当前位置:网站首页>From zero to one, I will teach you to build the "clip search by text" search service (2): 5 minutes to realize the prototype
From zero to one, I will teach you to build the "clip search by text" search service (2): 5 minutes to realize the prototype
2022-07-07 06:51:00 【Zilliz Planet】
stay Last article in , We learned about search technology 、 Search for pictures by text , as well as CLIP The basics of the model . In this article, we will spend 5 Minute time , Carry out a hands-on practice of these basic knowledge , Quickly build a 「 Search for pictures by text 」 Search service prototype .
Notebook link
https://github.com/towhee-io/examples/blob/main/image/text_image_search/1_build_text_image_search_engine.ipynb
Here we choose “ Search cute pet ” This little example : Facing thousands of cute pets , Help users quickly find the favorite cat or repair hook in the massive pictures ~

Don't talk much , First look at 5 The finished product effect of working in minutes :
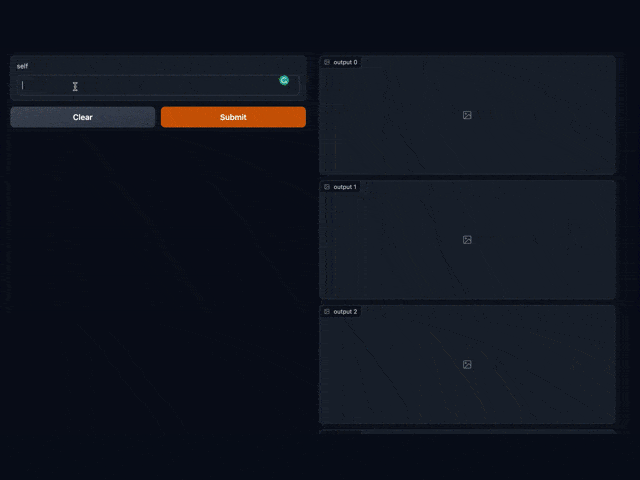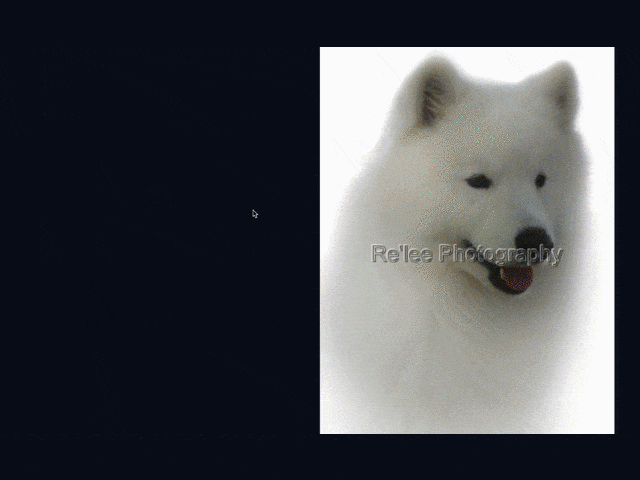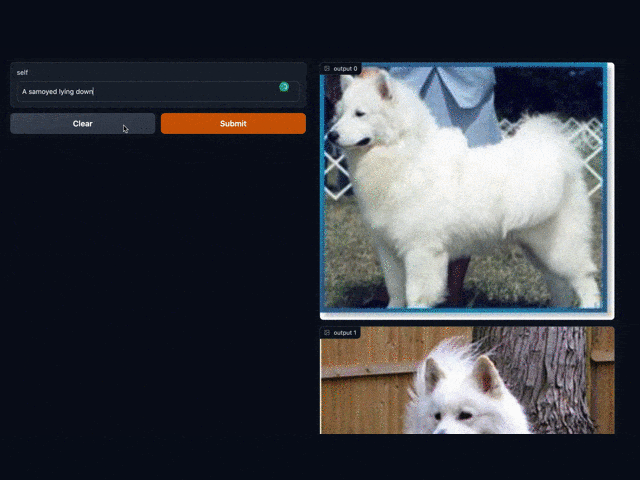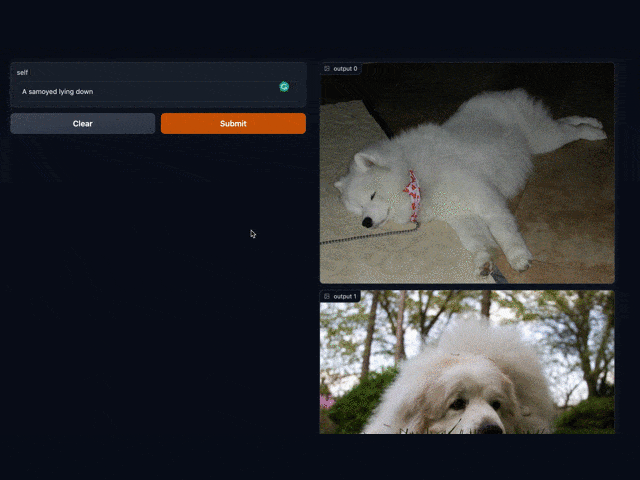
Let's see what it takes to build such a prototype :
A small picture library of pets .
