当前位置:网站首页>深度聚类:将深度表示学习和聚类联合优化
深度聚类:将深度表示学习和聚类联合优化
2022-07-07 00:43:00 【这个利弗莫尔不太冷】
参考文献:

简介
经典聚类即数据通过各种表示学习技术以矢量化形式表示为特征。随着数据变得越来越复杂和复杂,浅层(传统)聚类方法已经无法处理高维数据类型。结合深度学习优势的一种直接方法是首先学习深度表示,然后再将其输入浅层聚类方法。但是这有两个缺点:i)表示不是直接学习聚类,这限制了聚类性能; ii) 聚类依赖于复杂而不是线性的实例之间的关系; iii)聚类和表示学习相互依赖,应该相互增强。
为了解决改问题,深度聚类的概念被提出,即联合优化表示学习和聚类。
目的
聚类的主要目的是将实例分组,使相似的样本属于同一个簇,而不相似的样本属于不同的簇。 样本集群提供了数据实例的全局表征,这可以显着有利于对整个数据集的进一步分析,例如异常检测 ,域适应 ,社区检测和判别表示学习等。
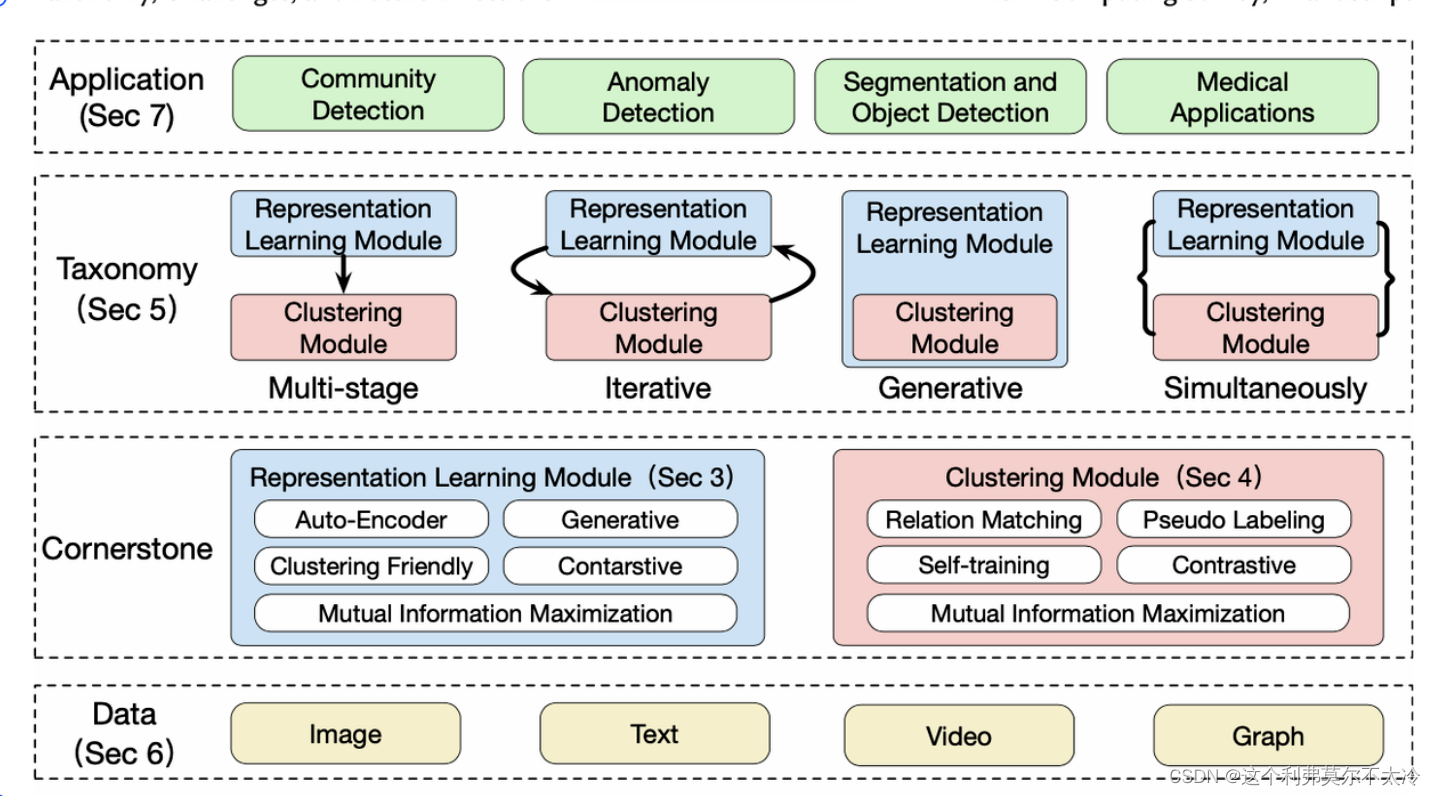
Image Representation Learning.
通过将现代表示学习技术(例如视觉变换器)引入深度聚类而取得了进展。 作为最流行的方向之一,图像数据的无监督表示学习将在深度聚类中发挥核心作用并影响其他数据类型。
Text Representation Learning
文本表示学习的早期尝试利用了基于统计的方法,如 TF-IDF 、Word2Vec和 Skip-Gram。 后来,一些工作专注于文本表示学习的主题建模和语义距离,以及更多关于无监督场景。 最近,像 BERT 和 GPT-3这样的预训练语言模型逐渐在文本表示学习领域占据主导地位。
Video Representation Learning
视频表示学习是一项具有挑战性的任务,它将时空学习、多模型学习和自然语言处理(带视频摘要和字幕)结合到一个地方。 早期的方法利用 LSTM Autoencoder 、3D-ResNets 和 3D-U-Net作为特征提取器。
Graph Representation Learning
经典的图表示学习旨在学习节点的低维表示,以便在嵌入空间中保留节点之间的接近度。此外,图级信息在蛋白质分类等任务中也具有巨大潜力,这在图级表示学习中引起了越来越多的关注

