当前位置:网站首页>14、Transformer--VIT TNT BETR
14、Transformer--VIT TNT BETR
2022-07-05 20:18:00 【C--G】
VIT–Vision Transformer
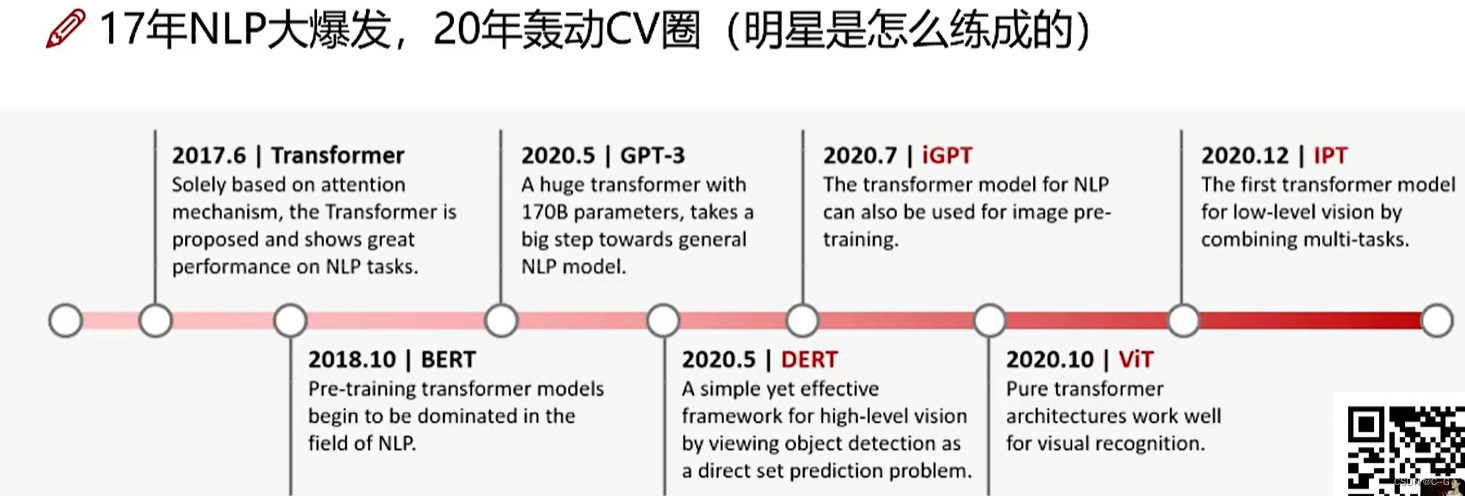

VIT架构图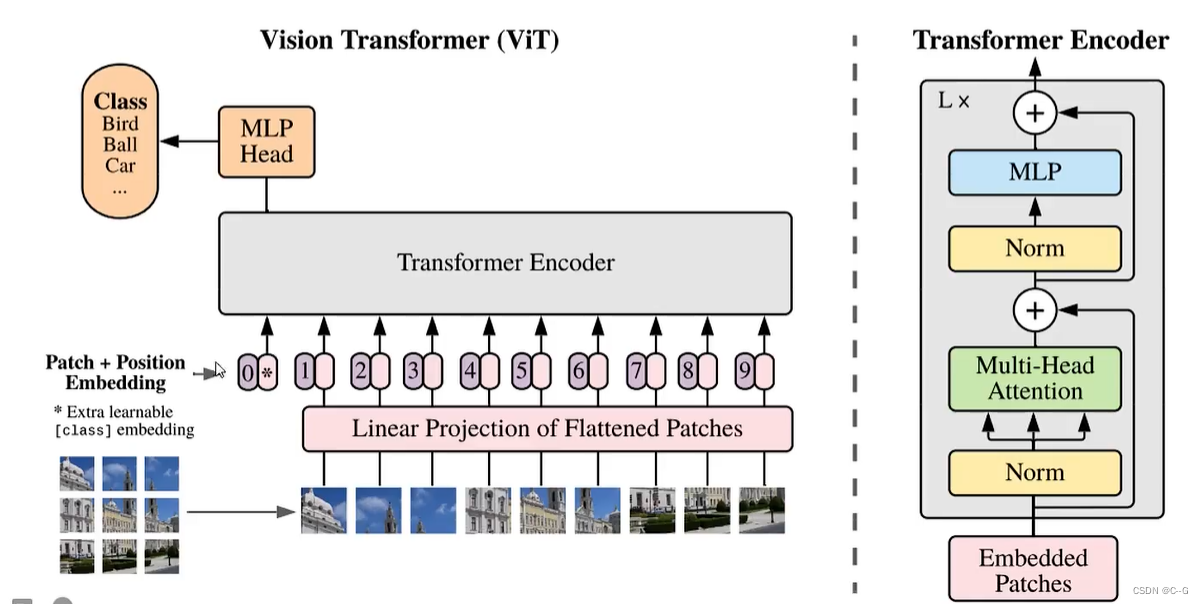

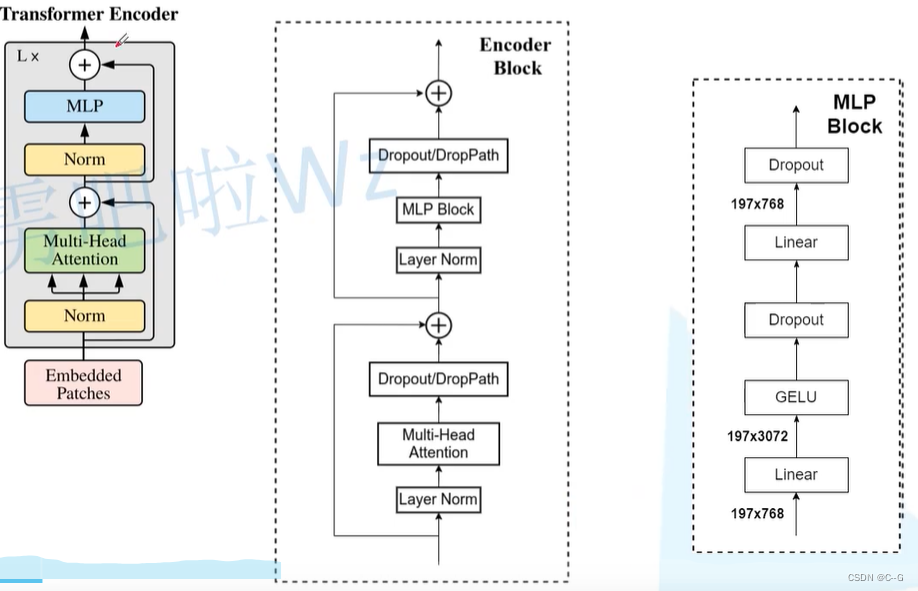
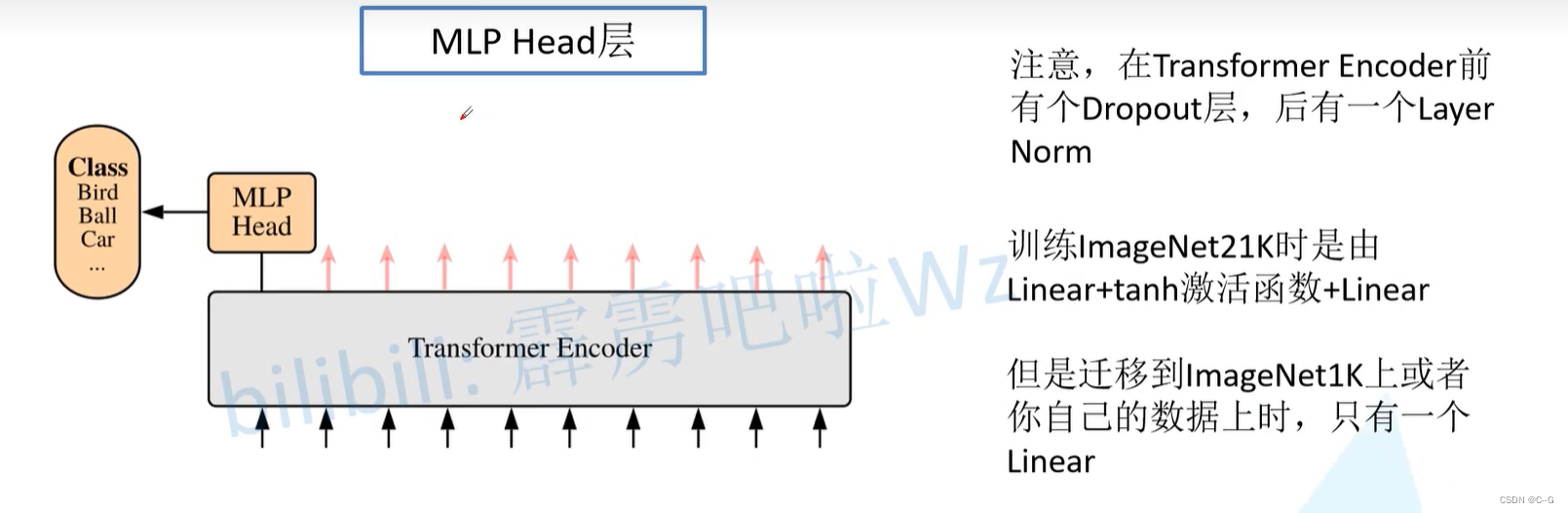
VIT为图像分类任务,这里使用了transformer的编码器,将图片分为九块,加上位置编码后并转化为一维再放入编码器,编码器此时有9个输入token,其中0号token与其他9位token进行了交互计算,融合了其他9位token的特征信息,因此只需要0号token即可,后面就是MLP Head和分类即可
