当前位置:网站首页>Common problems of caching in high concurrency scenarios
Common problems of caching in high concurrency scenarios
2022-07-07 06:21:00 【TimeFriends】
List of articles
Cache consistency issues
When data timeliness requirements are high , You need to make sure that the data in the cache is consistent with the data in the database , And you need to make sure that the data in the cache node and the replica are consistent , No differences . This is more dependent on cache expiration and update policies . Usually when the data changes , Actively update the data in the cache or remove the corresponding cache .
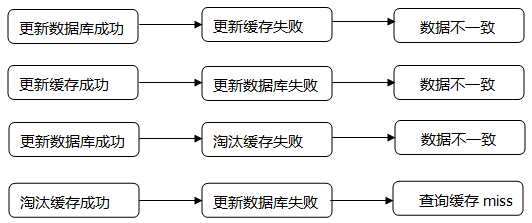
Cache concurrency issues
After the cache expires, it will try to get data from the back-end database , This is a seemingly reasonable process .
however , In high concurrency scenarios , It is possible for multiple requests to obtain data from the database concurrently , Great impact on back-end database , Even lead to “ An avalanche ” The phenomenon .
Besides , When a cache key When updated , At the same time, it may be obtained by a large number of requests , This can also lead to problems of consistency . How to avoid such problems ? We will think of something similar “ lock ” The mechanism of , In case of cache update or expiration , Try to get the lock first , Release the lock after the update or get from the database , Other requests only need to sacrifice a certain waiting time , You can continue to get data directly from the cache .
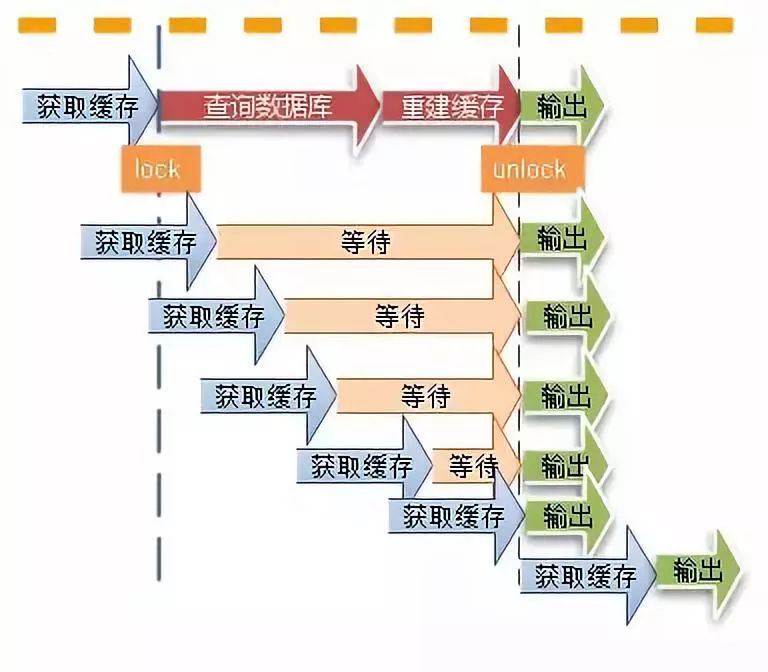
Cache penetration problem
Cache penetration is also called... In some places “ breakdown ”. Many friends' understanding of cache penetration is : A large number of requests penetrate the back-end database server due to cache failure or cache expiration , So it has a huge impact on the database .
This is actually a misunderstanding . The real cache penetration should be like this :
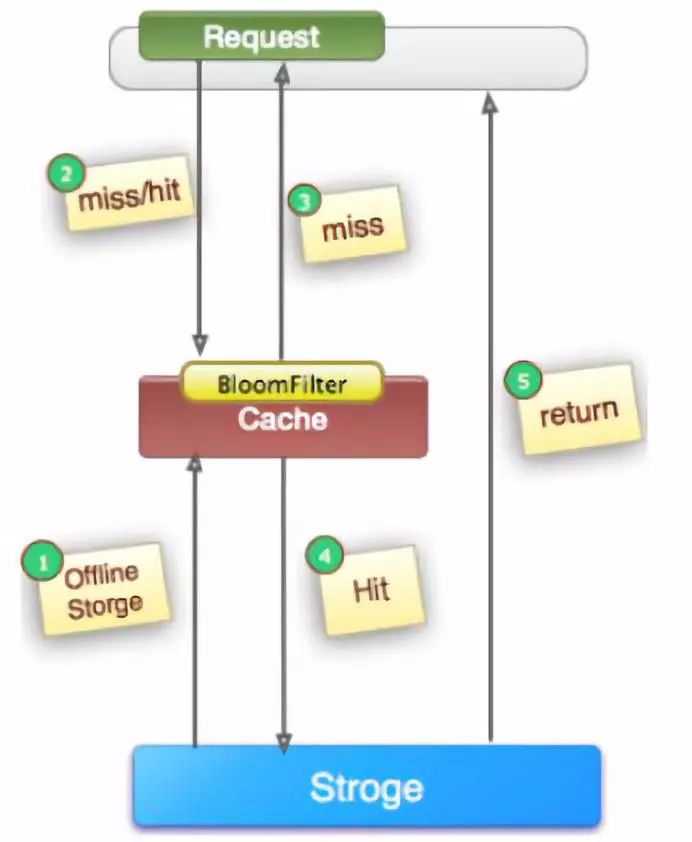
In high concurrency scenarios , If a certain key Access by high concurrency , Not hit , For the sake of fault tolerance , Will try to get... From the backend database , This leads to a large number of requests reaching the database , And when key When the corresponding data itself is empty , This causes many unnecessary query operations to be executed concurrently in the database , Which leads to huge shock and pressure .
