当前位置:网站首页>Deep clustering: joint optimization of depth representation learning and clustering
Deep clustering: joint optimization of depth representation learning and clustering
2022-07-07 06:01:00 【This Livermore is not too cold】
reference :

brief introduction
Classical clustering means that data is characterized by vectorization through various representation learning techniques . As data becomes more and more complex , Shallow ( Tradition ) Clustering methods have been unable to deal with high-dimensional data types . A direct way to combine the advantages of deep learning is to first learn the depth representation , Then input it into the shallow clustering method . But there are two disadvantages :i) It means that you are not learning clustering directly , This limits clustering performance ; ii) Clustering depends on complex rather than linear relationships between instances ; iii) Clustering and representation learning are interdependent , Should be mutually reinforcing .
In order to solve the problem , The concept of deep clustering is proposed , That is, joint optimization represents learning and clustering .
Purpose
The main purpose of clustering is to group instances , Make similar samples belong to the same cluster , Different samples belong to different clusters . Sample clusters provide a global representation of data instances , This can significantly facilitate further analysis of the entire data set , For example, anomaly detection , Domain adaptation , Community detection and discrimination represent learning .
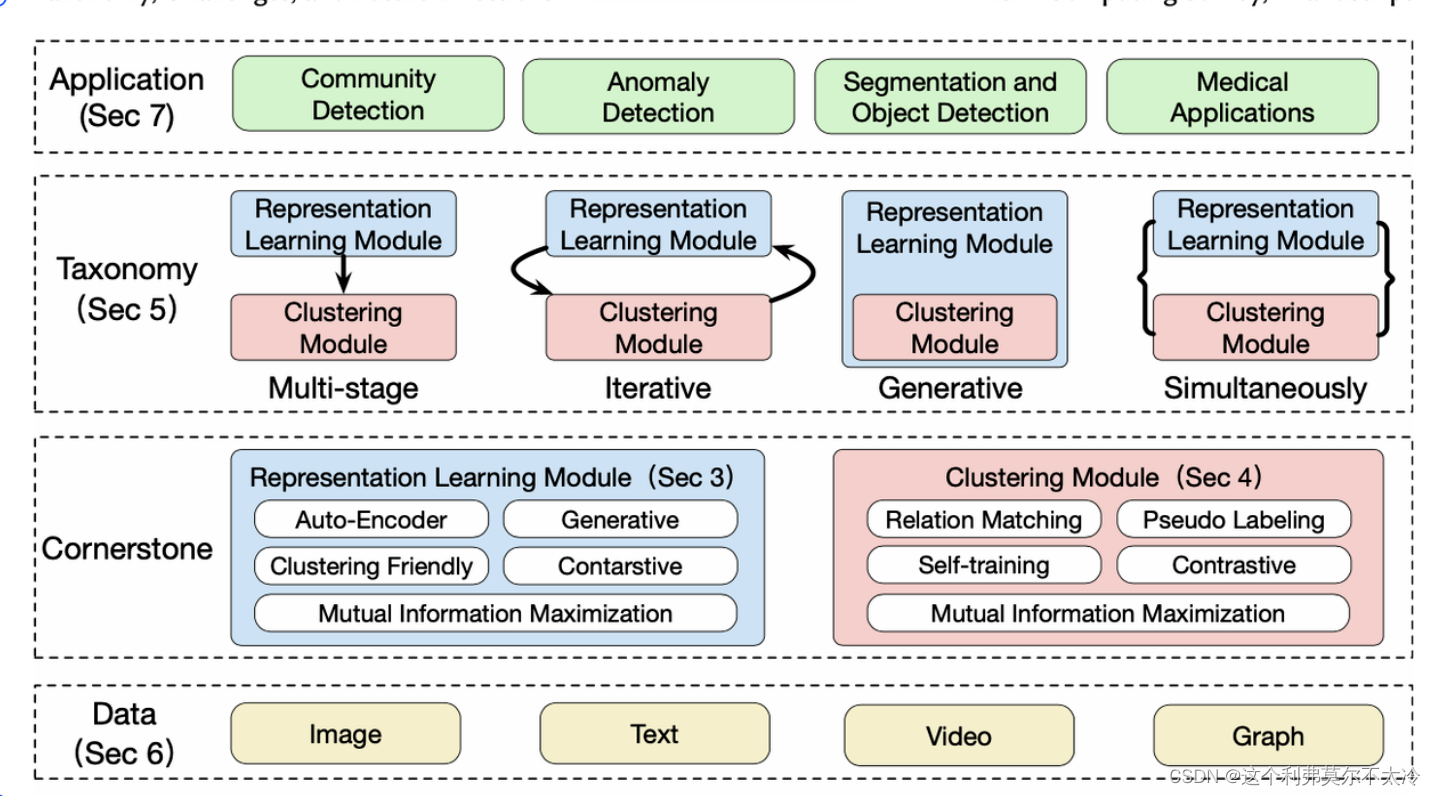
Image Representation Learning.
