当前位置:网站首页>Convolution free backbone network: Pyramid transformer to improve the accuracy of target detection / segmentation and other tasks (with source code)
Convolution free backbone network: Pyramid transformer to improve the accuracy of target detection / segmentation and other tasks (with source code)
2022-07-05 20:10:00 【Computer Vision Research Institute】

Computer Vision Institute column
author :Edison_G
Embedding pyramid structure into Transformer Structure is used to generate multi-scale features , And finally used in dense prediction tasks .
official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage
Pay attention to the parallel stars
Never get lost
Institute of computer vision


Address of thesis :https://arxiv.org/pdf/2102.12122.pdf
Source code address :https://github.com/whai362/PVT
background
With self attention Transformer It triggered a revolution in the field of natural language processing , Recently also inspired Transformer The emergence of Architectural Design , It has achieved competitive results in many computer vision tasks .
Here's what we shared earlier based on Transformer New target detection technology !
link :ResNet Super variant : JD.COM AI New open source computer vision module !( With source code )
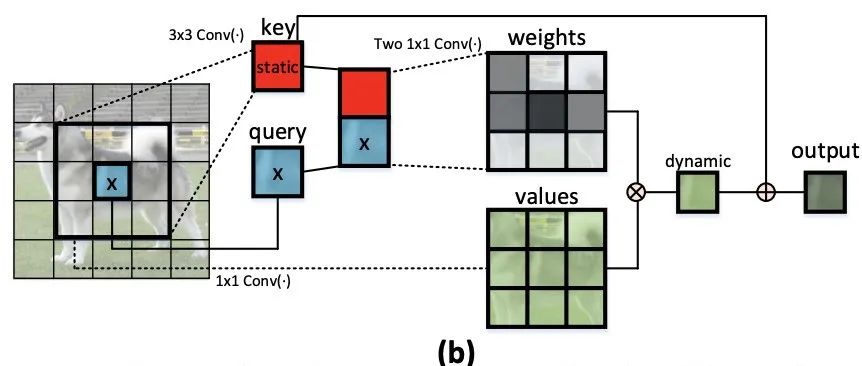
link : utilize TRansformer End to end target detection and tracking ( With source code )
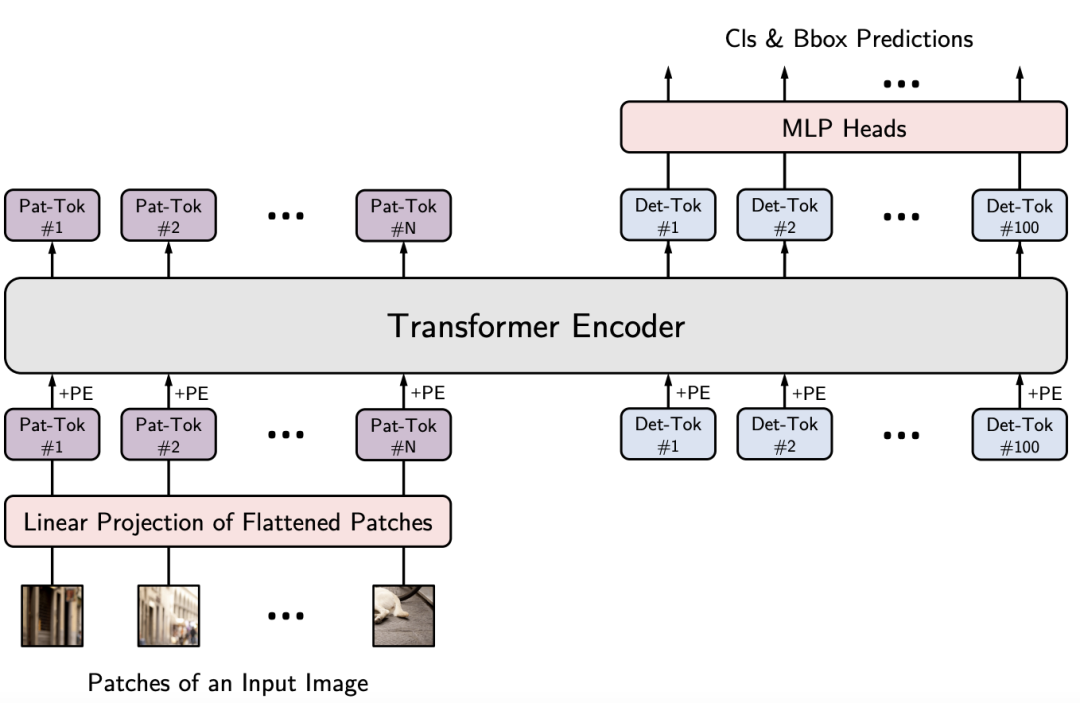
link :YOLOS: Rethink through target detection Transformer( With source code )
In the work shared today , The researchers designed a novel Transformer modular , Backbone network for dense prediction tasks , utilize Transformer The architecture design has made an innovative exploration , Combine the feature pyramid structure with Transformer A fusion , So that it can better output multi-scale features , Thus, it is more convenient to combine with other downstream tasks .
