当前位置:网站首页>012年通过修补_sss_提高扩散模型效率
012年通过修补_sss_提高扩散模型效率
2022-08-05 10:24:00 【Artificial Idiots】
Improving Diffusion Model Efficiency Through Patching
This paper is mainly innovative in thinking. DiffusionRequires hundreds of sampling steps, 这是DiffusionImportant reasons for slow sampling. 因此, a lot of accelerationDiffusionThe method focuses on how to reduce the number of sampling steps. The author of this paper proposes another way of thinking, That is, by dividing the imagepatch降低DiffusionSampling efficiency and memory footprint for each step of the model.
1. Introduction
对于图像数据, A very efficient way to reduce computational cost is to process low-dimensional representations of image data, This low-dimensional representation can be obtained by downsampling or an encoder, But these two methods also need to upsample or decode the low-dimensional data., need more network. This article adopts a more convenient approach, Is divided into imagespatch然后直接concatenate起来.
The main contributions of the authors of this paper:
- 对DiffusionIn-depth analysis of training objectives, shows that in many sampling steps, High-resolution convolutional layers are redundant.
- 提出了一种Patched Diffusion Model(PDM), And it is proved that the cost of sampling can be significantly reduced. And this method can be used concurrently with the existing downsampling method.
- The author's analysis of different training objectivesDiffusioncompare the effects, found whether or notpatch, Models are more robust by predicting data than by predicting noise.
- 作者提出了一种将PDMfor more complex,Higher resolution method of the data, That is, dividing a network into multiple parts, 然后在256x256的ImageNethigh-quality results.
2. Patch Diffusion Model
DiffusionThe principle of the model will not be repeated, It's just that the markup used by the author here is the same asDDPM不太一样, Put a picture at a glance.
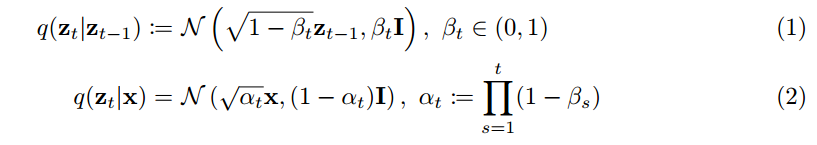
训练的目标, that is to rebuildx
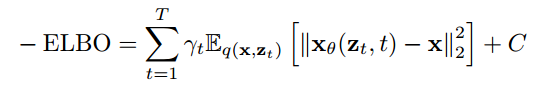
这里的 γ t \gamma_t γt 是常数. But if the target is added during training γ t \gamma_t γt On the contrary, the quality of the sampling will be degraded, 因为会 overemphasize high frequency information. So the author in this paper γ t = α t 1 − α t \gamma_t = \sqrt{\frac{\alpha_t}{1-\alpha_t}} γt=1−αtαt, to take into account low-frequency information.
Diffusion的训练过程, 也就是将 x 进行 perturb 得到 z t z_t zt, 然后训练网络 x θ x_{\theta} xθ 通过 z t z_t zt 重建出 x, The training goal of the figure above.
2.1 DiffusionRedundancy in model architecture
作者指出, for any hidden variable z t z_t zt, may be many different x x x by adding different noises. 但是这些 x x x can correspond to this z t z_t zt, 只是概率不同. 这种情况在 t 比较大, That is, when the noise is relatively loud, it is more obvious. 怎么理解呢?


As shown in the figure, three apples of different colors and shapes are exactly the same, Then, through the analysis of the implicit experimental results above:变量(That is, an image that approximates noise)预测得到的 x could be any of these three apples. 在这种情况下, What is the best result after model optimization??
