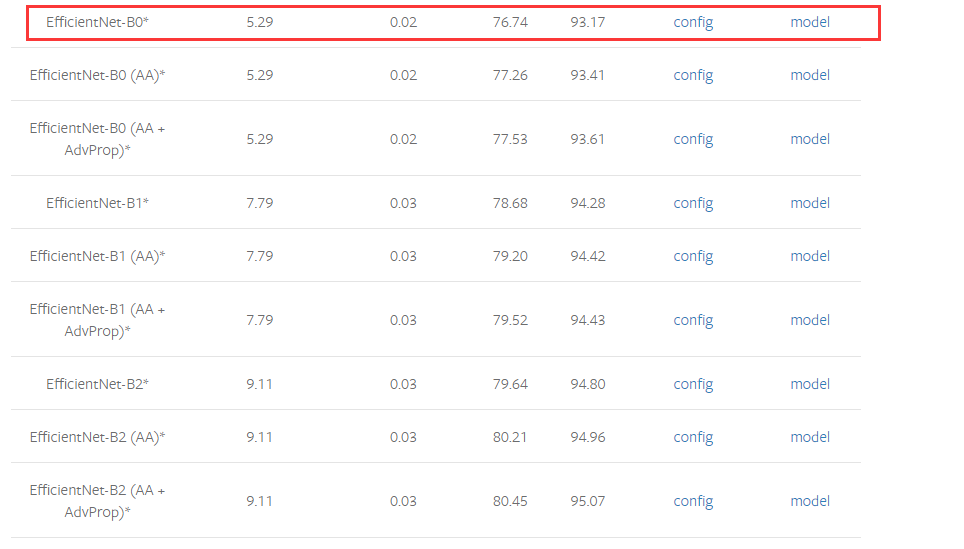
改写base model
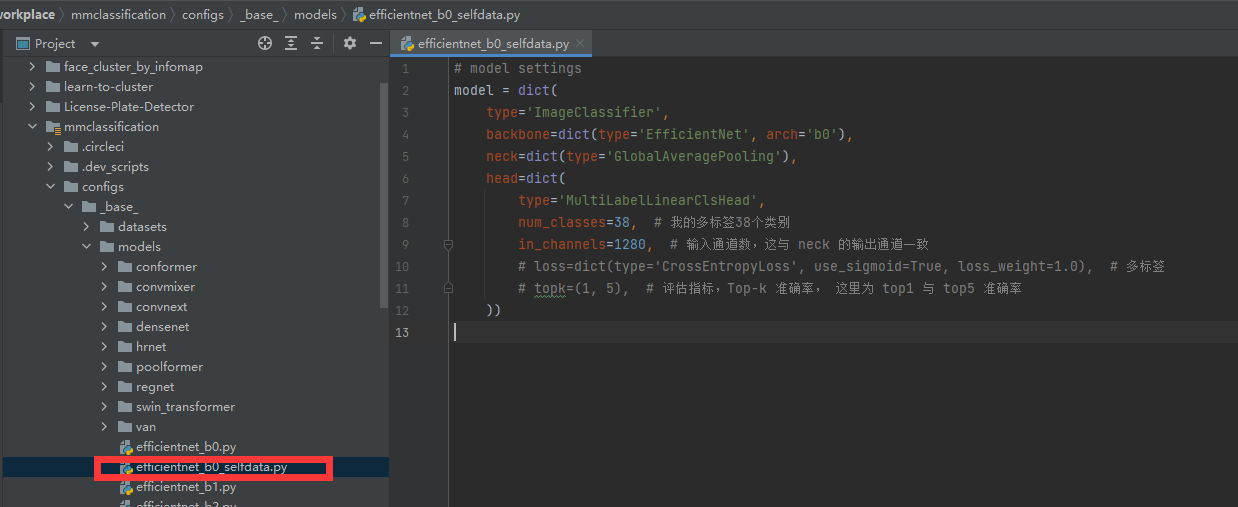
model改为:
# model settings
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(type='EfficientNet', arch='b0'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='MultiLabelLinearClsHead',
num_classes=38, # 我的多标签38个类别
in_channels=1280, # 输入通道数,这与 neck 的输出通道一致
# loss=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0), # 多标签
# topk=(1, 5), # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率
))
源码(MultiLabelLinearClsHead继承自MultiLabelClsHead,默认有loss,MultiLabelLinearClsHead只是在head部分加了线性全连接层):
@HEADS.register_module()
class MultiLabelLinearClsHead(MultiLabelClsHead):
"""Linear classification head for multilabel task. Args: num_classes (int): Number of categories. in_channels (int): Number of channels in the input feature map. loss (dict): Config of classification loss. init_cfg (dict | optional): The extra init config of layers. Defaults to use dict(type='Normal', layer='Linear', std=0.01). """
def __init__(self,
num_classes,
in_channels,
