当前位置:网站首页>企業如何進行數據治理?分享數據治理4個方面的經驗總結
企業如何進行數據治理?分享數據治理4個方面的經驗總結
2022-07-07 06:35:00 【雨果的書房】
在業界,大家都在為如何做好數據治理而感到困惑。數據治理工作一定要先摸清楚數據的家底,規劃好路線圖,再進行决策。
本文從數據治理的誤區、元數據管理、數據質量管理、數據標准管理等4個方面整理出數據治理的一套經驗總結,給予數據治理相關工作的同仁們一些借鑒參考。
本文有14351個字,閱讀時長約為15分鐘。
01 數據治理有哪些誤區?
大數據時代,數據成為社會和組織的寶貴資產,像工業時代的石油和電力一樣驅動萬物,然而如果石油的雜質太多,電流的電壓不穩,數據的價值豈不是大打折扣,甚至根本不可用,不敢用,因此,數據治理是大數據時代我們用好海量數據的必然選擇。
但大家都知道,數據治理是一項長期而繁雜的工作,可以說是大數據領域中的髒活累活,很多時候數據治理廠商做了很多工作,但客戶卻認為沒有看到什麼成果。大部分數據治理諮詢項目都能交上一份讓客戶足够滿意的答卷,但是當把諮詢成果落地到實處的時候,因為種種原因,很可能是另一番截然不同的風景。如何避免這種情况發生,是每一個做數據治理的企業都值得深思的問題。
可以說在業界,大家都在為如何做好數據治理而感到困惑。
筆者涉獵大數據治理領域有6年多的時間,負責過政府、軍工、航空、大中型制造企業的數據治理項目。在實踐當中有過成功的經驗,當然也經曆過很多失敗的教訓,在這些過程中,筆者一直在思考大數據治理究竟是在治理什麼?要達到什麼樣的合理目標?中間應該怎麼避免走一些彎路?下面是筆者曾經趟過的坑,希望對大家有一些借鑒意義。
誤區一:客戶需求不明確
客戶既然請廠商來幫助自己做數據治理,必定是看到了自己的數據存在種種問題。但是做什麼,怎麼做,做多大的範圍,先做什麼後做什麼,達到什麼樣的目標,業務部門、技術部門、廠商之間如何配合做……很多客戶其實並沒有想清楚自己真正想解决的問題。數據治理,難在找到一個切入點。
以筆者的經驗來看,如果客戶暫時想不清楚需求,建議先請廠商幫助自己做一個小型的諮詢項目,通過專業的團隊,大家一起找到切入點。這個諮詢項目工作的重點應該是數據現狀的調研。通過調研數據架構、現有的數據標准和執行情况,數據質量的現狀和痛點,客戶目前已經具有的數據治理能力現狀等,來摸清楚數據的家底。
在摸清家底的基礎上,由專業的數據治理團隊幫助客戶設計切實可行的數據治理路線圖,在雙方取得一致的基礎上,按照路線圖來執行數據治理工作。
其實客戶很多時候並不是沒需求,只是需求相對比較籠統,模糊不清晰,雙方可以花費一定的時間和精力找到真正目標,磨刀不誤砍柴工,這樣才不致於後續花更多的錢來交學費。
總結:數據治理工作,一定要先摸清楚數據的家底,規劃好路線圖,切忌一上來就搭平臺。
誤區二:數據治理是技術部門的事
在大數據時代,很多組織認識到了數據的價值,也成立了專門的團隊來負責管理數據,有的叫數據管理處,有的叫大數據中心,有的叫數據應用處,名稱不一而足。這些機構往往由技術人員組成,本身的定比特也屬於技術部門,它們的共同點是:强技術,弱業務。當數據治理項目需要實施的時候,往往就是由這些技術部門來牽頭。技術部門大多是以數據中心或者大數據平臺為出發點,受限於組織範圍,不希望擴大到業務系統,只希望把自已負責的範圍管好。
但數據問題產生的原因,往往是業務>技術。可以說大部分的數據質量問題,都是來自於業務,如:數據來源渠道多,責任不明確,導致同一份數據在不同的信息系統有不同的錶述;業務需求不清晰,數據填報不規範或缺失,等等。很多錶面上的技術問題,如ETL過程中某代號變更導致數據加工出錯,影響報錶中的數據正確性等,在本質上其實還是業務管理的不規範。
筆者在與很多客戶做數據治理交流的時候,發現大部分客戶認識不到數據質量問題發生的根本原因,只想從技術維度單方面來解决數據問題,這樣的思維方式導致客戶在規劃數據治理的時候,根本沒有考慮到建立一個涵蓋技術組、業務組的强有力的組織架構,能有效執行的制度流程,導致效果大打折扣。
總結:數據治理既是技術部門的事,更是業務部門的事,一定要建立多方共同參與的組織架構和制度流程,數據治理的工作才能真正落實到人,不至於浮在錶面。
誤區三:大而全的數據治理
出於投資回報的考慮,客戶往往傾向於做一個覆蓋全業務和技術域的,大而全的數據治理項目。從數據的產生,到數據的加工,應用,銷毀,數據的整個生命周期他們希望都能管到。從業務系統,到數據中心,到數據應用,裏面的每個數據他們希望都能被納入到數據治理的範圍中來。
但殊不知廣義上的數據治理是一個很大的概念,包括很多內容,想在一個項目裏就做完通常是不可能的,而是需要分期分批地實施,所以廠商如果屈從於客戶的這種想法,很容易導致最後哪個也做不好,用不起來。所以,我們需要引導客戶,從最核心的系統,最重要的數據開始做數據治理。
