当前位置:网站首页>云备份项目
云备份项目
2022-07-07 03:21:00 【李憨憨_】
云备份项目
文章目录
云备份的认识
自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储,节省磁盘空间。
项目实现目标
服务端程序:部署在Linux服务器上
实现针对客户端请求的业务处理:文件的上传备份,以及客户端浏览器的查看以及下载功能。并且具有热点管理功能,将非热点文件压缩存储节省磁盘空间
客户端程序:部署在Windows客户机上
实现针对客户端主机上指定的文件夹中的文件,自动进行检测判断是否需要备份,需要则上传到服务器备份
模块划分
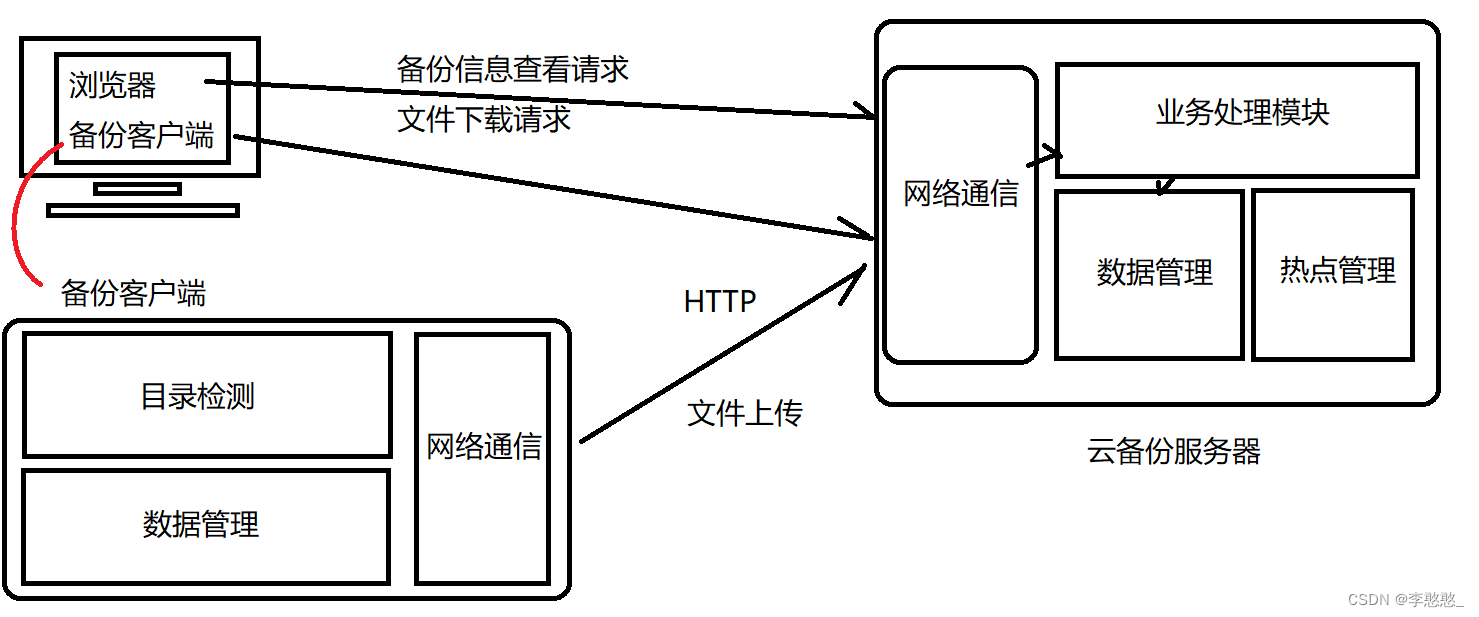
服务端:
网络通信模块:实现与客户端进行网络通信,并进行http协议数据解析
业务处理模块:明确客户端请求,并且进行对应的业务处理(上传文件,备份信息获取,文件下载)
数据管理模块:进行统一数据管理
热点管理模块:对服务器上备份的文件进行热点管理,将非热点文件进行压缩存储
在我们的服务端,首先有一个网络通信模块,这个模块可以实现与任意客户端,其中我们有两个客户端,一个是浏览器,一个是我们自己写的备份客户端,其中我们的备份客户端专门向我们的网络通信模块,也就是我们的服务器里边发送一个文件上传请求而浏览器给服务器发送的请求是备份信息查看请求以及文件下载请求。
在服务端接收到网络通信数据之后,在服务器里边有一个非常重要的模块:业务处理模块,它的功能就是,针对网络通信模块将数据接收上来,业务处理模块进行一个数据的分析,分析这个数据是一个什么样的请求,并且针对这个请求进行对应的一个业务处理。
在服务端还有一个模块,叫做数据管理模块,该模块是专门进行数据管理的网络通信模块拿到数据之后进行解析,解析完毕之后业务处理模块进行业务处理,业务处理的过程中就会涉及到对数据的访问,不能直接访问数据,而是通过数据管理模块获取到数据,对数据进行操作,不管是管理,存储,还是获取都由数据管理模块统一进行,只需要把请求发送过来就行了。
在服务端还有一个与业务处理模块并行运行是热点管理模块(服务器后台功能),专门检测服务器上边哪个文件的热度降低了,变成非热点文件了,把它压缩起来,如果业务处理模块有人要下载这个文件,先把文件解压缩之后再进行响应,毕竟它是一个非热点。
客户端:(备份客户端)
目录检测模块:遍历客户端主机上的指定文件夹,获取文件夹下所有的文件信息
数据管理模块:管理客户端所备份的所有文件信息
(判断一个文件是否需要备份:1. 历史备份信息中不存在,2. 历史备份信息存在但是不一致)
网络通信模块:搭建网络通信客户端,将需要备份的文件上传备份到服务器
第三方库认识
JSON认识
json 是一种数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据。
例如:小明同学的学生信息
char name = "小明";
int age = 18;
float score[3] = {
88.5, 99, 58};
当需要进行网络数据传输或者持久化存储的时候:需要按照指定的数据格式组织,这样才能用的时候解析出来
则json这种数据交换格式是将这多种数据对象组织成为一个字符串:
[
{
"姓名" : "小明",
"年龄" : 18,
"成绩" : [88.5, 99, 58]
},
{
"姓名" : "小黑",
"年龄" : 18,
"成绩" : [88.5, 99, 58]
}
]
json 数据类型:对象,数组,字符串,数字
对象:使用花括号 {} 括起来的表示一个对象。
数组:使用中括号 [] 括起来的表示一个数组。
字符串:使用常规双引号 “” 括起来的表示一个字符串
数字:包括整形和浮点型,直接使用。
以键值对组成
说白了就是把多个数据格式化为一个指定格式的字符串
jsoncpp库:就是提供了一系列接口用于实现JSON格式的序列化和反序列化功能的。
//Json数据对象类
class Json::Value{
Value &operator=(const Value &other); //Value重载了[]和=,因此所有的赋值和获取数据都可以通过
Value& operator[](const std::string& key);//简单的方式完成 val["姓名"] = "小明";
Value& operator[](const char* key);
Value removeMember(const char* key);//移除元素
const Value& operator[](ArrayIndex index) const; //val["成绩"][0]
Value& append(const Value& value);//添加数组元素val["成绩"].append(88);
ArrayIndex size() const;//获取数组元素个数 val["成绩"].size();
std::string asString() const;//转string string name = val["name"].asString();
const char* asCString() const;//转char* char *name = val["name"].asCString();
Int asInt() const;//转int int age = val["age"].asInt();
float asFloat() const;//转float
bool asBool() const;//转 bool
};
Json::Value类:jsoncpp库与外界进行数据交互的中间数据类
如果要将多个和数据对象进行序列化,则需要先实例化一个Json::Value对象,将数据加入其中