There are several common ways to avoid the traditional problem of caching :
1. Caching empty objects
Also cache objects with empty query results , If it's a collection , Can cache an empty collection ( Not null), If it's caching a single object , You can distinguish... By field identification . This prevents requests from penetrating the back-end database . meanwhile , We also need to ensure the timeliness of cached data .
It's cheaper to implement this way , It's more suitable for low hit , But data that can be updated frequently .
2. Separate filtration
Empty... For all possible corresponding data key For unified storage , And intercept before request , This prevents requests from penetrating the back-end database .
This approach is relatively complex to implement , It's more suitable for low hit , But update infrequent data .
Cache bumps
Cache bumps , Some places may be “ Cache jitter ”, It can be seen as a comparison “ An avalanche ” A more minor fault , But it will also have impact and performance impact on the system for a period of time . Generally, it is caused by cache node failure . The recommended practice in the industry is through consistency Hash Algorithm to solve .
The avalanche of cache
Cache avalanche is due to the cache , Result in a large number of requests to the back-end database , This causes the database to crash , System crash , There was a disaster . There are many reasons for this phenomenon , As mentioned above “ Cache concurrency ”,“ Cache penetration ”,“ Cache bumps ” Other questions , In fact, it may lead to cache avalanche .
These problems may also be exploited by malicious attackers . There's another situation , For example, at some point in time , The periodic concentration of the system's preloaded cache fails , It can also lead to avalanches . To avoid this periodic failure , You can set different expiration times , To stagger cache expiration , To avoid cache set failure .
From the perspective of application architecture , We can limit the flow through 、 Downgrade 、 Fuse and other means to reduce the impact , This kind of disaster can also be avoided through multi-level caching .
Besides , From the perspective of the whole R & D system process , Stress testing should be strengthened , Try to simulate the real scene , Expose problems as early as possible to prevent .
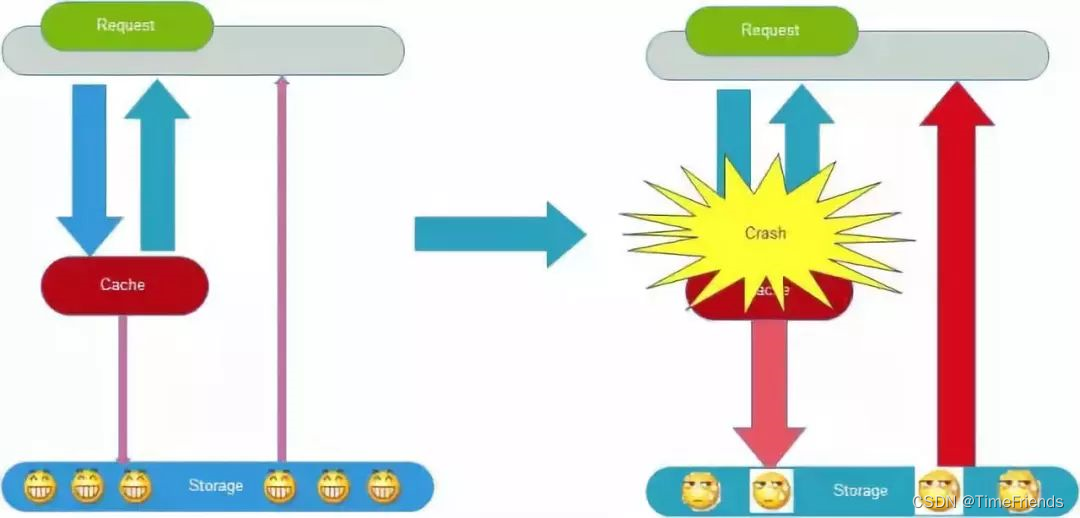
There is no bottom hole in the cache
The problem is caused by facebook Of the staff , facebook stay 2010 About years ago ,memcached The node has reached 3000 individual , Cache thousands G Content . They found a problem ——memcached Connection frequency 、 Efficiency is down , So add memcached node , After adding , Found problems due to connection frequency , There is still , It's not getting better , be called ” Bottomless hole phenomenon ”.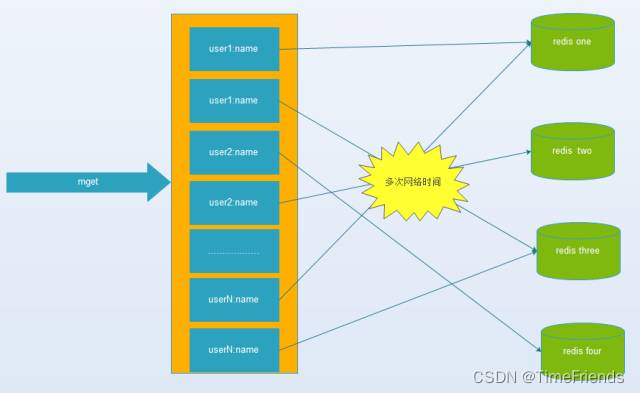
The current mainstream database 、 cache 、Nosql、 Search middleware and other technology stack , All support “ Fragmentation ” technology , To satisfy “ High performance 、 High concurrency 、 High availability 、 Scalable ” Other requirements . Some are in client End pass Hash modulus ( Or consistency Hash) Map values to different instances , Some are in client The end is mapped by range value . Of course , Some of them are on the server side .
