当前位置:网站首页>Flink的DataSource三部曲之二:内置connector
Flink的DataSource三部曲之二:内置connector
2020-11-06 20:12:00 【程序员欣宸】

欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
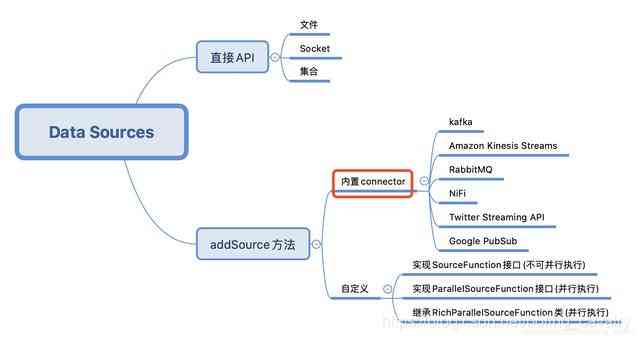
本文是《Flink的DataSource三部曲》系列的第二篇,上一篇《Flink的DataSource三部曲之一:直接API》学习了StreamExecutionEnvironment的API创建DataSource,今天要练习的是Flink内置的connector,即下图的红框位置,这些connector可以通过StreamExecutionEnvironment的addSource方法使用:
 今天的实战选择Kafka作为数据源来操作,先尝试接收和处理String型的消息,再接收JSON类型的消息,将JSON反序列化成bean实例;
今天的实战选择Kafka作为数据源来操作,先尝试接收和处理String型的消息,再接收JSON类型的消息,将JSON反序列化成bean实例;
Flink的DataSource三部曲文章链接
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | [email protected]:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinkdatasourcedemo文件夹下,如下图红框所示: 
环境和版本
本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
- Kafka:2.4.0
- Zookeeper:3.5.5
请确保上述内容都已经准备就绪,才能继续后面的实战;
Flink与Kafka版本匹配
- Flink官方对匹配Kafka版本做了详细说明,地址是:https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
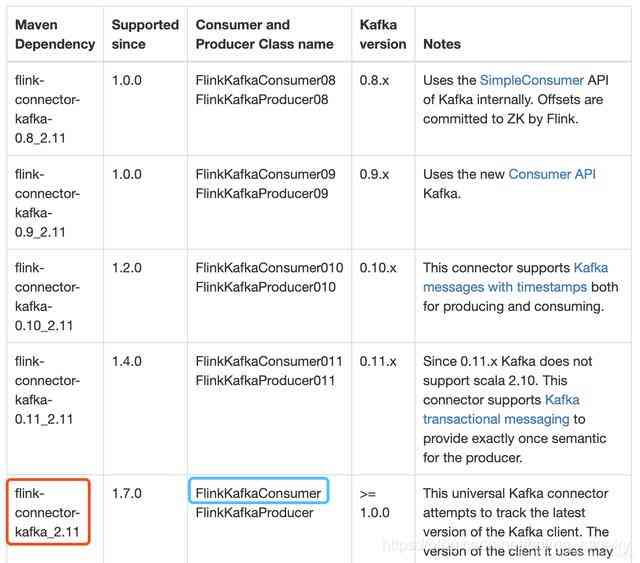
- 要重点关注的是官方提到的通用版(universal Kafka connector ),这是从Flink1.7开始推出的,对于Kafka1.0.0或者更高版本都可以使用:
 3. 下图红框中是我的工程中要依赖的库,蓝框中是连接Kafka用到的类,读者您可以根据自己的Kafka版本在表格中找到适合的库和类:
3. 下图红框中是我的工程中要依赖的库,蓝框中是连接Kafka用到的类,读者您可以根据自己的Kafka版本在表格中找到适合的库和类:
实战字符串消息处理
- 在kafka上创建名为test001的topic,参考命令:
./kafka-topics.sh \
--create \
--zookeeper 192.168.50.43:2181 \
--replication-factor 1 \
--partitions 2 \
--topic test001
- 继续使用上一章创建的flinkdatasourcedemo工程,打开pom.xml文件增加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
- 新增类Kafka240String.java,作用是连接broker,对收到的字符串消息做WordCount操作:
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import static com.sun.tools.doclint.Entity.para;
public class Kafka240String {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(2);
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new SimpleStringSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<String> dataStream = env.addSource(flinkKafkaConsumer);
//从kafka取得字符串消息后,分割成单词,统计数量,窗口是5秒
dataStream
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka");
}
}
- 确保kafka的topic已经创建,将Kafka240运行起来,可见消费消息并进行单词统计的功能是正常的:
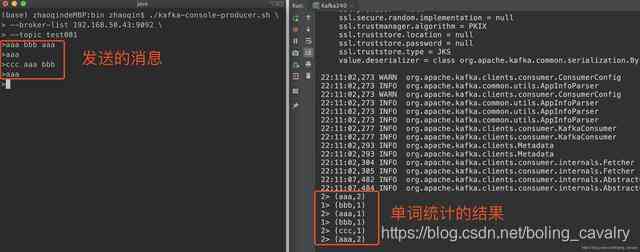 5. 接收kafka字符串消息的实战已经完成,接下来试试JSON格式的消息;
5. 接收kafka字符串消息的实战已经完成,接下来试试JSON格式的消息;
实战JSON消息处理
- 接下来要接受的JSON格式消息,可以被反序列化成bean实例,会用到JSON库,我选择的是gson;
- 在pom.xml增加gson依赖:
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
- 增加类Student.java,这是个普通的Bean,只有id和name两个字段:
package com.bolingcavalry;
public class Student {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
- 增加类StudentSchema.java,该类是DeserializationSchema接口的实现,将JSON反序列化成Student实例时用到:
ackage com.bolingcavalry.connector;
import com.bolingcavalry.Student;
import com.google.gson.Gson;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
public class StudentSchema implements DeserializationSchema<Student>, SerializationSchema<Student> {