作者指出, The optimal result obtained by optimizing the above training objective can be expressed as:
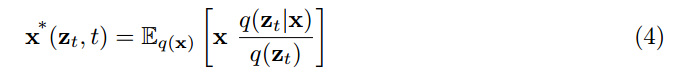
推导的过程如下:
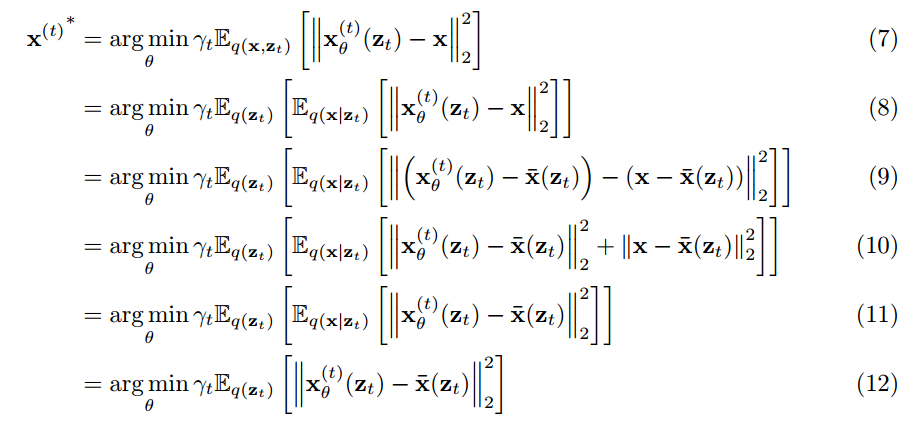
简而言之, That is to say, when the model converges to the optimum at each step, 预测得到的 x ∗ x^* x∗ 是输入的 z t z_t zt corresponding to all x x x 的期望, Or it can also be seen as the mean. Substitute into the apple example just now, The model predicts that the apple will be an average of the three colors. In fact, many usesL2Similar to the case where the loss is optimized, That is, what the model eventually learns is the mean of all possible cases., thereby losingdiversity. Not only is the coloring model tends to predict results as gray, 还体现在DiffusionThe model may predict that high-frequency information will be blurred, because the average.
But the author did not say how to solve the vague problem, but based on this vague fact, Point out that since the direct prediction when the noise is relatively large x 是模糊的, That is, high-frequency information cannot be obtained very well., Then there is no need for such a high computational cost, It's blurry anyway. So there is no need to do convolution at high resolution.

2.2 Patched Diffusion Models(PDM)
First of all, how does the authorPatch操作, 对于(H, W, C)的图像, the author according to P The size is divided into non-overlappingPatch, 然后concatenate起来, So convert the image to ( H / P , W / P , C × P 2 ) (H/P, W/P, C \times P^2) (H/P,W/P,C×P2) 的数据, 这个作为Unet的输入.
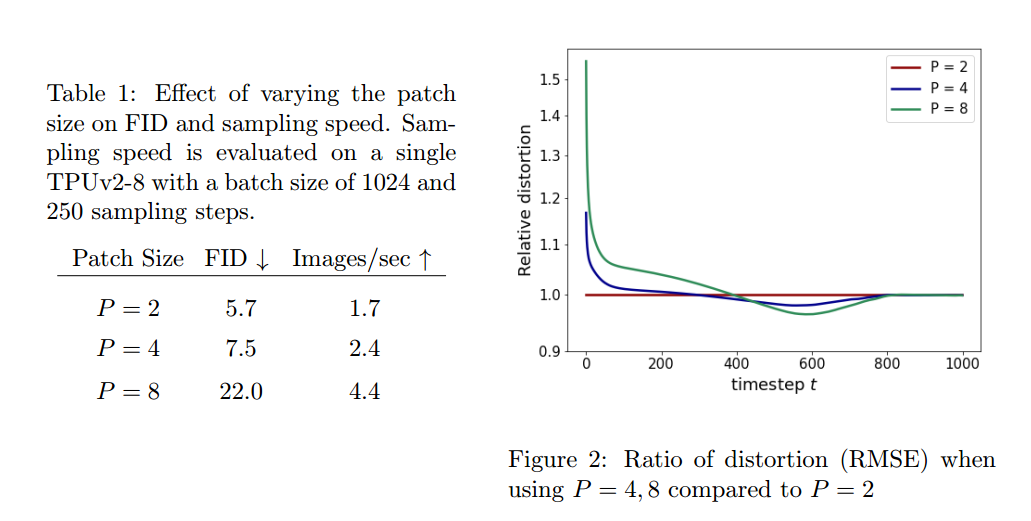
作者尝试了不同的patch大小2,4,8. 发现patch=4的时候, Both have better sampling quality, also increase the speed. And by comparing different authorpatch的RMSEIt is confirmed that when the noise is relatively large, Convolution at high resolution is useless.