怎麼引導客戶呢?這裏要引入一個眾所周知的概念:二八原則。實際上,二八原則在數據治理中同樣適用:80%的數據業務,其實是靠20%的數據在支撐;同樣的,80%的數據質量問題,其實是由那20%的系統和人產生的。在數據治理的過程中,如果能找出這20%的數據,和這20%的系統和人,毫無疑問,將會起到事半功倍的效果。
但如何說服客戶,從最重要的數據開始做起呢?這就是我們在誤區一中談到的:在沒有摸清楚數據的家底之前,切忌貿然動手開始做。通過調研,分析,找出那20%的數據和20%的系統和人,提供真實可靠的分析報告,才有可能打動客戶,讓客戶接受先從核心系統,核心數據開始做起,再漸漸覆蓋到其他領域。
總結:做數據治理,不要貪大求全,而要從核心系統,重要的數據開始做起。
誤區四:工具是萬能的
很多客戶都認為,數據治理就是花一些錢,買一些工具,認為工具就是一個過濾器,過濾器做好了,數據從中間一過,就沒問題了。結果是:一方面功能越做越多,另一方面實際上上線後,功能複雜,用戶不願意用。
其實上面的想法是一種簡單化的思維,數據治理本身包含很多的內容,組織架構、制度流程、成熟工具、現場實施和運維,這四項缺一不可,工具只是其中一部分內容。大家在做數據治理最容易忽視的就是組織架構和人員配置,但實際上所有的活動流程、制度規範都需要人來執行、落實和推動,沒有對人員的安排,後續工作很難得到保障。
一方面治理推廣工作沒人做,流程能否堅持執行得不到保障。另一方面沒有相關的數據治理培訓,導致大家對數據治理的工作不重視,認為與我無關,從而導致整個數據治理項目注定會失敗。建議大家在做數據治理的時候將組織架構放在第一比特,有組織的存在,就會有人去思考這方面的工作,怎麼去推動,持續把事情做好,以人為中心的數據治理工作,才更容易推廣落地。
有一比特國外的數據治理專家說得好,Data Governance is governance of people; Data behaves what people behave。翻譯過來就是:數據治理是對人的行為的治理。對於組織而言,無論是企業還是政府,數據治理實質上是一項覆蓋全員的、有關數據的“變革管理”,會涉及到組織架構,管理流程的變革。
當然,這是一種理想的狀態。話說回來,我們看看國內的情况,在金融業和一些大的企業,可能會建立專門的組織來負責數據治理工作,但是某些政府和中小型企業,他們出於成本的考慮,往往沒有這方面的預算。這種時候就需要折衷考慮,讓已有崗比特上的人,兼職負責數據治理的某個流程或功能。這樣會加大現有崗比特人員的工作負擔,但是不失為一種折衷的方式,重點是要責任到人。
現場的實施和運維也非常重要,盡管數據治理有向自動化的方向發展的趨勢,但是到目前為止,數據治理更多還是一種服務工作,而不僅僅是一套產品。因此,配置足够强的實施顧問和實施人員,幫助客戶逐步打造自身的數據治理能力,是一項非常重要的工作。
總結:記住,做數據治理不是去逛逛shopping mall,選幾樣得心應手的工具回來就萬事大吉了。開展好數據治理不能迷信工具,組織架構、制度流程、現場的實施和運維也非常重要,缺一不可。
誤區五:數據標准很難落地
很多客戶一說到數據治理,馬上就說我們有很多數據標准,但是這些標准卻統統沒有落地,因此,我們要先做數據標准的落地。數據標准真正落地了,數據質量自然就好了。
但這種說法其實混淆了數據標准和數據標准化。首先要明白一個道理:數據標准是一定要做的,但是數據標准化,也就是數據標准的落地,則需要分情况實施。
要做數據標准,我們首先需要全面梳理數據標准。而數據標准的全面梳理,範圍很大,包括國家標准,行業標准,組織內部的標准等等,需要花費很大的精力,甚至都可以單獨立一個項目來做。所以,首先需要讓客戶看到梳理數據標准的廣度和難度。
其次,就算是花很大精力梳理,也很難看到效果,結果往往是客戶只看到了一堆Word和Excel文檔,時間一長,誰也不會再去關心這些陳舊的文檔。這是最普遍的問題。
在金融業,或者像國家安全等一些特殊行業,數據標准的執行力度較好,而在普通企業,數據標准基本上就是一種擺設。
造成這種問題的原因有兩個:
一是大家對數據標准工作的不重視。
二是國內的企業做數據標准,動機往往不是為了做好數據治理,而是應付上級檢查,很多都是請諮詢公司,借鑒同行業企業的標准本地化修改而成,一旦諮詢公司撤離,企業本身是沒有數據標准落地的能力的。
但數據標准的落地,也就是數據標准化,其實一定要注意分情况進行,至少要分兩種情形:
一類是已經上線運行的系統,對於這部分信息系統,由於曆史原因,很難進行數據標准的落地。因為改造已有系統,除了成本以外,往往還會帶來不可估計的巨大風險。
第二類是對於新上線的系統,是完全可以要求其數據項嚴格按照數據標准落地的。
當然,數據標准是否能順利落地,還與負責數據治理的部門所獲得的權限直接相關,倘若沒有領導的授權和强力支持,你是無論如何無法推動“書同文車同軌”的,要做到這一點,請先確認你背後站著說一不二的秦始皇,或者你本身就是秦始皇。別抱怨,這就是每個做數據治理的團隊面臨的現狀。
總結:數據標准落地難是數據治理中的普遍性問題,實施過程中需要分遺留系統和新建系統,分別來執行不同的落地策略。
誤區六:數據質量問題找出來了,然後呢?
