当前位置:网站首页>Neural network and deep learning-5-perceptron-pytorch
Neural network and deep learning-5-perceptron-pytorch
2022-07-08 01:54:00 【Bai Xiaosheng in Ming Dynasty】
Reference documents :
《 Neural networks and deep learning 》
Preface :
Perceptron is 1957 Year by year Frank RoseBlatt Proposed , It is a widely used linear classifier .
This is an error driven algorithm
One perceptron

1.1 Parameter learning

The algorithm tries to find a set of parameters w, So that for each sample  Yes
Yes

1.1 Loss function

Using random gradient descent

1.2 Algorithm flow

1.3 The convergence of the algorithm
1963 year Novioff The convergence of the algorithm on linearly separable data sets is proved
shortcoming :
Poor generalization ability ,
The order of each iteration is different, and the hyperplane is also different .
If linear is inseparable , Will never converge
Two Voting perceptron
The weight vector of perceptron learning is related to the order of training samples .
In order to improve the robustness and generalization ability of the perceptron , We can talk about everything in the process of perceptron learning K Save four weight vectors ( Wrong ), And give each weight vector a  A confidence coefficient
A confidence coefficient  , The final classification result is passed through K Perceptrons with different weights vote , This model is also known as the voting perceptron
, The final classification result is passed through K Perceptrons with different weights vote , This model is also known as the voting perceptron
set up
For the first time k Update weight for times
Iterations of ( Number of trained samples )
Number of iterations for the next update
Set to
To
, Confidence coefficient
Explain the weight
This is an idea of integrated learning , use K A classifier , Vote to decide a result
 For the first time k Update weight for times
For the first time k Update weight for times  Number of iterations for the next update
Number of iterations for the next update  Set to
Set to  , Confidence coefficient
, Confidence coefficient 3、 ... and Average perceptron




T Is the total number of iterations ,
 by T Iteration average weight vector
by T Iteration average weight vector


