当前位置:网站首页>Summary of log feature selection (based on Tianchi competition)
Summary of log feature selection (based on Tianchi competition)
2022-07-08 01:47:00 【Mark_ Aussie】
The data is based on the third Alibaba cloud panjiu Zhiwei algorithm competition ,
Official address : Questions and data of the third Alibaba cloud panjiu Zhiwei algorithm competition - Tianchi competition - Alibaba cloud Tianchi (aliyun.com)
Runner up program gihub:AI-Competition/3rd_PanJiu_AIOps_Competition at main · yz-intelligence/AI-Competition · GitHub
This competition question provides fault work order and log data , analysis msg Structure , according to | It can be decomposed . According to the actual business scenario , Before and after the failure 5/10/15/30 Log information generated in minutes or more , May be related to this fault .
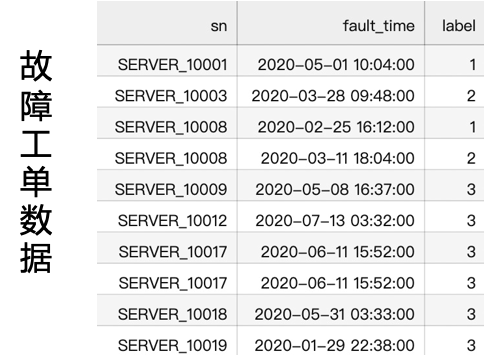

sn Represents the server serial number , There are... In the fault work order 13700+ individual sn;
Server model server_model And server serial number sn It's a one-to-many relationship ;
take msg after TF-IDF code , Input into the linear model , Use eli5 Get the results under each category ,msg The contribution of words , The higher the weight, the greater the contribution to distinguish the category .
0 Classes and 1 Class represents CPU Related faults ,processor Is the highest weight , And the discrimination is not very high ;
2 Class represents a memory related fault , The higher weight is memory、mem、ecc;
3 Class represents other types of faults , The higher weight is hdd、fpga、bus, It may be a hardware related failure .

Main steps : Data preprocessing , Feature Engineering , feature selection , model training , Model fusion .
Data preprocessing : According to the interval from the occurrence time of the fault , Divide the log into different time intervals ;msg Standardization according to special symbols .
Feature Engineering : Mainly build keyword features 、 Time difference characteristics 、TF-IDF Statistical characteristics of word frequency 、W2V features 、 Statistical characteristics 、New Data features .
feature selection : Feature selection against verification , Ensure the consistency of training and test sets , Improve the generalization ability of the model in the test set .
model training :CatBoost And LightGBM Model training using pseudo label technique .
Model fusion :CatBoost And LightGBM The result of the prediction is 8:2 The final model prediction result is obtained by weighted fusion .
According to the actual business scenario , An alarm log may be generated before the fault occurs , A log storm may occur after a fault occurs , For each fault work order data , Construct new log data according to different time segmentation , Construct statistical features after log aggregation .
Feature Engineering :
Time difference characteristics
Reflect the interval between failure log and normal log . Feature construction method :
Get the time difference between the log time and the failure time , combination
sn, server_modelGroup feature derivation .Statistical characteristics of time difference :
[max, min, median, std, var, skw, sum, mode]Quantile characteristics of time difference :
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]Time difference :
[max, min, median, std, var, skw, sum]
Keyword features
The influence of keywords on each category . To construct keyword features, you must first find the keyword , There are two ways to determine keywords :
programme 1:msg do TF-IDF code , Input into the linear model , Calculate the weight of keywords under each category , Take... For each category TOP20.
programme 2: according to ' | ' Yes msg participle , Count the word frequency of each category , Take... For each category TOP20.
Method 1 With the method 2 Union and collection , Get the final keyword .
Put each keyword in msg Whether or not it appears in .
Statistical characteristics : Statistical features are constructed by grouping according to category features , Make the hidden information of category characteristics fully exposed .
according to
sngrouping ,server_modeStatistical characteristics :[count,nunique,freq,rank]according to
sngrouping , Log statistical characteristics :msg, msg_0, msg_1, msg_2:[count,nunique,freq,rank]
W2V features : reflect msg Semantic information
according to
sngrouping , According to the timemsgSort , For each of thesesn, Sort it outmsgAs a sequence , extractembeddingfeatures .
TFIDF features
according to fault_id(sn+fault_time) grouping , according to fault_id take msg Splice as a sequence , extract TF-IDF features .
feature selection
Feature selection is mainly to use confrontation verification for feature selection , Delete training set and test set label Re marking , The training set is 1, The test set is 0, Data sets are merged for model training calculation AUC, If AUC Greater than the set threshold , Delete the feature with the highest importance , Retraining the model . until AUC Less than threshold .
During model training , Using pseudo tag technology , Specifically, I will A、B Prediction results of the test set , Selection confidence >0.85 As a trusted sample , Join the training set , To increase the sample size .
Reference resources :
Tianchi algorithm competition : Fault diagnosis runner up scheme based on large-scale log !
边栏推荐
- Graphic network: uncover the principle behind TCP's four waves, combined with the example of boyfriend and girlfriend breaking up, which is easy to understand
- Mat file usage
- Leetcode exercise - Sword finger offer 36 Binary search tree and bidirectional linked list
- regular expression
- php 获取音频时长等信息
- 从Starfish OS持续对SFO的通缩消耗,长远看SFO的价值
- Tapdata 的 2.0 版 ,開源的 Live Data Platform 現已發布
- Urban land use distribution data / urban functional zoning distribution data / urban POI points of interest / vegetation type distribution
- From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
- powerbuilder 中使用线程的方法
猜你喜欢

用户之声 | 对于GBase 8a数据库学习的感悟
Get familiar with XML parsing quickly

Redux usage

3、多智能体强化学习
Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
![[SolidWorks] modify the drawing format](/img/3c/b00e4510b1e129069140c2666c0727.png)
[SolidWorks] modify the drawing format

碳刷滑环在发电机中的作用
Understanding of maximum likelihood estimation

Sword finger offer II 041 Average value of sliding window
C语言-模块化-Clion(静态库,动态库)使用
随机推荐
Different methods for setting headers of different pages in word (the same for footer and page number)
ROS 问题(topic types do not match、topic datatype/md5sum not match、msg xxx have changed. rerun cmake)
Gnuradio transmits video and displays it in real time using VLC
Codeforces Round #649 (Div. 2)——A. XXXXX
Understanding of expectation, variance, covariance and correlation coefficient
滑环使用如何固定
In depth analysis of ArrayList source code, from the most basic capacity expansion principle, to the magic iterator and fast fail mechanism, you have everything you want!!!
Optimization of ecological | Lake Warehouse Integration: gbase 8A MPP + xeos
从cmath文件看名字是怎样被添加到命名空间std中的
After modifying the background of jupyter notebook and adding jupyterthemes, enter 'JT -l' and the error 'JT' is not an internal or external command, nor a runnable program
NPM Internal Split module
用户之声 | 对于GBase 8a数据库学习的感悟
Redis集群
Kindle operation: transfer downloaded books and change book cover
LaTeX 中 xcolor 颜色的用法
Working principle of stm32gpio port
Kafka-connect将Kafka数据同步到Mysql
Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)
break net
About snake equation (5)