A data processing pipeline that can encode the semantic features of pet pictures into vectors .
A data processing pipeline that can encode the semantic features of query text into vectors .
A vector database that can support vector nearest neighbor search .
A paragraph that can string all the above contents python Script program .
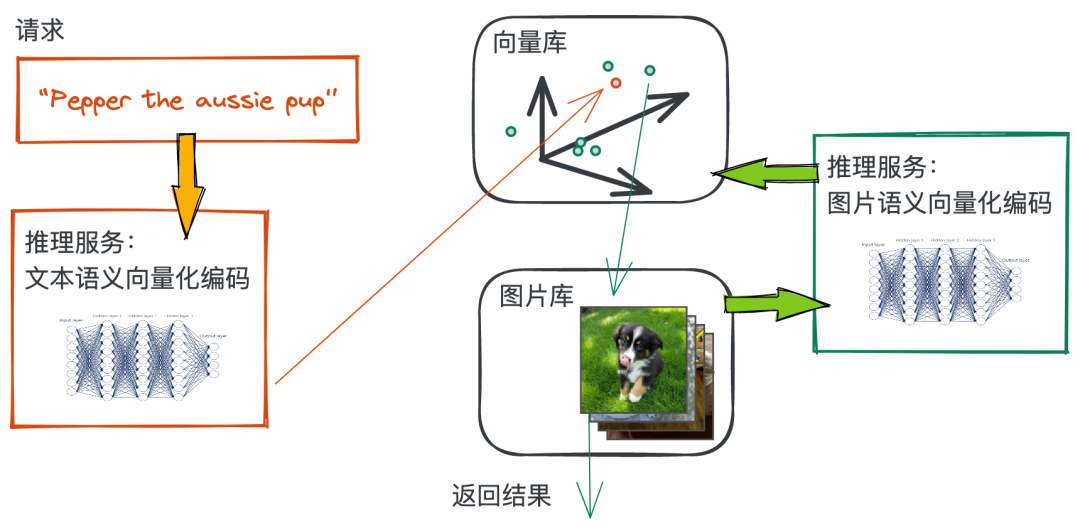
Next , We will complete the key components of this figure in succession , Get to work ~
Install the base kit
We used the following tools :
Towhee Framework for building model reasoning pipeline , Very friendly for beginners .
Faiss Efficient vector nearest neighbor search library .
Gradio Lightweight machine learning Demo Building tools .
Create a conda Environmental Science
conda create -n lovely_pet_retrieval python=3.9
conda activate lovely_pet_retrievalInstallation dependency
pip install towhee gradio
conda install -c pytorch faiss-cpuPrepare the data of the picture library
We choose ImageNet A subset of the dataset is used in this article “ Small pet picture library ”. First , Download the dataset and unzip it :
curl -L -O https://github.com/towhee-io/examples/releases/download/data/pet_small.zip
unzip -q -o pet_small.zipThe data set is organized as follows :
img: contain 2500 A picture of cats and dogs
info.csv: contain 2500 Basic information of this picture , Such as the number of the image (id)、 Image file name (file_name)、 And the category (label).