辛辛苦苦建立起來的平臺,業務和技術人員通力合作,配置好了數據質量的檢核規則,也找出來了一大堆的數據質量問題,然後呢?半年之後,一年之後,同樣的數據質量問題依舊存在。
發生這種問題的根源在於沒有形成數據質量問責的閉環。要做到數據質量問題的問責,首先需要做到數據質量問題的定責。定責的基本原則是:誰生產,誰負責。數據是從誰那裏出來的,誰負責處理數據質量問題。
這種閉環不一定非要走線上流程,但是一定要做到每一個問題都有人負責,每一個問題都必須反饋處理方案,處理的效果最好是能够形成績效評估,如通過排名的方式,來督促各責任人和責任部門處理數據質量問題。

這其實還是要追溯到我們在誤區二裏談到的:要建立組織架構和制度流程,否則數據治理工作中的種種事情,沒有人負責,沒有人去做。
總結:數據質量問題的解决,要形成每一個環節都有確定責任人的閉環機制和反饋機制。
誤區七:你們好像什麼也沒做?
很多數據治理的項目難驗收,客戶往往有疑問:你們做數據治理究竟幹了些啥?看你們匯報說幹了一大堆事情,我們怎麼什麼都看不到?發生這種情况,原因往往有前面誤區一所說的客戶需求不明確,誤區三所說的做了大而全的數據治理而難以收尾等,但還有一個原因不容忽視,那就是沒有讓客戶感知到數據治理的成果。用戶缺乏對數據治理成果的感知,導致數據治理缺乏存在感,特別是用戶方的領導决策層,自然不會痛快地對項目進行驗收。
遇到這種情况,一句“寶寶心裏苦,但寶寶不說”是無濟於事的。一個項目從銷售、售前、到組織團隊實施,多少人付出了辛勤的汗水。重要的是讓客戶認識到項目的重要價值,最終為所有人的付出買單啊。
在我看來,在數據治理的項目需求階段,就應該堅持業務價值導向,把數據治理的目的定比特在有效地對數據資產進行管理,確保其准確、可信、可感知、可理解、易獲取,為大數據應用和領導决策提供數據支撐。並且在這個過程中,一定要重視並設計數據治理的可視化呈現效果,諸如:
管理了多少元數據,是否應該用數據資產地圖漂亮地展示出來。
管理了多少數據資產,哪些來源,哪些主題,來自於什麼數據源,是否應該用數據資產門戶的方式展示出來。
數據資產用什麼方式對上層應用提供服務,這些對外服務是如何管控的,誰使用了數據,用了多少數據,是否應該用圖形化的方式進行統計和展現。
建立了多少條清洗數據的規則,清洗了多少類數據,是否應該用圖錶展示出來。
發現了多少條問題數據,處理了多少條問題數據,是否應該有一個不斷更新的統計數字來錶示。
數據質量問題逐月减少的趨勢,是否應該用趨勢圖展現出來。
數據質量問題根據部門、系統的排名,是否應該加在數據質量報告中,提供給决策層,幫助客戶進行績效考核。
數據分析、報錶等應用,因為數據問題而必須回溯來源和加工過程的次數,是否應該統計逐月下降的趨勢;之前的回溯方式,和現在通過血緣管理更清楚地定比特問題數據產生的環節,這兩者之間進行對比,節省了客戶多少時間和精力,是否應該有一個公平的評估,並提交給客戶。
用戶之前找數據平均使用的時間,現在找數據平均需要的時間,是否能通過訪談的方式得到公平的結論,提交給客戶。
……
以上這些都是提昇數據治理存在感的手段。除了這些之外,時常組織交流和培訓,引導客戶認識到數據治理的重要性,讓客戶真正認識到數據治理工作對他們業務的促進作用,逐步轉移數據治理的能力給客戶等,這些都是平時需要注意的工作。
總結:傳統的數據治理工作不重視效果的呈現,我們做數據治理工作,一定要從需求開始,就想辦法讓客戶直觀地看到成果。
在激烈的市場競爭下,大數據廠商提出來數據治理的各種理念,有的提出覆蓋數據全生命周期的數據治理,有的提出以用戶為中心的自服務化數據治理,有的提出减少人工幹預、節省成本的基於人工智能的自動化數據治理,在面對這些概念的時候,我們一方面要對數據現狀有清晰的認識,對數據治理的目標有明確的訴求,另一方面還要知道數據治理中各種常見的誤區,跨越這些陷阱,才能把數據治理工作真正落到實處,項目取得成效,做到數據更准確,數據更好取,數據更好用,真正地用數據提昇業務水平。
02 數據治理之元數據管理
從關於元數據的三個概念談起,講到元數據的分布範圍和如何獲取元數據,最後從幾個常見的應用出發,談談元數據的一些實際應用場景。
一、元數據到底是個啥?