Json::Write类:jsoncpp库的一个序列化类
成员接口:write()接口就是用于将Json::Value对象中的所有数据组织序列化成为一个字符串。
Json::Reader类:jsoncpp库的一个反序列类
成员接口:parse()接口就是用于将一个json格式字符串,解析各个数据到Json::Value对象中
例:
这是一个序列化
#include <iostream>
#include <sstream>
#include <string>
#include <jsoncpp/json/json.h>
using namespace std;
void Serialize() {
const char *name = "小明";
int age = 18;
float score[] = {
77.5, 88, 99};
//进行序列化
//1.定义一个Json::Value对象,将数据填充进去
Json::Value val;
val["姓名"] = name;
val["年龄"] = age;
val["成绩"].append(score[0]);
val["成绩"].append(score[1]);
val["成绩"].append(score[2]);
//2.使用StreamWriter对象进行序列化
Json::StreamWriterBuilder swb;
Json::StreamWriter *sw = swb.newStreamWriter();//new一个StreamWriter对象
stringstream ss;
sw->write(val, &os);//实现序列化
cout << ss.str() << endl;
delete sw;
}
int main()
{
Serialize();
return 0;
}

接下来再看一个反序列化
void UnSerialize(string &str) {
Json::CharReaderBuilder crb;
Json::CharReader *cr = crb.newCharReader();
Json::Value val;
string err;
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &val, &err);
if (ret == false) {
cout << "UnSerialize failed:" << err << endl;
delete cr;
return ;
}
cout << val["姓名"].asString() << endl;
cout << val["性别"].asString() << endl;
cout << val["年龄"].asString() << endl;
int sz = val["成绩"].size();
for (int i = 0; i < sz; ++i) {
cout << val["成绩"][i].asFloat() << endl;
}
delete cr;
return;
}

bundle文件压缩库
BundleBundle 是一个嵌入式压缩库,支持23种压缩算法和2种存档格式。使用的时候只需要加入两个文件bundle.h 和 bundle.cpp 即可。
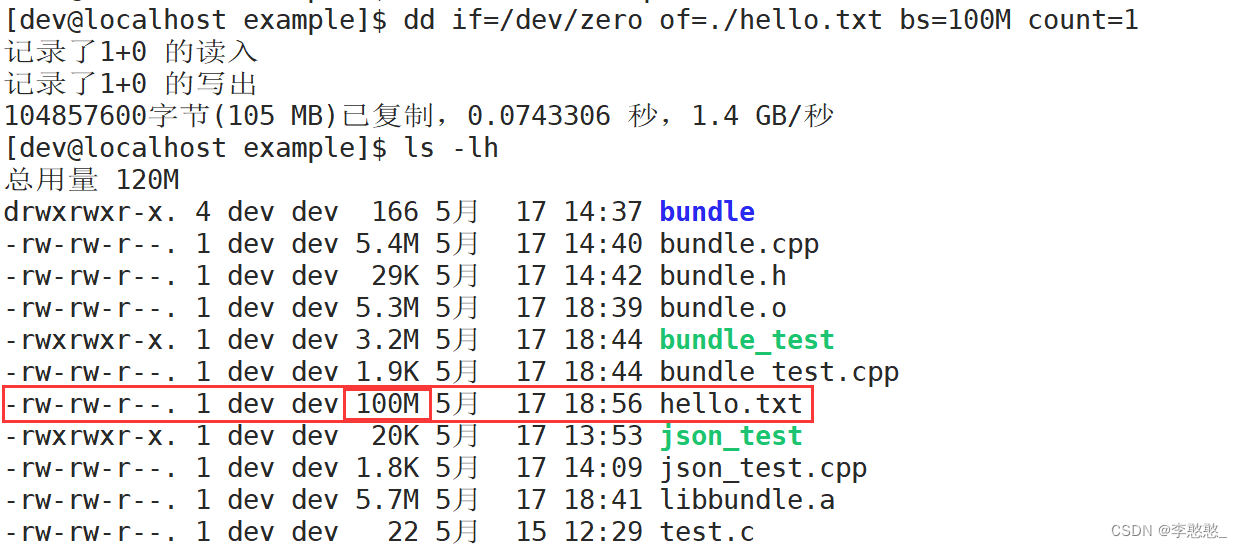
我们先创建出一个100M大小的文件
dd if=/dev/zero of=./hello.txt bs=100M count=1
#include <iostream>
#include <fstream>
#include <string>
#include "bundle.h"
using namespace std;
//读取文件所有数据
bool Read(const string &name, string *body) {
ifstream ifs;
ifs.open(name, ios::binary);//以二进制方式打开文件
if (ifs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ifs.seekg(0, ios::end);//fseek(fp, 0, SEEK_END);
size_t fsize = ifs.tellg();//获取当前位置相对于文件起始位置的偏移量
ifs.seekg(0, ios::beg);//fseek(fp, 0, SEEK_SET);
body->resize(fsize);
ifs.read(&(*body)[0], fsize);//string::c_str() 返回值 const char*
if (ifs.good() == false) {
cout << "read file failed!\n";
ifs.close();
return false;
}
ifs.close();
return true;
}
//向文件写入数据
bool Write(const string &name, const string &body) {
ofstream ofs;
ofs.open(name, ios::binary);//以二进制方式打开文件
if (ofs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ofs.write(body.c_str(), body.size());
if (ofs.good() == false) {
cout << "read file failed!\n";
ofs.close();
return false;
}
ofs.close();
return true;