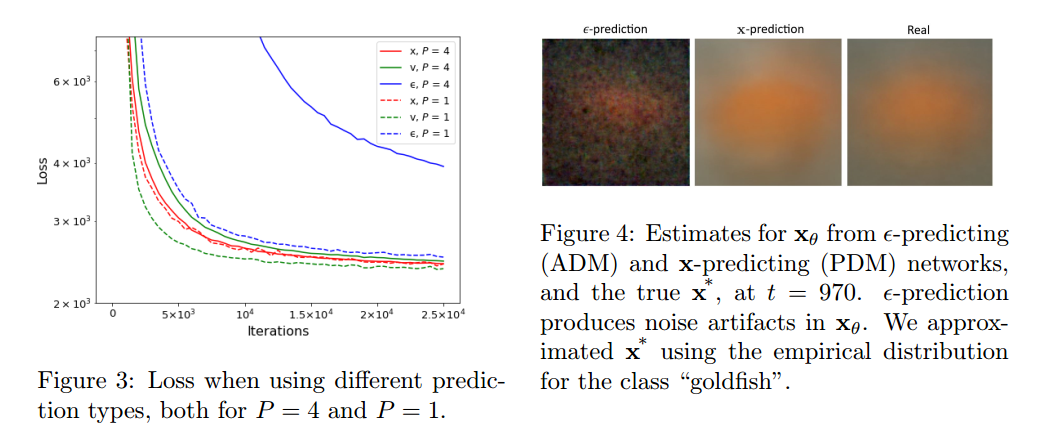
After that, the author tried different training objectives, 也就是重建 ϵ \epsilon ϵ, x x x, α t ϵ − 1 − α t x \sqrt{\alpha_t} \epsilon - \sqrt{1-\alpha_t} x αtϵ−1−αtxThe impact of three different goals on quality. The conclusion is to rebuild x x x, α t ϵ − 1 − α t x \sqrt{\alpha_t} \epsilon - \sqrt{1-\alpha_t} x αtϵ−1−αtx than rebuild ϵ \epsilon ϵ 更鲁棒.
2.3 Scaling to more complex datasets
这个部分很简单, 就是用了两个Unet, 一个不分patchUsed in the first half of the blurring stage, The other is used in the second half.