Four Generate linearly separable data sets
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 6 12:07:09 2022
@author: chengxf2
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
import csv
def saveCsv(trainData):
with open('trainData.csv','w') as f:
wr = csv.writer(f)
wr.writerows(trainData)
'''
Classification generator
Reference resources https://cloud.tencent.com/developer/ask/sof/1961912/answer/2665673
args
n_samples: Total number of generated samples
n_features: Single sample dimension n_informative + n_redundant + n_repeated
n_classes : Category
centers: Sample center to be generated , The default is 3
n_informative: Multi information feature dimension
n_redundant: Redundant feature dimension
n_repeated: Duplicate information
shuffle: Upset
n_clusters-per_calsss: A category consists of several cluster form
return
data: array sample X
feature: Sample characteristics
'''
def makeTrain(batch=1000):
separable = False
trainData =[]
while not separable:
samples = make_classification(n_samples=batch, n_features=2, n_redundant=0, n_informative=1, n_clusters_per_class=1, flip_y=-1)
red = samples[0][samples[1] == 0]
blue = samples[0][samples[1] == 1]
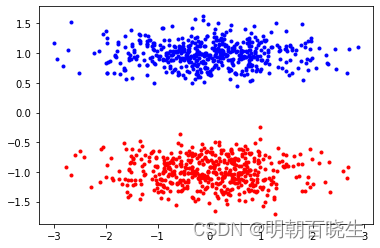
separable = any([red[:, k].max() < blue[:, k].min() or red[:, k].min() > blue[:, k].max() for k in range(2)])
data = samples[0]
feature = samples[1]
#print(np.shape(data),type(data))
for i in range(batch):
item = list(data[i])
label = feature[i]
item.append(label)
trainData.append(item)
#print(label)
plt.plot(red[:, 0], red[:, 1], 'r.')
plt.plot(blue[:, 0], blue[:, 1], 'b.')
plt.show()
return trainData
data = makeTrain(100)
saveCsv(data)5、 ... and Examples of parameter learning for two types of perceptrons
With the data set generated above Train
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 6 14:08:27 2022
@author: chengxf2
"""
import numpy as np
import torch
import csv
import os
# perceptron ( Artificial network that simulates the brain to recognize things and differences )
class perceptron():
'''
from csv Load the data set in the file
args
self.fileName : File path
'''
def loadData(self):
if not os.path.exists(self.fileName) :
print("\n ------ The file path does not exist -----")
return None
feature =[] # Sample labels Y skelearn by 0-1 Turn to -1,1
trainData =[] # Training set X
with open(self.fileName)as f:
f_csv = csv.reader(f)
for row in f_csv:
Y = int(row[-1])*2-1 # become [-1,1]
X = [float(v) for v in row[0:-1]]
X.append(1) # Generate augmented matrix
trainData.append(X)
feature.append(Y)
#print(data,label)
self.m,self.n = np.shape(trainData)
print("\n ---- First step Load data set ---------")
return torch.FloatTensor(trainData),torch.IntTensor(feature)
'''
forecast
'''
def forecast(self,w,x):
hatY = torch.matmul(w.T, x)
sgnY = 0
#print("\n forecast",w, x)
if hatY>0:
sgnY =1
elif hatY<0:
sgnY =-1
return hatY, sgnY
'''
forecast
'''
def test(self,trainData, feature,w):
err = 0
for i in range(0,self.m):
index = torch.LongTensor([i])
#print(index, index.dtype)
i = 0
x = trainData[index].T# Column vector
y = torch.index_select(feature, -1, index) # Corresponding tag value
predy,sngY =self.forecast(w,x)
result = sngY*y
#print("\n sngY: ",sngY,"\t y ",y)
if result<=0:
err = err+1
print("\n Number of classification errors ",err)
'''
Training
'''
def train(self,trainData, feature):
w = torch.zeros((3,1)) # Weight factor
k = 0 # The number of samples with errors in each round of prediction
t = 0 # The number of iterations
bLoop = True
print("\n -----step2 Training begins ---------------")
while(bLoop):
perm = torch.randperm(self.m) # Scrambling data sets Random sampling
k = 0 # The default for errors in this round of classification is 0
t =t+1 # The number of iterations
for i in range(self.m):
index = perm[i] # Index
x = trainData[index].T# Column vector
y = torch.index_select(feature, -1, index) # Corresponding tag value
hatY,sgnY = self.forecast(w,x) # forecast
result = y*sgnY # Whether the prediction is correct
if result<=0: # The prediction is wrong
k = k+1
a = y*x
w = w+a.view(3,1) # Update gradient
#print("\n result ",result, "\t ",y, "\t sgny ",sgnY,index)
print("\n k:%d t:%d "%(k,t),"w: ",w)
if t == self.maxIter:
print("\n --- Stop training ---------")
bLoop = False
break
return w
def __init__(self):
self.m = 0 # Number of samples
self.n = 0 # Sample dimension
self.maxIter = 10 # Maximum number of iterations
self.fileName = "trainData.csv"
if __name__ == "__main__":
model = perceptron()
trainData, feature = model.loadData()
w = model.train(trainData, feature)
model.test(trainData, feature, w)边栏推荐
- Redux使用
- 由排行榜实时更新想到的数状数值
- 软件测试笔试题你会吗?
- Redismission source code analysis
- 如何制作企业招聘二维码?
- 为什么更新了 DNS 记录不生效?
- Graphic network: uncover the principle behind TCP's four waves, combined with the example of boyfriend and girlfriend breaking up, which is easy to understand
- If time is a river
- 图解网络:揭开TCP四次挥手背后的原理,结合男女朋友分手的例子,通俗易懂
- PHP 计算个人所得税
猜你喜欢
nmap工具介绍及常用命令