元數據是一個相當抽象、不易理解的概念,所以第一個章節,我們先把元數據是什麼搞懂。這一章節共提出三個概念。
1、元數據(Meta Data)是描述數據的數據。
這是元數據的標准定義,但這麼說有些抽象,技術同學能聽懂,倘若聽眾缺乏相應的技術背景,可能當場就懵逼了。產生這個問題的根源其實是一個知識的詛咒:我們知道某件事情,向不了解的人描述時卻很難講清楚。

要破解這個詛咒,我們不妨借用一個比喻來描述元數據:元數據是數據的戶口本。讓我們想想一個人的戶口本是什麼,是這個人的信息登記册:上面有這個人的姓名,年齡,性別、身份證號碼,住址、原籍、何時從何地遷入等等,除了這些基本的描述信息之外,還有這個人和家人的血緣關系,比如說父子,兄妹等等。所有的這些信息加起來,構成對這個人的全面描述。那麼所有的這些信息,我們都可以稱之為這個人的元數據。
同樣的,如果我們要描述清楚一個實際的數據,以某張錶為例,我們需要知道錶名、錶別名、錶的所有者、數據存儲的物理比特置、主鍵、索引、錶中有哪些字段、這張錶與其他錶之間的關系等等。所有的這些信息加起來,就是這張錶的元數據。
這麼一類比,我們對元數據的概念可能就清楚很多了:元數據是數據的戶口本。
2、元數據管理,是數據治理的核心和基礎。
為什麼我們說元數據管理是數據治理的核心和基礎?為什麼在做數據治理的時候要先做元數據管理?它的地比特為何如此特殊?
讓我們想象一下,一比特將軍要去打仗,他必不可少,必須要掌握的信息是什麼?對,是戰場的地圖。很難相信手裏沒有軍事地圖的一比特將軍能打勝仗。而元數據就相當於是所有數據的一張地圖。
在這張關於數據的地圖中,我們可以知道:
我們有哪些數據?
數據分布在哪裏?
這些數據分別是什麼類型?
數據之間有什麼關系?
哪些數據經常被引用?哪些數據無人光顧?
……
所有的這些信息,都可以從元數據中找到。如果我們要做數據治理,但是手裏卻沒有掌握這張地圖,做數據治理就猶如是瞎子摸象。後續的文章中我們要講到的數據資產管理,知識圖譜,其實它們大部分也是建立在元數據之上的。所以我們說:元數據是一個組織內的數據地圖,它是數據治理的核心和基礎。
3、元數據是描述數據的數據,那麼有沒有描述元數據的數據?
有。描述元數據的數據叫元模型(Meta Model)。元模型、元數據、數據之間的關系,可以用下面這張圖來描述。

對於元模型的概念,我們不做深入的討論。我們只需要知道下面這些:
元數據本身的數據結構也是需要被定義和規範的,定義和規範元數據的就是元模型,國際上元模型的標准是CWM(Common Warehouse Metamodel,公共倉庫元模型),一個成熟的元數據管理工具,需要支持CWM標准。
二、元數據是從哪裏來的?
在大數據平臺中,元數據貫穿大數據平臺數據流動的全過程,主要包括數據源元數據、數據加工處理過程元數據、數據主題庫專題庫元數據、服務層元數據、應用層元數據等。下圖以一個數據中心為例,展示了元數據的分布範圍:

業內通常把元數據分為以下類型:
技術元數據:庫錶結構、字段約束、數據模型、ETL程序、SQL程序等。
業務元數據:業務指標、業務代碼、業務術語等。
管理元數據:數據所有者、數據質量定責、數據安全等級等。
元數據采集是指獲取數據生命周期中的元數據,對元數據進行組織,然後將元數據寫入數據庫中的過程。
要獲取到元數據,需要采取多種方式,在采集方式上,使用包括數據庫直連、接口、日志文件等技術手段,對結構化數據的數據字典、非結構化數據的元數據信息、業務指標、代碼、數據加工過程等元數據信息進行自動化和手動采集。
元數據采集完成後,被組織成符合CWM模型的結構,存儲在關系型數據庫中。
三、有了元數據,我們能做些什麼?