}
void Compress(const string &filename, const string &packname) {
string body;
Read(filename, &body);//从filename文件中读取数据到body中
string packed = bundle::pack(bundle::LZIP, body);//对body中的数据进行lzip格式压缩,返回压缩后数据
Write(packname, packed);//将压缩后的数据写入到指定的压缩包中
}
void UnCompress(const string &filename, const string &packname) {
string packed;
Read(packname, &packed);//从压缩包中读取压缩的数据
string body = bundle::unpack(packed);//对压缩的数据进行解压缩
Write(filename, body);//将解压缩胡的数据写入到新文件中
}
int main()
{
Compress("./hello.txt", "./hello.zip");
UnCompress("./hi.txt", "./hello.zip");
return 0;
}
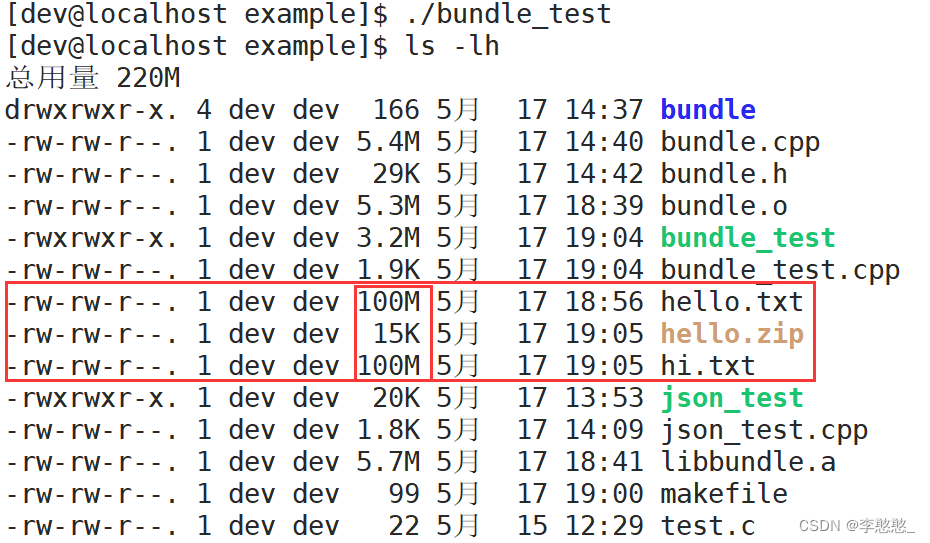
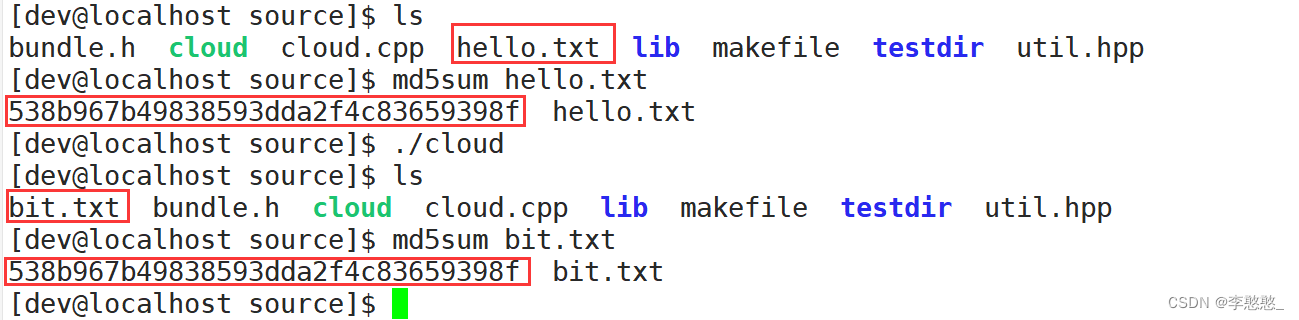
要验证两个文件内容是否一致,那就计算两个文件的MD5值,进行对比是否一致
MD5:是一种散列算法,会根据数据进行大量运算,最终得到一个最终结果(字符串),两个文件只要文件内容稍有差异,则最终得到的MD5值都是完全不一样的
很明显我们可以看出,这两个文件是一致的
httplib库
httplib 库,一个 C++11 单文件头的跨平台 HTTP/HTTPS 库。安装起来非常容易。只需包含 httplib.h 在你的代码中即可。
httplib 库实际上是用于搭建一个简单的 http 服务器或者客户端的库,这种第三方网络库,可以让我们免去搭建服务器或客户端的时间,把更多的精力投入到具体的业务处理中,提高开发效率。
http协议是一个应用层协议,在传输层基于tcp实现传输—因此http协议本质上是应用层的数据格式
http协议格式:
请求:
请求首行:请求方法URL协议版本\r\n
头部字段:key:val\r\n的键值对
空行:\r\n-用于间隔头部与正文
正文:提交给服务器的数据
响应:
响应首行:协议版本 响应状态码 状态码描述\r\n
头部字段:key: val\r\n的键值对
空行:\r\n-用于间接头部与正文
正文:响应给客户端的数据
在httplib库中,有两个数据结构,用于存放请求与响应信息:struct Request & struct Response

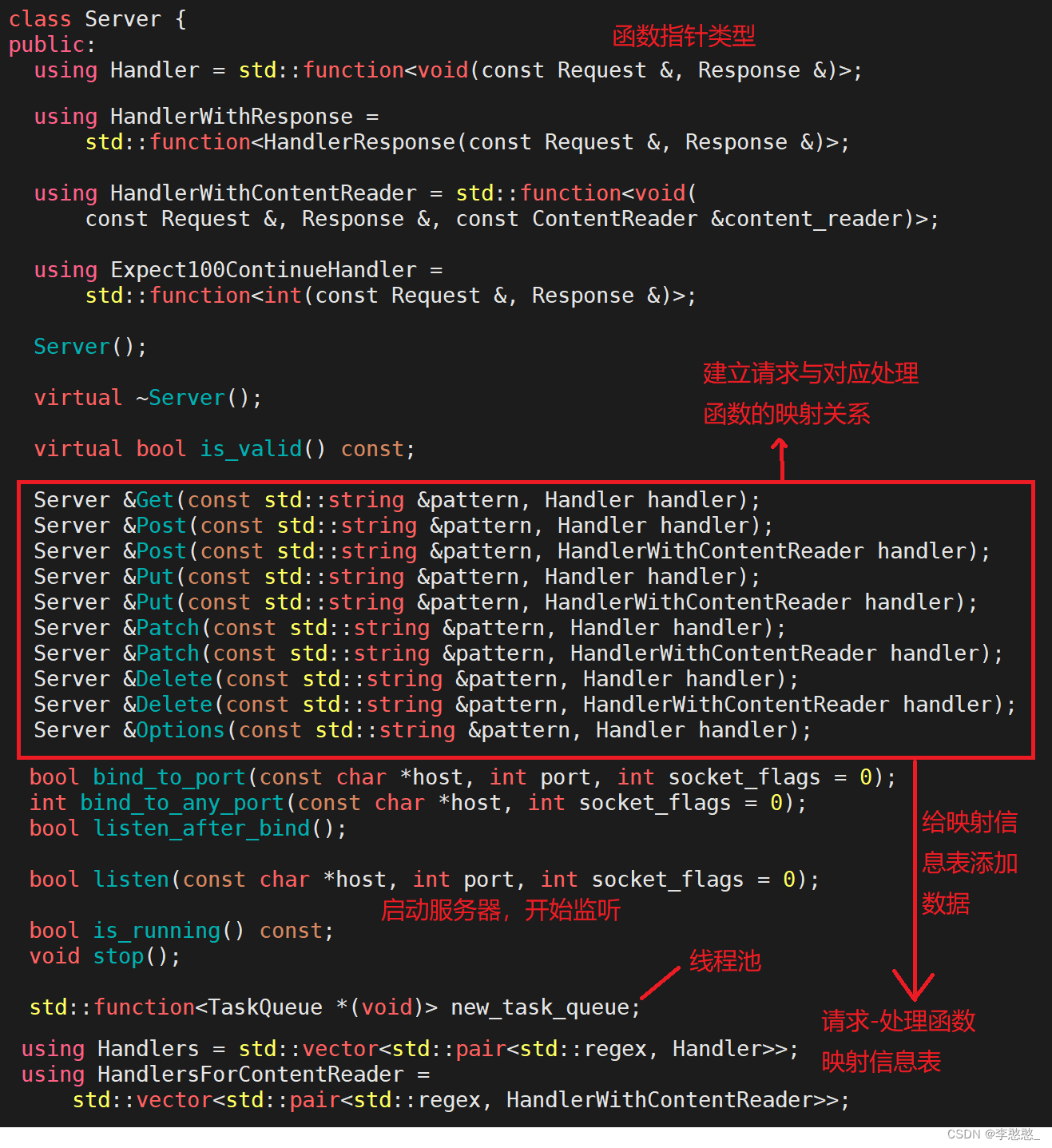
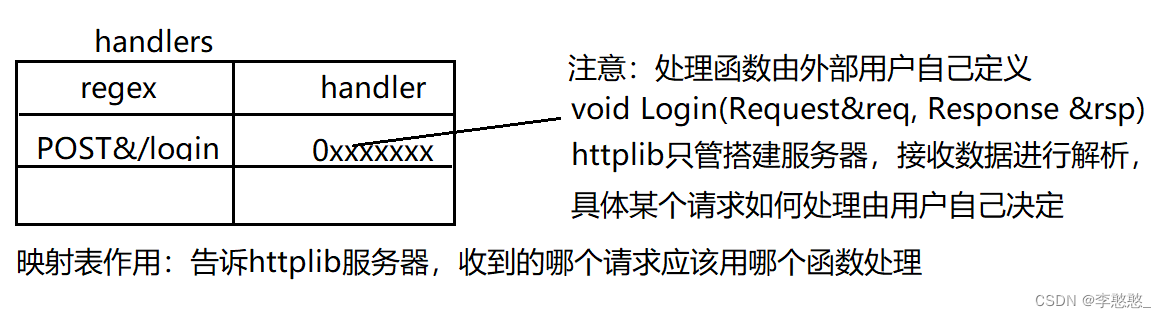
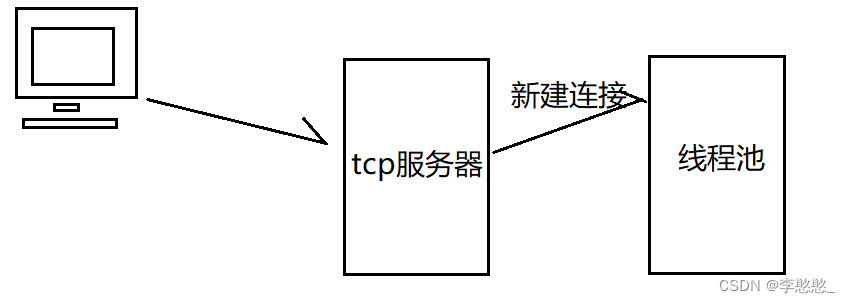
线程池中的线程获取连接进行处理:
1.接收请求数据,并进行解析,将解析得到的请求数据放到了一个Request结构体变量req中;
2.根据请求信息(请求方法&资源路径),到映射表中查找有没有对应的处理函数,如果没有则返回404;
3.如果有对应映射信息-调用业务处理函数,将解析得到的req传入接口中,并且传入一个空的Response结构体变量rsp;
4.处理函数中会根据req中的请求信息进行对应的业务处理,并且在处理过程中想rsp结构体中添加响应信息;
5.等到处理函数执行完毕,则httplib得到了一个填充了响应信息的Response变量rsp;
6.根据rsp中的信息,组织一个http格式的响应,发送给客户端;
7.如果是短连接则关闭连接处理下一个,长连接则等待请求,超时则关闭处理下一个;
先看一个简单的文件上传的界面
<!--html是一个超文本标签语言,一个标签就可以理解是一个元素,一个控件-->
<html>
<body>
<!--form是一个表单域控件,当点击表单域提交按钮时,会将表单域中所有控件的数据进行组织提交-->
<!--action是本次请求的资源路径;method是请求的方法;enctype是编码类型,是数据的组织格式-->
<form action="http://192.168.122.000:9090/upload" method="post" enctype="multipart/form-data">
<div>
<input type="file" name="file"> <!--这是一个文件上传的选择框-->
</div>
<div>
<input type="submit" name="submit" value="上传"> <!--这是一个submit提交按钮-->
</div>
</form>
</body>
</html>

其数据组织格式是这样的
POST /upload HTTP/1.1
HOST: 192.168.122.130:9090
Connection: keep-alive
Content-Length: xxxxx
Content-Type: multipart/form-data; boundary=--xxxxxxxxxxxxxxxxxxxx
----xxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name='file' filename=''
选中的那个文件的文件数据
----xxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name='submit'