import pandas as pd
df = pd.read_csv('info.csv')
df.head()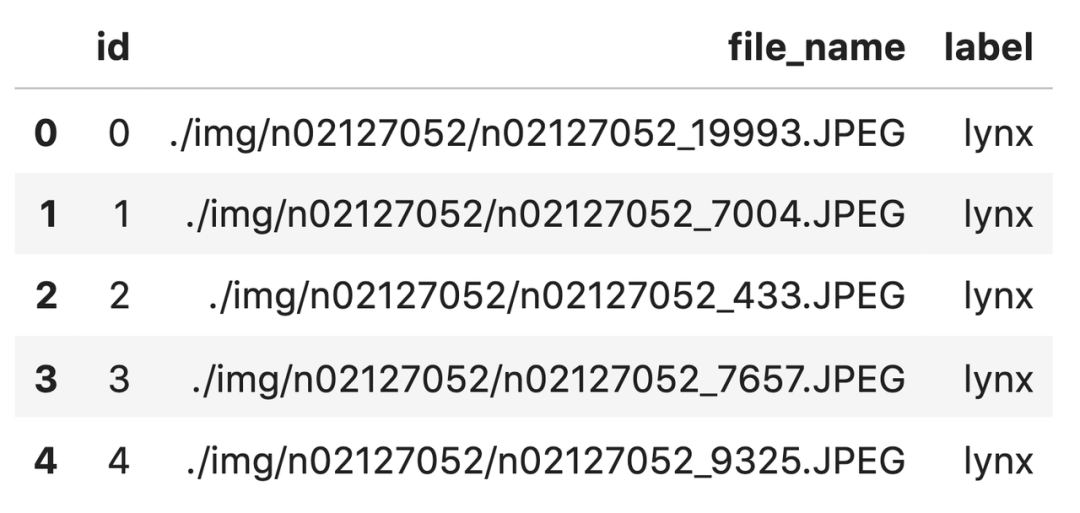
Come here , We have finished the preparation of the image library .
Encode the features of the picture into vectors
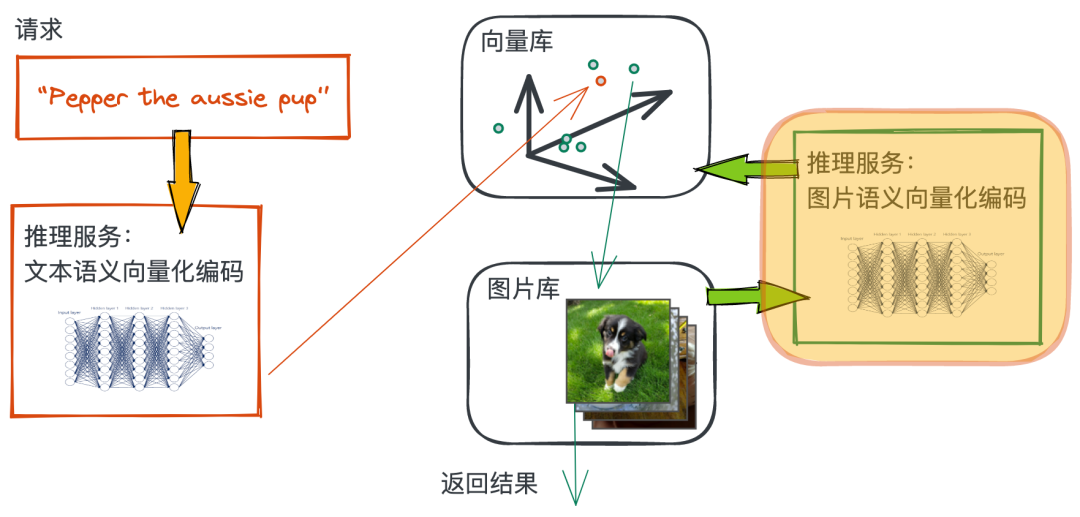
We go through Towhee call CLIP Model reasoning to generate images Embedding vector :
import towhee
img_vectors = (
towhee.read_csv('info.csv')
.image_decode['file_name', 'img']()
.image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image')
.tensor_normalize['vec','vec']() # normalize vector
.select['file_name', 'vec']()
)Here is a brief description of the code :
read_csv('info.csv')Read three columns of data to data collection, Corresponding schema by (id,file_name,label).image_decode['file_name', 'img']()Through thefile_nameRead picture file , Decode and put the picture data intoimgColumn .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32',modality='image')useclip_vit_b32takeimgThe semantic features of each image of the column are encoded into vectors , Put the vector invecColumn .tensor_normalize['vec','vec']()takevecThe vector data of the column is normalized .select['file_name', 'vec']()Choosefile_nameandvecTwo columns as the final result .