- CNN的问题

- transformer优势

- 公式

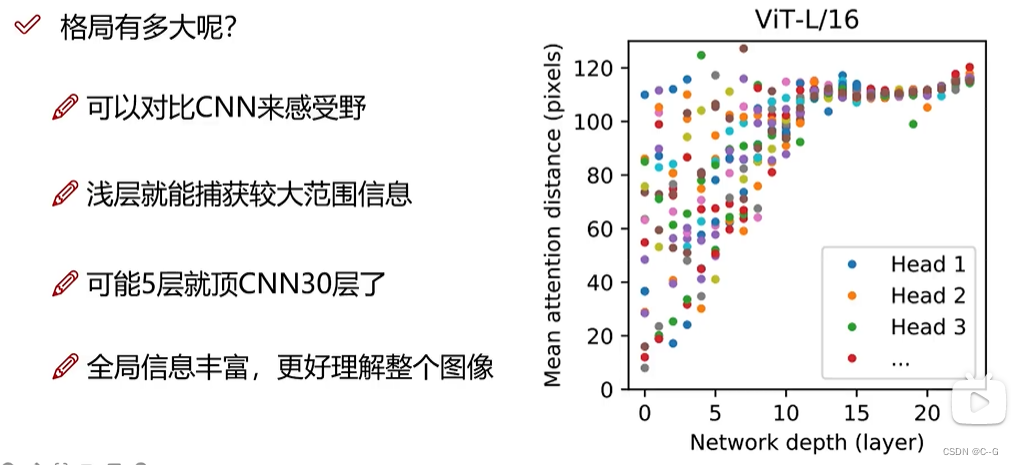
- VIT格局
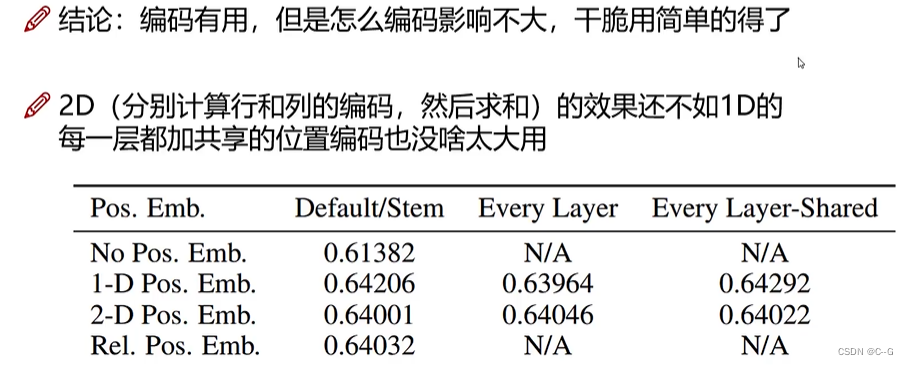
- 位置编码
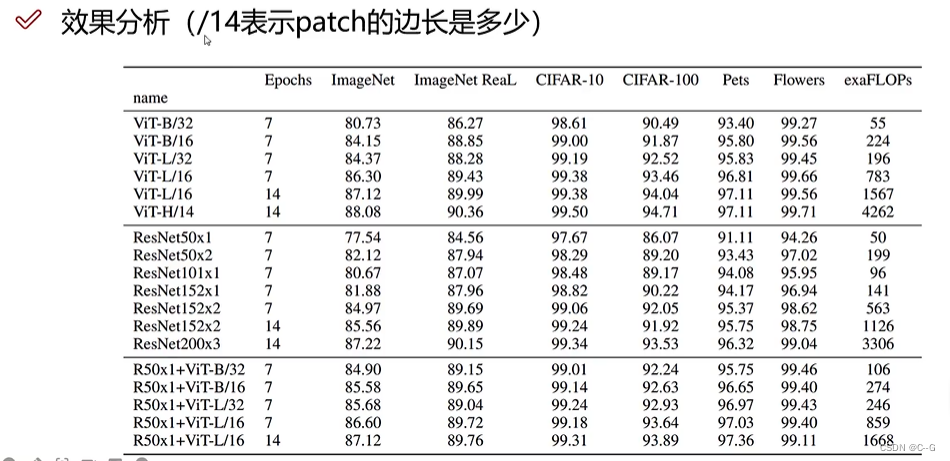
- 效果分析
- 代码链接
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/vision_transformer
TNT-Transformer in Transformer
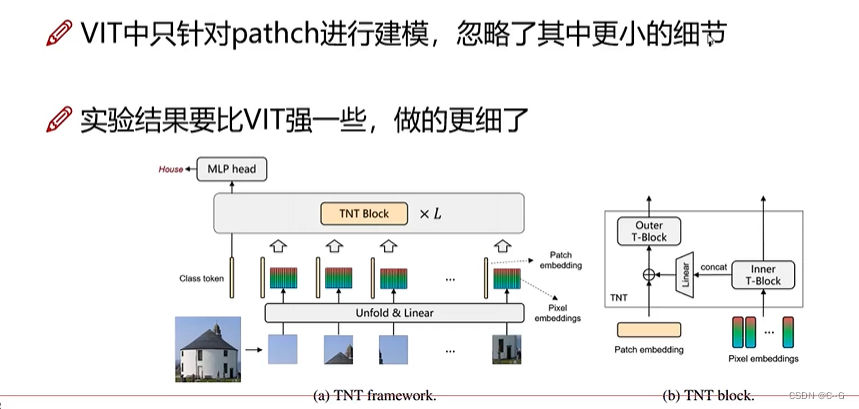
- 基本组成
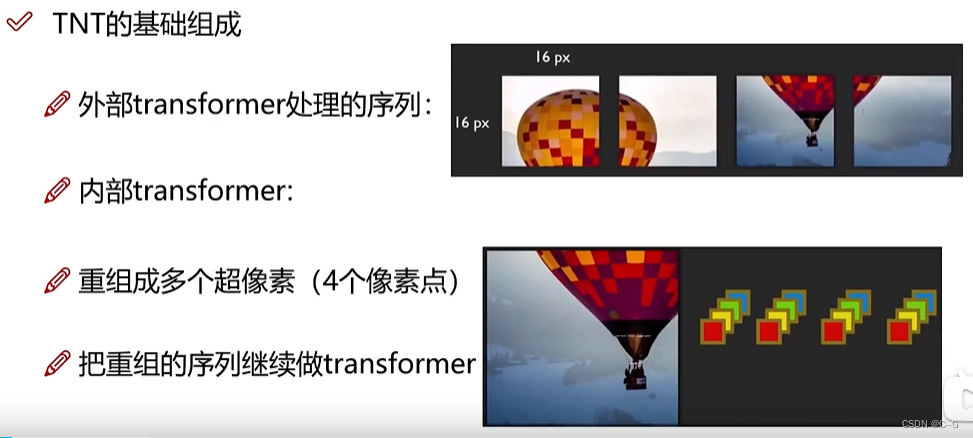
- 序列构建
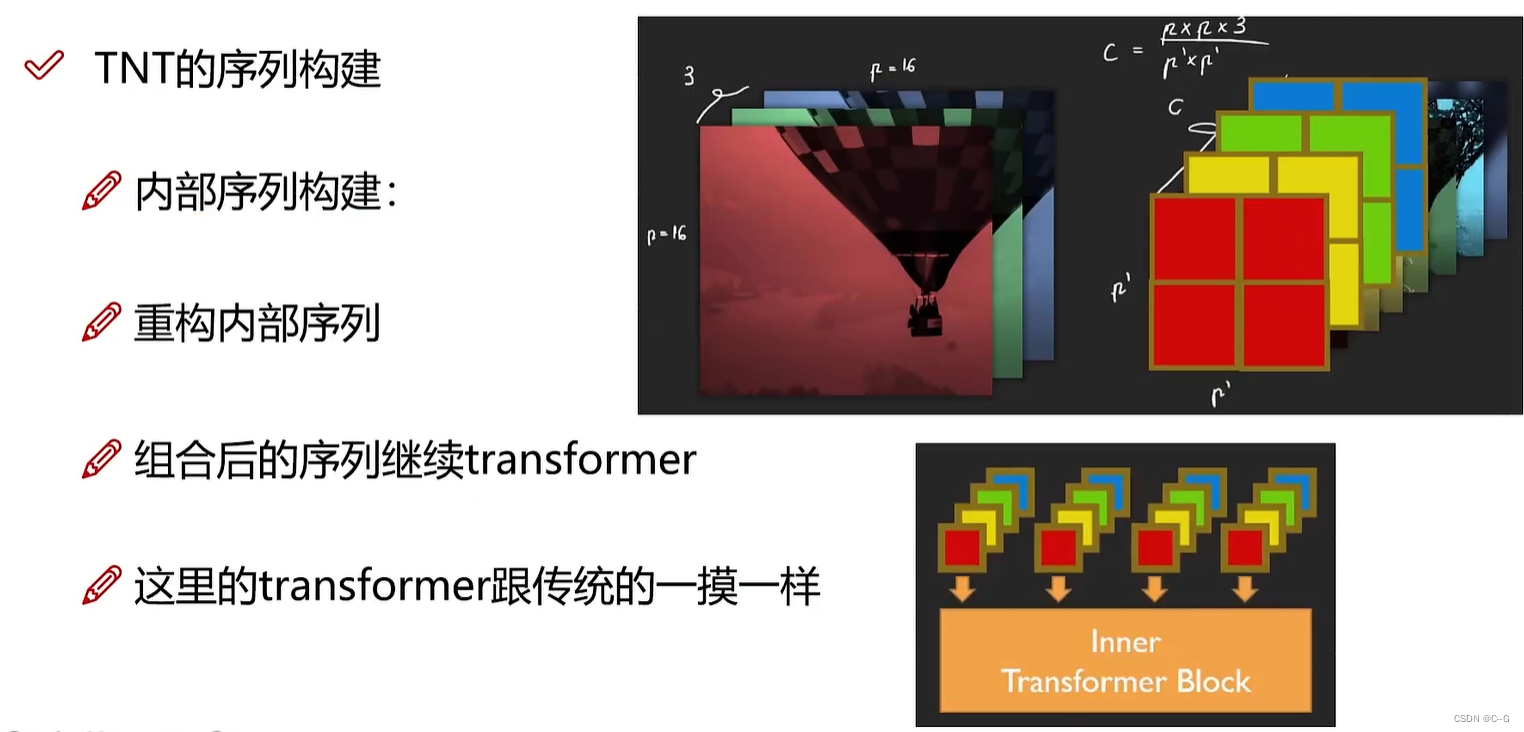
- 基本计算