上传(上传按钮的value值)
----xxxxxxxxxxxxxxxxxxxxxxxxxx
httplib库搭建服务器
有了这么一个界面之后,我们就可以搭建http服务器了
#include "httplib.h"
using namespace std;
void Numbers(const httplib::Request &req, httplib::Response &rsp)
{
//这就是业务处理函数
rsp.body = req.path;
rsp.body += "-------------";
rsp.body += req.matches[1];
rsp.status = 200;
rsp.set_header("Content-Type", "text/plain");
}
void Upload(const httplib::Request &req, httplib::Response &rsp)
{
//req.files MultipartFormDataMap v--MultipartFormData{name, filename, content, content_type}
for (auto &v : req.files) {
cout << v.second.name << endl; //区域字段标识名
cout << v.second.filename << endl;//如果是文件上传则保存文件名称
cout << v.second.content << endl;//区域正文数据,如果是文件上传则是文件内容数据
}
}
int main()
{
//实例化server对象
httplib::Server server;
//添加映射关系--告诉服务器什么请求用哪个函数处理
//因为数字没法确定固定数据,因此实际上人家用的是正则表达式--匹配符合制定规则的数据
//正则表达式中 \d 表示一个数字字符;+表示匹配前边的字符一次或多次;()表示单独捕捉括号内规则的数据
server.Get("/numbers/(\\d+)", Numbers);
server.Post("/upload", Upload);
//0.0.0.0表示服务器任意地址;虚拟机需要关闭防火墙;云服务器需要设置安全组开通端口
server.listen("0.0.0.0", 9090);
return 0;
}
我们可以把action中的资源路径改成我们自己的虚拟机或者云服务器地址,然后当我们点击选择,选择我们刚写的HTML文件,然后点击上传,就可以看到一下结果
httplib库搭建客户端
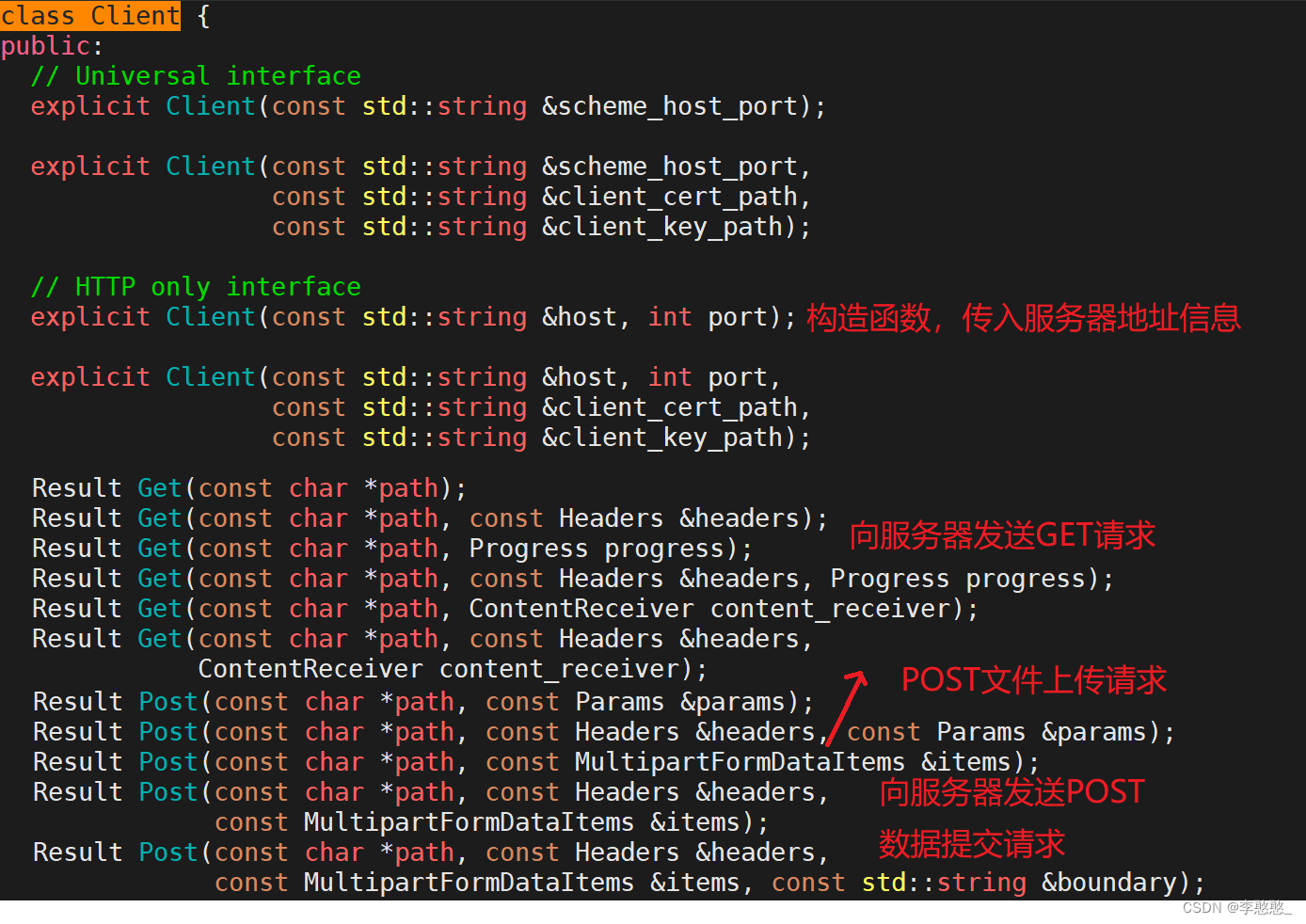
#include "httplib.h"
using namespace std;
int main()
{
httplib::Client client("192.168.19.xxx", 9090);
//Result Get(const char *path, const Headers &headers);
httplib::Headers header = {
{
"connection", "close"}
};
//Response *res
auto res = client.Get("/numbers/5678", header);
if (res && res->status == 200) {
cout << res->body << endl;
}
//Result Post(const char *path, const MultiparFormDataItems &items);
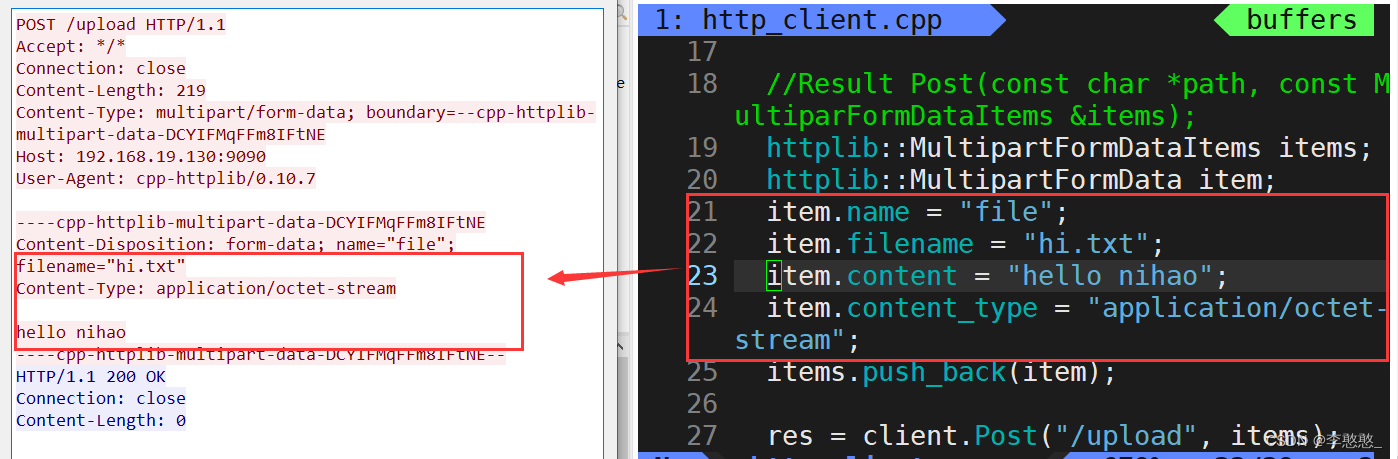
httplib::MultipartFormDataItems items;
httplib::MultipartFormData item;
item.name = "file";
item.filename = "hi.txt";
item.content = "hello nihao";
item.content_type = "application/octet-stream";
items.push_back(item);
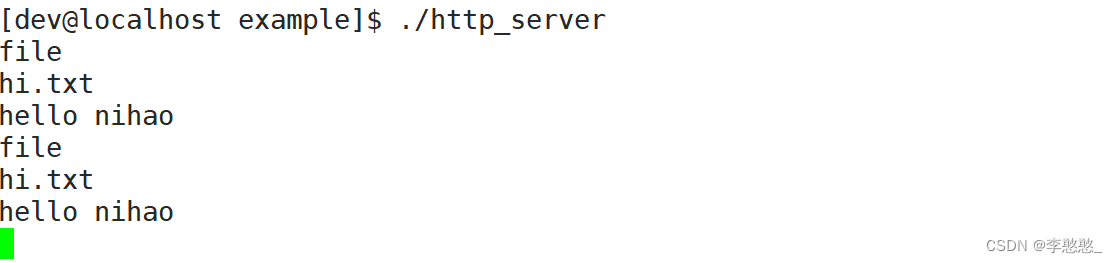
res = client.Post("/upload", items);
return 0;
}

项目实现
云备份服务端实现
网络通信模块:通过httplib搭建http客户端与服务器实现网络通信
业务处理模块:针对客户端请求进行处理(上传,下载,展示界面)
数据管理模块:统一数据管理
热点管理模块:找出备份文件中的非热点文件,进行压缩存储
一个文件如果是非热点文件,我们会进行压缩存储,但是不管是否压缩,当别人获取展示界面的时候,我们都需要给出上传的文件信息,并且当客户端要下载文件的时候,也能找到对应的压缩包,进行解压后,返回源文件数据(不能是压缩包)
数据管理模块
数据管理模块:统一数据管理
到底要管理什么数据:原文件名,原文件大小,原文件时间属性,对应的压缩包名称,压缩标志
上传的文件,最终是要能够在浏览器上进行查看并下载的,而浏览器界面上我们需要能够展示客户端曾经备份过的文件:原文件名,文件大小,文件备份时间
而一个非热点文件,如果被压缩了,获取到的大小就是压缩包大小,时间是压缩包的时间,然而页面上应该展示的是原文件的各项属性,而不是压缩包的属性
一个文件一旦压缩了,压缩包会被存放到压缩包路径下,原文件就会被删除
一个压缩包被解压缩,就应该把解压后的文件放到备份路径,压缩包应该被删除
要管理的数据信息已经确定了,问题是到底如何管理?