這一章節我們主要講元數據的幾個典型的應用。
先看一張元數據管理的整體功能架構圖,有了元數據,我們能做些什麼,從這張圖裏一目了然:

1.元數據查看
一般是以樹形結構組織元數據,按不同類型對元數據進行瀏覽和檢索。如我們可以瀏覽錶的結構、字段信息、數據模型、指標信息等。通過合理的權限分配,元數據查看可以大大提昇信息在組織內的共享。
2.數據血緣和影響性分析
數據血緣和影響性分析主要解决“數據之間有什麼關系”的問題。因其重要價值,有的廠商會從元數據管理中單獨提取出來,作為一個獨立的重要功能。但是筆者考慮到數據血緣和影響性分析其實是來自於元數據信息,所以還是放在元數據管理中來描述。
血緣分析指的是取到數據的血緣關系,以曆史事實的方式記錄數據的來源,處理過程等。
以某張錶的血緣關系為例,血緣分析展示如下信息:

數據血緣分析對於用戶具有重要的價值,如:當在數據分析中發現問題數據的時候,可以依賴血緣關系,追根溯源,快速地定比特到問題數據的來源和加工流程,减少分析的時間和難度。
數據血緣分析的典型應用場景:某業務人員發現“月度營銷分析”報錶數據存在質量問題,於是向IT部門提出异議,技術人員通過元數據血緣分析發現“月度營銷分析”報錶受到上遊FDM層四張不同的數據錶的影響,從而快速定比特問題的源頭,低成本地解决問題。
除了血緣分析之外,還有一種影響性分析,它能分析出數據的下遊流向。當系統進行昇級改造的時候,如果修改了數據結構、ETL程序等元數據信息,依賴數據的影響性分析,可以快速定比特出元數據修改會影響到哪些下遊系統,從而减少系統昇級改造帶來的風險。從上面的描述可以知道:數據影響性分析和血緣分析正好相反,血緣分析指向數據的上遊來源,影響性分析指向數據的下遊。
影響性分析的典型應用場景:某機構因業務系統昇級,在“FINAL_ZENT ”錶中修改了字段:TRADE_ACCORD長度由8修改為64,需要分析本次昇級對後續相關系統的影響。對元數據“FINAL_ZENT”進行影響性分析,發現對下遊DW層相關的錶和ETL程序都有影響,IT部門定比特到影響之後,及時修改下遊的相應程序和錶結構,避免了問題的發生。由此可見,數據的影響性分析有利於快速鎖定元數據變更帶來的影響,將可能發生的問題提前消滅在萌芽之中。
3.數據冷熱度分析
冷熱度分析主要是對數據錶的被使用情况進行統計,如:錶與ETL程序、錶與分析應用、錶與其他錶的關系情况等,從訪問頻次和業務需求角度出發,進行數據冷熱度分析,用圖錶的方式,展現錶的重要性指數。
數據的冷熱度分析對於用戶有巨大的價值,典型應用場景:我們觀察到某些數據資源處於長期閑置,沒有被任何應用調用,也沒有別的程序去使用的狀態,這時候,用戶就可以參考數據的冷熱度報告,結合人工分析,對冷熱度不同的數據做分層存儲,以更好地利用HDFS資源,或者評估是否對失去價值的這部分數據做下線處理,以節省數據存儲空間。
4.數據資產地圖
通過對元數據的加工,可以形成數據資產地圖等應用。數據資產地圖一般用於在宏觀層面組織信息,以全局視角對信息進行歸並、整理,展現數據量、數據變化情况、數據存儲情况、整體數據質量等信息,為數據管理部門和决策者提供參考。
5.元數據管理的其他應用
元數據管理中還有其他一些重要功能,如:
元數據變更管理。對元數據的變更曆史進行查詢,對變更前後的版本進行比對等等。
元數據對比分析。對相似的元數據進行比對。
元數據統計分析。用於統計各類元數據的數量,如各類數據的種類,數量等,方便用戶掌握元數據的匯總信息。
諸如此類的應用,限於篇幅,不一一列舉。
四、總結
元數據就相當於是數據的戶口本和地圖,是數據治理的核心和基礎。
元數據產生於從數據生產、數據接入、數據加工、數據服務到數據應用的各個環節,整體上可以分為三類:技術元數據、業務元數據和管理元數據。
元數據采集入庫後,可以產生冷熱度分析、血緣關系分析、影響性分析,數據資產地圖等應用。元數據管理可以讓數據被描述得更加清晰,更容易被理解,被追溯,更容易評估其價值和影響力。元數據管理還可以大大促進信息在組織內外的共享。
03 數據治理之數據質量管理
數據治理的理論和實踐不斷向前發展,但數據質量管理始終是數據治理的初衷,也是最重要的目的。下面從數據質量管理的目標,質量問題產生的根源,質量評估標准,質量管理流程,質量管理的取與舍幾個方面進行闡述。
一、數據質量管理的目標
數據質量管理主要解决“數據質量現狀如何,誰來改進,如何提高,怎樣考核”的問題。
最開始的關系型數據庫時代,做數據治理最主要的目的,就是為了提昇數據質量,讓報錶、分析、應用更加准確。時至今日,雖然數據治理的範疇擴大了很多,我們開始講數據資產管理、知識圖譜、自動化的數據治理等等概念,但是提昇數據的質量,依然是數據治理最重要的目標之一。
為什麼數據質量問題如此重要?