Create an index of the vector library
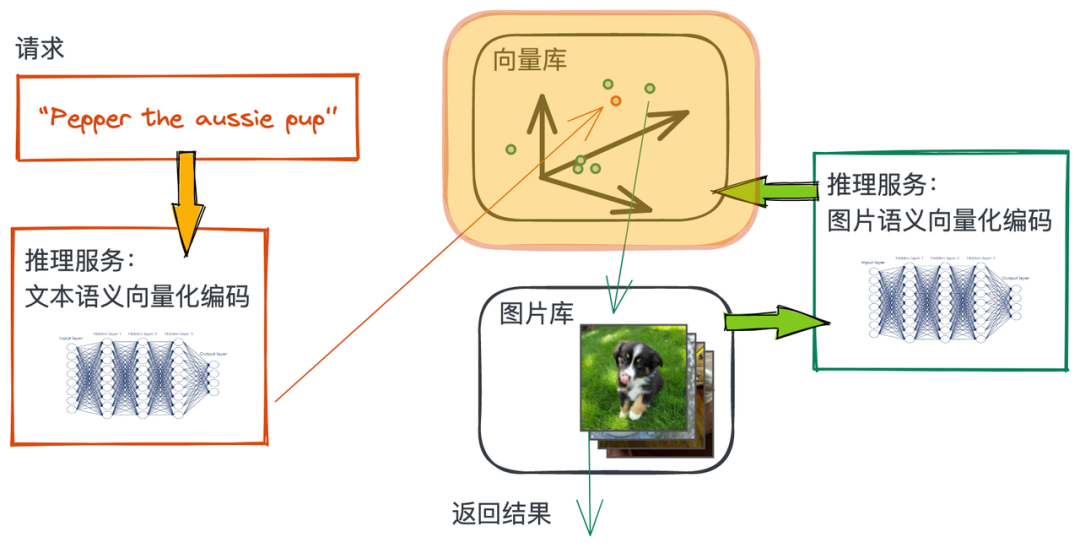
We use Faiss On images Embedding Vector building index :
img_vectors.to_faiss['file_name', 'vec'](findex='./index.bin')img_vectors Contains two columns of data , Namely file_name,vec.Faiss About the vec Column build index , And put the file_name And vec Related to . In the process of vector search ,file_name Information will be returned with the result . This step may take some time .
Vectorization of query text
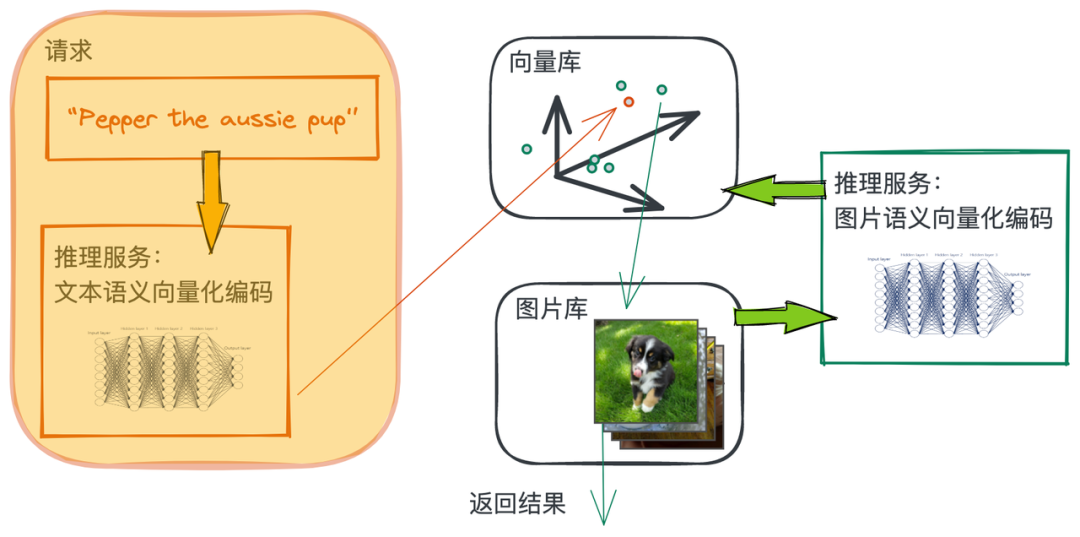
The vectorization process of query text is similar to that of image semantics :
req = (
towhee.dc['text'](['a samoyed lying down'])
.image_text_embedding.clip['text', 'vec'](model_name='clip_vit_b32', modality='text')
.tensor_normalize['vec', 'vec']()
.select['text','vec']()
)Here is a brief description of the code :
dc['text'](['a samoyed lying down'])Created a data collection, Contains one row and one column , Column name istext, The content is 'a samoyed lying down'.image_text_embedding.clip['text', 'vec'](model_name='clip_vit_b32',modality='text')useclip_vit_b32Put text 'query here' Coding into vectors , Put the vector invecColumn . Be careful , Here we use the same model (model_name='clip_vit_b32'), But text mode is selected (modality='text'). This can ensure that the semantic vectors of image and text exist in the same vector space .tensor_normalize['vec','vec']()takevecThe vector data of the column is normalized .select['vec']()Choosetext,vecColumn as the final result .