数据的管理分为两部分:
一部分是内存中的数据管理:查询效率更高—undered_mep(hash)
一部分是持久化磁盘存储管理:防止数据断电丢失—文件存储(json序列化&反序列化)—也可用数据库存储
数据存放到内存是为了查询效率;放到磁盘存储是为了安全;
先不急着完成数据管理模块:
首先是完成一些工具接口
文件操作工具类:
文件操作:文件的属性获取(时间,大小,……),文件写入数据,从文件读取数据
目录操作:创建目录,遍历目录(获取目录下的所有文件信息)
JSON操作工具类:
实现Json序列化&Json反序列化
第三个工具类:文件的压缩与解压缩(应用在热点管理模块)
本质上还是文件的操作,因此简化操作,将功能实现直接放到文件工具类中实现
文件操作工具类
util.hpp
#ifndef __MY_UTIL__
#define __MY_UTIL__
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <time.h>
#include <sys/stat.h>
#include <experimental/filesystem>
namespace fs = std::experimental::filesystem;
using namespace std;
namespace cloud{
class FileUtil{
private:
string _name;
public:
FileUtil(const string &name): _name(name){
}
//文件是否存在
bool Exists() {
return fs::exists(_name);
}
//获取文件大小
size_t Size() {
if (this->Exists() == false) {
return 0;
}
return fs::file_size(_name);
}
//最后一次修改时间
time_t MTime() {
if (this->Exists() == false) {
return 0;
}
auto ftime = fs::last_write_time(_name);
time_t cftime = decltype(ftime)::clock::to_time_t(ftime);
return cftime;
}
//最后一次访问时间
time_t ATime() {
if (this->Exists() == false) {
return 0;
}
struct stat st;
stat(_name.c_str(), &st);
return st.st_atime;
}
//读取文件所有数据到body中
bool Read(string *body) {
if (this->Exists() == false) {
return false;
}
ifstream ifs;
ifs.open(_name, ios::binary);//以二进制方式打开文件
if (ifs.is_open() == false) {
cout << "open failed!\n";
return false;
}
size_t fsize = this->Size();
body->resize(fsize);
ifs.read(&(*body)[0], fsize);//string::c_str() 返回值 const char*
if (ifs.good() == false) {
cout << "read file failed!\n";
ifs.close();
return false;
}
ifs.close();
return true;
}
//将body中的数据写入文件
bool Writer(const string &body) {
ofstream ofs;
ofs.open(_name, ios::binary);//以二进制方式打开文件
if (ofs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ofs.write(body.c_str(), body.size());
if (ofs.good() == false) {
cout << "read file failed!\n";
ofs.close();
return false;
}
ofs.close();
return true;
}
//创建目录
bool CreateDirectory() {
if (this->Exists()) {
return true;
}
fs::create_directories(_name);
return true;
}
//遍历目录,获取目录下的所有文件路径名
bool ScanDirectory(vector<string> *array) {
if (this->Exists() == false) {
return false;
}
//目录迭代器当前默认只能遍历深度为一层的目录
for(auto &a : fs::directory_iterator(_name)) {
if(fs::is_directory(a) == true) {
continue;//如果当前文件是一个文件夹,则不处理,遍历下一个
}
//当前我们的目录遍历中,只获取普通文件信息,针对目录不做深度处理
//string pathname = fs::path(a).filename().string();//纯文件名
string pathname = fs::path(a).relative_path().string();//带有路径的文件名
array->push_back(pathname);
}
}
};
}
#endif
cloud.cpp
#include "util.hpp"
void FileUtilTest()
{
//cloud::FileUtil("./testdir/adir").CreateDirectory();
//cloud::FileUtil("./testdir/a.txt").Writer("hello bit\n");
//string body;
//cloud::FileUtil("./testdir/a.txt").Read(&body);
//cout << body << endl;
//cout << cloud::FileUtil("./testdir/a.txt").Size() << endl;
//cout << cloud::FileUtil("./testdir/a.txt").MTime() << endl;
//cout << cloud::FileUtil("./testdir/a.txt").ATime() << endl;
vector<string> array;
cloud::FileUtil("./testdir").ScanDirectory(&array);
for(auto& a : array) {
cout << a << endl;
}
}
创建文件,向文件中写入数据,包括文件大小,修改时间,访问时间等都没有问题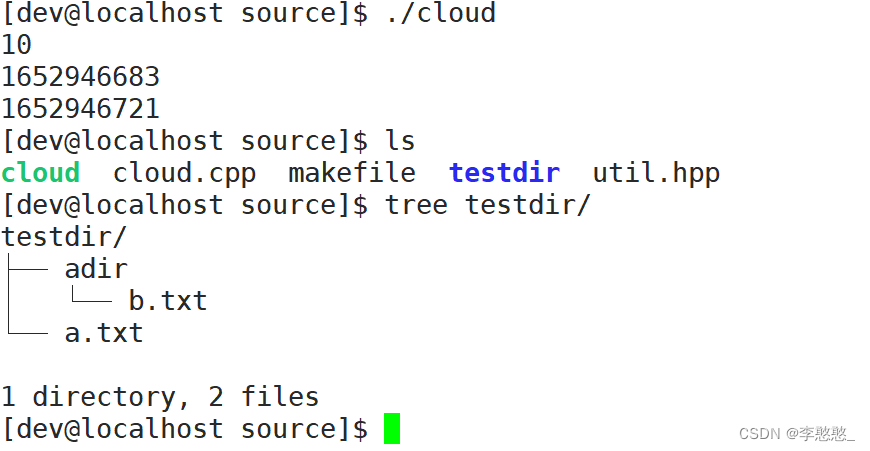
Json操作工具类
class JsonUtil{
public:
//序列化
static bool Serialize(Json::Value &val, string *body) {
Json::StreamWriterBuilder swb;
Json::StreamWriter *sw = swb.newStreamWriter(); //new一个StreamWriter对象
stringstream ss;
int ret = sw->write(val, &ss);//实现序列化
if (ret != 0) {
cout << "seriallize failed!\n";
delete sw;
return false;
}
*body = ss.str();
delete sw;
return true;
}
//反序列化
static bool UnSerialize(string &body, Json::Value *val) {
Json::CharReaderBuilder crb;
Json::CharReader *cr = crb.newCharReader();
string err;
//pars(字符串首地址,字符串末尾地址,Json::Value对象指针,错误信息获取)
bool ret = cr->parse(body.c_str(), body.c_str() + body.size(), val, &err);
if (ret == false) {
cout << "UnSerialize failed:" << err << endl;
delete cr;
return false;
}
delete cr;
return true;
}
};
void JsonTest()
{
Json::Value val;
val["姓名"] = "小明";
val["性别"] = "男";
val["年龄"] = 18;
val["成绩"].append(77.5);
val["成绩"].append(78.5);
val["成绩"].append(79.5);
string body;
cloud::JsonUtil::Serialize(val, &body);
cout << body << endl;
Json::Value root;
cloud::JsonUtil::UnSerialize(body, &root);
cout << root["姓名"].asString() << endl;
cout << root["性别"].asString() << endl;
cout << root["年龄"].asInt() << endl;
cout << root["成绩"][0].asFloat() << endl;
cout << root["成绩"][1].asFloat() << endl;
cout << root["成绩"][2].asFloat() << endl;
}
序列化与反序列化同样没有问题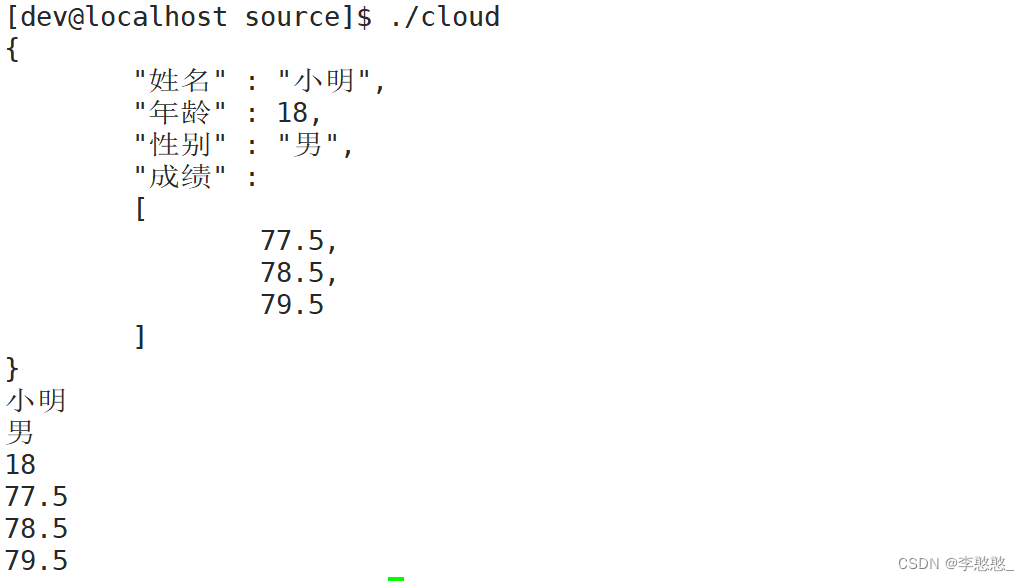
文件的压缩与解压缩
//文件压缩
bool Compress(const string &packname) {
if (this->Exists() == false) {
return false;
}
string body;
if (this->Read(&body) == false) {
cout << "Compress read failed!\n";
}
string packed = bundle::pack(bundle::LZIP, body);
if (FileUtil(packname).Writer(packed) == false) {
cout << "Compress write pack data failed!\n";
return false;
}
fs::remove_all(_name);//压缩后删除原文件
return true;
}
//文件解压缩
bool UnCompress(const string &filename) {
if (this->Exists() == false) {
return false;
}
string body;
if (this->Read(&body) == false) {
cout << "UnCompress read pack data failed!\n";
}