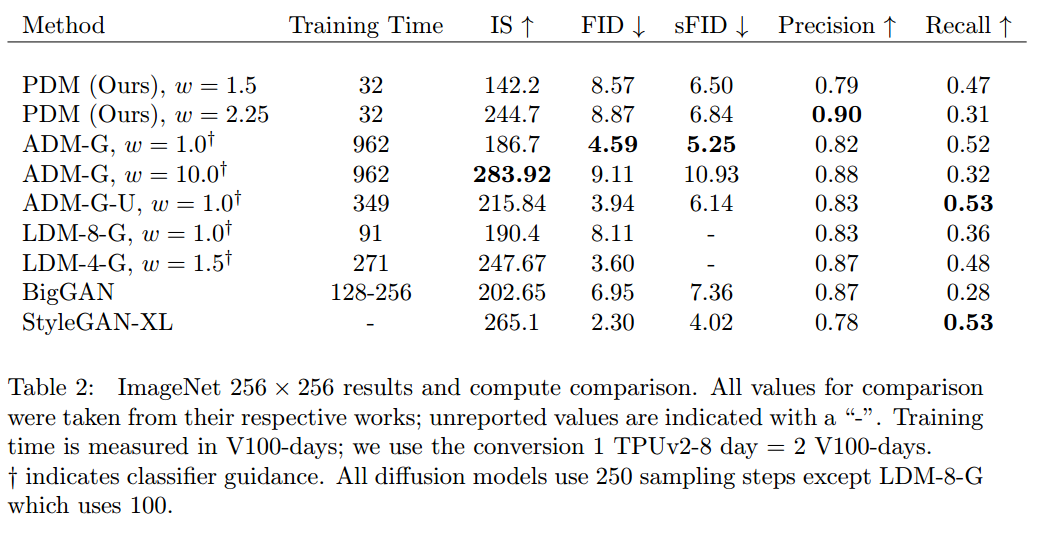
For more experimental results, please refer to the original text.
边栏推荐
- Voice-based social software development - making the most of its value
- 首次去中心化抢劫?近2亿美元损失:跨链桥Nomad 被攻击事件分析
- 第七章,activiti个人任务分配,动态指定和监听器指定任务委派人「建议收藏」
- 【综合类型第 35 篇】程序员的七夕浪漫时刻
- FPGA:基础入门LED灯闪烁
- STM32+ULN2003 drives 28BYJ4 stepper motor (forward and reverse according to the number of turns)
- Four years of weight loss record
- 教你本地编译运行一个IDEA插件,在IDEA里聊天、下棋、斗地主!
- 技术干货 | 基于 MindSpore 实现图像分割之豪斯多夫距离
- 19.3 restart the Oracle environment
猜你喜欢
Still looking for a network backup resources?Hurry up to collect the following network backup resource search artifact it is worth collecting!

STM32+ULN2003驱动28BYJ4步进电机(根据圈数正转、反转)
数据中台建设(十):数据安全管理
Huawei's lightweight neural network architecture GhostNet has been upgraded again, and G-GhostNet (IJCV22) has shown its talents on the GPU

three.js debugging tool dat.gui use
Jenkins manual (2) - software configuration
How to choose coins and determine the corresponding strategy research

DFINITY 基金会创始人谈熊市沉浮,DeFi 项目该何去何从

Pytorch Deep Learning Quick Start Tutorial -- Mound Tutorial Notes (3)
【 temperature warning program DE development 】 event driven model instance
随机推荐
【Office】Microsoft Office下载地址合集(微软官方原版离线安装下载)
第五章:多线程通信—wait和notify
【MindSpore易点通机器人-01】你也许见过很多知识问答机器人,但这个有点不一样
企业的数字化转型到底是否可以买来?
语音社交软件开发——充分发挥其价值
【MindSpore Easy-Diantong Robot-01】You may have seen many knowledge quiz robots, but this one is a bit different
【Unity】【UGUI】【在屏幕上显示文本】
Four years of weight loss record
three物体围绕一周呈球形排列
Brief Analysis of WSGI Protocol
创建一个 Dapp,为什么要选择波卡?
Chapter 4: In the activiti process, variable transmission and acquisition process variables, setting and acquiring multiple process variables, setting and acquiring local process variables "recommende
Ali's new launch: Microservices Assault Manual, all operations are written out in PDF
How does the official account operate and maintain?Public account operation and maintenance professional team
RT-Thread记录(一、RT-Thread 版本、RT-Thread Studio开发环境 及 配合CubeMX开发快速上手)
SMB + SMB2: Accessing shares return an error after prolonged idle period
使用工具类把对象中的null值转换为空字符串(集合也可以使用)
Score interview (1)----related to business
2022 Huashu Cup Mathematical Modeling Ideas Analysis and Exchange
用KUSTO查询语句(KQL)在Azure Data Explorer Database上查询LOG实战