loss=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='mean',
loss_weight=1.0),
init_cfg=dict(type='Normal', layer='Linear', std=0.01)):
super(MultiLabelLinearClsHead, self).__init__(
loss=loss, init_cfg=init_cfg)
if num_classes <= 0:
raise ValueError(
f'num_classes={
num_classes} must be a positive integer')
self.in_channels = in_channels
self.num_classes = num_classes
self.fc = nn.Linear(self.in_channels, self.num_classes)
改写base dataset
这里的有点麻烦,里面的一些参数肯定得弄清楚是啥,所以深入看了代码。如果是multi-class任务,直接看教程https://mmclassification.readthedocs.io/zh_CN/latest/tutorials/new_dataset.html即可,比较简单。多标签就得写自己的类,实现load_annotations方法。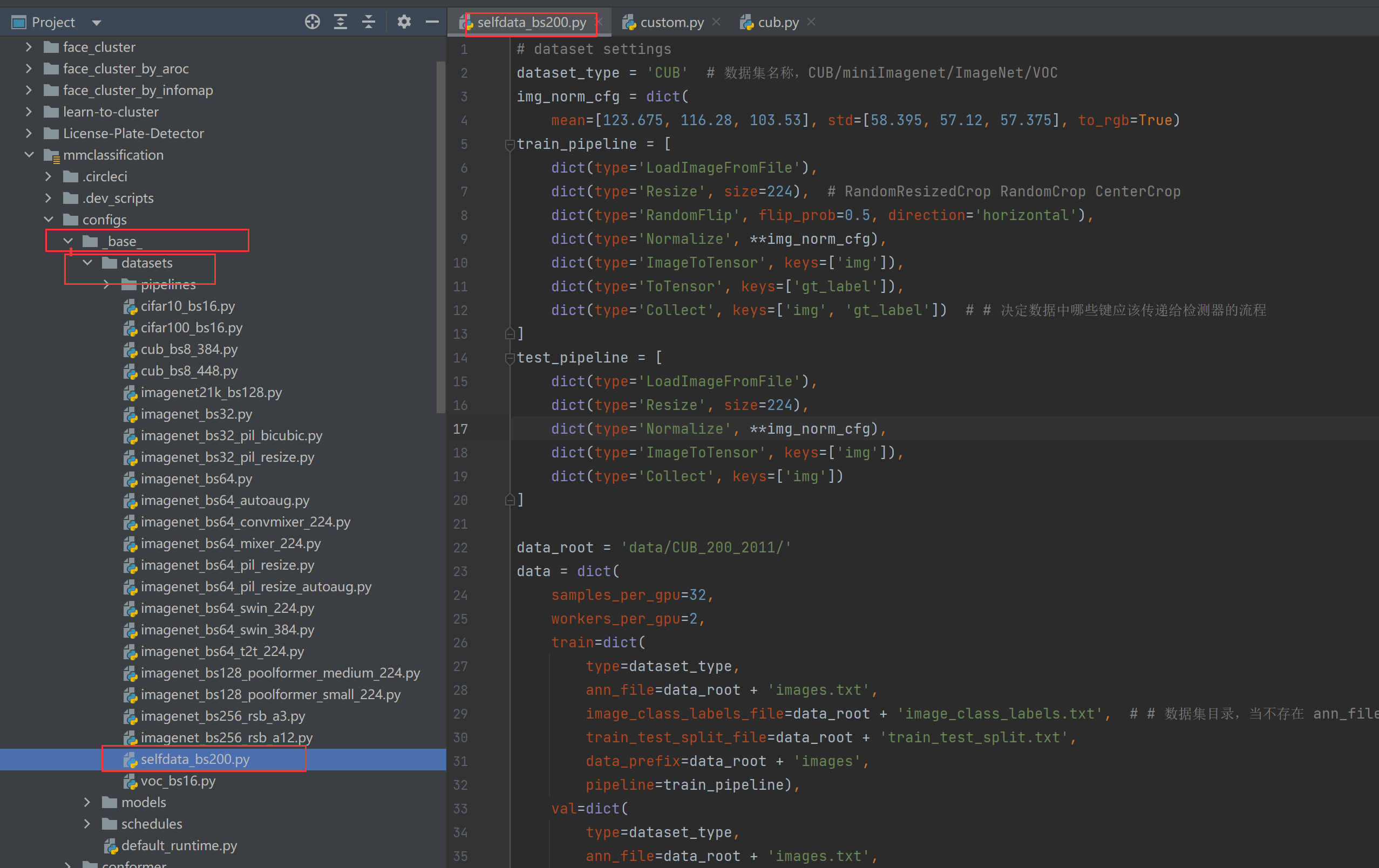
dataset_type = ‘CUB’ 这句不能乱填,应该写成CUB、CustomDataset等这种被@DATASETS.register_module()装饰的类。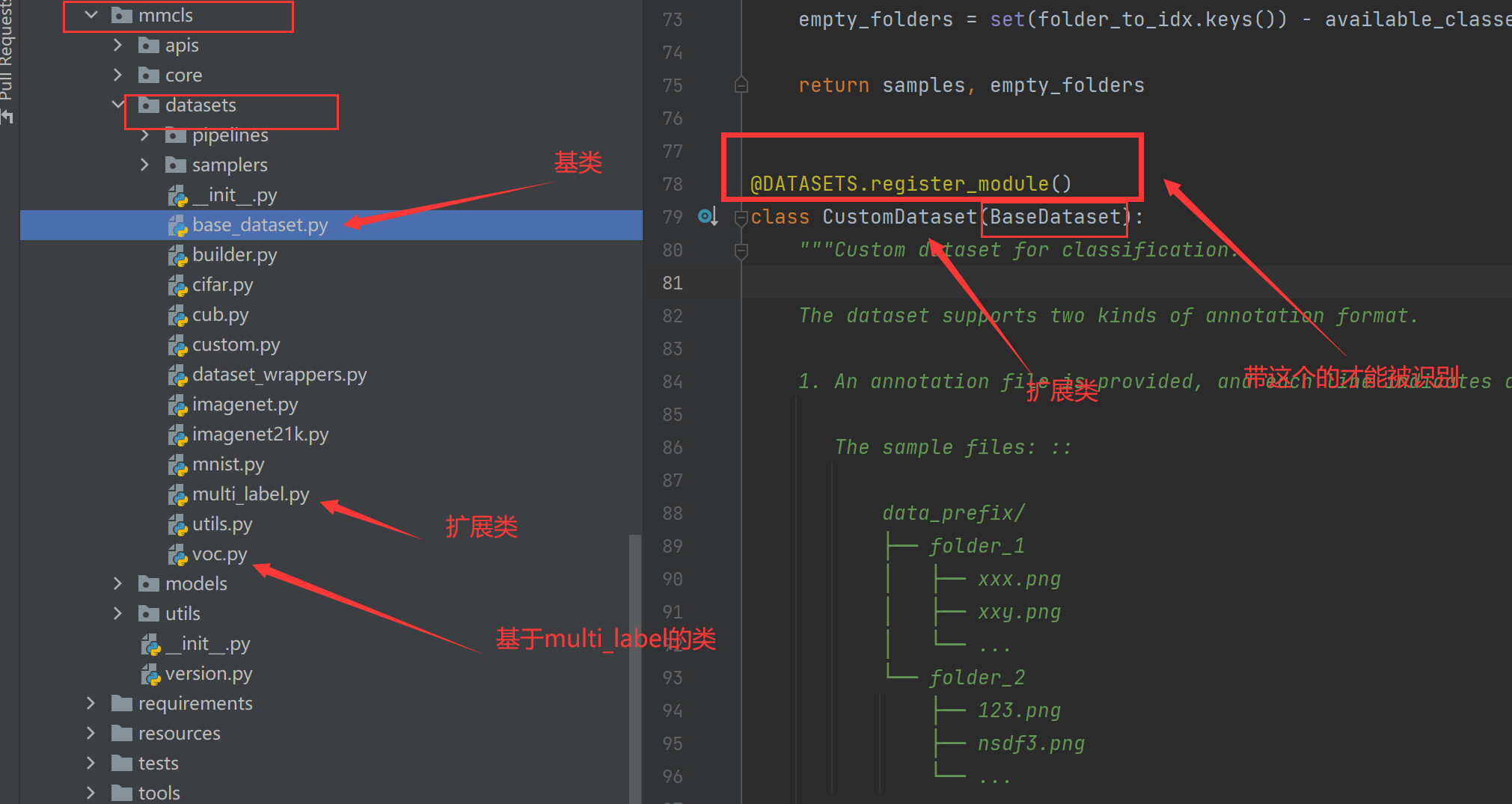
在了解BaseDataset、MultiLabelDataset、VOC 这几个与多标签有关的类之后,定义一个属于我们的类: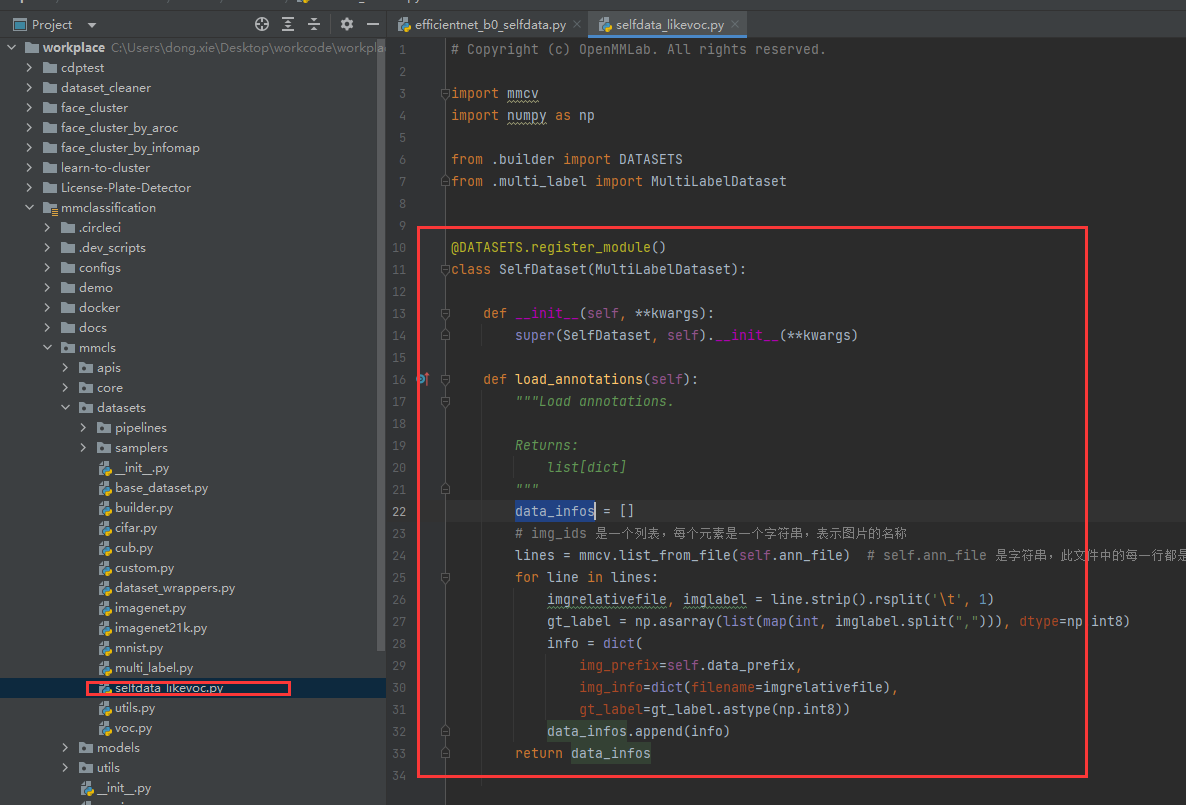
改写的SelfDataset(SelfDataset的load_annotations返回的是list[dict],每一个dict里面img_prefix是一张图片根目录【配置文件里给进来】,img_info是一张图片相对路径,gt_label是对应的labelslist【比如我38个类别的gt_label就应该是38个0或者1的组合】):