因為數據要能發揮其價值,關鍵在於其數據的質量的高低,高質量的數據是一切數據應用的基礎。
如果一個組織根據劣質的數據分析業務、進行决策,那還不如沒有數據,因為通過錯誤的數據分析出的結果往往會帶來“精確的誤導”,對於任何組織來說,這種“精確誤導”都無异於一場灾難。
根據統計,數據科學家和數據分析員每天有30%的時間浪費在了辨別數據是否是“壞數據”上,在數據質量不高的環境下,做數據分析可謂是戰戰兢兢。可見數據質量問題已經嚴重影響了組織業務的正常運營。通過科學的數據質量管理,持續地提昇數據質量,已經成為組織內刻不容緩的優先任務。
二、數據質量問題產生的根源
做數據質量管理,首先要搞清楚數據質量問題產生的原因。原因有多方面,比如在技術、管理、流程方面都會碰到。但從根本上來時,數據質量問題產生的大部分原因在於業務上,也就是管理不善。許多錶面上的技術問題,深究下去,其實還是業務問題。
筆者在給客戶做數據治理諮詢的時候,發現很多客戶認識不到數據質量問題產生的根本原因,局限於只想從技術角度來解决問題,希望通過購買某個工具就能解决質量問題,這當然達不到理想的效果。經過和客戶交流以及雙方共同分析之後,大部分組織都能認識到數據質量問題產生的真正根源,從而開始從業務著手解决數據質量問題了。
從業務角度著手解决數據質量問題,重要的是建立一套科學、可行的數據質量評估標准和管理流程。
三、數據質量評估的標准
當我們談到數據質量管理的時候,我們必須要有一個數據質量評估的標准,有了這個標准,我們才能知道如何評估數據的質量,才能把數據質量量化,並知道改進的方向,比較改進後的效果。
目前業內認可的數據質量的標准有:
“
准確性: 描述數據是否與其對應的客觀實體的特征相一致。
完整性: 描述數據是否存在缺失記錄或缺失字段。
一致性: 描述同一實體的同一屬性的值在不同的系統是否一致。
有效性: 描述數據是否滿足用戶定義的條件或在一定的域值範圍內。
唯一性: 描述數據是否存在重複記錄。
及時性: 描述數據的產生和供應是否及時。
穩定性: 描述數據的波動是否是穩定的,是否在其有效範圍內。
以上數據質量標准只是一些通用的規則,這些標准是可以根據數據的實際情况和業務要求進行擴展的,如交叉錶校驗等。
四、數據質量管理的流程
要提昇數據質量,需要以問題數據為切入點,注重問題的分析、解决、跟踪、持續優化、知識積累,形成數據質量持續提昇的閉環。
首先需要梳理和分析數據質量問題,摸清楚數據質量的現狀;然後針對不同的質量問題選擇適合的解决辦法,制定出詳細的解决方案;接著是問題的認責,追踪方案執行的效果,監督檢查,持續優化;最後形成數據質量問題解决的知識庫,以供後來者參考。上述步驟不斷迭代,形成數據質量管理的閉環。
很顯然,要管理好數據質量,僅有工具支撐是遠遠不够的,必須要組織架構、制度流程參與進來,做到數據的認責,數據的追責。
五、數據質量管理的取與舍
企業也好,政府也好,從來不是生活在真空之中,而是被社會緊緊地包裹。解决任何棘手的問題,都必須考慮到社會因素的影響,做適當的取舍。
第一個取舍:數據質量管理流程。前面講到的數據質量管理流程,是一個相對理想的狀態,但是不同的組織內部,其實施的力度都是不同的,以數據追責為例:在企業內部推行還具有一定的可行性,但是在政府就很難適用。因為政府部門的大數據項目,牽頭單比特無論是誰,很可能沒有相關的權限。
遇到這種問題,我們只能迂回地做些事情,盡量彌補某個環節缺失帶來的不利影響,比如和數據提供方一起建立起數據清洗的規則,對來源數據做清洗,盡量達到可用的標准。
第二個取舍:不同時間維度上的數據采取不同的處理方式。從時間維度上劃分,數據主要有三類:未來數據、當前數據、曆史數據。在解决不同種類的數據質量問題時,需要考慮取舍之道,采取不同的處理方式。
1.曆史數據
當你拿著一堆曆史問題數據,找信息系統的負責人給你整改,對方通常不會給你好臉色看,可能會以“當前的數據問題都處理不過來,哪有時間給你處理曆史數據的問題”為理由,拒你以千裏之外。這時候你即便是找領導協調,一般也起不到太大的作用,因為這確實是現實情况:一個組織的曆史數據通常是經年累月的積累,已經是海量的規模,很難一一處理。
那麼難道就沒有更好的辦法了嗎?——對於曆史數據問題的處理,我們可以發揮技術人員的優勢,用數據清洗的辦法來解决,對於實在清洗不了的,我們要讓决策者判斷投入和產出的效益比,結果往往是需要接受這種現狀。
從另一個角度來看:數據的新鮮度不同,其價值往往也有所區分。一般來說,曆史數據的時間越久遠,其價值越低。所以,我們不應該把最重要的資源放在曆史數據質量的提昇上,而是應該更多地著眼於當前產生和未來即將產生的數據。
2.當前數據
當前數據的問題,需要從我們通過前面第四個章節講過的梳理和發現問題,分析問題,解决問題,問題認責、跟踪和評估等幾個流程環節來解决,管理過程中必須嚴格遵循流程,避免髒數據繼續流到數據分析和應用環節。
3.未來數據
管理未來的數據,一定要從數據規劃開始,從整個組織信息化的角度出發,規劃組織統一的數據架構,制定出統一的數據標准。借業務系統新建、改造或重建的時機,在創建物理模型、建錶、ETL開發、數據服務、數據使用等各個環節遵循統一的數據標准,從根本上提昇數據質量。這也是最理想、效果最好的數據質量管理模式。
這樣,通過對不同時期數據的不同處理方式,能做到事前預防、事中監控、事後改善,從根本上解决數據質量問題。
總結
提昇數據質量,是數據治理最重要的目標之一。做數據質量管理,首先要弄清楚數據質量問題產生的根源大部分在於業務管理出了問題。