string unpack_data = bundle::unpack(body);
if (FileUtil(filename).Writer(unpack_data) == false) {
cout << "UnCompress write file data failed!\n";
return false;
}
fs::remove_all(_name);//解压后删除压缩包
return true;
}
void CompressTest()
{
cloud::FileUtil("./hello.txt").Compress("hello.zip");
cloud::FileUtil("./hello.zip").UnCompress("bit.txt");
}
数据管理模块的实现:
思想:
1. 文件信息通过结构体来保存
2. 多个文件信息,通过hash表组织管理
3. 持久化存储,通过文件完成,文件存储格式Json序列化格式
数据操作
数据的增删改查 :
增:输入一个文件名,在接口中获取各项信息,生成压缩包名称,填充结构体,压入hash表
改:当文件压缩存储了,要修改压缩标志,下载解压后也要修改压缩标志
查:查询所有备份信息(前端展示界面需要-文件名,下载链接,大小,备份时间),查询单个文件信息(文件下载-获取文件时机备份路径)
删:基本备份的文件都不删除(防备功能扩展)
头文件及结构体
#ifndef __MY_DATA__
#define __MY_DATA__
#include "util.hpp"
#include <iostream>
#include <unordered_map>
#include <jsoncpp/json/json.h>
using namespace std;
namespace cloud {
typedef struct _FileInfo {
string filename; //文件名
string url_path; //下载链接路径
string real_path; //实际存储路径
size_t file_size; //文件大小
time_t back_time; //备份时间
bool pack_flag; //压缩标志
string pack_path; //压缩包路径名
}FileInfo;
数据管理类:
私有数据成员
class DataManager {
private:
string _back_dir = "./backup_dir/";//备份文件的实际存储路径
string _pack_dir = "./pack_dir/";//压缩包存储路径
string _download_prefix = "/download/";//下载链接的前缀路径
string _pack_subfix = ".zip";//压缩包后缀名
string _back_info_file = "./backup.dat";//存储备份信息的文件
//用url作为key,是因为当前下载文件时,就会发送过来url
unordered_map<string, FileInfo> _back_info;//<url, fileinfo>备份信息
构造函数
public:
DataManager() {
FileUtil(_back_dir).CreateDirectory();
FileUtil(_pack_dir).CreateDirectory();
if (FileUtil(_back_info_file).Exists()) {
InitLoad();
}
}
数据存储
bool Storage() {
Json::Value infos;
vector<FileInfo> arry;
this->SelectAll(&arry);
for (auto& a : arry) {
Json::Value info;
info["filename"] = a.filename;
info["url_path"] = a.url_path;
info["real_path"] = a.real_path;
info["file_size"] = (Json::UInt64)a.file_size;
info["back_time"] = (Json::UInt64)a.back_time;
info["pack_flag"] = a.pack_flag;
info["pack_path"] = a.pack_path;
infos.append(info);
}
string body;
JsonUtil::Serialize(infos, &body);
FileUtil(_back_info_file).Writer(body);
return true;
}
当模块运行起来后,第一时间将历史信息读取出来存储到hash表中
//当模块运行起来后,第一时间将历史信息读取出来存储到hash表中
bool InitLoad() {
//1.读取文件中的历史备份信息
string body;
bool ret = FileUtil(_back_info_file).Read(&body);
if (ret == false) {
cout << "load history failed!\n";
return false;
}
//2.对读取的信息进行反序列化
Json::Value infos;
ret = JsonUtil::UnSerialize(body, &infos);
if (ret == false) {
cout << "initload parse history falied!\n";
return false;
}
//3.将反序列化得到的数据存储到hash表中
int sz = infos.size();
for (int i = 0; i < sz; ++i) {
FileInfo info;
info.filename = infos[i]["filename"].asString();
info.url_path = infos[i]["url_path"].asString();
info.real_path = infos[i]["real_path"].asString();
info.file_size = infos[i]["file_size"].asInt64();
info.back_time = infos[i]["back_time"].asInt64();
info.pack_flag = infos[i]["pack_flag"].asBool();
info.pack_path = infos[i]["pack_path"].asString();
_back_info[info.url_path] = info;
}
return true;
}
数据的增删改查
增:输入一个文件名,在接口中获取各项信息,生成压缩包名称,填充结构体,压入hash表
bool Insert(const string& pathname) {
if (cloud::FileUtil(pathname).Exists() == false) {
cout << "insert file is not exists!\n";
return false;
}
// pathname = ./backup_dir/a.txt
FileInfo info;
info.filename = cloud::FileUtil(pathname).Name();//a.txt
info.url_path = _download_prefix + info.filename;// /download/a.txt 下载链接的资源路径
info.real_path = pathname; //实际存储路径 ./backup_dir/a.txt
info.file_size = cloud::FileUtil(pathname).Size(); //文件大小
info.back_time = cloud::FileUtil(pathname).MTime();//最后一次修改时间就是备份时间
info.pack_flag = false;//刚上传的文件都是非压缩状态
info.pack_path = _pack_dir + info.filename + _pack_subfix;//压缩包路径名 /.pack_dir/a.txt.zip
_back_info[info.url_path] = info;//以url_path为key,info为value添加到map中;
Storage();
return true;
}
改:当文件压缩存储了,要修改压缩标志,下载解压后也要修改压缩标志
bool UpdateStatus(const string& pathname, bool status) {
string url_path = _download_prefix + FileUtil(pathname).Name();
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
it->second.pack_flag = status;
return true;
}
查:查询所有备份信息(前端展示界面需要-文件名,下载链接,大小,备份时间),
查询单个文件信息(文件下载-获取文件时机备份路径)
bool SelectAll(vector<FileInfo>* infos) {
for (auto it = _back_info.begin(); it != _back_info.end(); ++it) {
infos->push_back(it->second);
}
return true;
}
bool SelectOne(const string& url_path, FileInfo* info) {
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
*info = it->second;
return true;
}
删:基本备份的文件都不删除(防备功能扩展)
bool DeleteOne(const string& url_path) {
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
_back_info.erase(it);
Storage();
return true;
}
热点管理模块
对非热点文件进行压缩存储,节省服务器磁盘空间。
功能:对备份目录下的文件,进行检测,检测每一个文件最近一次访问时间,判断距离当前系统时间是否已经超过了热点判断时间(30秒无访问),如果超过了就表示这是一个非热点文件,则需要压缩存储,压缩之后删除原文件,压缩成功之后,通过数据管理对象,修改备份信息–状态为已压缩。
实现:
1. 遍历指定目录-文件备份目录-原文件存储路径,获取目录下所有文件的实际路径名
2. 遍历所有文件名,通过文件路径名,获取文件的时间属性(最后一次访问时间)
3. 获取系统当前时间,与文件最后一次访问时间进行相减,将差值与指定的热点判断时间长度进行比较
4. 若超过热点判断时长,则判定为非热点,进行压缩存储
5. 压缩完毕后,修改备份信息
#ifndef __MY_HOT__
#define __MY_HOT__
#include "data.hpp"
#include <unistd.h>
extern cloud::DataManager* _data;//全局数据
using namespace std;
namespace cloud {
class HotManager {
private:
time_t _hot_time = 30; //热点判断时长,应该是个可配置项,当前简化,先默认30s