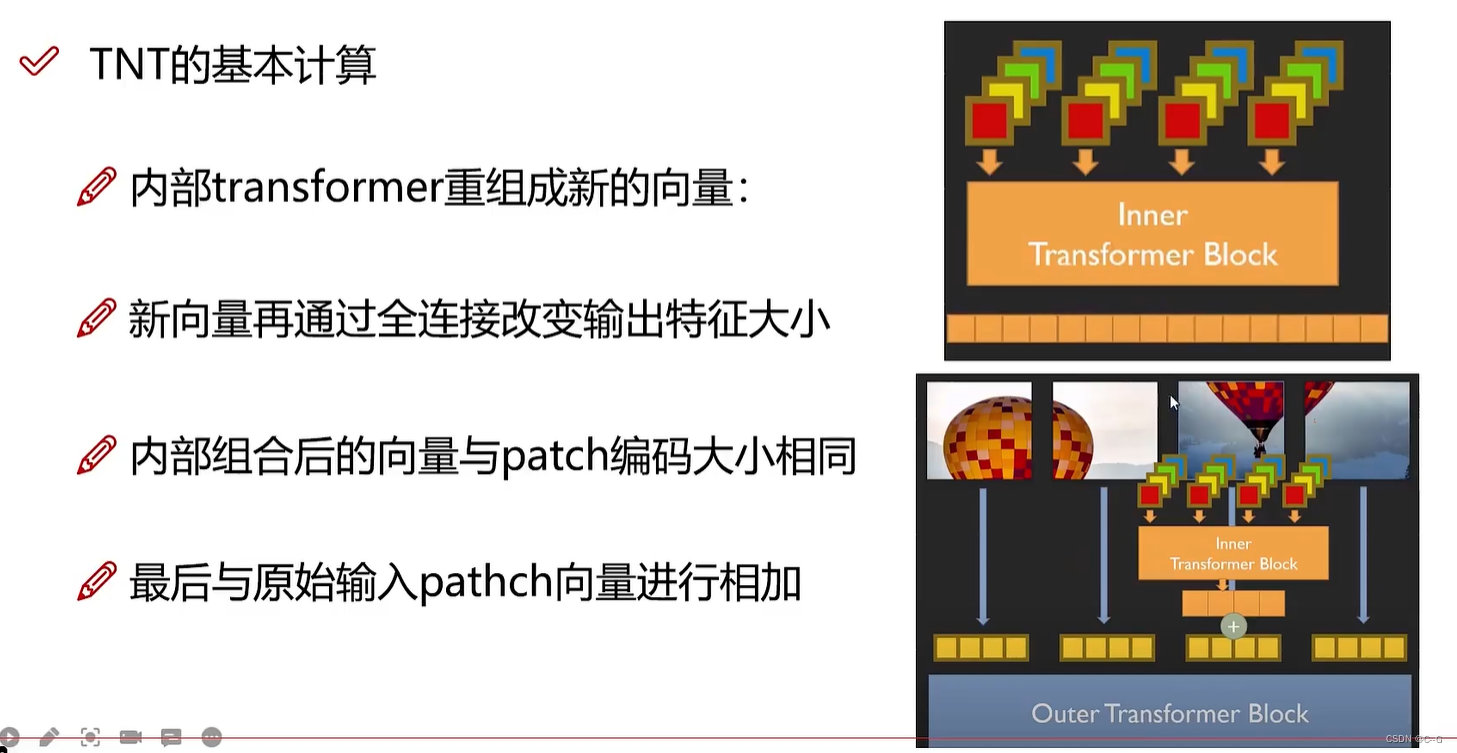
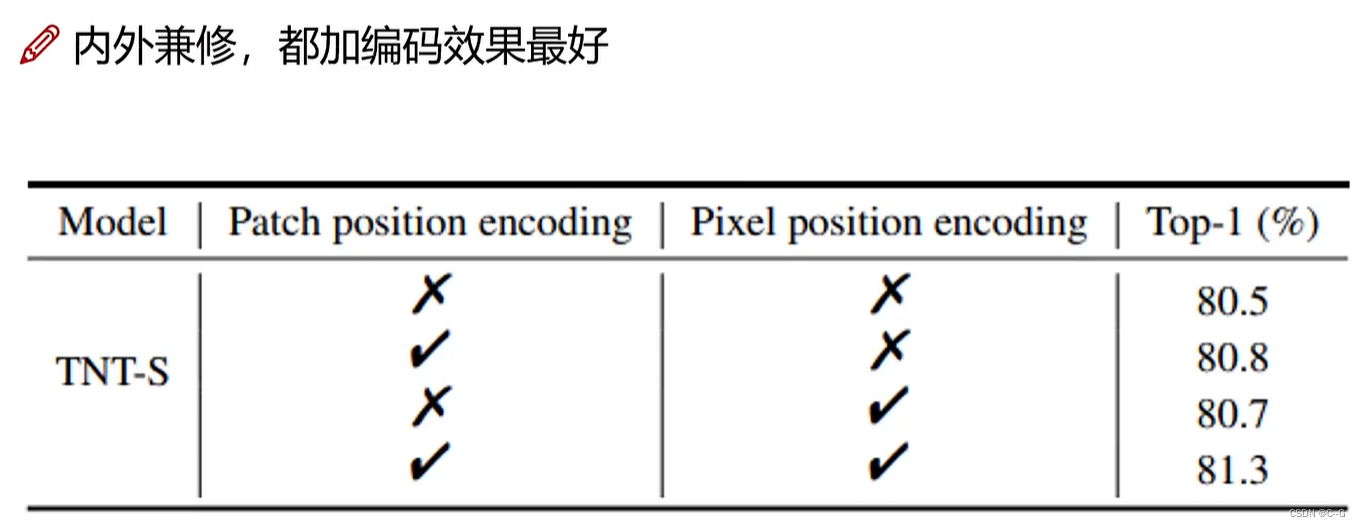
- 位置编码
- PatchEmbedding可视化

BETR
目标检测

基本思想
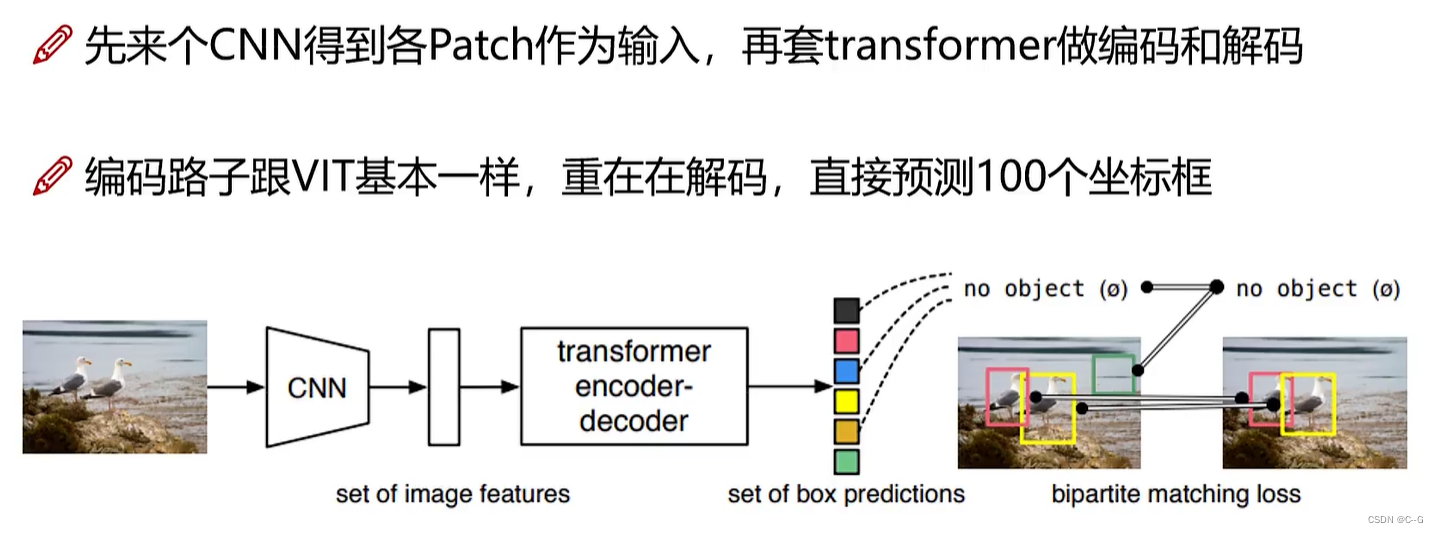
并行预测100个坐标框,没有物体,那就是背景网络架构
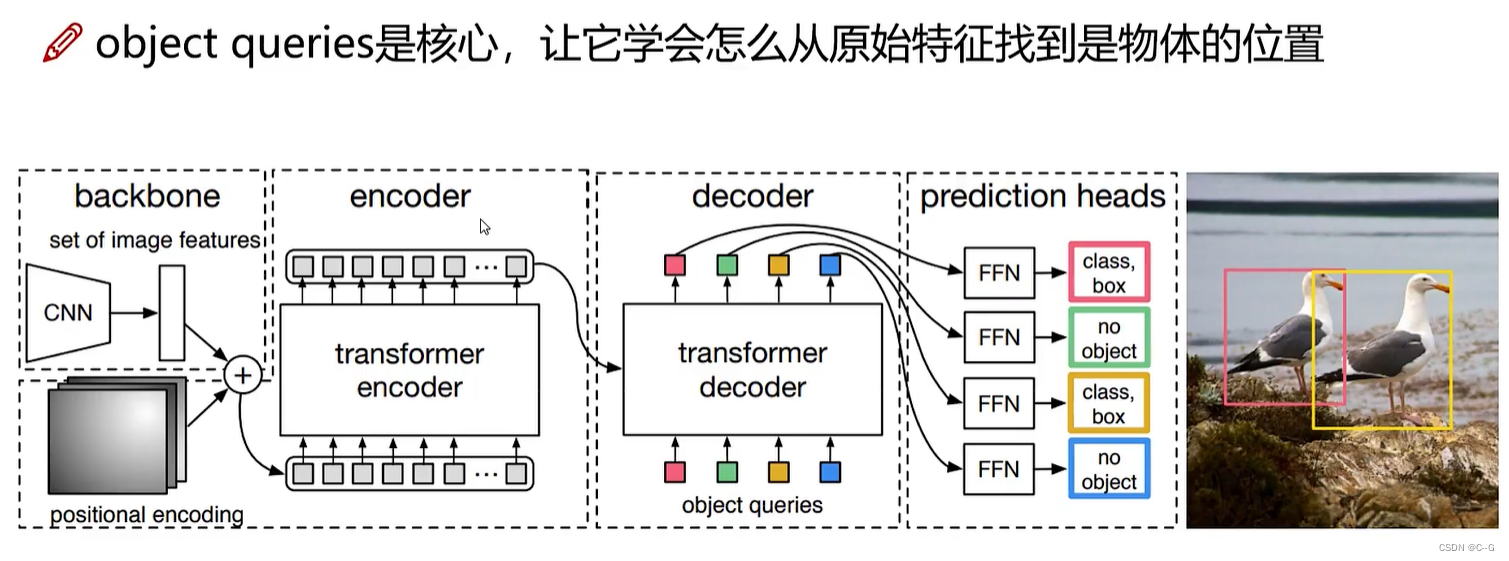
cnn获取一维特征图,positional encoding获取位置编码,与VIT不同,BETR没有0号token,与传统Transformer Decoder不同,BETR是由object queries一次产生多少坐标框,每个框并行与encoder输出进行匹配,再通过prediction heads判断是否是目标框
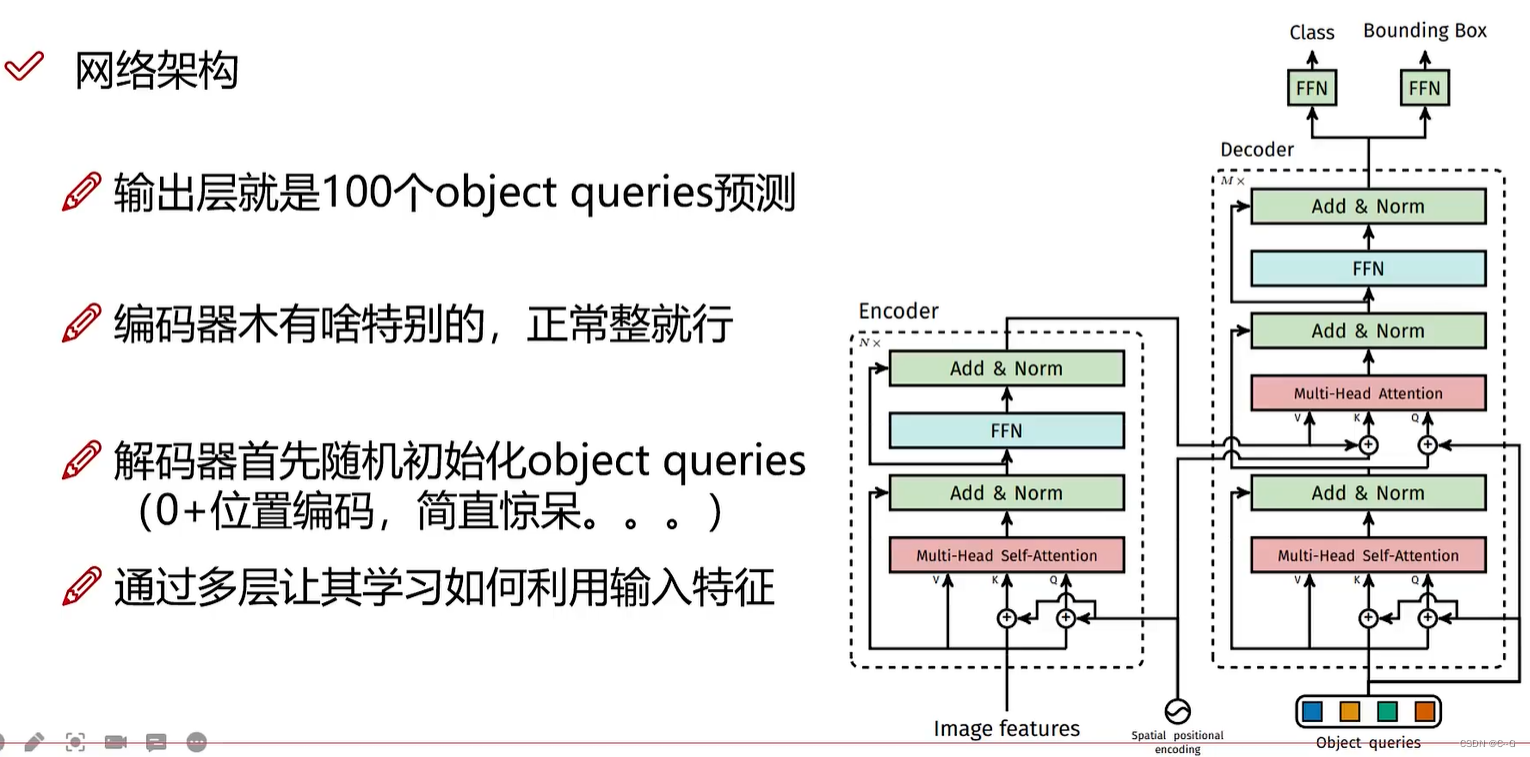
