当前位置:网站首页>Experiment 1 of Compilation Principle: automatic implementation of lexical analyzer (Lex lexical analysis)
Experiment 1 of Compilation Principle: automatic implementation of lexical analyzer (Lex lexical analysis)
2022-07-07 19:18:00 【Zombotany Zhiyong】
One 、 Experimental content
1. With the help of lexical analysis tools Flex or Lex complete ( Reference network resources )
2. Input : High level language source code ( Such as helloworld.c)
3. Output : A sequence of word symbols represented by two tuples .
Two 、 The experiment purpose
Through the design 、 Organization 、 Debug a specific lexical analysis program , Deepen the understanding of the principle of lexical analysis , And master the lexical analysis method of decomposing the programming language source program into various words in the process of scanning it .
3、 ... and 、 experimental analysis
Because the overall structure of words in different high-level programming languages is roughly the same , Basically, it can be described by a set of regular expressions , So construct such an automatic generation system : Just give a set of regular expressions of the lexical structures of various words in a high-level language and the semantic actions that the lexical analysis program should take when recognizing various words , The system can automatically generate the lexical analysis program of this high-level programming language .Lex It is an automatic generation tool of lexical analysis program . One Lex Source program process Lex The compiler system can generate lexical analysis programs L.
One Lex The source program has the following form :
Declaration part
%%
Conversion rules
%%
Auxiliary function
In the declaration section , Defining variables and constants . You can also declare regular expressions .
and Lex Each transformation rule of has the following form : Pattern { action }
among , Patterns are regular expressions , You can use the regular definition given in the declaration section . Actions are code snippets , utilize c Language writing .
Lex The source program is stored in .l In file , utilize win_flex You can generate output lex.yy.c file .lex.yy.c Documents can be c The language compiler compiles and runs .
In order to identify a real c Language source , The following auxiliary definitions are required :letter->a-zA-Zdigit->0-9
These two auxiliary definitions are used to recognize single alphabetic characters and single numeric characters .
In this experiment , What needs to be identified is c The reserved words of the language program are as follows :while、if、else、switch、case、int、main、using、namespace、std、printf. A regular expression can be used to identify :(while)|(if)|(else)|(switch)|(case)|(int)|(main)|(using)|(namespace)|(std)|(printf)
c Language identifier id The following rules : By letter 、 Numbers 、 Underline composition , And the first character can only be letters or underscores . Then the regular expression of the identifier is :({letter}|_)({letter}|{digit}|_)*
The regular expression of an integer is as follows :(‘+’|’-’)?{digit}*
among , Question mark ’+’ Number or ’-’ No. or it doesn't appear , Or there is only once . This regular expression can accept positive and negative numbers .
The regular expression of floating point numbers is as follows :{digit}+.{digit}+((E|e)(‘+’|’-’)?{digit}+)?
There is at least one digit before the decimal point , There is at least one digit after the decimal point . You can attach this number after the number, which needs to be multiplied 10 How many powers of , It can also be without .
c The operators in language are addition, subtraction, multiplication and division 、 Compare 、 Outside assignment , And stream input and output . The regular expression is as follows :\+|-|\*|<=|<|==|=|>=|>|>>|<<. Because regular expressions have plus and multiplier signs , So add a backslash before the plus sign and the multiply sign to escape .
Recognize spaces 、tab、 A newline 、 A carriage return (\r) The regular expression of is : \t\n\r, Write it down as delim. To identify multiple blanks , You can use regular expressions {delim}+
The regular expression that identifies the string is :”[^”]*”, That is, there can be any character other than the double quotation mark character in two double quotation marks . For the sake of escape , stay c Writing is required in language programs :\"[^"]*\"
distinguish c When the header file included at the beginning of the language program , Need to identify first # Number , Then recognize any characters except line breaks . The regular expression statement is as follows :"#".*
stay lex In the program , After reading the source code file that needs lexical analysis , call yylex() You can automatically start lexical analysis , The attribute value of lexical unit obtained by lexical analysis is temporarily stored in the global variable yylval in , The recognized word string is stored in the variable yytext in .
