当前位置:网站首页>mysql 的一些重要知识
mysql 的一些重要知识
2022-07-07 17:52:00 【whiteye太白】
引擎区别
- InnoDB:默认存储引擎,支持行锁表锁、事务、外键、崩溃恢复,支持mvcc多版本控制 读写并发。更新效率高。底层是B+树。
- MyISAM:只支持表级锁,采用非聚集索引。表结构、数据、索引三表分离。查询效率高。
- Mrg_Myisam:MyIsam的表聚合,它内部没有数据,真正的数据依然是Mylsam引擎表中。
- Memory:内存中建表,只支持存储数据长度不变的数据,进程崩溃时数据丢失。
B+树、红黑树
- InnoDB-底层B+树:B+树是多路平衡树,树高更小,查询速度快,查询效率稳定,用于存储索引等较为固定的数据。
- Hashmap-底层数组+链表 / 数组+红黑树:红黑树为不完全平衡二叉树,利用颜色插入删除结点后能快速实现平衡,用于存储插入删除操作较多的数据。
什么是聚簇索引(主键索引)和非聚簇索引(二级索引)?
- 聚簇索引就是索引和数据存储在一起的。例如:InnoDB的存储引擎中必须包含主键,如果我们没有指定主键,会生成默认的主键,主键和数据都存储在B+树中,这种索引称为聚簇索引。我们如果使用主键作为查询条件,会直接在B+树中找到具体的数据。
- 非聚簇索引就是索引和数据是分开存储的。例如:InnoDB的非主键索引都是单独存储在一个B+树中,但叶子节点存储的是具体主键索引的主键值,所以对于非聚簇索引,还需要主键值到聚簇索引中查询到一条完整记录,因此按非聚簇索引检索实际上进行了二次查询,效率肯定是没有按照聚簇索引检索高的。
聚簇索引、主键索引:
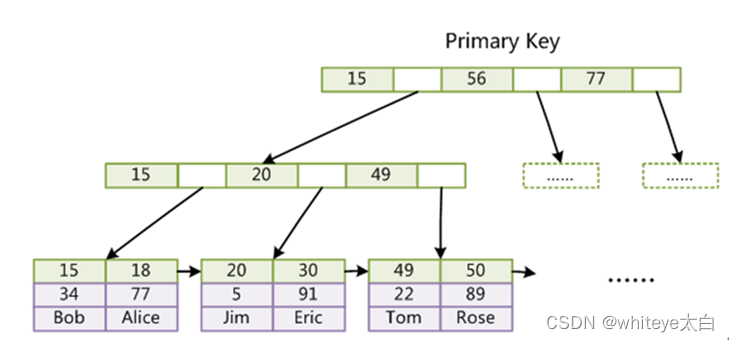
聚簇索引、辅助索引、二级索引:

