当前位置:网站首页>隐马尔科夫模型(HMM)学习笔记
隐马尔科夫模型(HMM)学习笔记
2022-07-07 02:05:00 【Wsyoneself】
- 马尔科夫链:在任一时刻t,观测变量的取值仅依赖于当前的状态变量,与其他时刻的状态变量即观测变量无关;同时,当前的状态值仅依赖于前一个时刻的状态,与其他无关。
- 由马尔可夫得到HMM的联合概率分布
- 一个模型肯定包含参数,机器学习的本质就是找到一组最优的参数,使得模型的拟合效果最好。
- HMM的参数:状态转移概率(由当前状态推测下一状态的概率),输出观测概率(由当前状态推测观测值的概率)
- 三个基本问题:
- 概率计算问题:给定模型和观测序列,计算观测序列的出现概率
- 学习问题:已知观测序列,估计模型参数,使得观测序列的输出概率最大
- 预测问题:给定模型和观测序列,求对给定观测序列条件概率P(I|O)最大的隐藏状态I
- 算法:
- 前向算法:给定隐马尔科夫模型,以及至时刻t的观测序列,且状态为qi的前向概率:实际就是从t=1开始计算,根据隐式马尔可夫的假设,迭代计算即可得(自己理解:前向概率就是时刻t转移到时刻t+1的概率,每个状态乘上当前状态的状态转移概率,由于最后得到的是观测值,还需要乘上最后时刻的观测概率)
- 后向算法:给定隐马尔科夫模型,以及从t+1时刻到T的观测序列,且状态为qi的后向概率:假设最后一时刻的概率为1,然后理由条件概率的逆计算从后向前推
- Baum-welch算法:如果样本数据没有标签,则训练数据只包含观测序列O,但对应的状态I未知,则此时的隐马尔科夫模型是一个含有隐变量的概率模型。
参数学习本质还是EM,EM的基本思想是先将参数的初设估计值加入到似然函数中,然后对似然函数进行极大化(一般是求导,令其等于0),得到新的参数估计值,一直重复,直到收敛。
维特比(Viterbi)算法:是一种动态规划算法,用于寻找最有可能产生观测事件序列的-维特比路径-隐含状态序列。
概括:
给定模型和观察,Forward算法可以计算从模型观察出特定序列的概率;Viterbi算法可以计算最有可能的内部状态;Baum-Welch算法可以用于训练HMM。当有足够的训练数据,用Baum-Welch算出HMM的状态转移概率和观察概率函数,然后就可以用Viterbi算法求出每一句输入的语音背后最有可能的音素序列。但如果数据量有限,往往先训练一些比较小的HMM用于识别各个单音子(monophone),或者三音子(triphone),然后把这些小HMM串起来就能识别连续语音
对于语音合成,给定一串音素,去数据库里找出最符合这串音素的一堆小HMM,把它们串成一个较长的HMM,代表整个句子。然后根据这个组合出的HMM,计算最有可能观察出的语音参数序列,剩下的就是从参数序列生成语音了。这是对完整过程的简化,最主要的问题在于,这样生成的语音参数是不连续的,因为HMM的状态是离散的。为了解决这个问题,Keiichi Tokuda借鉴语音识别中广泛使用的动态参数(参数的一阶和二阶导数),将其引入语音合成的参数生成中,使生成语音的连贯性有了大幅提高。重点是利用隐性状态,如语法,用词习惯等,推测出概率更高的输出。
- 在已知模型参数的情况下,观测序列为O时,状态可以为任何一种状态,则每一种状态下观测序列为O的概率累加就是观测序列的概率了。
- 对于有监督学习,可以直接根据数据计算状态转移概率和输出观测概率(对于分词来说,观测序列对应的是文本句子,隐藏状态对应的是句子中每个字的标签)
- 语音识别中观测序列是语言,隐藏状态是文字,语音识别的作用就是将语音转化为对应的文字。
参考:
「隐马尔可夫模型」(HMM-Based)在语音合成中是如何应用的? - 知乎 (zhihu.com)
边栏推荐
- docker-compose启动redis集群
- 3428. Put apples
- ST表预处理时的数组证明
- go-microservice-simple(2) go-Probuffer
- 请问如何查一篇外文文献的DOI号?
- [opencv] morphological filtering (2): open operation, morphological gradient, top hat, black hat
- How to keep accounts of expenses in life
- C面试24. (指针)定义一个含有20个元素的double型数组a
- Redis (I) -- getting to know redis for the first time
- window下面如何安装swoole
猜你喜欢