# Copyright (c) OpenMMLab. All rights reserved.
import mmcv
import numpy as np
from .builder import DATASETS
from .multi_label import MultiLabelDataset
@DATASETS.register_module()
class SelfDataset(MultiLabelDataset):
def __init__(self, **kwargs):
super(SelfDataset, self).__init__(**kwargs)
def load_annotations(self):
"""Load annotations. Returns: list[dict] """
data_infos = []
# img_ids 是一个列表,每个元素是一个字符串,表示图片的名称
lines = mmcv.list_from_file(self.ann_file) # self.ann_file 是字符串,此文件中的每一行都是我们自己存的
for line in lines:
imgrelativefile, imglabel = line.strip().rsplit('\t', 1)
gt_label = np.asarray(list(map(int, imglabel.split(","))), dtype=np.int8)
info = dict(
img_prefix=self.data_prefix,
img_info=dict(filename=imgrelativefile),
gt_label=gt_label.astype(np.int8))
data_infos.append(info)
return data_infos
此外需要把这个类注册到datasets的init: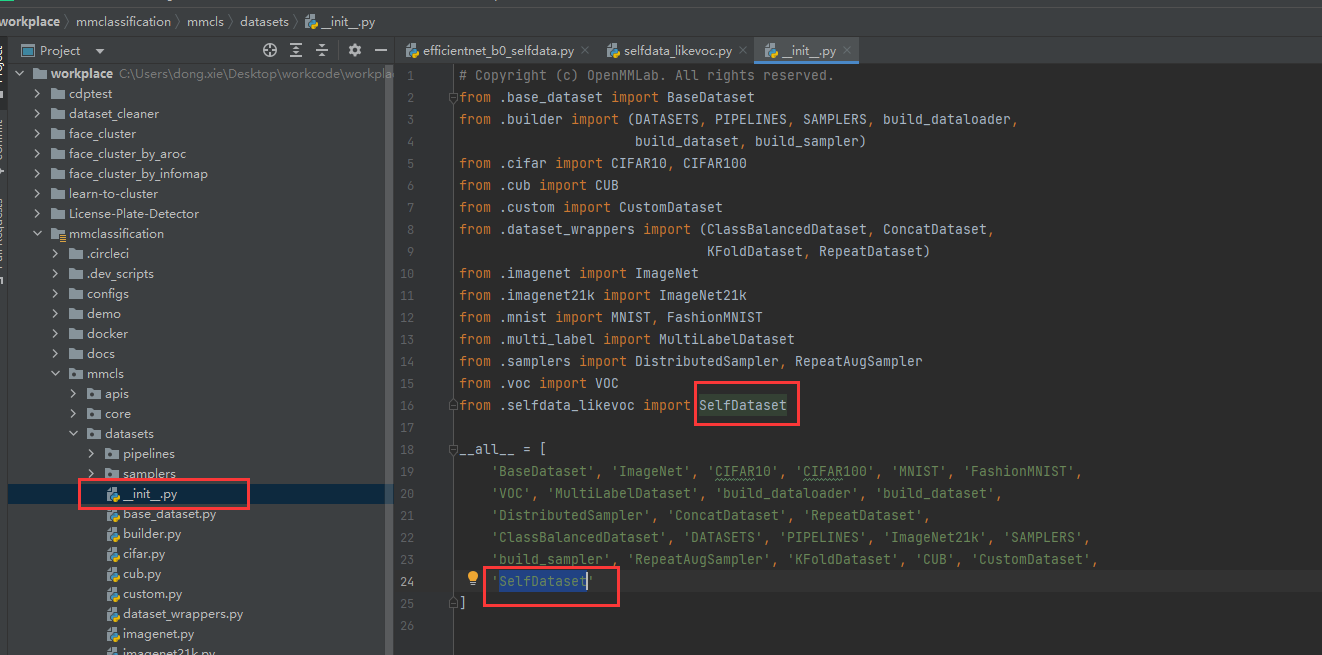
此外还注意到BaseDataset这个类在做什么,data_prefix是后面在配置文件给进去的图片根目录,pipeline是由Compose组合起来的pipeline处理,self.CLASSES是给进去的classes决定的(给文件路径进去后会读取每一行作为一个类别),self.ann_file是在配置文件给进去的文件路径,self.data_infos是由load_annotations对self.ann_file处理得到的真实dataset。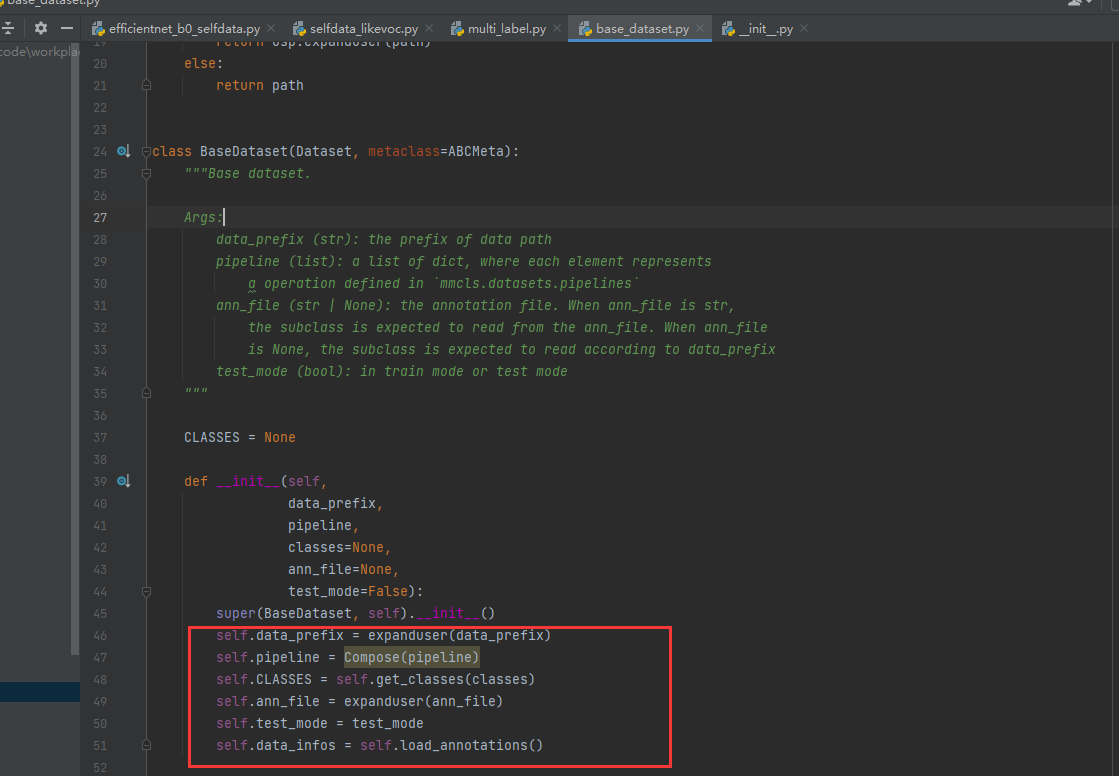
改写BaseDataset中__getitem__方法,也就是prepare_data方法,prepare_data方法接受idx,然后按照pipeline处理后输出,问题出在pipeline,有时候图片损坏读不出来,所以这里try上,然后except里读取第一张图片出去。这不是一个好的办法,等后面看到dataloader的时候在那里try更好,直接抛弃这个batch的训练。或者opencv把所有图都读一遍,先把损坏的图删除出去。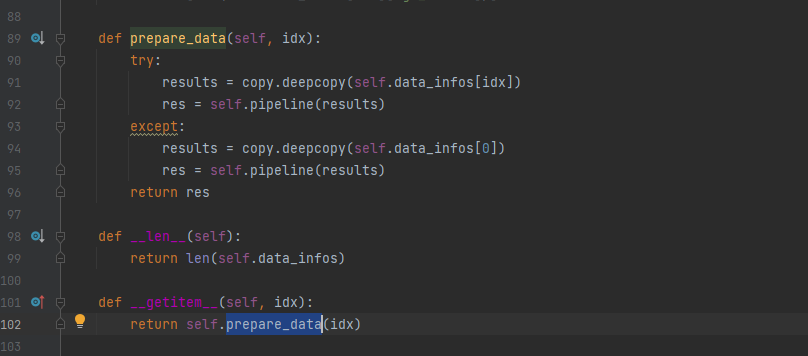
终于可以到这里: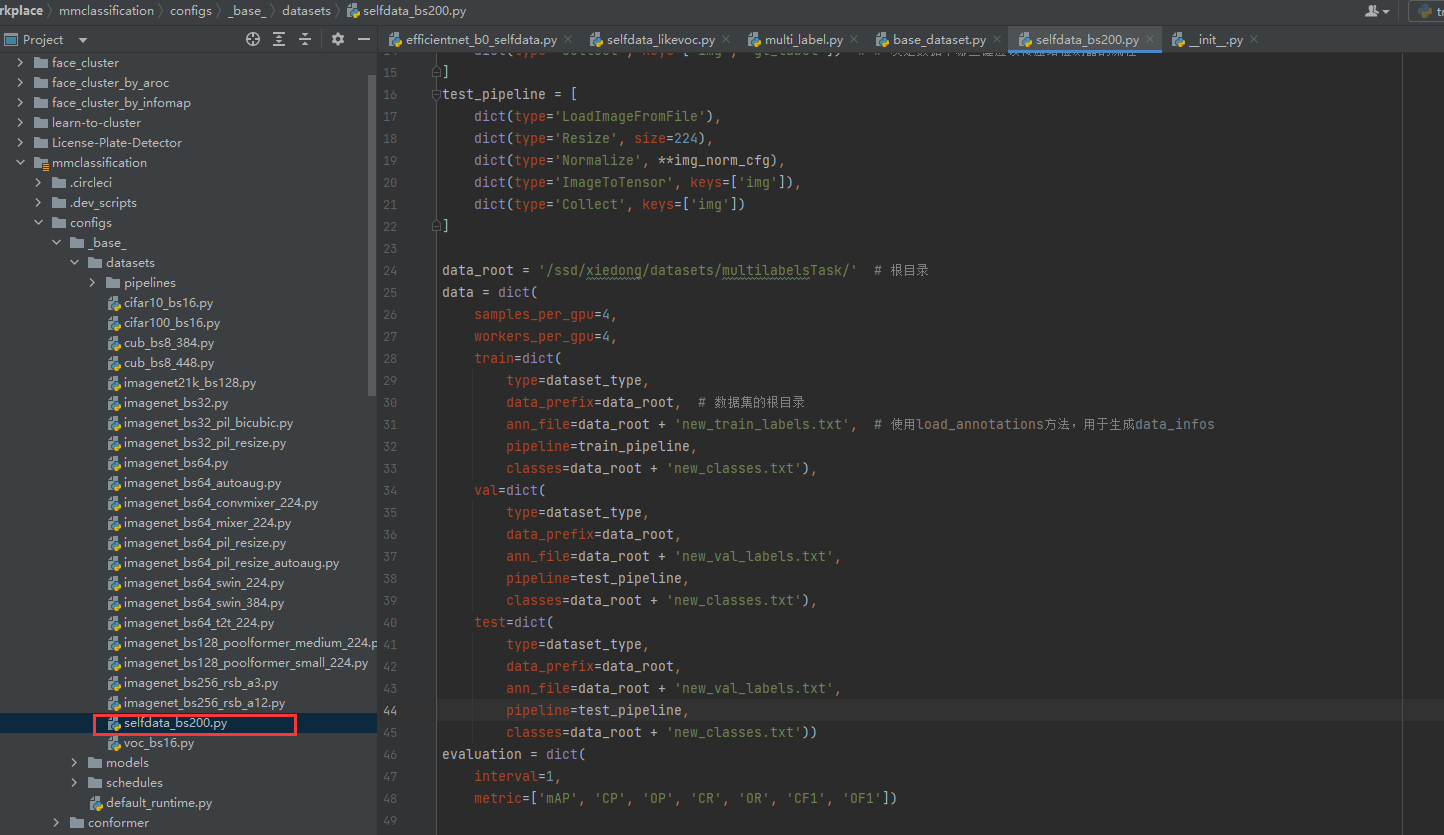
给出自己的datasets配置:
# dataset settings
dataset_type = 'SelfDataset' # 数据集名称
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=224), # RandomResizedCrop RandomCrop CenterCrop
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label']) # # 决定数据中哪些键应该传递给检测器的流程
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data_root = '/ssd/xiedong/datasets/multilabelsTask/' # 根目录
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_prefix=data_root, # 数据集的根目录