其次,我們要根據組織架構,建立一套數據質量評估的標准和數據質量管理的流程。
最後,在做數據質量管理過程中,我們要充分考慮到現狀,對曆史數據、當前數據、未來數據分別制定不同的處理策略。
04 數據治理之數據標准管理
一、大數據標准體系
根據全國信息技術標准化技術委員會大數據標准工作組制定的大數據標准體系,大數據的標准體系框架共由七個類別的標准組成,分別為:基礎標准、數據標准、技術標准、平臺和工具標准、管理標准、安全和隱私標准、行業應用標准。本文主要闡述其中的第二個類別:數據標准。
二、關於數據標准認識的幾個誤區
數據標准這個詞,最早是在金融行業,特別是銀行業的數據治理中開始使用的。數據標准工作一直是數據治理中的基礎性重要內容。但是對於數據標准,不同的人卻有不同的看法:
有人認為數據標准極其重要,只要制定好了數據標准,所有數據相關的工作依標進行,數據治理大部分目標就水到渠成了。
也有人認為數據標准幾乎沒什麼用,做了大量的梳理,建設了一整套全面的標准,最後還不是被束之高閣,被人遺忘,幾乎沒有發揮任何作用。
首先亮明作者的觀點:這兩種看法都是不對的,至少是片面的。實際上,數據標准工作是一項複雜的,涉及面廣的,系統性的,長期性的工作。它既不能快速地發揮作用,迅速解决掉數據治理中的大部分問題,同時也肯定不是完全沒有作用,最後只剩下一堆文檔——如果數據標准工作的結局真是如此,那只能說明這項工作沒有做好,沒有落到實處。本文主要的目的,就是分析為什麼會出現這種情况,以及如何應對。而首先需要做的是厘清數據標准的定義。
三、數據標准的定義
何為數據標准,各相關組織並沒有統一的,各方都認可的定義。結合各家對數據標准的闡述,從數據治理的角度出發,我嘗試著給數據標准做一個定義:數據標准是對數據的錶達、格式及定義的一致約定,包含數據業務屬性、技術屬性和管理屬性的統一定義;數據標准的目的,是為了使組織內外部使用和交換的數據是一致的,准確的。
四、如何制定數據標准
一般來說,對於政府,會有國家或地方政府發文的數據標准管理辦法,其中會詳細規定相關的數據標准。所以在此主要講企業如何制定數據標准。
企業的數據標准來源非常豐富,有外部的監管要求,行業的通用標准,同時也必須考慮到企業內部數據的實際情况,梳理其中的業務指標、數據項、代碼等,將以上的所有的來源都納入數據標准是沒有必要的,數據標准的範圍應該主要集中在企業業務最核心的數據部分,有的企業也稱作關鍵業務數據或核心數據,只要制定出這些核心數據的標准,就能够支撐企業數據質量、主數據管理、數據分析等需要。

五、數據標准化的難題
數據標准好制定,但是數據標准落地相對就困難多了。國內的數據標准化工作發展了那麼多年,各個行業,各個組織都在建設自己的數據標准,但是你很少聽到哪個組織大張旗鼓地宣傳自己的數據標准工作多麼出色,換句話說,做數據標准取得顯著效果的案例並不多。為什麼會出現這種情况,主要有兩個原因:
一是制定的數據標准本身有問題。有些標准一味地追求先進,向行業領先看齊,標准大而全,脫離實際的數據情况,導致很難落地。
第二個原因,是標准化推進過程中出了問題。這是我們重點闡述的原因,主要有以下幾種情况:
對建設數據標准的目的不明確。某些組織建設數據標准,其目的不是為了指導信息系統建設,提高數據質量,更容易地處理和交換數據,而是應付監管機構檢查,因此需要的就是一堆標准文件和制度文件,根本就沒有執行的計劃。
過分依賴諮詢公司。一些組織沒有建設數據標准的能力,因此請諮詢公司來幫忙規劃和執行。一旦諮詢公司撤離,組織依然缺乏將這些標准落地的能力和條件。
對數據標准化的難度估計不足。很多公司上來就說要做數據標准,卻不知道數據標准的範圍很大,很難以一個項目的方式都做完,而是一個持續化推進的長期過程,結果是客戶越做遇到的阻力越大,困難越多,最後自己都沒有信心了,轉而把前期梳理的一堆成果束之高閣,這是最普遍的問題。
缺乏落地的制度和流程規劃。數據標准的落地,需要多個系統、部門的配合才能完成。如果只梳理出數據標准,但是沒有規劃如何落地的具體方案,缺乏技術、業務部門、系統開發商的支持,尤其是缺乏領導層的支持,是無論如何也不可能落地的。
組織管理水平的不足:數據標准落地的長期性、複雜性、系統性的特點,决定了推動落地的組織機構的管理能力必須保持在很高的水平線上,且架構必須持續穩定,才能有序地不斷推進。以上這些原因,導致數據標准化工作很難開展,更難取得較好的成效。數據標准化難落地,是數據治理行業的現狀,不容回避。
六、如何應對這些難題
應對以上這些難題,最經濟、最理想的模式當然是:做大數據建設,首先做標准,再做大數據平臺,數據倉庫等。但一般的不大可能有這樣的認識,很多時候大家都是先建設再治理。先把信息系統、數據中心建好,然後標准有問題,質量不高,再建數據標准,但實際上這時候已經是回過頭來做一些亡羊補牢的事情,客戶的投資肯定有一部分是浪費。
正因為其太過理想化,所以這種模式幾乎是見不到的。在實踐中,我們往往還是需要更多地考慮如何把數據標准落地到已有的系統和大數據平臺中。
數據標准落地有三種形式:
源系統改造:對源系統的改造是數據標准落地最直接的方式,有助於控制未來數據的質量,但工作量與難度都較高,現實中往往不會選擇這種方式,例如有客戶編號這個字段,涉及多個系統,範圍廣、重要程度高、影響大,一旦修改該字段,會涉及到相關的系統都需要修改。但是也不是完全不可行,可以借系統改造,重新上線的機會,對相關源系統的數據進行部分的對標落地。
數據中心落地:根據數據標准要求建設數據中心(或數據倉庫),源系統數據與數據中心做好映射,保證傳輸到數據中心的數據為標准化後的數據。這種方式的可行性較高,是絕大多數組織的選擇。