Preface
Although convolutional neural networks (CNN) Great success has been achieved in computer vision , But the work shared today explores a simpler 、 Convolution free backbone network , It can be used for many intensive prediction tasks .
object detection

Semantic segmentation

Instance segmentation
Compared with the recently proposed method designed for image classification Vision Transformer(ViT) Different , The researchers introduced Pyramid Vision Transformer(PVT), It overcomes the problem of Transformer The difficulty of porting to various intensive prediction tasks . Compared with the current state of Technology ,PVT There are several advantages :
It is different from that which usually produces low resolution output and leads to high computing and memory costs ViT Different ,PVT It can not only be trained on the dense partition of the image to obtain the information which is very important for dense prediction High output resolution , It also uses a progressive contraction pyramid to Reduce the calculation of large feature map ;
PVT Inherited CNN and Transformer The advantages of , Make it a unified backbone of various visual tasks , No convolution , It can directly replace CNN The trunk ;
Through a large number of experiments PVT, Show it Improved performance of many downstream tasks , Including object detection 、 Instance and semantic segmentation .
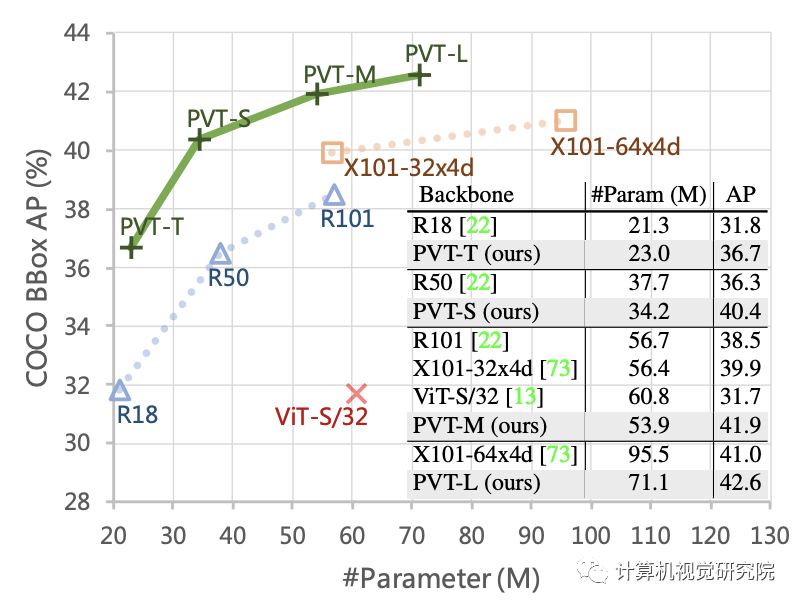
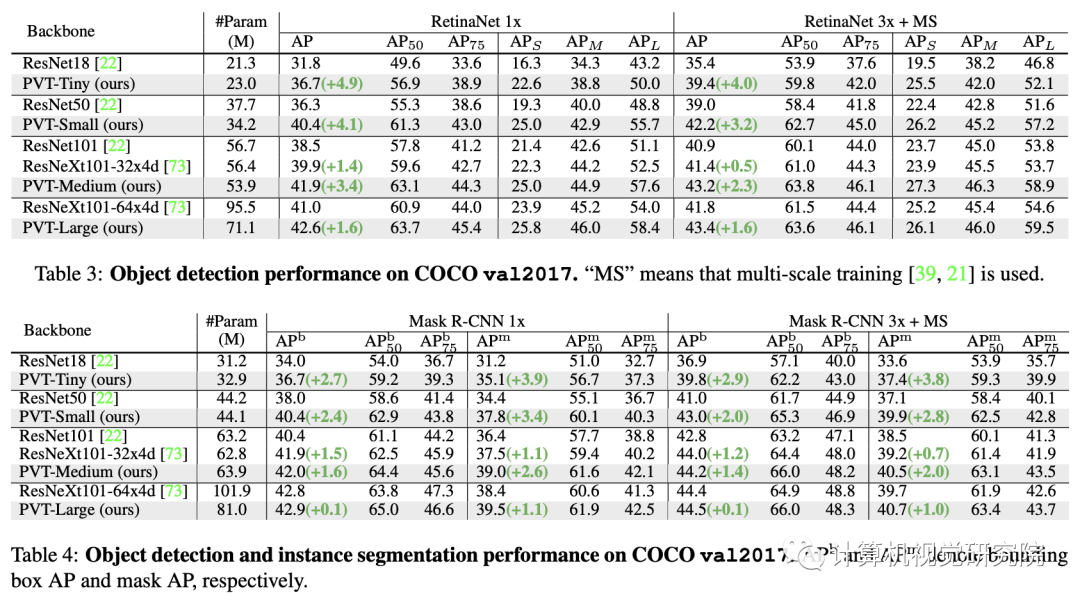