join内连接
- left join …on… 向左连接,右表加入左表,多的删除,缺的填NULL
- inner join …on… 内连接,交集
索引结构
B+树:非叶子节点存放索引,叶子节点存放数据,叶子节点之间形成双向链表。
索引使用场景
- 经常查询的列。where id=?
- 经常排序,分组的列。因为索引已经排好序了
- 唯一性高的列。比如说主键、用户名
覆盖索引
索引字段覆盖了查询语句涉及的字段,直接通过索引文件就可以返回查询所需的数据,不必通过回表操作。
回表
通过非主键索引找到主键id,再根据主键id去主键索引的叶子节点链表查询。
索引下推
在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
索引失效(索引失效时进行全表扫描,行锁升级为表锁)
- select *
、<、!=、between
- 前置 % 的like查询
- or连接不同字段
- where字段值与数据库字段存在类型转换
- 函数或运算导致索引失效
- IS NULL不走索引,IS NOT NULL走索引(表设计:非必要时,字段不要为NULL,设置默认空字符串或0)
- IN会走索引,但是当IN的取值范围较大时会导致索引失效
ep_range_index_dive_limit这个参数影响in是否使用索引,MySQL 5.6默认10,
MySQL 5.7默认200。但是我们代码更倾向于控制在50内。
A表数据大于B表数据时,选择in比exists执行效率要高。
相反,A表数据小于B表数据时,选择exists比较高效。
in先执行子查询,exists先执行外表。 - not in 会使索引失效,无论在哪种情况not exists 都比 not in 高效。
使用 left join 或 not exists 来优化 not in 操作 - 表数据少会索引失效
慢查询
超过 long_query_time 阈值(默认10s),就被认为是慢查询。手动开启慢查询日志,慢查询会被记录在慢查询日志里。
可设置项:阈值,未使用索引的sql,日志存放的地方。
日志内容:
第一行:记录的时间
第二行:用户名 、用户的IP信息、线程ID号
第三行:执行的时间、获得锁的时间、获得的结果行数、扫描的数据行数
第四行:SQL执行的时间戳 第五行:具体的SQL语句
事务隔离级别
- 读未提交
- 读已提交
- 可重复读
- 串行化
MySQL隔离级别基于锁和 MVCC 机制共同实现。 InnoDB默认隔离级别是可重复读。
不可重复读和幻读区别 :
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次查询同一条查询语句(DQL)时,记录发现记录增多或减少了。
- 共享锁:又称读锁。
- 排他锁:又称写锁。
- 意向锁:在为数据行加共享 / 排他锁之前,InooDB会先获取该数据行所在在数据表的对应意向锁。来快速判断是否可以对某个表使用表锁。
InnoDB 三种行锁定方式
- 记录锁:单行锁。
- 间隙锁:范围锁,锁范围类防止插入、删除。
- 临键锁:锁住的是索引本身以及索引之前的间隙,是左开右闭的区间,防止插入。
InnoDB行锁实现 --(mysql行锁如何转变为表锁)
InnoDB行锁是通过给索引上的索引项加锁实现的,因此只有走索引查询数据,(索引未失效)innoDB才会使用行锁,否则InnoDB将使用表锁。
由于MySQL的⾏锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同⾏的记录,但是如果是使⽤相同的索引键,是会出现锁冲突的。
undo log 崩溃恢复主要有两个作用:
- 当事务回滚时用于将数据恢复到修改前的样子。
- 另一个作用是 MVCC ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 undo log 读取之前的版本数据,以此实现非锁定读。
MVCC
- 多版本并发控制,通过记录的版本号,实现读写并发。
- InnoDB在每一行数据中额外保存两个隐藏的列,保存创建和过期的系统版本号。
- 每开始新的事务,系统版本号会自动递增,事务开始时的系统版本号作为事务的版本号。
- InnoDB事务只查询版本号小于等于它的数据行,保证数据行在事务开始前就以存在,或者事务自身插入或修改的。
边栏推荐
- 一张图深入的理解FP/FN/Precision/Recall
- 【Confluence】JVM内存调整
- 小试牛刀之NunJucks模板引擎
- el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
- ASP.NET幼儿园连锁管理系统源码
- 最多可以参加的会议数目[贪心 + 优先队列]
- Research and practice of super-resolution technology in the field of real-time audio and video
- 2022.07.05
- 开源重器!九章云极DataCanvas公司YLearn因果学习开源项目即将发布!
- The research group of the Hunan Organizing Committee of the 24th China Association for science and technology visited Kirin Xin'an
猜你喜欢
华南X99平台打鸡血教程
一张图深入的理解FP/FN/Precision/Recall

Kirin Xin'an joins Ningxia commercial cipher Association
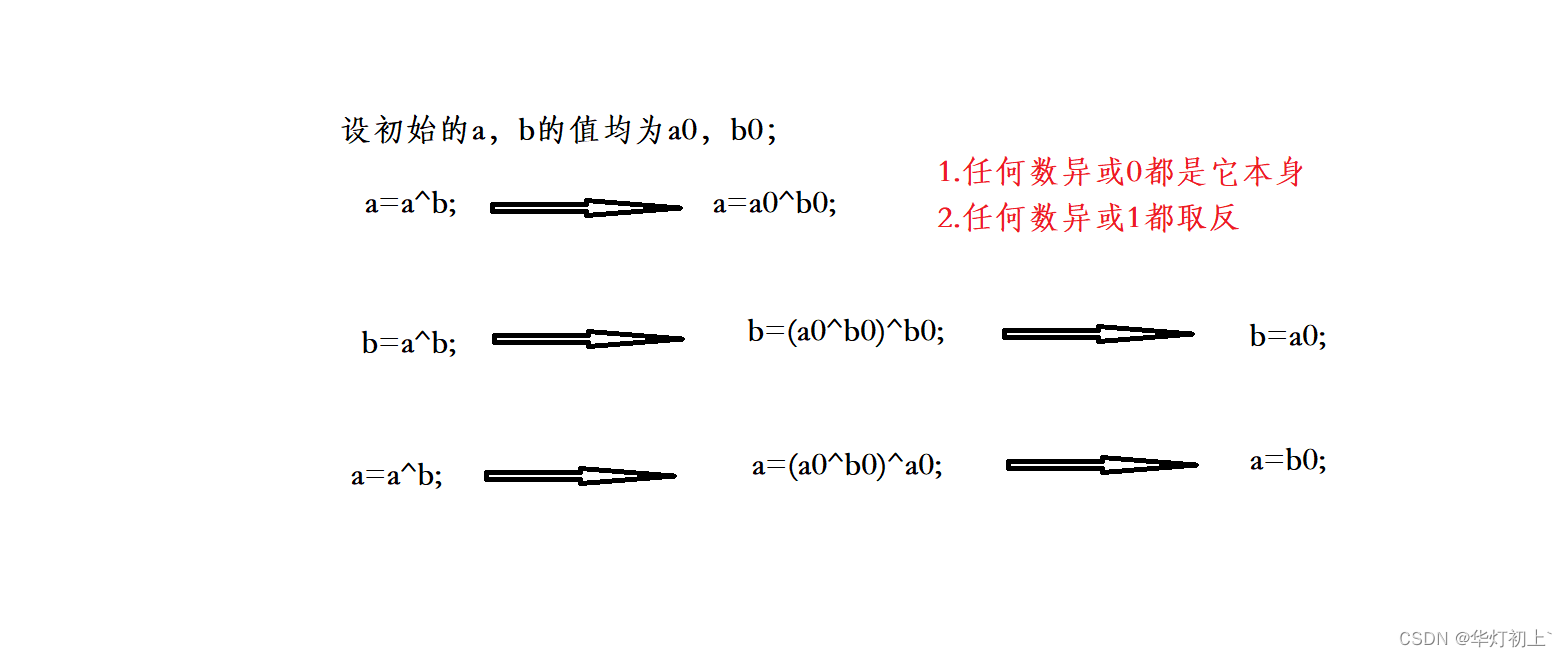
Introduction to bit operation