string _backup_dir = "./back_dir/"; //要检测的原文件的存储路径
public:
HotManager() {
FileUtil(_backup_dir).CreateDirectory();
}
bool IsHot(const string& filename) {
time_t atime = FileUtil(filename).ATime();
time_t ctime = time(NULL);
if ((ctime - atime) > _hot_time) {
return false;
}
return true;
}
bool RunModule() {
while (1) {
//1.遍历目录
vector<string> arry;
FileUtil(_backup_dir).ScanDirectory(&arry);
//2.遍历信息
for (auto& file : arry) {
//3.获取指定文件时间属性,以当前系统时间,进行热点判断
if (IsHot(file) == true) {
continue;//热点文件暂时不处理
}
//获取当前文件的历史信息
FileInfo info;
bool ret = _data->SelectOneByRealpath(file, &info);
if (ret == false) {
//当前检测到的文件,没有历史备份信息,这可能是一个异常上传的文件,删除处理
cout << "An exception file is deleted. Delete it!\n";
FileUtil(file).Remove();
continue;//异常文件删除后,处理下一个
//对于检测到没有历史信息的文件,则新增信息,然后进行压缩存储
//_data->Insert(file);
//_data->SelectOneByRealpath(file, &info);
}
//4.非热点进行压缩存储
FileUtil(file).Compress(info.pack_path);
//5.压缩后则进行备份信息修改
info.pack_flag = true;
_data->UpdateStatus(file, true);
}
usleep(1000);//避免空目录情况下,空遍历消耗CPU资源过高
}
return true;
}
};
}
#endif
网络通信模块&业务处理模块
网络通信模块使用httplib库搭建http服务器,我们更多关注业务处理。
业务处理:上传的处理,查看页面请求的处理,下载的处理
#ifndef __MY_SERVER__
#define __MY_SERVER__
#include "data.hpp"
#include "httplib.h"
#include <sstream>
using namespace std;
extern cloud::DataManager* _data;
namespace cloud {
class Server {
private:
int _srv_port = 9090;//服务器的绑定监听端口
string _url_prefix = "/download/";
string _backup_dir = "./backup_dir/";//上传文件的备份存储路径
httplib::Server _srv;
private:
static void Upload(const httplib::Request& req, httplib::Response& rsp) {
string _backup_dir = "./backup_dir/";//上传文件的备份存储路径
//判断有没有对应标识的文件上传区域数据
if (req.has_file("file") == false) {
//判断有没有name字段值是file的标识的区域
cout << "Upload file data format error!\n";
rsp.status = 400;
return;
}
//获取解析后的区域数据
httplib::MultipartFormData data = req.get_file_value("file");
//cout << data.filename << endl;//如果是文件上传则保存文件名称
//cout << data.content << endl;//区域正文数据,如果是文件上传则是文件内容数据
//组织文件的实际存储路径名
string realpath = _backup_dir + data.filename;
//向文件中写入数据,实际上就是把文件备份起来了
if (FileUtil(realpath).Writer(data.content) == false) {
cout << "back file failed!\n";
rsp.status = 500;
return;
}
//新增备份信息
if (_data->Insert(realpath) == false) {
cout << "insert back info failed!\n";
rsp.status = 500;
return;
}
rsp.status = 200;
return;
}
static string StrTime(time_t t) {
return asctime(localtime(&t));
}
static void List(const httplib::Request& req, httplib::Response& rsp) {
//获取所有历史备份信息,并且根据这些信息组织出来一个html页面,作为响应正文
vector<FileInfo> arry;
if (_data->SelectAll(&arry) == false) {
cout << "select all back info failed!\n";
rsp.status = 500;
return;
}
stringstream ss;
ss << "<html>";
ss << "<head>";
ss << "<meta http-equiv='Content-Type' content='text/html;charset=utf-8'>";
ss << "<title>Download</title>";
ss << "</head>";
ss << "<body>";
ss << "<h1>Download</h1>";
ss << "<table>";
for (auto& a : arry) {
//组织每一行的页面标签
ss << "<tr>";
//<td><a href="/download/test.txt">test.txt</a></td>
ss << "<td><a href='" << a.url_path << "'>" << a.filename << "</a></td>";
//<td align="right"> 2021-12-29 10:10:10 </td>
ss << "<td align='right'>" << StrTime(a.back_time) << "</td>";
ss << "<td align='right'>" << a.file_size / 1024 << " KB </td>";
ss << "</tr>";
}
ss << "</table>";
ss << "</body>";
ss << "</html>";
rsp.set_content(ss.str(), "text/html");
rsp.status = 200;
return;
}
static string StrETag(const string& filename) {
//etag是一个文件的唯一标识,当文件被修改则会发生改变
//这里etag不用内容计算:文件大小-文件最后修改时间
time_t mtime = FileUtil(filename).MTime();
size_t fsize = FileUtil(filename).Size();
stringstream ss;
ss << fsize << "-" << mtime;
return ss.str();
}
static void Download(const httplib::Request& req, httplib::Response& rsp) {
FileInfo info;
if (_data->SelectOne(req.path, &info) == false) {
cout << "select one back info failed!\n";
rsp.status = 404;
return;
}
//如果文件已经被压缩了,则要先解压缩,然后再去原文件读取数据
if (info.pack_flag == true) {
FileUtil(info.pack_path).UnCompress(info.real_path);
}
if (req.has_header("If-Range")) {
//using Range = std::pair<ssize_t, ssize_t>;
//using Ranges = std::vector<Range>;
string old_etag = req.get_header_value("If-Range");
string cur_etag = StrETag(info.real_path);
if (old_etag == cur_etag) {
//文件没有改变可以断点续传
//如果我们自己处理进行字符串解析得到起始和结束位置就行
//size_t start = req.Ranges[0].first;//但是httplib已经替我们解析了
//size_t end = req.Ranges[0].second;//如果没有end数字,则表示文件末尾
//httplib会将second设置为-1,这时候从文件start位置开始读取end-start+1长度,如果end是-1,则> 是文件长度-start长度
//因为假设1000长度的文件,请求900-999,则返回包含900和999在内总共100长度的数据
//而如果请求900-,1000长度末尾位置其实就是999,直接长度减去900就可以了
//
//httplib已经替我们完成了断点续传的功能,我们只需要将文件的所有数据放到body中,
//然后设置响应状态码206,httplib检测到的响应状态码是206,就会从body中截取指定区间的数据进行 响应
FileUtil(info.real_path).Read(&rsp.body);
rsp.set_header("Content-Type", "application/octet-stream");//设置正文类型为二进制流
rsp.set_header("Accept-Ranges", "bytes");//告诉客户端我支持断点续传
//rsp.set_header("Content-Range", "bytes start-end/fsize");//httplib会自动设置
rsp.set_header("ETag", cur_etag);
rsp.status = 206;
return;
}
}
FileUtil(info.real_path).Read(&rsp.body);
rsp.set_header("Content-Type", "application/octet-stream");//设置正文类型为二进制流
rsp.set_header("Accept-Ranges", "bytes");//告诉客户端我支持断点续传
rsp.set_header("ETag", StrETag(info.real_path));