Inquire about
We first define a function to read pictures according to the query results read_images, It is used to support access to the original image after recall .
import cv2
from towhee.types import Image
def read_images(anns_results):
imgs = []
for i in anns_results:
path = i.key
imgs.append(Image(cv2.imread(path), 'BGR'))
return imgsNext is the query pipeline :
results = (
req.faiss_search['vec', 'results'](findex='./index.bin')
.runas_op['results', 'result_imgs'](func=read_images)
.select['text', 'result_imgs']()
)
results.show()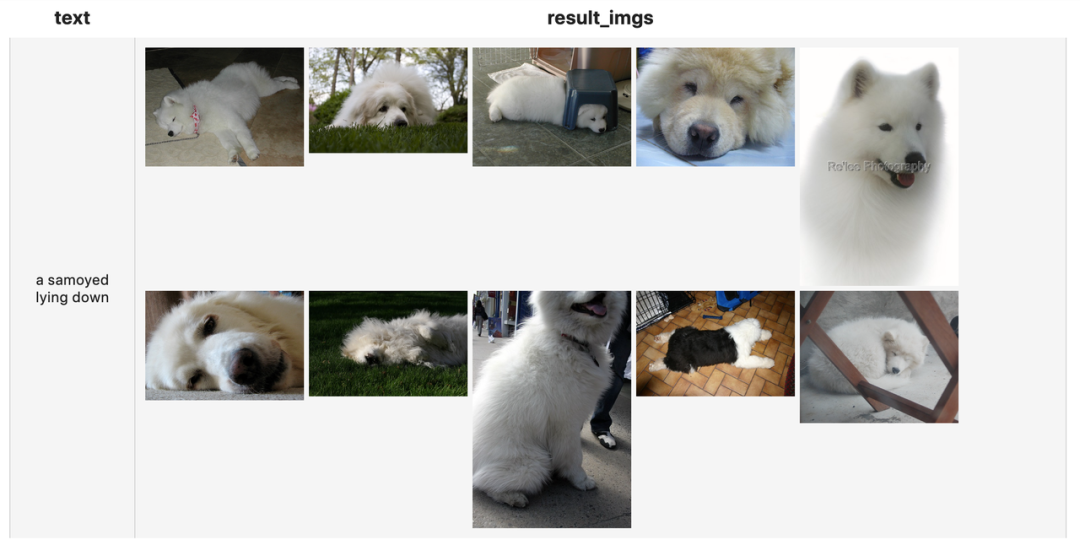
faiss_search['vec', 'results'](findex='./index.bin', k = 5)Use the text corresponding Embedding Vector index of the imageindex.binThe query , Find the one closest to the semantics of the text 5 A picture , And return to this 5 The file name corresponding to the pictureresults.runas_op['results', 'result_imgs'](func=read_images)Among them read_images Is the image reading function we define , We userunas_opConstruct this function as Towhee An operator node on the inference pipeline . This operator reads the image according to the input file name .select['text', 'result_imgs']()selectiontextandresult_imgsTwo columns as a result .