數據接口標准化:對已有的系統間的數據傳輸接口進行改造,讓數據在系統間進行傳輸的時候,全部遵循數據標准。這也是一種可行的方法。
在數據標准落地的過程中,需要做好6件事情,如下圖所示:

事先確定好落地的範圍:哪些數據標准需要落地,涉及到哪些IT系統,都是需要事先考慮好的。
事先做好差异分析:現有的數據和數據標准之間,究竟存在哪些差异,這些差异有多大,做好差异性分析。
事先做好影響性分析:如果這些數據標准落地了,會對哪些相關下遊戲廳產生什麼樣的影響,這些影響是否可控。元數據管理中的影響性分析可以幫助用戶確定影響的範圍。
制定落地的執行方案:執行方案要側重於可落地性。不能落地的方案,最終只能被廢弃。一個可落地的方案,要有組織架構和人員分工,每個人負責什麼,如何考核,怎麼監管,都是必須納入執行方案中的內容。
具體地執行落地方案:根據執行方案,進行數據標准落地執行。
事後評估:事後需要跟踪、評估數據落地的效果如何,做對了哪些事,哪些做得不足,如何改進。
七、總結
數據標准的建設大致可以分成兩個階段:
1、梳理和制定數據標准。
2、數據標准的落地和實施。
其中後者是公認的難題。本文分析了其中的原因,提供了一些如何讓數據標准更快更好落地的方法。
內容來源:數據學堂;本文來源:CDO之家
(如有侵權請聯系小編删除,謝謝)
边栏推荐
猜你喜欢
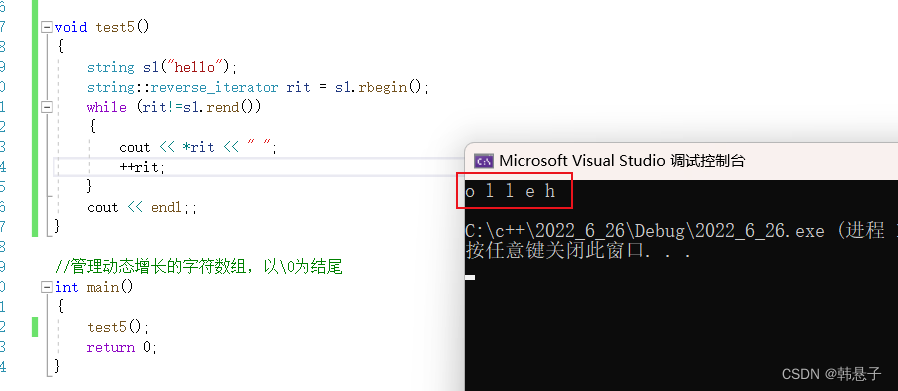
String (explanation)

Which foreign language periodicals are famous in geology?
Go straight to the 2022ecdc fluorite cloud Developer Conference: work with thousands of industries to accelerate intelligent upgrading
![[opencv] morphological filtering (2): open operation, morphological gradient, top hat, black hat](/img/45/f3b960e3c56f50674b0e6374cba705.png)
[opencv] morphological filtering (2): open operation, morphological gradient, top hat, black hat
Force deduction 62 different paths (the number of all paths from the upper left to the lower right of the matrix) (dynamic planning)
安装VMmare时候提示hyper-v / device defender 侧通道安全性
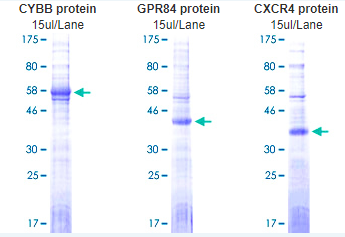
Abnova 膜蛋白脂蛋白体技术及类别展示
Installing redis and windows extension method under win system

Abnova循环肿瘤DNA丨全血分离,基因组DNA萃取分析
BindingException 异常(报错)处理
随机推荐
基于FPGA的VGA协议实现
Stack and queue-p79-10 [2014 unified examination real question]
How can I check the DOI number of a foreign document?
C语言面试 写一个函数查找两个字符串中的第一个公共字符串
循环肿瘤细胞——Abnova 解决方案来啦
Crudini profile editing tool
leetcode 509. Fibonacci Number(斐波那契数字)
Can't you really do it when you are 35 years old?
POI导出Excel:设置字体、颜色、行高自适应、列宽自适应、锁住单元格、合并单元格...
Pinduoduo lost the lawsuit: "bargain for free" infringed the right to know but did not constitute fraud, and was sentenced to pay 400 yuan
MySQL卸载文档-Windows版
C language sorting (to be updated)
Overview of FlexRay communication protocol
Which foreign language periodicals are famous in geology?
dolphinscheduler3.x本地启动
Several key steps of software testing, you need to know
Ha Qu projection dark horse posture, only half a year to break through the 1000 yuan projector market!
基本Dos命令
偏执的非合格公司
What books can greatly improve programming ideas and abilities?