ann_file=data_root + 'new_train_labels.txt', # 使用load_annotations方法,用于生成data_infos
pipeline=train_pipeline,
classes=data_root + 'new_classes.txt'),
val=dict(
type=dataset_type,
data_prefix=data_root,
ann_file=data_root + 'new_val_labels.txt',
pipeline=test_pipeline,
classes=data_root + 'new_classes.txt'),
test=dict(
type=dataset_type,
data_prefix=data_root,
ann_file=data_root + 'new_val_labels.txt',
pipeline=test_pipeline,
classes=data_root + 'new_classes.txt'))
evaluation = dict(
interval=1,
metric=['mAP', 'CP', 'OP', 'CR', 'OR', 'CF1', 'OF1'])
改写schedules
优化器和学习策略: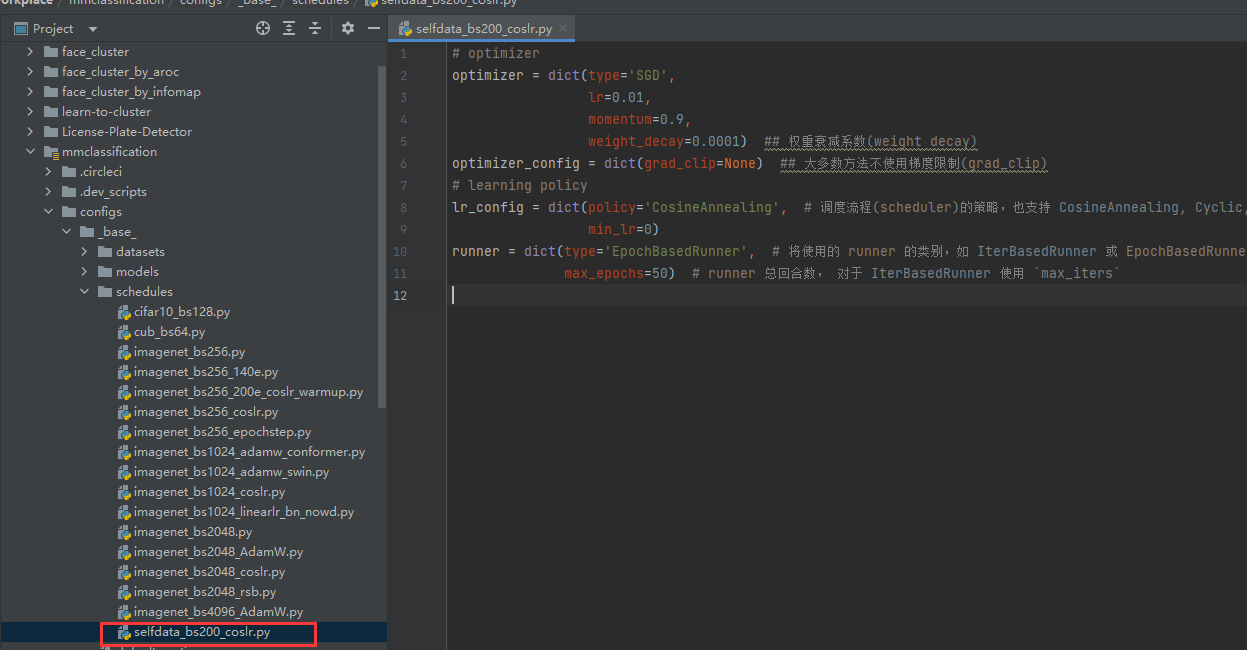
代码:
# optimizer
optimizer = dict(type='SGD',
lr=0.01,
momentum=0.9,
weight_decay=0.0001) ## 权重衰减系数(weight decay)
optimizer_config = dict(grad_clip=None) ## 大多数方法不使用梯度限制(grad_clip)
# learning policy
lr_config = dict(policy='CosineAnnealing', # 调度流程(scheduler)的策略,也支持 CosineAnnealing, Cyclic, 等
min_lr=0)
runner = dict(type='EpochBasedRunner', # 将使用的 runner 的类别,如 IterBasedRunner 或 EpochBasedRunner
max_epochs=50) # runner 总回合数, 对于 IterBasedRunner 使用 `max_iters`
改写default_runtime
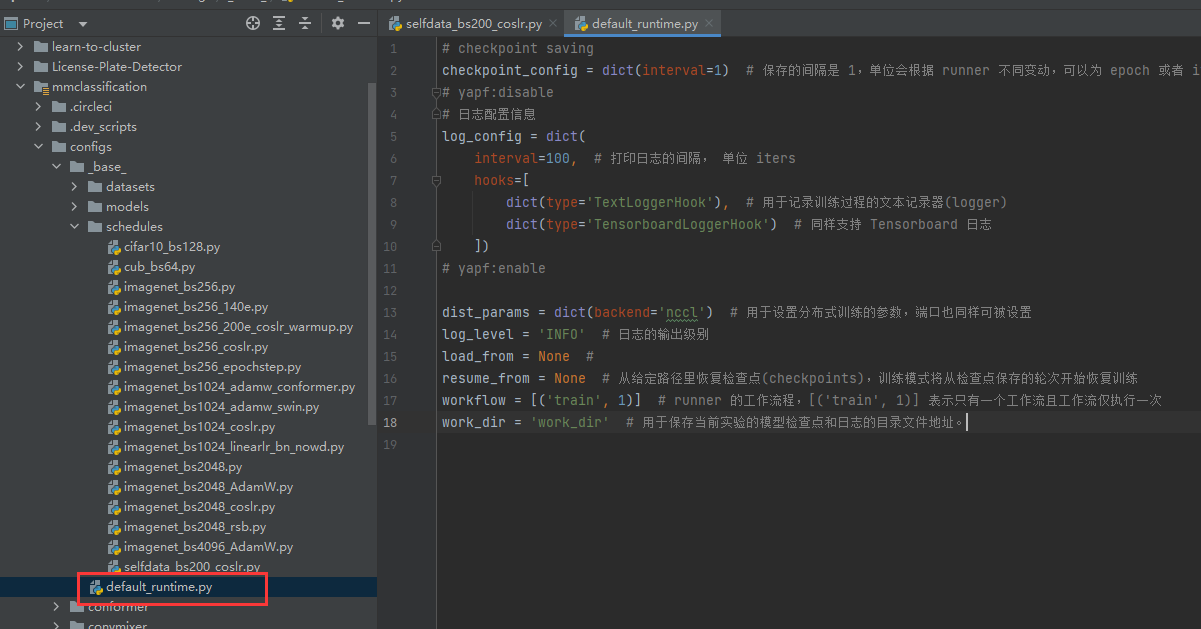
代码:
# checkpoint saving
checkpoint_config = dict(interval=1) # 保存的间隔是 1,单位会根据 runner 不同变动,可以为 epoch 或者 iter
# yapf:disable
# 日志配置信息
log_config = dict(
interval=100, # 打印日志的间隔, 单位 iters
hooks=[
dict(type='TextLoggerHook'), # 用于记录训练过程的文本记录器(logger)
dict(type='TensorboardLoggerHook') # 同样支持 Tensorboard 日志
])
# yapf:enable
dist_params = dict(backend='nccl') # 用于设置分布式训练的参数,端口也同样可被设置
log_level = 'INFO' # 日志的输出级别
load_from = None #
resume_from = None # 从给定路径里恢复检查点(checkpoints),训练模式将从检查点保存的轮次开始恢复训练
workflow = [('train', 1)] # runner 的工作流程,[('train', 1)] 表示只有一个工作流且工作流仅执行一次
work_dir = 'work_dir' # 用于保存当前实验的模型检查点和日志的目录文件地址。
改写 最终模型总配置
在这里也可以写之前的一些配置,默认会优先采用这里的,而不是_base_里面的: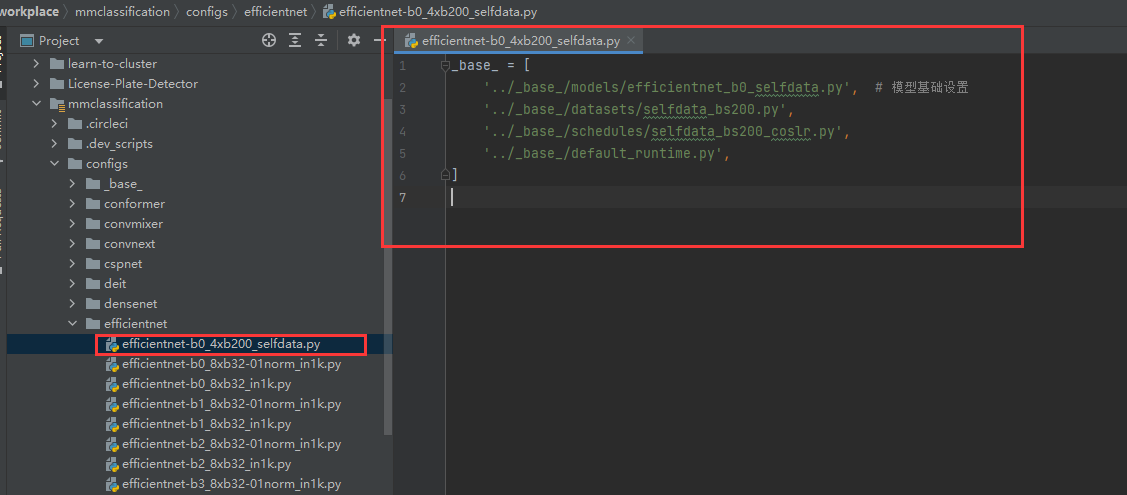
代码:
_base_ = [
'../_base_/models/efficientnet_b0_selfdata.py', # 模型基础设置
'../_base_/datasets/selfdata_bs200.py',