for example , When the number of parameters is equal ,PVT+RetinaNet stay COCO Data set on the implementation of 40.4 AP, exceed ResNet50+RetinNet(36.3 AP)4.1 Absolutely AP( See the picture below ). The researchers hope that PVT It can be used as an alternative and useful backbone for pixel level prediction , And promote future research .
Basic review
CNN Backbones
CNN It is the main force of deep neural network in visual recognition . standard CNN Originally in 【Gradient-based learning applied to document recognition】 Write numbers in the middle . The model includes convolution kernel with specific receptive field to capture favorable visual environment . In order to provide translation equivariance , The weight of convolution kernel is shared in the whole image space . lately , With the rapid development of computing resources ( for example ,GPU), Stacked convolution blocks are successfully trained on large-scale image classification data sets ( for example ,ImageNet) Has become possible . for example ,GoogLeNet It is proved that the convolution operator with multiple kernel paths can achieve very competitive performance .
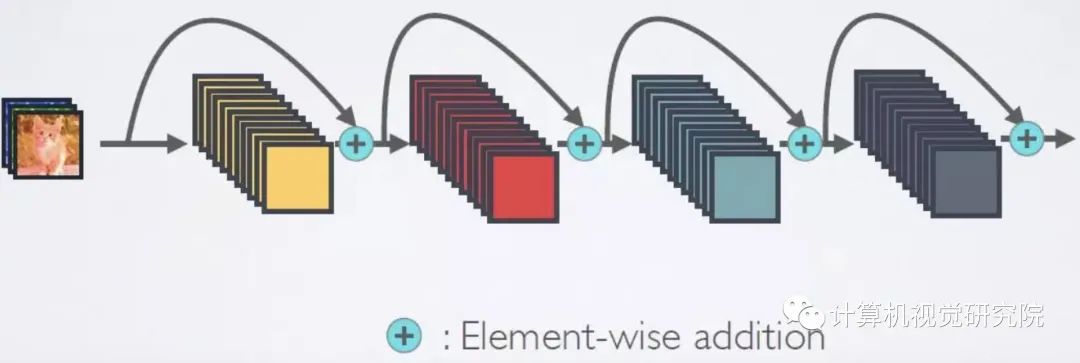
multi-path convolutional block The effectiveness of Inception series 、ResNeXt、DPN、MixNet and SKNet It has been further verified . Besides ,ResNet The skip connection is introduced into the convolution block , So you can create / Train a very deep network and get impressive results in the field of computer vision .DenseNet A densely connected topology is introduced , It connects each convolution block to all previous blocks . More recent developments can be found in recent papers .