Encoder的任务

encoder提供目标的注意力结果优于cnn的特征图结果,有利于解码器快速识别目标,如图所示,encoder在有遮挡情况下也能很好的识别物体网络架构
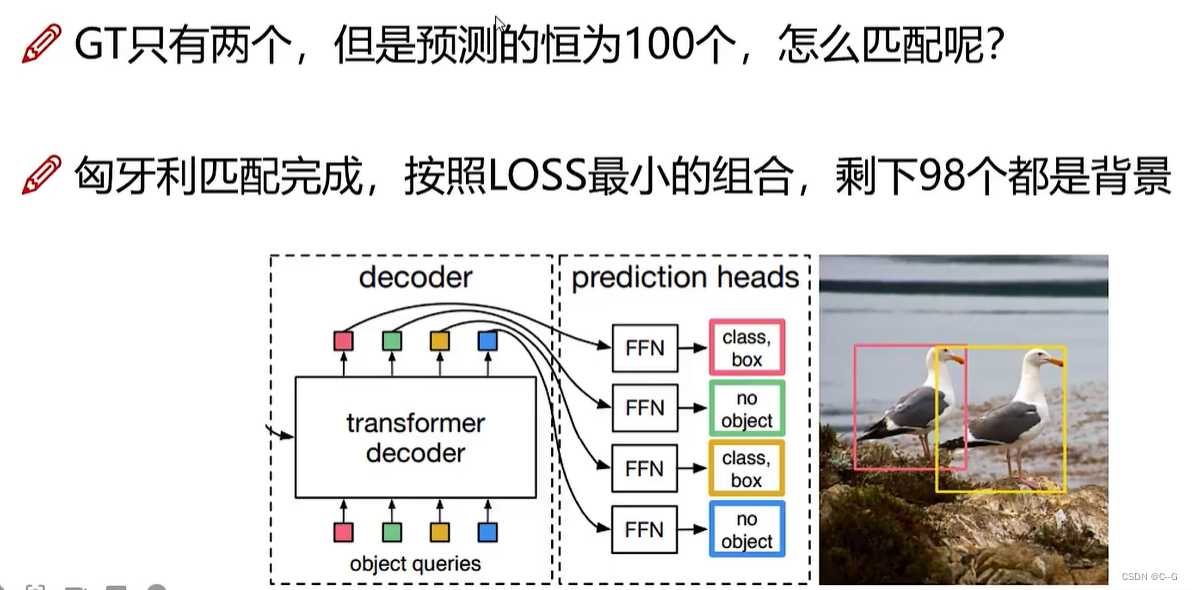
输出匹配
注意力的作用


数据资源–大佬的博客
https://blog.csdn.net/qq_37774399/article/details/121748163
边栏推荐
- How to retrieve the root password of MySQL if you forget it
- Parler de threadlocal insecurerandom
- 2020 CCPC 威海 - A. Golden Spirit(思维),D. ABC Conjecture(大数分解 / 思维)
- [C language] three implementations of quick sorting and optimization details