'../_base_/schedules/selfdata_bs200_coslr.py',
'../_base_/default_runtime.py',
]
五、开始训练
小试牛刀
在mmclassification中执行指令,
单机多卡(我这里四张卡),work-dir给出了结果存储路径:
./tools/dist_train.sh configs/efficientnet/efficientnet-b0_4xb200_selfdata.py 4 --work-dir worktest
能看到一轮训练完成,损失不断下降,val验证了模型的metric,这样就算是成功开启训练了: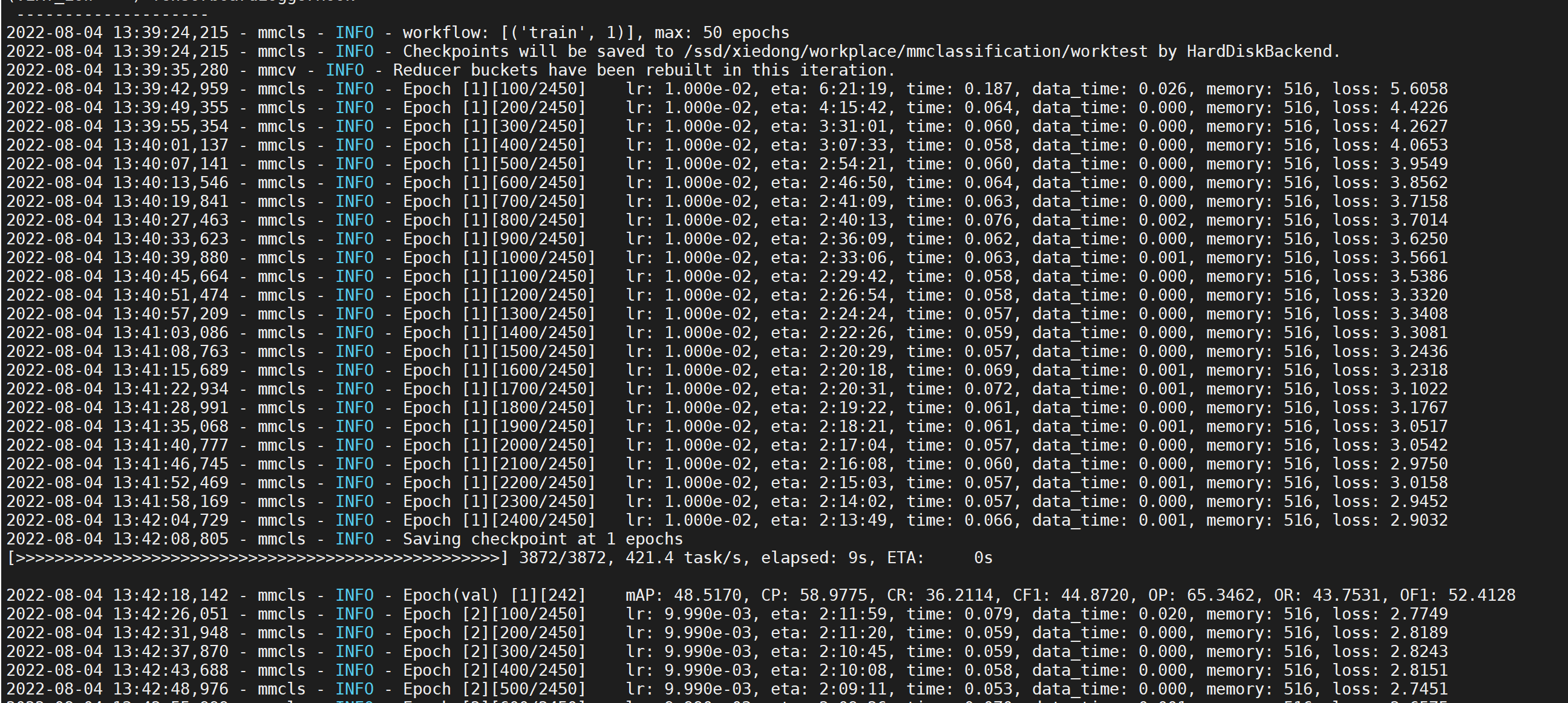
意外中断恢复训练:
./tools/dist_train.sh configs/efficientnet/efficientnet-b0_4xb200_selfdata.py 4 --resume-from worktest/latest.pth --work-dir worktest
一个好的训练调整
修改batchsize: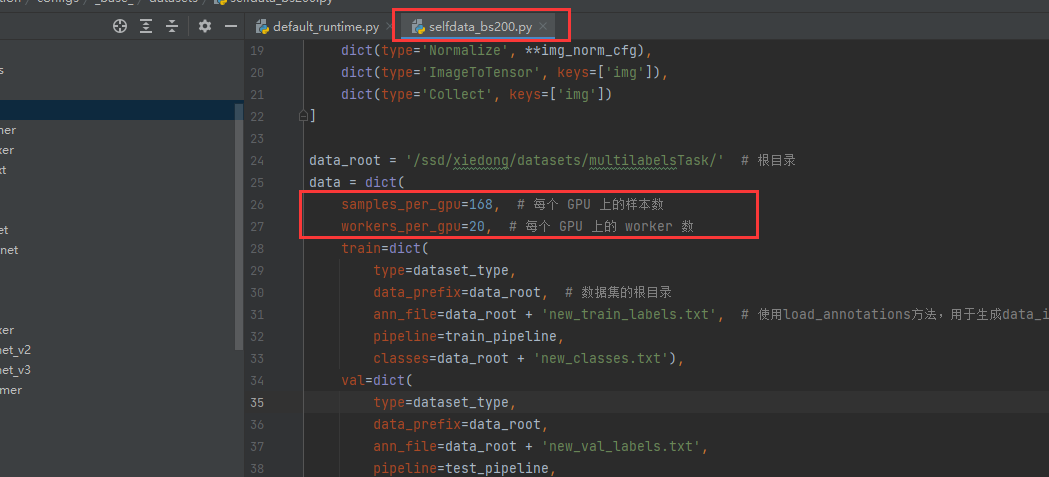
resume_from或者load_from或者work_dir在这里指定就好了,反正这几个参数最终是给到train.py去的: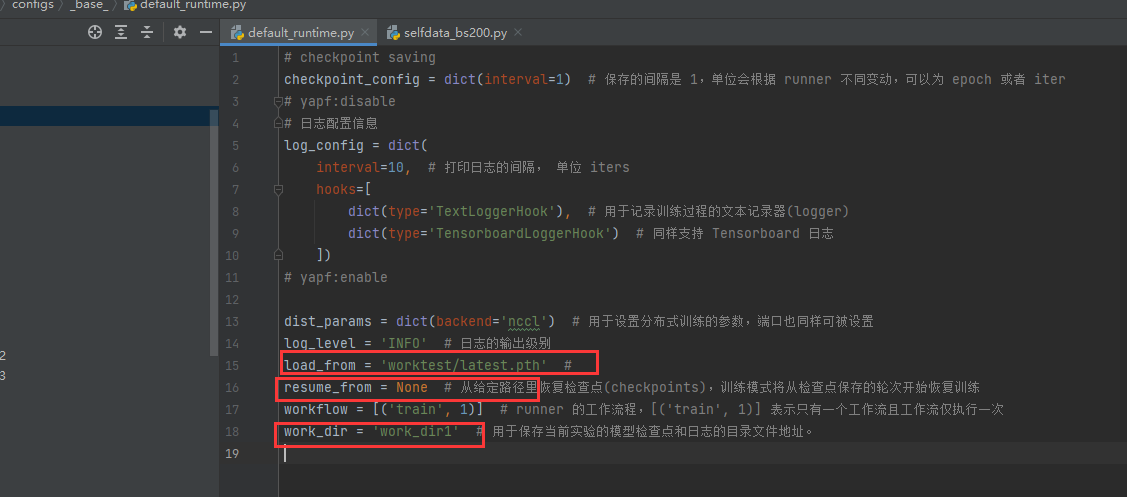
运行这个指令执行训练就行了:
./tools/dist_train.sh configs/efficientnet/efficientnet-b0_4xb200_selfdata.py 4
能看到占用稍微合理了一些: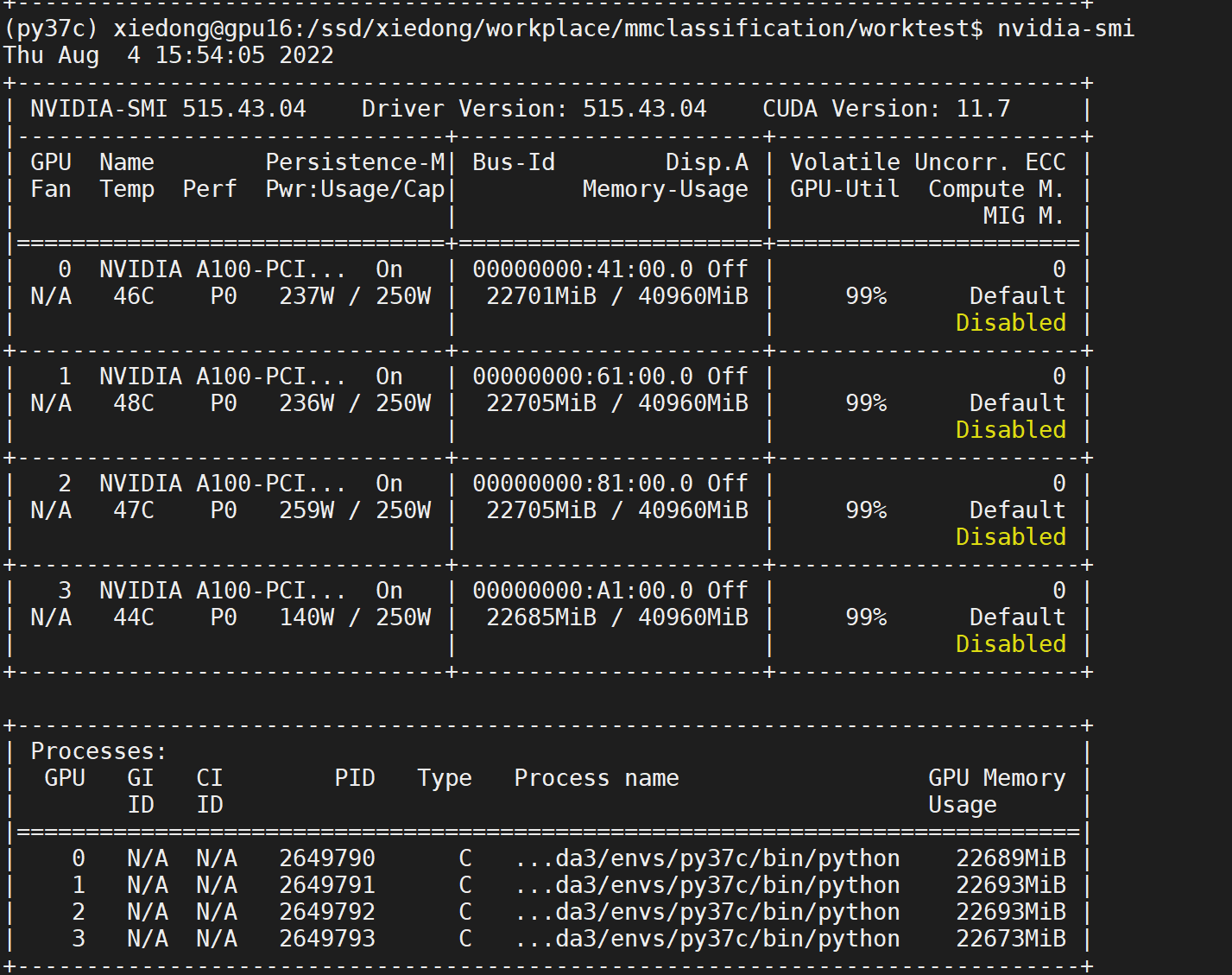
六、TensorboardLoggerHook
tfboard日志被保存到worktest/tf_logs/,即是设置的保存路径里的子路径tf_logs。
TensorboardLoggerHook源码是https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/logger/tensorboard.py这个mmcv里的,要改写估计是有点麻烦。
贴个Tensorboard介绍https://blog.csdn.net/u010099080/article/details/77426577: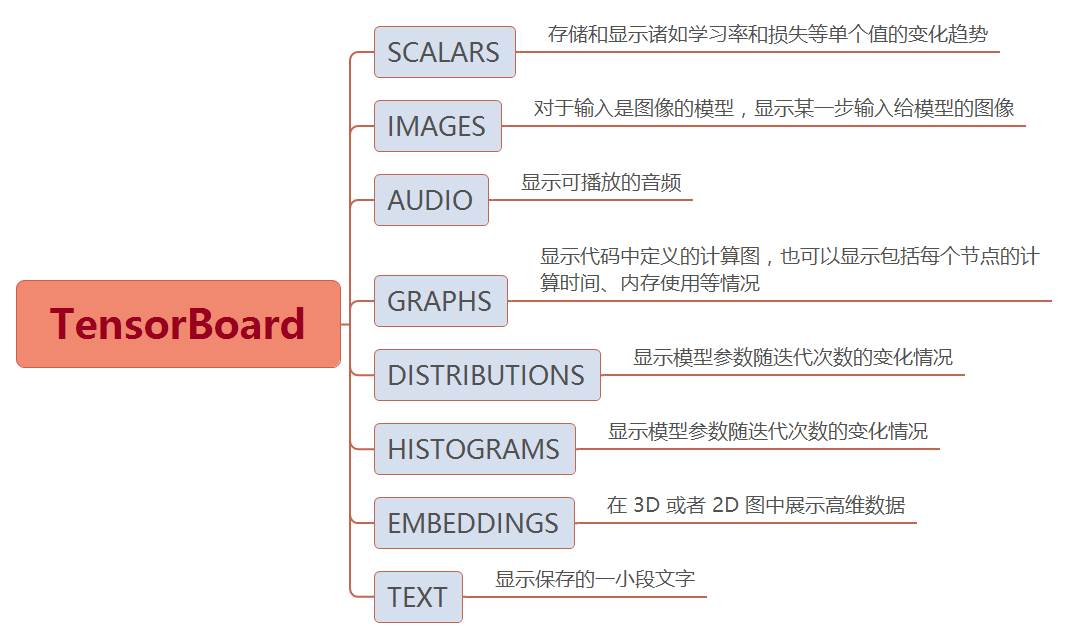
由于在之前default_runtime中设置了TensorboardLoggerHook才有这个日志,在命令行中执行:
tensorboard --logdir="/ssd/xiedong/workplace/mmclassification/worktest/tf_logs/"
打开了6006端口在线查看训练过程:
或者使用tensorboard dev upload --logdir '/ssd/xiedong/workplace/mmclassification/worktest/tf_logs/'让每个人都能在线观看。
学习率变化: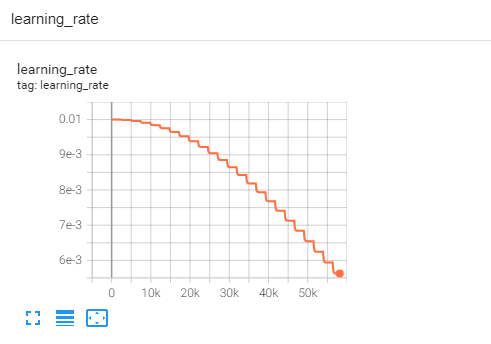
训练过程损失变化: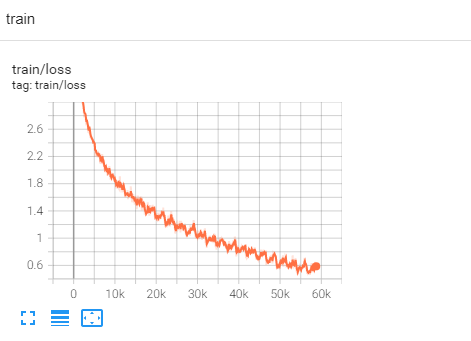
评价指标变化: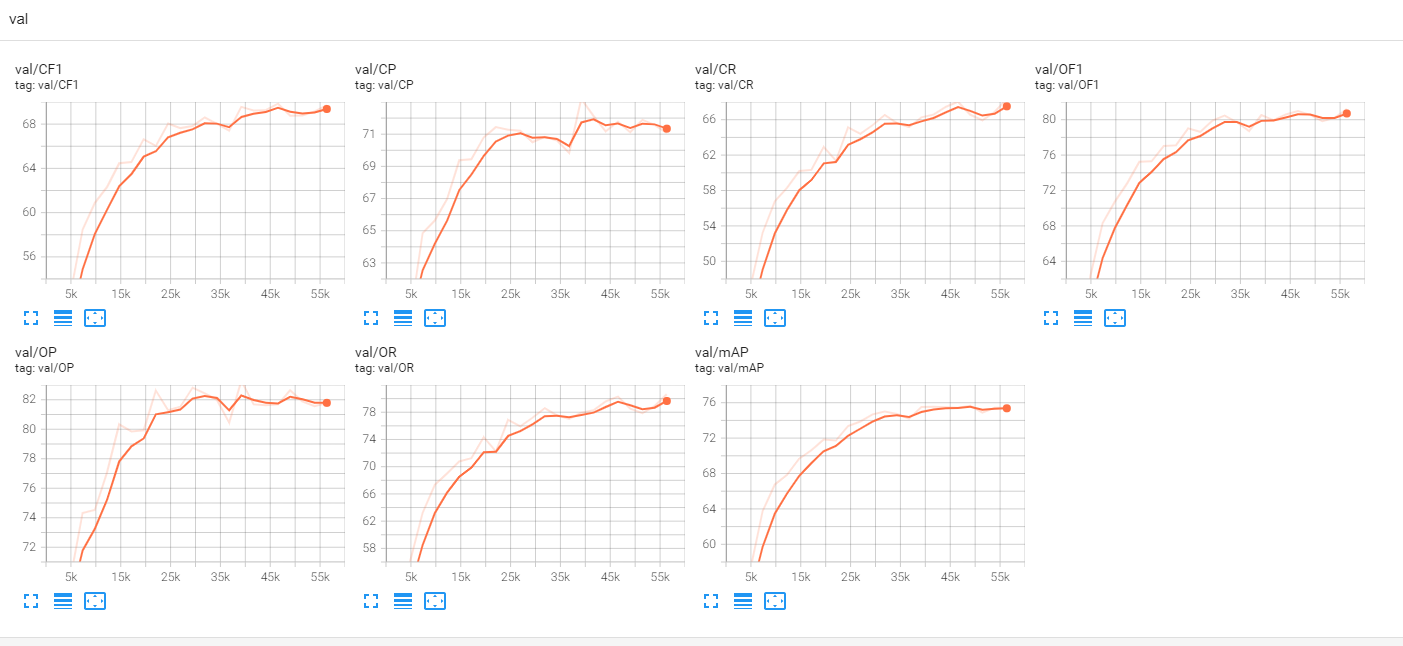
没有特别需求的话,TensorboardLoggerHook是够用了,查看一些指标很方便。
七、评价指标 ‘mAP’, ‘CP’, ‘OP’, ‘CR’, ‘OR’, ‘CF1’, ‘OF1’
在base datasets中配置了:
evaluation = dict(
interval=1,
metric=['mAP', 'CP', 'OP', 'CR', 'OR', 'CF1', 'OF1'])
在mmcls的dataset有类class MultiLabelDataset(BaseDataset),类方法书写了:
def evaluate(self,
results,
metric='mAP',
metric_options=None,
indices=None,
logger=None):