however , Each operation may require network communication with different nodes to complete , More instance nodes , The more expensive it will be , The greater the impact on performance .
It can be avoided and optimized from the following aspects :
1. Data distribution
Some business data may be suitable for Hash Distribution , And some businesses are suitable for range distribution , This can avoid the Internet to some extent IO The cost of .
2.IO Optimize
Make full use of the connection pool ,NIO Wait for technology to minimize connection overhead , Enhance concurrent connectivity .
3. Data access
Get large datasets at once , Will score many times to get the network of small datasets IO It costs less .
Of course , The phenomenon of no bottom hole in cache is not common . In the vast majority of companies, there may not be .
According to the access method **
Get large datasets at once , Will score many times to get the network of small datasets IO It costs less .
Of course , The phenomenon of no bottom hole in cache is not common . In the vast majority of companies, there may not be .
Common problems about caching in high concurrency scenarios , Did you stop learning ?
We sincerely invite you to join our family , There is not only technical knowledge sharing here , And the bloggers help each other . I still get red packets from time to time , There is a lottery every month , Game consoles and physical books ( Free shipping ), Let's keep warm together , Curl up . Create beauty C standing . Looking forward to your joining .
边栏推荐
- 693. Travel sequencing
- Three updates to build applications for different types of devices | 2022 i/o key review
- ICML 2022 | 探索语言模型的最佳架构和训练方法
- Understand the deserialization principle of fastjson for generics
- 软件测试知识储备:关于「登录安全」的基础知识,你了解多少?
- How to set up in touch designer 2022 to solve the problem that leap motion is not recognized?
- A freshman's summary of an ordinary student [I don't know whether we are stupid or crazy, but I know to run forward all the way]
- 一段程序让你明白什么静态内部类,局部内部类,匿名内部类
- Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
- Niuke Xiaobai monthly race 52 E. sum logarithms in groups (two points & inclusion and exclusion)
猜你喜欢
![[FPGA] EEPROM based on I2C](/img/28/f4f2efda4b5feb973c9cf07d9d908f.jpg)
[FPGA] EEPROM based on I2C
JVM命令之 jstat:查看JVM統計信息
Jinfo of JVM command: view and modify JVM configuration parameters in real time
![[FPGA tutorial case 13] design and implementation of CIC filter based on vivado core](/img/19/1a6d43c39f2cf810ba754ea9674426.png)
[FPGA tutorial case 13] design and implementation of CIC filter based on vivado core
rt-thread 中对 hardfault 的处理
window下面如何安装swoole

当我们谈论不可变基础设施时,我们在谈论什么
基于FPGA的VGA协议实现
安装VMmare时候提示hyper-v / device defender 侧通道安全性
JVM command - jmap: export memory image file & memory usage
随机推荐
3531. 哈夫曼树
2022Android面试必备知识点,一文全面总结
C语言面试 写一个函数查找两个字符串中的第一个公共字符串
Convert numbers to string strings (to_string()) convert strings to int sharp tools stoi();
一段程序让你明白什么静态内部类,局部内部类,匿名内部类
Several key steps of software testing, you need to know
Crudini profile editing tool
Say sqlyog deceived me!
C面试24. (指针)定义一个含有20个元素的double型数组a
Jstat of JVM command: View JVM statistics
3531. Huffman tree
tkinter窗口选择pcd文件并显示点云(open3d)
Subghz, lorawan, Nb IOT, Internet of things
10W word segmentation searches per second, the product manager raised another demand!!! (Collection)
win系统下安装redis以及windows扩展方法
Jstat pour la commande JVM: voir les statistiques JVM
Three updates to build applications for different types of devices | 2022 i/o key review
rt-thread 中对 hardfault 的处理
Career experience feedback to novice programmers
哈趣投影黑馬之姿,僅用半年强勢突圍千元投影儀市場!