New framework
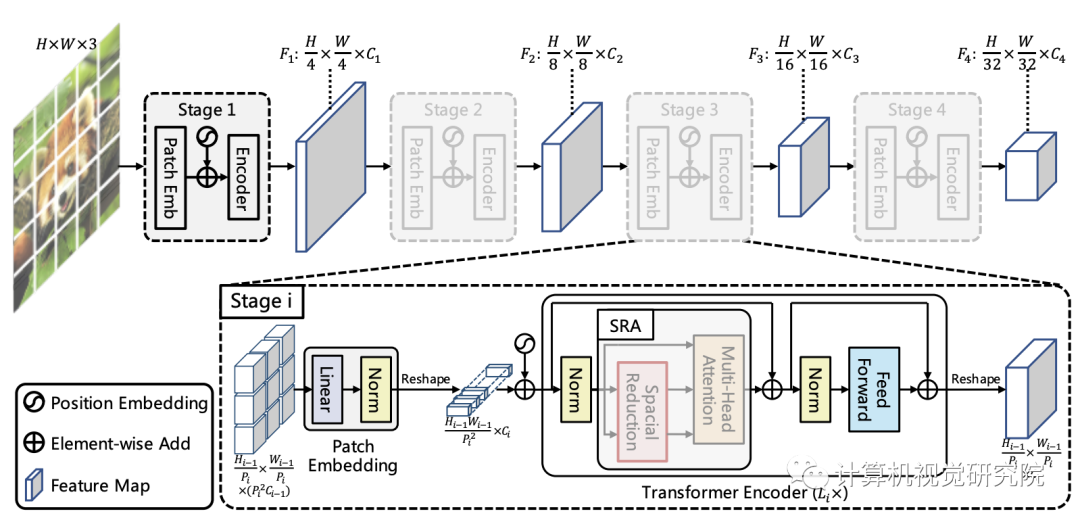
The framework aims to embed the pyramid structure into Transformer Structure is used to generate multi-scale features , And finally used in dense prediction tasks . The figure above shows the proposed PVT Schematic architecture , Similar to CNN Backbone structure ,PVT It also contains four stages for generating features with different scales , All stages have a similar structure :Patch Embedding+Transformer Encoder.
In the first stage , The given size is H*W*3 The input image of , Follow the following procedure :
First , Divide it into HW/4^2 The block , The size of each block is 4*4*3;
then , Send the expanded block to the linear projection , The obtained size is HW/4^2 * C1 Embedded block ;
secondly , The embedding block and position embedding information are sent to Transformer Of Encoder, Its output will be reshap by H/4 * W/4 * C1.
In a similar way , The output of the previous stage can be used as the input to obtain the feature F2,F3 and F4. Feature based pyramid F1、F2、F3、F4, The proposed scheme can be easily combined with most downstream tasks ( Such as image classification 、 object detection 、 Semantic segmentation ) To integrate .
Feature Pyramid for Transforme
differ CNN use stride Multiscale features obtained by convolution ,PVT By block embedding according to progressive shrinking The policy controls the scale of the feature .
Hypothesis number 1 i The block size of the stage is Pi, At the beginning of each phase , Evenly split the input features into Hi-1Wi-1/Pi Block , Then each block is expanded and projected onto Ci Embedded information of dimension , After linear projection , The size of the embedded block can be regarded as Hi-1/Pi * Wi-1/Pi * Ci. In this way, the feature size of each stage can be flexibly adjusted , Make it possible to target Transformer Build a feature pyramid .
Transformer Encoder
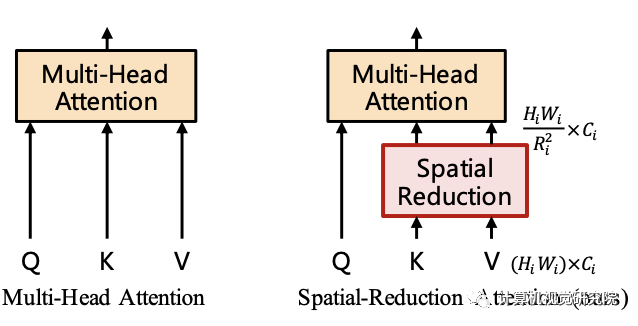
about Transformer encoder Of the i Stage , It has Li individual encoder layer , Every encoder Layer consists of attention layer and MLP constitute . Because the proposed method needs to deal with high-resolution features , Therefore, a SRA(spatial-reduction attention) Used to replace the traditional MHA(multi-head-attention).
Be similar to MHA,SRA Also received from the input Q、K、V As input , And output the refined characteristics .SRA And MHA The difference is that :SRA It will reduce K and V The spatial scale of , See the picture below .