postgresql 数据库 timescaledb 函数time_bucket_gapfill()报错解决及更换 license
jmeter 函数助手 — — 随机值、随机字符串、 固定值随机提取

What are the classic database questions in the interview?

A very good JVM interview question article (74 questions and answers)
window下面如何安装swoole
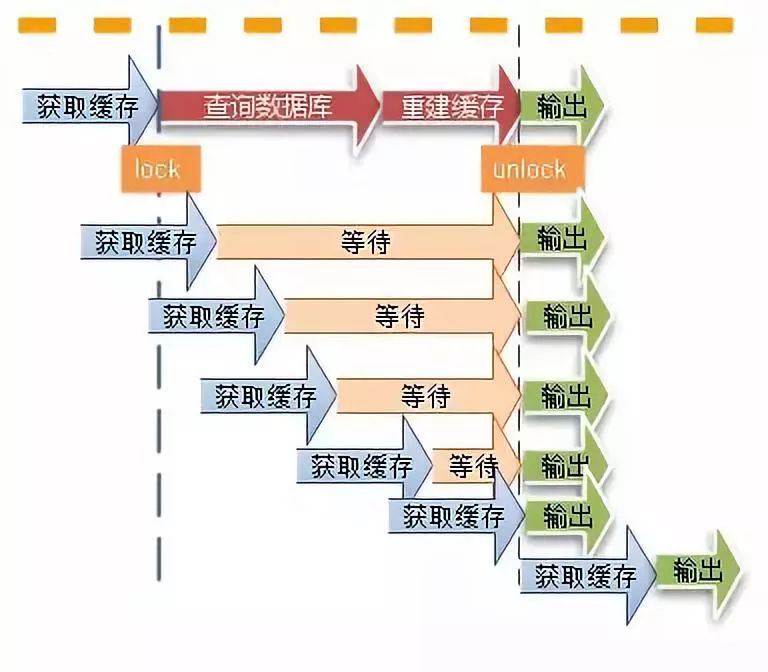
缓存在高并发场景下的常见问题
Redis (I) -- getting to know redis for the first time
Navicat导入15G数据报错 【2013 - Lost connection to MySQL server during query】 【1153:Got a packet bigger】

Developers don't miss it! Oar hacker marathon phase III chain oar track registration opens
tkinter窗口选择pcd文件并显示点云(open3d)
随机推荐
Peripheral driver library development notes 43: GPIO simulation SPI driver
UIC (configuration UI Engineering) public file library adds 7 industry materials
屏幕程序用串口无法调试情况
A very good JVM interview question article (74 questions and answers)
一段程序让你明白什么静态内部类,局部内部类,匿名内部类
Jstack of JVM command: print thread snapshots in JVM
当我们谈论不可变基础设施时,我们在谈论什么
JVM monitoring and diagnostic tools - command line
string(讲解)
Ha Qu projection dark horse posture, only half a year to break through the 1000 yuan projector market!
C interview encryption program: input plaintext by keyboard, convert it into ciphertext through encryption program and output it to the screen.
Database notes 04
c语言(结构体)定义一个User结构体,含以下字段:
Redis(二)—Redis通用命令
tkinter窗口选择pcd文件并显示点云(open3d)
K8s running Oracle
uniapp开发小程序如何使用微信云托管或云函数进行云开发
docker-compose启动redis集群
JMeter function assistant - random value, random string, fixed value random extraction
缓存在高并发场景下的常见问题