At run time , Each input file is matched to a regular expression , It automatically performs its action . In this experiment , The action to be performed is to represent the current word in the form of a binary . That is to say :( Word type , The value of the word itself ). This process is repeated , And will make mistakes when recognizing illegal characters . Until the end of the file is read , The process ends .
Four 、 Experimental process
After the download is complete win_flex After the compressed package of , Unzip the folder and you can see win_flex.exe The file of . this exe Files cannot be run directly . You need to configure environment variables first , Add the path of this file to the system variable Path Inside . stay cmd window , Yes Lex Of the source program .l File execution win_flex --nounistd lex.l, Can generate lex.yy.c. Add parameter –nounistd The purpose of is to generate windows Compiled and run in the environment lex.yy.c Not only in linux/unix In the environment lex.yy.c.
At the end of writing .l After the document , perform win_flex, Generate lex.yy.c. stay visual studio Wait for the compiler to compile and run this file , Another one to be analyzed c The language source program performs lexical analysis and outputs it to the control tower .
therefore , The overall operation process of the experiment is as follows 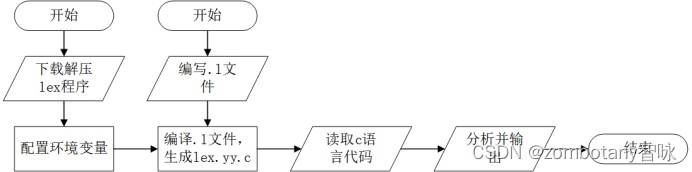
5、 ... and 、 Experimental code
5.1 Code instructions
stay %{ And %} Between them is the insertion c Language program ,include Related libraries and define global variables to record the current number of words being analyzed for the counter .
%{
#include <stdio.h>
#include <stdlib.h>
int count = 0;
%}
The declarative part of the regular expression , The regular expressions corresponding to each word type analyzed in Chapter 3 are consistent .
digit [0-9]
letter [a-zA-Z]
reservedWord [w][h][i][l][e]|[i][f]|[e][l][s][e]|[s][w][i][t][c][h]|[c][a][s][e]|[i][n][t]|[m][a][i][n]|[u][s][i][n][g]|[n][a][m][e][s][p][a][c][e]|[s][t][d]|[p][r][i][n][t][f]
id ({
letter}|_)({
letter}|{
digit}|_)*
num {
digit}+
operator \+|-|\*|<=|<|==|=|>=|>|>>|<<
delim [ \t\n\r]
whitespace {
delim}+
semicolon [\;]
str \"[^"]*\"
other .
%%
Auxiliary function part , Perform the corresponding action for each regular expression : Add one counter , Analyze the word type of the current word and the value of the word itself .
%%
{
reservedWord} {
count++;printf("%d\t(reserved word,\'%s\')\n",count,yytext);}
{
id} {
count++;printf("%d\t(id,\'%s\')\n",count,yytext);}
{
num} {
count++;printf("%d\t(num,\'%s\')\n",count,yytext);}
{
operator} {
count++;printf("%d\t(op,\'%s\')\n",count,yytext);}
{
whitespace} {
/* do nothing*/ }
{
str} {
count++;printf("%d\t(string,\'%s\')\n",count,yytext);}
"(" {
count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}
")" {
count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}
"{" {
count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}
"}" {
count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}
":" {
count++;printf("%d\t(colon,\'%s\')\n",count,yytext);}
";" {
count++;printf("%d\t(semicolon,\'%s\')\n",count,yytext);}
"#".* {
count++;printf("%d\t(head,\'%s\')\n",count,yytext);}
{
other} {
printf("illegal character:\'%s\'\n",yytext);}
%%
main The function reads a file to yyin, And call yylex() Automatically to yyin For lexical analysis .
int main(){
yyin=fopen("F:/HOMEWORK/Compiler/Lab2/test.c","r");
yylex();
return 0;
}
int yywrap()
{
return 1;
}
5.2 Complete code
%{
#include <stdio.h>
#include <stdlib.h>
int count = 0;
%}
digit [0-9]
letter [a-zA-Z]
reservedWord [w][h][i][l][e]|[i][f]|[e][l][s][e]|[s][w][i][t][c][h]|[c][a][s][e]|[i][n][t]|[m][a][i][n]|[u][s][i][n][g]|[n][a][m][e][s][p][a][c][e]|[s][t][d]|[p][r][i][n][t][f]
id ({
letter}|_)({
letter}|{
digit}|_)*
num {
digit}+
operator \+|-|\*|<=|<|==|=|>=|>|>>|<<
delim [ \t\n\r]
whitespace {
delim}+
semicolon [\;]
str \"[^"]*\"
other .
%%
{
reservedWord} {
count++;printf("%d\t(reserved word,\'%s\')\n",count,yytext);}
{
id} {
count++;printf("%d\t(id,\'%s\')\n",count,yytext);}
{
num} {
count++;printf("%d\t(num,\'%s\')\n",count,yytext);}
{
operator} {
count++;printf("%d\t(op,\'%s\')\n",count,yytext);}
{
whitespace} {
/* do nothing*/ }
{
str} {
count++;printf("%d\t(string,\'%s\')\n",count,yytext);}
"(" {
count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}
")" {
count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}
"{" {
count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}
"}" {
count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}
":" {
count++;printf("%d\t(colon,\'%s\')\n",count,yytext);}
";" {
count++;printf("%d\t(semicolon,\'%s\')\n",count,yytext);}
"#".* {
count++;printf("%d\t(head,\'%s\')\n",count,yytext);}
{
other} {
printf("illegal character:\'%s\'\n",yytext);}
%%
int main(){
yyin=fopen("F:/HOMEWORK/Compiler/Lab2/test.c","r");
yylex();
return 0;
}
int yywrap(){
return 1;
}
6、 ... and 、 Running results