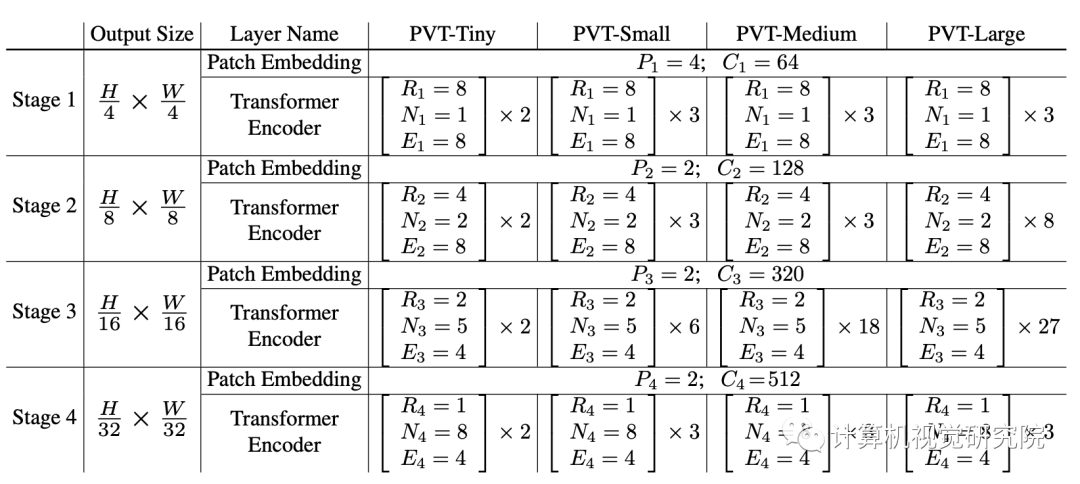
Detailed settings of PVT series
experiment
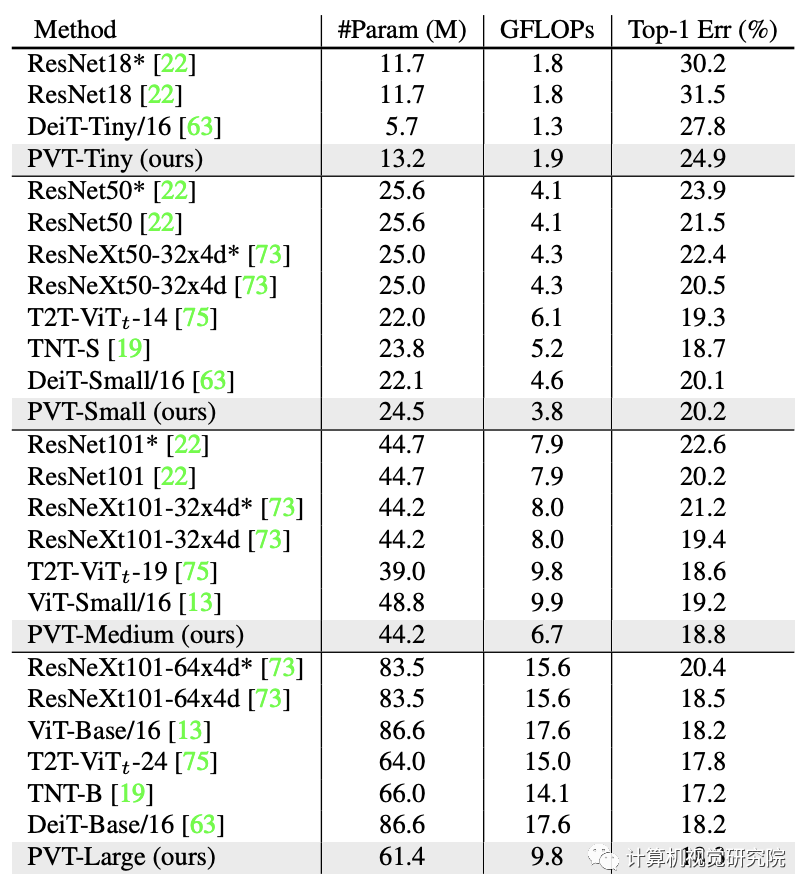
ImageNet Performance comparison on datasets , The results are shown in the table above . You can see from it :
comparison CNN, Under the same parameter quantity and calculation constraints ,PVT-Small achieve 20.2% The error rate of , be better than ResNet50 Of 21.5%;
Compared to other Transformer( Such as ViT、DeiT), The proposed PVT Considerable performance is achieved with less computation .