- 【数字IC验证快速入门】9、Verilog RTL设计必会的有限状态机(FSM)
- Unity editor extended UI control
- What is PyC file
- Some problems encountered in cocos2d-x project summary
- 信息学奥赛一本通 1340:【例3-5】扩展二叉树
- Securerandom things | true and false random numbers
猜你喜欢
![[Yugong series] go teaching course in July 2022 004 go code Notes](/img/18/ffbab0a251dc2b78eb09ce281c2703.png)
[Yugong series] go teaching course in July 2022 004 go code Notes
ROS2专题【01】:win10上安装ROS2

About the priority of Bram IP reset

js实现禁止网页缩放(Ctrl+鼠标、+、-缩放有效亲测)
Rainbond 5.7.1 支持对接多家公有云和集群异常报警
![[quick start to digital IC Verification] 8. Typical circuits in digital ICs and their corresponding Verilog description methods](/img/3a/7eaff0bf819c129b4f866388e57b87.png)
[quick start to digital IC Verification] 8. Typical circuits in digital ICs and their corresponding Verilog description methods
Go language | 02 for loop and the use of common functions

leetcode刷题:二叉树14(左叶子之和)
【数字IC验证快速入门】3、数字IC设计全流程介绍
关于BRAM IP复位的优先级
随机推荐
sort和投影
图嵌入Graph embedding学习笔记
走入并行的世界
Unity editor extended UI control
Wechat applet regular expression extraction link
DP: tree DP
秋招字节面试官问你还有什么问题?其实你已经踩雷了
Autumn byte interviewer asked you any questions? In fact, you have stepped on thunder
本季度干货导航 | 2022年Q2
Let's talk about threadlocalinsecurerandom
强化学习-学习笔记4 | Actor-Critic
ROS2专题【01】:win10上安装ROS2
CTF reverse Foundation
Go language | 03 array, pointer, slice usage
Elk distributed log analysis system deployment (Huawei cloud)
USACO3.4 “破锣摇滚”乐队 Raucous Rockers - DP
Reinforcement learning - learning notes 4 | actor critical
Some problems encountered in cocos2d-x project summary
Go language learning tutorial (16)
Leetcode skimming: binary tree 10 (number of nodes of a complete binary tree)