"""Evaluate the dataset. Args: results (list): Testing results of the dataset. metric (str | list[str]): Metrics to be evaluated. Default value is 'mAP'. Options are 'mAP', 'CP', 'CR', 'CF1', 'OP', 'OR' and 'OF1'. metric_options (dict, optional): Options for calculating metrics. Allowed keys are 'k' and 'thr'. Defaults to None logger (logging.Logger | str, optional): Logger used for printing related information during evaluation. Defaults to None. Returns: dict: evaluation results """
if metric_options is None or metric_options == {
}:
metric_options = {
'thr': 0.5}
if isinstance(metric, str):
metrics = [metric]
else:
metrics = metric
allowed_metrics = ['mAP', 'CP', 'CR', 'CF1', 'OP', 'OR', 'OF1']
eval_results = {
}
results = np.vstack(results)
gt_labels = self.get_gt_labels()
if indices is not None:
gt_labels = gt_labels[indices]
num_imgs = len(results)
assert len(gt_labels) == num_imgs, 'dataset testing results should ' \
'be of the same length as gt_labels.'
invalid_metrics = set(metrics) - set(allowed_metrics)
if len(invalid_metrics) != 0:
raise ValueError(f'metric {
invalid_metrics} is not supported.')
if 'mAP' in metrics:
mAP_value = mAP(results, gt_labels)
eval_results['mAP'] = mAP_value
if len(set(metrics) - {
'mAP'}) != 0:
performance_keys = ['CP', 'CR', 'CF1', 'OP', 'OR', 'OF1']
performance_values = average_performance(results, gt_labels,
**metric_options)
for k, v in zip(performance_keys, performance_values):
if k in metrics:
eval_results[k] = v
return eval_results
八、微调网络
教程 https://mmclassification.readthedocs.io/zh_CN/latest/tutorials/finetune.html
看这个文件找预训练模型: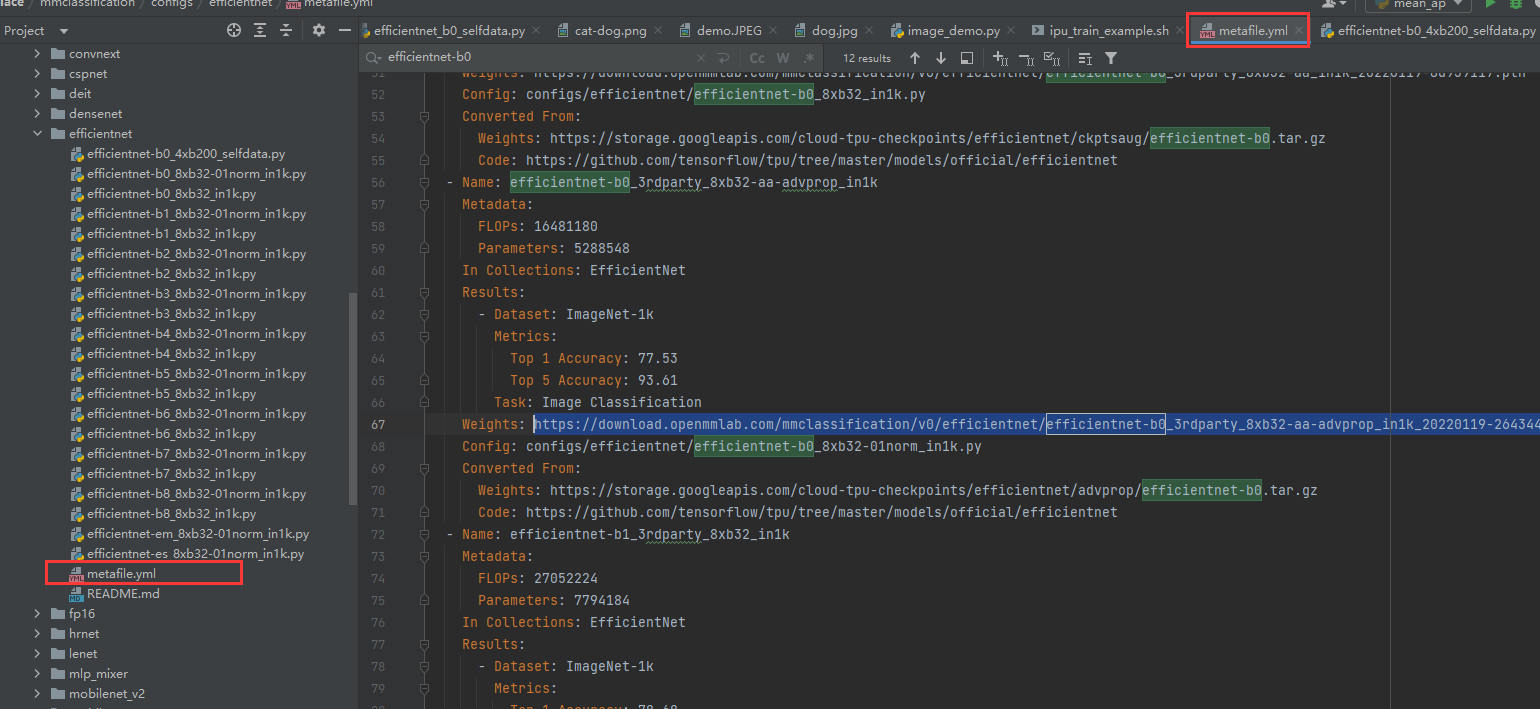
这里的定义会覆盖base里的configs: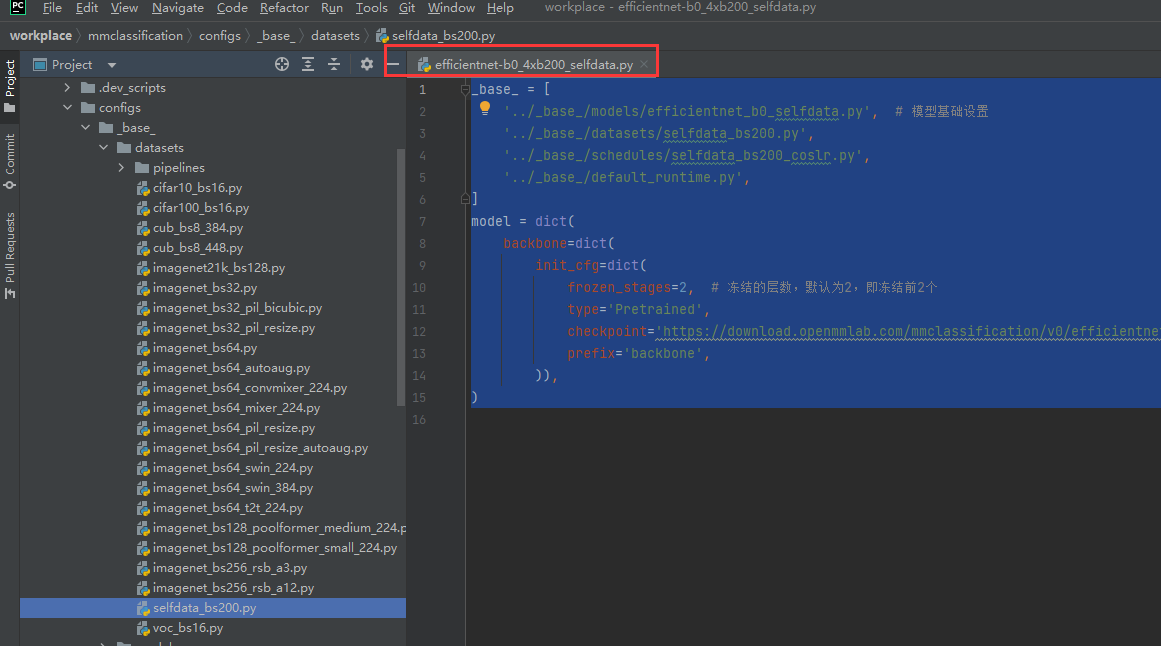
_base_ = [
'../_base_/models/efficientnet_b0_selfdata.py', # 模型基础设置
'../_base_/datasets/selfdata_bs200.py',
'../_base_/schedules/selfdata_bs200_coslr.py',
'../_base_/default_runtime.py',
]
model = dict(
backbone=dict(
init_cfg=dict(
# frozen_stages=2, # 冻结的层数,默认为2,即冻结前2个
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32-aa-advprop_in1k_20220119-26434485.pth',