Compiler optimization (4): inductive variables
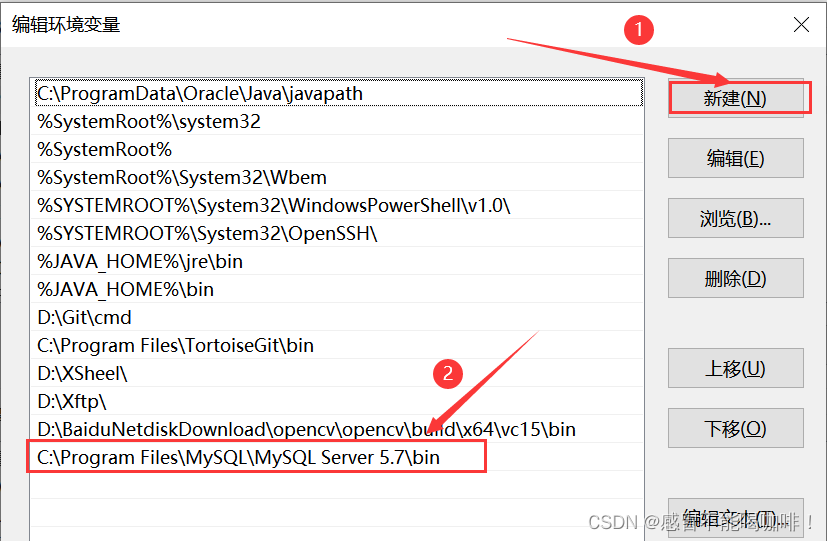
CMD command enters MySQL times service name or command error (fool teaching)

论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
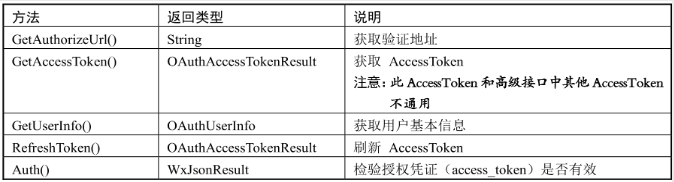
微信公众号OAuth2.0授权登录并显示用户信息
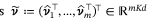
Automatic classification of defective photovoltaic module cells in electroluminescence images-论文阅读笔记

2022.07.04
随机推荐
The research group of the Hunan Organizing Committee of the 24th China Association for science and technology visited Kirin Xin'an
转置卷积理论解释(输入输出大小分析)
LeetCode 648(C#)
Tp6 realize Commission ranking
2022年投资哪个理财产品收益高?
ant desgin 多选
L1-027 rental (Lua)
R语言dplyr包mutate_at函数和min_rank函数计算dataframe中指定数据列的排序序号值、名次值、将最大值的rank值赋值为1
吞吐量Throughout
The strength index of specialized and new software development enterprises was released, and Kirin Xin'an was honored on the list
[sword finger offer] sword finger offer II 012 The sum of left and right subarrays is equal
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
R language uses ggplot2 function to visualize the histogram distribution of counting target variables that need to build Poisson regression model, and analyzes the feasibility of building Poisson regr
Make insurance more "safe"! Kirin Xin'an one cloud multi-core cloud desktop won the bid of China Life Insurance, helping the innovation and development of financial and insurance information technolog
Kunpeng developer summit 2022 | Kirin Xin'an and Kunpeng jointly build a new ecosystem of computing industry
what‘s the meaning of inference
指定opencv非标准安装的版本
Jerry's headphones with the same channel are not allowed to pair [article]
LeetCode_ 7_ five
My creation anniversary