Learning technology through modern representation ( For example, visual converter ) The introduction of deep clustering has made progress . As one of the most popular directions , Unsupervised representation learning of image data will play a central role in deep clustering and affect other data types .
Text Representation Learning
Early attempts at text representation learning used statistical methods , Such as TF-IDF 、Word2Vec and Skip-Gram. later , Some work focuses on topic modeling and semantic distance in text representation learning , And more about unsupervised scenarios . lately , image BERT and GPT-3 Such a pre training language model gradually occupies a dominant position in the field of text representation learning .
Video Representation Learning
Video shows that learning is a challenging task , It will learn from time and space 、 Multi model learning and natural language processing ( With video summary and subtitles ) Combine into one place . Early methods used LSTM Autoencoder 、3D-ResNets and 3D-U-Net As a feature extractor .
Graph Representation Learning
The classical graph representation learning aims to learn the low dimensional representation of nodes , In order to preserve the proximity between nodes in the embedded space . Besides , Map level information also has great potential in tasks such as protein classification , This has attracted more and more attention in graph level representation learning

The data type specific representation learning mentioned above can be simple backbone for feature extraction or end-to-end unsupervised representation learning , This is the most active research direction in deep learning . As more types of data are collected , Deep clustering will grow with data type specific representation learning techniques .
Deep learning method
Multilevel deep clustering (Multistage Deep Clustering)
Multilevel deep clustering refers to the method of optimizing and connecting two modules respectively . One direct way is Using deep unsupervised representation learning technology, first learn the representation of each data instance , Then input the learned representation into the classical clustering model to obtain the final clustering result . This separation of data processing and clustering is helpful for researchers to carry out cluster analysis . More specifically , All existing clustering algorithms can serve any Research scenario .
Iterative depth clustering (Iterative Deep Clustering)
The main purpose of iterative depth clustering is Good representation can benefit clustering , The clustering results provide supervision for representation learning in reverse . Most existing iterative depth clustering pipelines update iteratively between two steps
1) Calculate the clustering result given the current representation ;
2) Update the representation given the current clustering result . Iterative depth clustering method benefits from the mutual promotion between representation learning and clustering . However , They are also affected by error propagation during iteration . Inaccurate clustering results may lead to chaotic representation , Among them, the performance is limited by the effectiveness of self marking . Besides , This in turn will affect the clustering results , Especially in the early stages of training . therefore , Existing iterative clustering methods rely heavily on the pre training of representation modules .
Generate deep clustering (Generative Deep Clustering)
Deep generation clustering model can Generate samples while clustering
The generated model can capture 、 Represent and recreate data points , Therefore, it has attracted more and more attention from academia and industry . They will make assumptions about the potential cluster structure , Then the cluster allocation is inferred by estimating the data density . The most representative model is Gaussian mixture model , It assumes that data points are generated from Gaussian mixture
There are weaknesses :
1) Training generation models usually involve Monte Carlo sampling , It may lead to unstable training and high computational complexity ;
2) The mainstream generation model is based on VAE and GAN, Inevitably inherited their shortcomings . be based on VAE Our model usually requires a priori assumption of data distribution , This may not be true in actual cases ; Even though be based on GAN Our algorithm is more flexible , But they usually have problems of mode collapse and slow convergence , Especially for data with multiple clusters .