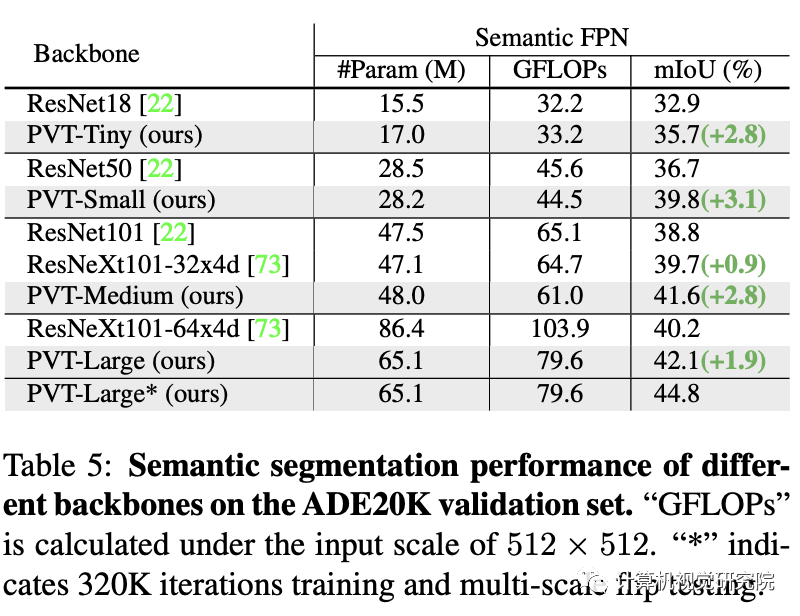
Performance comparison in semantic segmentation , See the table above . You can see : Under different parameter configurations ,PVT Can achieve better than ResNet And ResNeXt Performance of . This side shows : comparison CNN, Benefit from the global attention mechanism ,PVT Better features can be extracted for semantic segmentation .
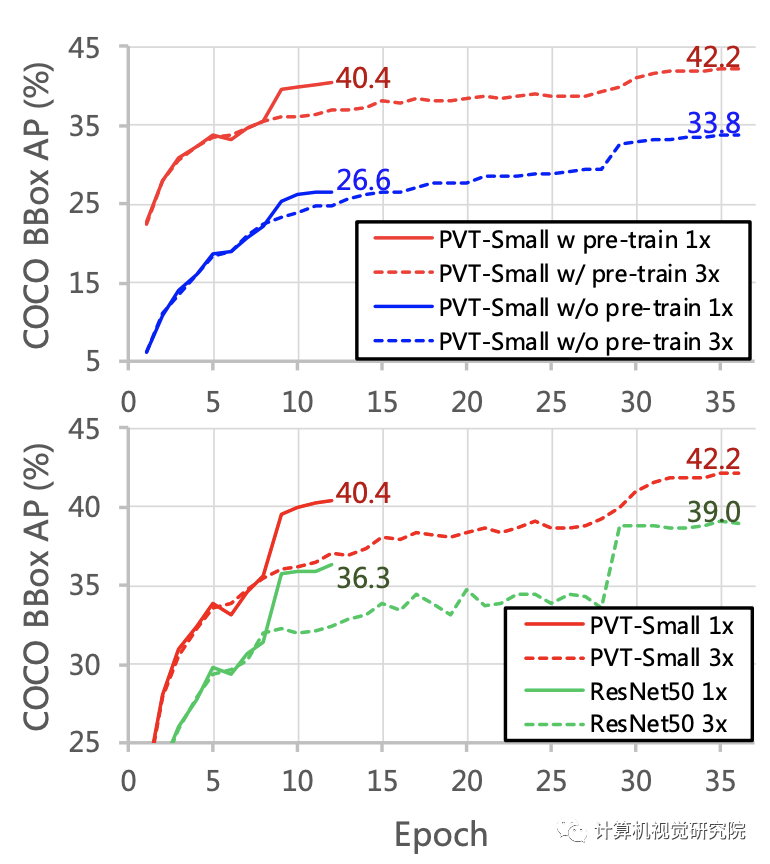

THE END
Please contact the official account for authorization.

The learning group of computer vision research institute is waiting for you to join !