rsp.status = 200;
return;
}
public:
Server() {
FileUtil(_backup_dir).CreateDirectory();
}
bool RunModule() {
//搭建http服务器
//建立请求-处理函数映射关系
//Post(请求的资源路径,对应的业务处理回调函数);
_srv.Post("/upload", Upload);
_srv.Get("/list", List);//这是一个展示页面的请求
string regex_download_path = _url_prefix + "(.*)";
_srv.Get(regex_download_path, Download);
//启动服务器
_srv.listen("0.0.0.0", _srv_port);
return true;
}
};
}
#endif
断点续传
当下载一个文件的时候,下载到中途,因为网络或者其他原因,导致下载中断,如果第二次后边重新下载所有文件数据,效率就比较低,因为实际上之前传输的数据是不需要重新传输的,如果这次下载只是从上一次断开的位置重新下载,就可以提升很高的下载效率
实现思想:必然需要有一端能够记录自己传输的位置,也就是下载到哪里了,但是实际上服务端记录是不合适的,因为请求都是由客户端发起的,因此应该由客户端记录,实际上也就是谁需要数据,就谁记录。
客户端下载过程中,记录自己的已经下载的数据长度和位置,如果中途下载中断,在下次请求的时候,将自己所需要的指定文件的区间范围发送给服务器,服务器根据指定的区间范围返回数据即可。
但是存在一个问题:怎么保证下次下载的文件,和当前续传的文件是一致的???也就是如果续传的时候,服务器上的文件数据已经发生了改变,则续传是没有意义的!!!因此就必须有个标识,用于辨别服务器上的文件在生一次下载后有没有被修改过。没有修改过则可以断点续传,如果修改过了则不能断点续传,需要重新下载
因此断点续传,需要和上一次的下载关联起来,需要上一次下载信息的支持,比如文件唯一标识。
一个服务器是否支持断点续传,应该从第一次下载开始就告诉客户端
客户端实现
环境:Windows10/vs2017以上
因为我们的文件操作工具类用到了C++17中的文件系统库,而C++17在低版本VS中支持度不够
功能:对客户端主机上指定文件夹中的文件进行检测,哪个文件需要备份,则将其上传到服务器备份起来
思想:
1. 目录检索:遍历指定文件夹,获取所有文件路径名称
2. 获取所有文件的属性:根据属性信息判断这个文件是否需要备份
文件需要备份的条件:1.新增的文件;2.上次上传过后最近又被修改过的文件;
每次把文件的备份信息给记录起来:备份的文件路径名&文件的唯一标识,当文件被修改就会发生改变,如果根据文件路径名找不到历史备份信息,就表示这个文件是新增的,需要备份,如果找到了历史备份信息,但是唯一标识与当前的标识不同,则表示上传后修改过,需要备份;
存在一种情况:一个文件可能当前处于一个持续修改中,会造成每次检索都需要备份一次,实际处理—判断一个文件当前没有被其他进程占用,才能进行判断是否需要备份,简单处理—判断一个文件如果间隔指定时间长度都没有修改过则进行判断是否需要备份
3. 如果一个文件需要备份,则创建http客户端,上传文件
4. 上传文件完成后,添加当前文件的历史备份信息。
模块划分:
1. 数据管理模块:管理客户端的历史备份记录信息
2. 目录检索模块:获取指定文件夹中的所有文件
3. 网络通信模块:将需要备份的文件上传到服务器进行备份
#pragma once
#include "data.hpp"
#include "httplib.h"
namespace cloud {
class Client {
private:
string _backup_dir = "./backup_dir";
DataManager* _data = NULL;
string _srv_ip;
int _srv_port;
private:
string FileEtag(const string& pathname) {
size_t fsize = FileUtil(pathname).Size();
time_t mtime = FileUtil(pathname).MTime();
stringstream ss;
ss << fsize << "-" << mtime;
return ss.str();
}
bool IsNeedBackup(const string& filename) {
//需要备份:1.没有历史信息;2.有历史信息,但是被修改过(标识是否一致)
string old_etag;
if (_data->SelectOne(filename, &old_etag) == false) {
return true;//没有历史备份信息
}
string new_etag = FileEtag(filename);
time_t mtime = FileUtil(filename).MTime();
time_t ctime = time(NULL);
//防止文件处于持续修改状态,因此判断最后一次修改时间,与当前时间间隔是否超过3秒
if (new_etag != old_etag && (ctime - mtime) > 3) {
return true;//当前标识与历史标识不同,意味着文件被修改过
}
return false;
}
bool Upload(const string& filename) {
httplib::Client client(_srv_ip, _srv_port);
httplib::MultipartFormDataItems items;
httplib::MultipartFormData item;
item.name = "file";//区域名称标识
item.filename = FileUtil(filename).Name();//文件名
FileUtil(filename).Read(&item.content); //文件数据
item.content_type = "application/octet-stream";//文件数据格式---二进制流
items.push_back(item);
auto res = client.Post("/upload", items);
if (res && res->status != 200) {
return false;
}
return true;
}
public:
Client(const string srv_ip, int srv_port) :_srv_ip(srv_ip), _srv_port(srv_port) {
}
bool RunModule() {
//1.初始化:初始化数据管理对象,创建监控目录
FileUtil(_backup_dir).MCreateDirectory();
_data = new DataManager();
while (1) {
//2.创建目录,获取目录下所有文件
vector<string> arry;
FileUtil(_backup_dir).ScanDirectory(&arry);
//3.根据历史备份信息判断,当前文件是否需要备份
for (auto& a : arry) {
if (IsNeedBackup(a) == false) {
continue;
}
cout << a << "need backup!\n";
//4.如果需要则备份文件
bool ret = Upload(a);
//5.添加备份信息
_data->Insert(a);
cout << a << "backup success!\n";
}
Sleep(10);
}
}
};
}
边栏推荐
- 使用TCP/IP四层模型进行网络传输的基本流程
- ESXI挂载移动(机械)硬盘详细教程
- Exception of DB2 getting table information: caused by: com ibm. db2.jcc. am. SqlException: [jcc][t4][1065][12306][4.25.13]
- 【luogu P1971】兔兔与蛋蛋游戏(二分图博弈)
- Bus消息总线
- 2022年全国所有A级景区数据(13604条)
- Complete process of MySQL SQL
- 2018年江苏省职业院校技能大赛高职组“信息安全管理与评估”赛项任务书第一阶段答案
- AddressSanitizer 技术初体验
- Config分布式配置中心
猜你喜欢

Several index utilization of joint index ABC
LC 面试题 02.07. 链表相交 & LC142. 环形链表II

Sword finger offer high quality code

品牌·咨询标准化
From zero to one, I will teach you to build the "clip search by text" search service (2): 5 minutes to realize the prototype
LVS+Keepalived(DR模式)学习笔记
Config分布式配置中心
2018年江苏省职业院校技能大赛高职组“信息安全管理与评估”赛项任务书

Can 7-day zero foundation prove HCIA? Huawei certification system learning path sharing
Complete process of MySQL SQL
随机推荐
Under what circumstances should we consider sub database and sub table
7天零基础能考证HCIA吗?华为认证系统学习路线分享
Bus message bus
Leetcode T1165: 日志分析
Config分布式配置中心
MATLAB小技巧(29)多项式拟合 plotfit
Special behavior of main function in import statement
【mysqld】Can't create/write to file
请教一下,监听pgsql ,怎样可以监听多个schema和table
Unity3d learning notes
父组件传递给子组件:Props
剑指offer-高质量的代码
How DHCP router works
from .onnxruntime_pybind11_state import * # noqa ddddocr运行报错
Matlab tips (29) polynomial fitting plotfit
Network foundation - header, encapsulation and unpacking
Take you to brush (niuke.com) C language hundred questions (the first day)
.net 5 FluentFTP连接FTP失败问题:This operation is only allowed using a successfully authenticated context
Can 7-day zero foundation prove HCIA? Huawei certification system learning path sharing
After the promotion, sales volume and flow are both. Is it really easy to relax?