Compile operation .l file , Add parameters nounistd, Generated a can be in Windows 10 Can run in the environment lex.yy.c, Pictured 3 Shown .

Pictured 4, Write a real for testing lexical analyzer c The language code .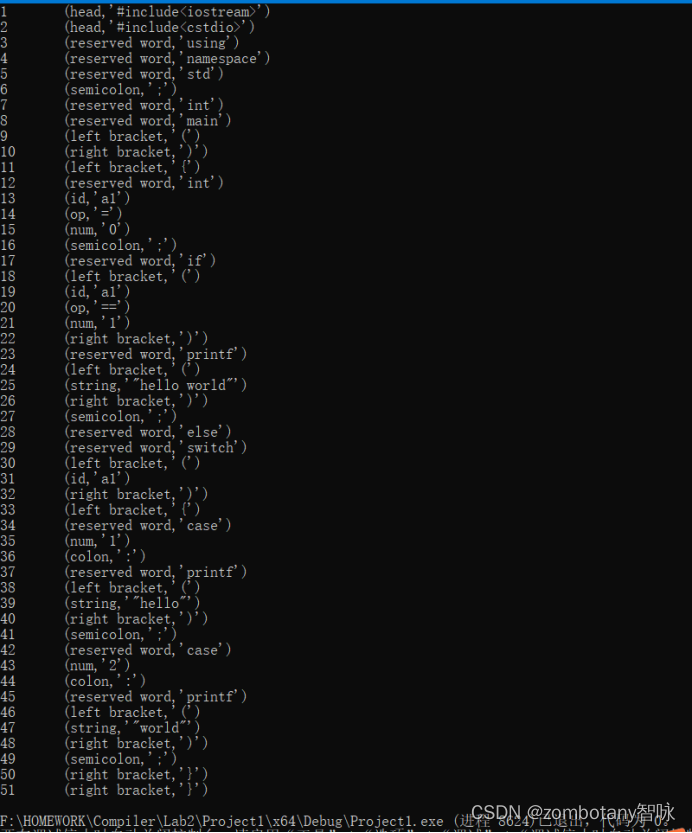
Yes lex.yy.c Compile and run the code , And output the results on the console , Pictured 5. The lexical analyzer can automatically ignore spaces 、 A newline 、tab, Number each word one by one in order , And generate two tuples ( Word type , The value of the word itself ).
chart 5 Lexical analysis results and graphs 4 The test files of are corresponding one by one .
The header file is first identified . Recognition statement using namespace std, And identify the semicolon of the statement .
distinguish int main, And identify the right and left parentheses and braces that follow .
Source code “int a1=0;” Identified as follows : Reserved words int, identifier a1, Assignment number =, Numbers 0. And identify the semicolon .
Source code “if(a1==1);” Identified as follows : Reserved words if、 Left parenthesis 、 identifier a1、 Compare equal symbols ==、 Numbers 1、 Right bracket 、 A semicolon .
Source code “printf(“hello world”)” Was identified as : Reserved words printf、 Left parenthesis 、 character string ”hello world”、 Right bracket . It should be noted that ,”hello world” A string is a word , It is not recognized as two words because there is a space in the middle .
else、switch And other words are reserved . Identification identifier a1、 The process of brackets is the same .
Source code “case 1:printf(“hello”);” Was identified as : Reserved words case、 Numbers 1、 Reserved words printf、 Left parenthesis 、 character string ”hello”、 Right bracket 、 A semicolon . Source code “case 2:printf(“world”);” Empathy .
Finally, identify the two right braces . After reading the end of the file , Program end .
7、 ... and 、 Experimental experience
边栏推荐
猜你喜欢
Mathematical analysis_ Notes_ Chapter 11: Fourier series
Complete e-commerce system
Comparison and selection of kubernetes Devops CD Tools

Desci: is decentralized science the new trend of Web3.0?

5billion, another master fund was born in Fujian
![[Tawang methodology] Tawang 3W consumption strategy - U & a research method](/img/63/a8c08ac6ec7d654159e5fc8b4423e4.png)
[Tawang methodology] Tawang 3W consumption strategy - U & a research method

杰理之手动配对方式【篇】
![Learn open62541 -- [67] add custom enum and display name](/img/98/e5e25af90b3f98c2be11d7d21e5ea6.png)
Learn open62541 -- [67] add custom enum and display name
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布

Three forms of multimedia technology commonly used in enterprise exhibition hall design
随机推荐
微服务远程Debug,Nocalhost + Rainbond微服务开发第二弹
PTA 1102 教超冠军卷
Creative changes brought about by the yuan universe
面试唯品会实习测试岗、抖音实习测试岗【真实投稿】
RISCV64
Reuse of data validation framework Apache bval
In 2021, the national average salary was released. Have you reached the standard?
2022.07.02
Command mode - unity
Three forms of multimedia technology commonly used in enterprise exhibition hall design
Longest common prefix (leetcode question 14)
5billion, another master fund was born in Fujian
10 schemes to ensure interface data security
Numpy——2.数组的形状
Draw squares with Obama (Lua)
AI来搞财富分配比人更公平?来自DeepMind的多人博弈游戏研究
杰理之快速配对,不支持取消配对【篇】
Cadre de validation des données Apache bval réutilisé
State mode - Unity (finite state machine)
Tips and tricks of image segmentation summarized from 39 Kabul competitions