At the same time, deep clustering (Simultaneous Deep Clustering)
The representation learning module and the clustering module are optimized simultaneously in an end-to-end manner . Although most iterative depth clustering methods also optimize two modules with a single objective , But these two modules are optimized by explicit iteration , Cannot update at the same time . Although most iterative depth clustering methods also optimize two modules with a single objective , But these two modules are optimized by explicit iteration , Cannot update at the same time .
The representation of learning is Clustering Oriented , Clustering is carried out on the discriminant space . however , It may produce an unwanted bias against the optimization focus between the representation learning module and the clustering module , At present, this bias can only be alleviated by manually setting the balance parameters . Besides , The model can easily fall into a degraded solution , All instances are assigned to a cluster
Common data set
4 Common data sets in three directions
The future direction
Initialization of Deep Clustering Module
Overlapping Deep Clustering
Degenerate Solution VS Unbalanced Data
Boosting Representation with Deep Clustering
Deep Clustering Explanation
Transfer Learning with Deep Clustering
Clustering with Anomalies
Efficient Training VS Global Modeling
边栏推荐
- Why does the data center need a set of infrastructure visual management system
- Ten stages of becoming a Senior IC Design Engineer. What stage are you in now?
- ML's shap: Based on the adult census income binary prediction data set (whether the predicted annual income exceeds 50K), use the shap decision diagram combined with the lightgbm model to realize the
- 一个简单的代数问题的求解
- 毕业之后才知道的——知网查重原理以及降重举例
- 线性回归
- PowerPivot——DAX(函数)
- Message queue: how to deal with message backlog?
- What EDA companies are there in China?
- 软件测试面试技巧
猜你喜欢
pytorch_ 01 automatic derivation mechanism
![C. colonne Swapping [tri + Simulation]](/img/0e/64d17980d3ec0051cdfb5fdb34e119.png)
C. colonne Swapping [tri + Simulation]

Red hat install kernel header file
C note 13
Go语学习笔记 - gorm使用 - 原生sql、命名参数、Rows、ToSQL | Web框架Gin(九)
Red Hat安装内核头文件
Jstat pour la commande JVM: voir les statistiques JVM

Hcip eighth operation
An example of multi module collaboration based on NCF
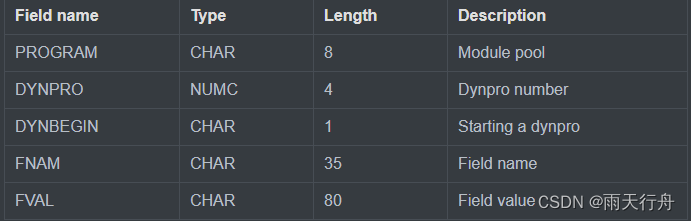
SAP ABAP BDC (batch data communication) -018
随机推荐
数字IC面试总结(大厂面试经验分享)
Wechat applet Bluetooth connects hardware devices and communicates. Applet Bluetooth automatically reconnects due to abnormal distance. JS realizes CRC check bit
Interview skills of software testing
TCC of distributed transaction solutions
Understand the deserialization principle of fastjson for generics
yarn入门(一篇就够了)
力扣102题:二叉树的层序遍历
苹果cms V10模板/MXone Pro自适应影视电影网站模板
数据中心为什么需要一套基础设施可视化管理系统
Bbox regression loss function in target detection -l2, smooth L1, IOU, giou, Diou, ciou, focal eiou, alpha IOU, Siou
Win configuration PM2 boot auto start node project
如果不知道这4种缓存模式,敢说懂缓存吗?
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
OpenSergo 即将发布 v1alpha1,丰富全链路异构架构的服务治理能力
linear regression
JVM the truth you need to know
关于服装ERP,你知道多少?
从“跑分神器”到数据平台,鲁大师开启演进之路
Say sqlyog deceived me!
[daily training -- Tencent selected 50] 235 Nearest common ancestor of binary search tree