prefix='backbone',
)),
)
九、数据集包装 类别数据平衡 数据增强
教程:https://mmclassification.readthedocs.io/zh_CN/latest/tutorials/new_dataset.html。
数据集包装是一种可以改变数据集类行为的类,比如将数据集中的样本进行重复,或是将不同类别的数据进行再平衡。由ClassBalancedDataset包裹原训练数据即可完成对类别少图片的进行过采样,但也容易造成对这个类别过拟合。
搭配数据增强会更好,由dict(type='AutoAugment', policies={ {_base_.policy_imagenet}}), 打开数据自动增强。
进行重复采样的数据集需要实现函数 self.get_cat_ids(idx) 以支持 ClassBalancedDataset。
# dataset settings
_base_ = [
'pipelines/auto_aug.py',
]
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=224), # RandomResizedCrop RandomCrop CenterCrop
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='AutoAugment', policies={
{
_base_.policy_imagenet}}),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label']) # # 决定数据中哪些键应该传递给检测器的流程
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data_root = '/ssd/xiedong/datasets/multilabelsTask/' # 根目录
dataset_type = 'SelfDataset' # 数据集名称
data = dict(
samples_per_gpu=16, # 每个 GPU 上的样本数
workers_per_gpu=16, # 每个 GPU 上的 worker 数
train=dict(
type='ClassBalancedDataset',
oversample_thr=1 / 38, # 过采样阈值, 比如我38个类别,一个类别预计1000个样本,不足1000的则过采样
dataset=dict(
type=dataset_type,
data_prefix=data_root, # 数据集的根目录
ann_file=data_root + 'new_train_labels.txt', # 使用load_annotations方法,用于生成data_infos
pipeline=train_pipeline,
classes=data_root + 'new_classes.txt'), ),
val=dict(
type=dataset_type,
data_prefix=data_root,
ann_file=data_root + 'new_val_labels.txt',
pipeline=test_pipeline,
classes=data_root + 'new_classes.txt'),
test=dict(
type=dataset_type,
data_prefix=data_root,
ann_file=data_root + 'new_val_labels.txt',
pipeline=test_pipeline,
classes=data_root + 'new_classes.txt'),
)
evaluation = dict(
interval=1,
metric=['mAP', 'CP', 'OP', 'CR', 'OR', 'CF1', 'OF1'])
MultiLabelDataset类默认写了: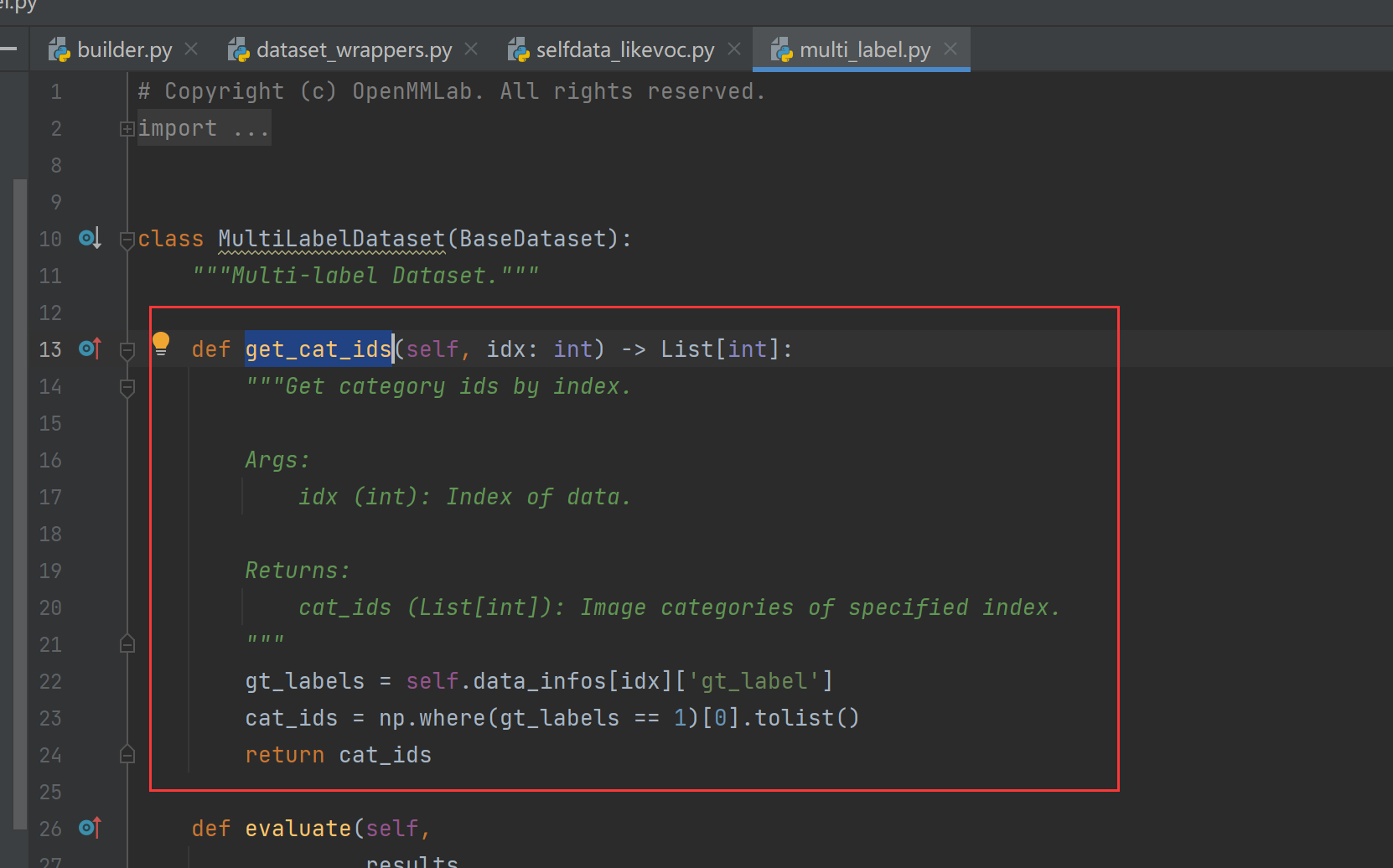
十、模型导出
边栏推荐
- The century-old Nordic luxury home appliance brand ASKO smart wine cabinet in the three-temperature area presents the Chinese Valentine’s Day, and tastes the love of the delicacy