Remote Sensing投稿经验分享

城市土地利用分布数据/城市功能区划分布数据/城市poi感兴趣点/植被类型分布
Write a pure handwritten QT Hello World

保姆级教程:Azkaban执行jar包(带测试样例及结果)

Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)
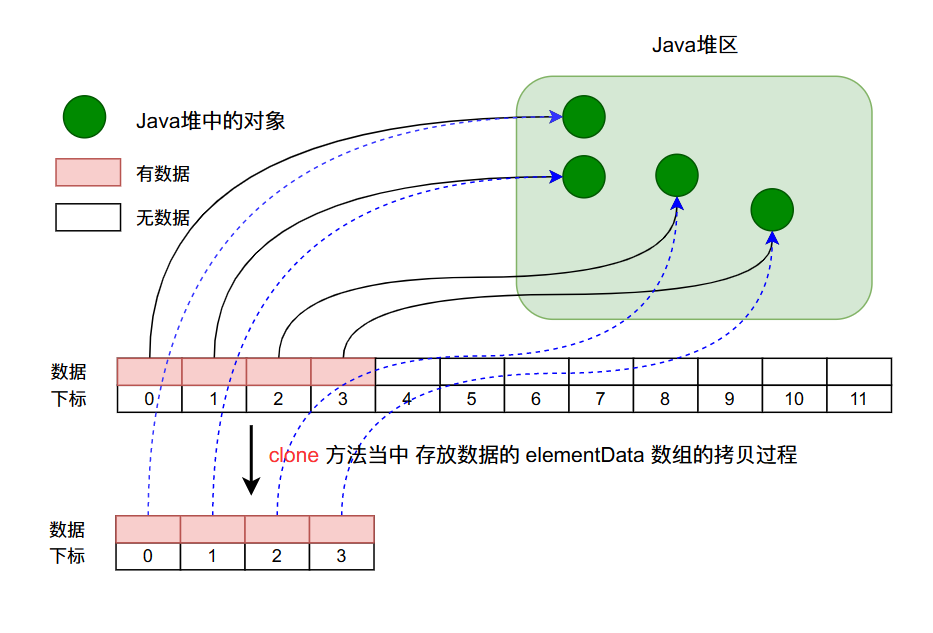
In depth analysis of ArrayList source code, from the most basic capacity expansion principle, to the magic iterator and fast fail mechanism, you have everything you want!!!
Get familiar with XML parsing quickly
Nmap tool introduction and common commands
![[target tracking] |dimp: learning discriminative model prediction for tracking](/img/72/d151fe0eb0a92e8c6931e6c50dad0f.png)
[target tracking] |dimp: learning discriminative model prediction for tracking
随机推荐
ArrayList源码深度剖析,从最基本的扩容原理,到魔幻的迭代器和fast-fail机制,你想要的这都有!!!
WPF 自定义 写实风 雷达图控件
Keras深度学习实战——基于Inception v3实现性别分类
adb工具介绍
腾讯游戏客户端开发面试 (Unity + Cocos) 双重轰炸 社招6轮面试
Graphic network: uncover the principle behind TCP's four waves, combined with the example of boyfriend and girlfriend breaking up, which is easy to understand
Redission源码解析
How mysql/mariadb generates core files
发现值守设备被攻击后分析思路
Js中forEach map无法跳出循环问题以及forEach会不会修改原数组
Version 2.0 of tapdata, the open source live data platform, has been released
QML fonts use pixelsize to adapt to the interface
Sum of submatrix
Sword finger offer II 041 Average value of sliding window
电路如图,R1=2kΩ,R2=2kΩ,R3=4kΩ,Rf=4kΩ。求输出与输入关系表达式。
C语言-Cmake-CMakeLists.txt教程
ArrayList源码深度剖析,从最基本的扩容原理,到魔幻的迭代器和fast-fail机制,你想要的这都有!!!
液压旋转接头的使用事项
Node JS maintains a long connection
Write a pure handwritten QT Hello World