To this step , We'll finish the whole process of searching pictures with text , Next , We use Grado, Wrap the above code into a demo.
Use Gradio make demo
First , We use Towhee Organize the query process into a function :
search_function = (
towhee.dummy_input()
.image_text_embedding.clip(model_name='clip_vit_b32', modality='text')
.tensor_normalize()
.faiss_search(findex='./index.bin')
.runas_op(func=lambda results: [x.key for x in results])
.as_function()
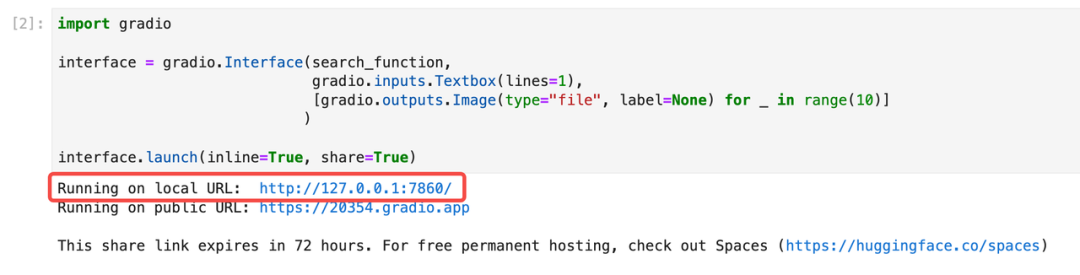
)then , Create based on Gradio establish demo Program :
import gradio
interface = gradio.Interface(search_function,
gradio.inputs.Textbox(lines=1),
[gradio.outputs.Image(type="file", label=None) for _ in range(5)]
)
interface.launch(inline=True, share=True)Gradio It provides us with a Web UI, Click on URL Visit ( Or directly with notebook Interact with the interface that appears below ):
Click on this. URL link , Will jump to us 「 Search for pictures by text 」 Interactive interface of , Enter the text you want , The picture corresponding to the text can be displayed . for example , We type in "puppy Corgi" ( Corky suckling dog ) You can get :
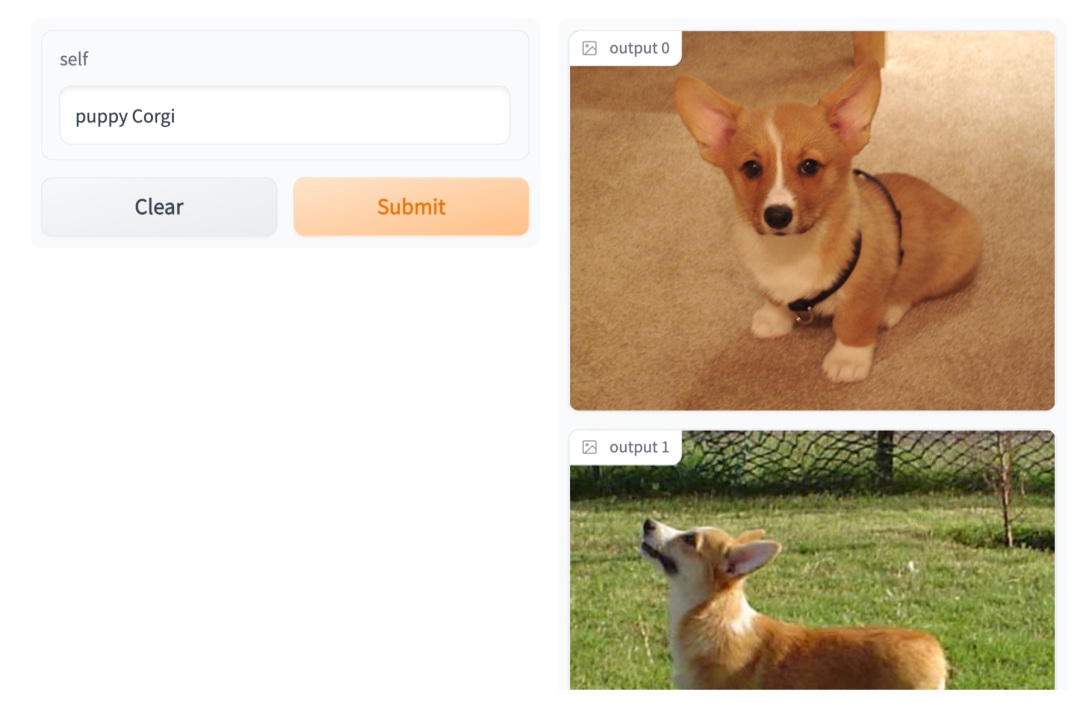
You can see CLIP The semantic coding of text and image is still very detailed , image “ Young and cute boyfriend ” Such a concept is also included in the picture and text Embedding Vector .