- 攻防世界-PWN-new_easypwn
- 2022杭电多校 第6场 1008.Shinobu Loves Segment Tree 规律题
- Latex如何控制表格的宽度和高度
- SMB + SMB2: Accessing shares return an error after prolonged idle period
- 什么是 DevOps?看这一篇就够了!
- In-depth understanding of timeout settings for Istio traffic management
- 告白数字化转型时代:麦聪软件以最简单的方式让企业把数据用起来
- 【综合类型第 35 篇】程序员的七夕浪漫时刻
- poj2935 Basic Wall Maze (2016xynu暑期集训检测 -----D题)
猜你喜欢

今天告诉你界面控件DevExpress WinForms为何弃用经典视觉样式

The founder of the DFINITY Foundation talks about the ups and downs of the bear market, and where should DeFi projects go?
【温度预警程序de开发】事件驱动模型实例运用
Huawei's lightweight neural network architecture GhostNet has been upgraded again, and G-GhostNet (IJCV22) has shown its talents on the GPU
012年通过修补_sss_提高扩散模型效率
深入理解 Istio 流量管理的超时时间设置

一文道清什么是SPL

SD NAND Flash简介!
DFINITY 基金会创始人谈熊市沉浮,DeFi 项目该何去何从

Confessing in the era of digital transformation: Mai Cong Software allows enterprises to use data in the easiest way
随机推荐
MySQL事务
What are the standards for electrical engineering
DFINITY 基金会创始人谈熊市沉浮,DeFi 项目该何去何从
012_SSS_ Improving Diffusion Model Efficiency Through Patching
js劫持数组push方法
JS introduction to reverse the recycling business network of learning, simple encryption mobile phone number
拓朴排序例题
Huawei's lightweight neural network architecture GhostNet has been upgraded again, and G-GhostNet (IJCV22) has shown its talents on the GPU
第五章:多线程通信—wait和notify
[Strong Net Cup 2022] WP-UM
一张图看懂 SQL 的各种 join 用法!
Introduction to SD NAND Flash!
Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database
一个栈的输入序列为1 2 3 4 5 的出站顺序的理解
第四章:redis 数组结构的set和一些通用命令「建议收藏」
This notebook of concurrent programming knowledge points strongly recommended by Ali will be a breakthrough for you to get an offer from a big factory
这份阿里强推的并发编程知识点笔记,将是你拿大厂offer的突破口
用KUSTO查询语句(KQL)在Azure Data Explorer Database上查询LOG实战
【C语言指针】用指针提升数组的运算效率
MySQL data view