Institute of computer vision Mainly involves Deep learning field , It's mainly about Face detection 、 Face recognition , Multi target detection 、 Target tracking 、 Image segmentation, etc Research direction . research institute Next, we will continue to share the latest papers, algorithms and new frameworks , The difference of our reform this time is , We need to focus on ” Research “. After that, we will share the practice process for the corresponding fields , Let's really understand Get rid of the theory The real scene of , Develop the habit of hands-on programming and brain thinking !

Sweep code Focus on
Institute of computer vision
official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage
Previous recommendation
YOLOS: Rethink through target detection Transformer( With source code )
I think it's an interesting target detection framework , Share with you ( Source papers have )
ICCV2021 object detection : Improve accuracy with graph feature pyramid ( Attached thesis download )
CVPR21 Best test : It is no longer a square target detection output ( Source code attached )
Sparse R-CNN: Sparse frame , End to end target detection ( Source code attached )
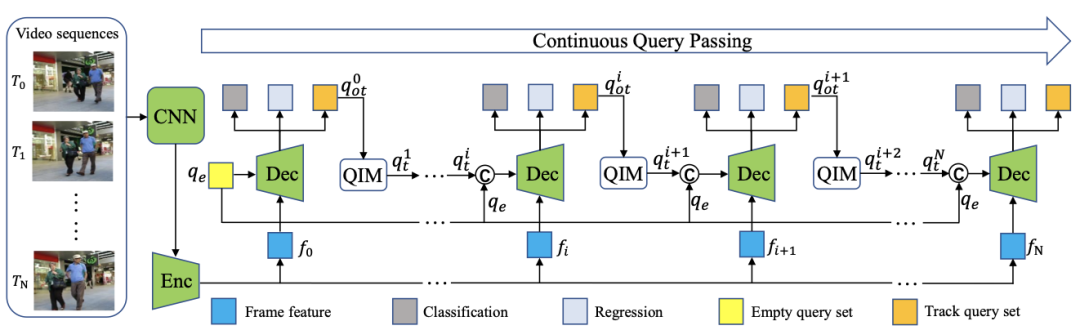
utilize TRansformer End to end target detection and tracking ( With source code )
边栏推荐
- 图嵌入Graph embedding学习笔记
- 多分支结构
- 【数字IC验证快速入门】1、浅谈数字IC验证,了解专栏内容,明确学习目标
- [C language] merge sort
- [quick start of Digital IC Verification] 6. Quick start of questasim (taking the design and verification of full adder as an example)
- 怎么挑选好的外盘平台,安全正规的?
- 秋招字节面试官问你还有什么问题?其实你已经踩雷了
- 线程池参数及合理设置
- Leetcode skimming: binary tree 12 (all paths of binary tree)
- sun. misc. Base64encoder error reporting solution [easy to understand]
猜你喜欢
.Net分布式事务及落地解决方案
【数字IC验证快速入门】3、数字IC设计全流程介绍

浅浅的谈一下ThreadLocalInsecureRandom
Leetcode skimming: binary tree 10 (number of nodes of a complete binary tree)
Android interview classic, 2022 Android interview written examination summary

Leetcode brush question: binary tree 14 (sum of left leaves)
How to select the Block Editor? Impression notes verse, notation, flowus
. Net distributed transaction and landing solution
无卷积骨干网络:金字塔Transformer,提升目标检测/分割等任务精度(附源代码)...

14. Users, groups, and permissions (14)

随机推荐
港股将迎“最牛十元店“,名创优品能借IPO突围?
Build your own website (16)
c——顺序结构
BZOJ 3747 POI2015 Kinoman 段树
Thread pool parameters and reasonable settings
Notes on key vocabulary in the English original of the biography of jobs (12) [chapter ten & eleven]
leetcode刷题:二叉树13(相同的树)
Codeforces Round #804 (Div. 2) - A, B, C
【c语言】归并排序
ffplay文档[通俗易懂]
解决php无法将string转换为json的办法
leetcode刷题:二叉树17(从中序与后序遍历序列构造二叉树)
Interviewer: what is the internal implementation of set data types in redis?
Zero cloud new UI design
Leetcode skimming: binary tree 12 (all paths of binary tree)
id选择器和类选择器的区别
Wildcard selector
字节跳动Dev Better技术沙龙成功举办,携手华泰分享Web研发效能提升经验
Go language learning tutorial (XV)
淺淺的談一下ThreadLocalInsecureRandom