summary
In this article , We have built a service prototype based on text and map ( Although very small , But it has all five internal organs ), And use Gradio Created an interactive demo Program .
In today's prototype , We used 2500 A picture , And use Faiss The library indexes vectors . But in a real production environment , The data volume of the vector base is generally in the tens of millions to billions , Use only Faiss The library cannot meet the performance required by large-scale vector search 、 Extensibility 、 reliability . In the next article , We will enter the advanced content : Learn to use Milvus Vector database stores large-scale vectors 、 Indexes 、 Inquire about . Coming soon !
For more project updates and details, please pay attention to our project ( https://github.com/towhee-io/towhee ) , Your attention is a powerful driving force for us to generate electricity with love , welcome star, fork, slack Three even :)
Author's brief introduction
Yu zhuoran ,Zilliz Algorithm practice
Guo rentong , Partner and technical director
Chen Shiyu , System Engineer
Editor's profile
Xiongye , Community operation practice

边栏推荐
- 软件测试到了35岁,真的就干不动了吗?
- Abnova 体外转录 mRNA工作流程和加帽方法介绍
- sqlserver多线程查询问题
- Go straight to the 2022ecdc fluorite cloud Developer Conference: work with thousands of industries to accelerate intelligent upgrading
- Can't you really do it when you are 35 years old?
- [opencv] morphological filtering (2): open operation, morphological gradient, top hat, black hat
- 2022年全国所有A级景区数据(13604条)
- How to find the literature of a foreign language journal?
- mobx 知识点集合案例(快速入门)
- Can 7-day zero foundation prove HCIA? Huawei certification system learning path sharing
猜你喜欢
Abnova 体外转录 mRNA工作流程和加帽方法介绍

MYSQL----导入导出&视图&索引&执行计划
2018年江苏省职业院校技能大赛高职组“信息安全管理与评估”赛项任务书第一阶段答案

联合索引ABC的几种索引利用情况
Apache ab 压力测试

项目实战 五 拟合直线 获得中线
This article introduces you to the characteristics, purposes and basic function examples of static routing
Prompt for channel security on the super-v / device defender side when installing vmmare
Mysql---- import and export & View & Index & execution plan
Abnova 膜蛋白脂蛋白体技术及类别展示
随机推荐
sqlserver多线程查询问题
Installing redis and windows extension method under win system
Basic introduction of JWT
什么情况下考虑分库分表
华为机试题素数伴侣
[opencv] morphological filtering (2): open operation, morphological gradient, top hat, black hat
What books can greatly improve programming ideas and abilities?
oracle如何备份索引
LM small programmable controller software (based on CoDeSys) Note 23: conversion of relative coordinates of servo motor operation (stepping motor) to absolute coordinates
Etcd database source code analysis -- starting from the start function of raftnode
JESD204B时钟网络
from .onnxruntime_pybind11_state import * # noqa ddddocr运行报错
带你刷(牛客网)C语言百题(第一天)
MySQL的安装
2018年江苏省职业院校技能大赛高职组“信息安全管理与评估”赛项任务书
jdbc数据库连接池使用问题
unity3d学习笔记
剑指offer-高质量的代码
Basic DOS commands
Tkinter window selects PCD file and displays point cloud (open3d)