private static final Gson gson = new Gson();
/**
* 反序列化,将byte数组转成Student实例
* @param bytes
* @return
* @throws IOException
*/
@Override
public Student deserialize(byte[] bytes) throws IOException {
return gson.fromJson(new String(bytes), Student.class);
}
@Override
public boolean isEndOfStream(Student student) {
return false;
}
/**
* 序列化,将Student实例转成byte数组
* @param student
* @return
*/
@Override
public byte[] serialize(Student student) {
return new byte[0];
}
@Override
public TypeInformation<Student> getProducedType() {
return TypeInformation.of(Student.class);
}
}
- 新增类Kafka240Bean.java,作用是连接broker,对收到的JSON消息转成Student实例,统计每个名字出现的数量,窗口依旧是5秒:
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import com.bolingcavalry.Student;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Kafka240Bean {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(2);
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<Student> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new StudentSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<Student> dataStream = env.addSource(flinkKafkaConsumer);
//从kafka取得的JSON被反序列化成Student实例,统计每个name的数量,窗口是5秒
dataStream.map(new MapFunction<Student, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(Student student) throws Exception {
return new Tuple2<>(student.getName(), 1);
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka bean");
}
}
- 在测试的时候,要向kafka发送JSON格式字符串,flink这边就会给统计出每个name的数量:
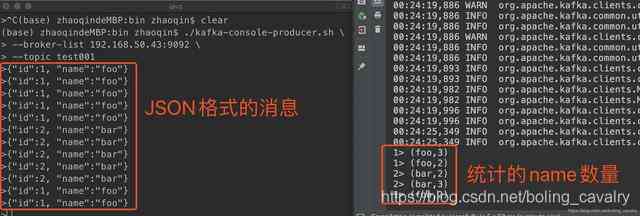 至此,内置connector的实战就完成了,接下来的章节,我们将要一起实战自定义DataSource;
至此,内置connector的实战就完成了,接下来的章节,我们将要一起实战自定义DataSource;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界... https://github.com/zq2599/blog_demos
版权声明
本文为[程序员欣宸]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4198380/blog/4705334
边栏推荐
- 分布式ID生成服务,真的有必要搞一个
- 【C/C++ 1】Clion配置与运行C语言
- Top 10 best big data analysis tools in 2020
- 《Google軟體測試之道》 第一章google軟體測試介紹
- Menu permission control configuration of hub plug-in for azure Devops extension
- nlp模型-bert从入门到精通(一)
- Serilog原始碼解析——使用方法
- Polkadot series (2) -- detailed explanation of mixed consensus
- [C#] (原創)一步一步教你自定義控制元件——04,ProgressBar(進度條)
- 数据科学家与机器学习工程师的区别? - kdnuggets
猜你喜欢


随机推荐
解決pl/sql developer中資料庫插入資料亂碼問題
【C/C++ 2】Clion配置与运行C语言
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
哇,ElasticSearch多字段权重排序居然可以这么玩
恕我直言,我也是才知道ElasticSearch条件更新是这么玩的
7.3.1 file upload and zero XML registration interceptor
被老程式設計師壓榨怎麼辦?我不想辭職
python过滤敏感词记录
车的换道检测
条码生成软件如何隐藏部分条码文字
Listening to silent words: hand in hand teaching you sign language recognition with modelarts
Serilog原始碼解析——使用方法
Real time data synchronization scheme based on Flink SQL CDC
【快速因數分解】Pollard's Rho 演算法
使用NLP和ML来提取和构造Web数据
windows10 tensorflow(二)原理实战之回归分析,深度学习框架(梯度下降法求解回归参数)
小白量化投资交易入门课(python入门金融分析)
如何使用ES6中的参数
安装Anaconda3 后,怎样使用 Python 2.7?
向北京集结!OpenI/O 2020启智开发者大会进入倒计时