上面提到的数据类型特定表示学习可以是用于特征提取的朴素主干或端到端无监督表示学习,这是深度学习中最活跃的研究方向。 随着更多类型的数据被收集,深度聚类会随着数据类型特定的表示学习技术而增长。
深度学习方法
多级深度聚类(Multistage Deep Clustering)
多级深度聚类是指两个模块分别优化和顺序连接的方法。 一种直接的方法是使用深度无监督表示学习技术首先学习每个数据实例的表示,然后将学习的表示输入经典聚类模型以获得最终的聚类结果。 这种数据处理和聚类的分离有助于研究人员进行聚类分析。 更具体地说,所有现有的聚类算法都可以服务于任何研究场景。
迭代深度聚类(Iterative Deep Clustering)
迭代深度聚类的主要目的是良好的表示可以使聚类受益,而聚类结果反向为表示学习提供监督。大多数现有的迭代深度聚类管道在两个步骤之间迭代更新
1)在给定当前表示的情况下计算聚类结果;
2)在给定当前聚类结果的情况下更新表示。 迭代深度聚类方法受益于表示学习和聚类之间的相互促进。 然而,它们也受到迭代过程中的错误传播的影响。不准确的聚类结果可能导致混乱的表示,其中性能受到自标记有效性的限制。 此外,这反过来会影响聚类结果,尤其是在训练的早期阶段。 因此,现有的迭代聚类方法严重依赖于表示模块的预训练。
生成深度聚类(Generative Deep Clustering)
深度生成聚类模型可以在完成聚类的同时生成样本
生成模型能够捕获、表示和重新创建数据点,因此越来越受到学术界和工业界的关注。 他们将对潜在集群结构做出假设,然后通过估计数据密度来推断集群分配。 最具代表性的模型是高斯混合模型,它假设数据点是从高斯混合生成的
存在的弱点:
1)训练生成模型通常涉及蒙特卡罗采样,可能导致训练不稳定和计算复杂度高;
2)主流的生成模型基于VAE和GAN,不可避免地继承了它们的缺点。 基于 VAE 的模型通常需要对数据分布进行先验假设,这在实际案例中可能不成立; 尽管基于 GAN 的算法更加灵活多样,但它们通常会出现模式崩溃和收敛缓慢的问题,尤其是对于具有多个集群的数据。
同时深度聚类(Simultaneous Deep Clustering)
表示学习模块和聚类模块以端到端的方式同时进行优化。 尽管大多数迭代深度聚类方法也以单一目标优化两个模块,但这两个模块以显式迭代方式进行优化,不能同时更新。尽管大多数迭代深度聚类方法也以单一目标优化两个模块,但这两个模块以显式迭代方式进行优化,不能同时更新。
学习的表示是面向聚类的,聚类是在判别空间上进行的。 但是,它可能会在表示学习模块和聚类模块之间对优化焦点产生不希望的偏见,目前只能通过手动设置平衡参数来减轻这种偏见。 此外,该模型很容易陷入退化的解决方案,其中所有实例都分配到一个集群中
常用数据集
4个方向的常用数据集
未来的方向
Initialization of Deep Clustering Module
Overlapping Deep Clustering
Degenerate Solution VS Unbalanced Data
Boosting Representation with Deep Clustering
Deep Clustering Explanation
Transfer Learning with Deep Clustering
Clustering with Anomalies
Efficient Training VS Global Modeling
边栏推荐
- Ten stages of becoming a Senior IC Design Engineer. What stage are you in now?
- [daily training -- Tencent selected 50] 235 Nearest common ancestor of binary search tree
- SQL Server 2008 各种DateTime的取值范围
- Web authentication API compatible version information
- Input of native applet switches between text and password types
- 《2022中国低/无代码市场研究及选型评估报告》发布
- R language [logic control] [mathematical operation]
- Introduction to distributed transactions
- TCC of distributed transaction solutions
- 原生小程序 之 input切換 text與password類型
猜你喜欢


随机推荐
TCC of distributed transaction solutions
PTA 天梯赛练习题集 L2-002 链表去重
【Shell】清理nohup.out文件
SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
Reptile exercises (III)
PowerPivot——DAX(函数)
PTA TIANTI game exercise set l2-003 moon cake test point 2, test point 3 Analysis
Web authentication API compatible version information
sql查询:将下一行减去上一行,并做相应的计算
【已解决】记一次EasyExcel的报错【读取xls文件时全表读不报错,指定sheet名读取报错】
Pytorch builds neural network to predict temperature
Determine whether the file is a DICOM file
[daily training -- Tencent selected 50] 292 Nim games
Detailed explanation of platform device driver architecture in driver development
What is make makefile cmake qmake and what is the difference?
Why does the data center need a set of infrastructure visual management system
Classic questions about data storage
make makefile cmake qmake都是什么,有什么区别?
The 2022 China low / no code Market Research and model selection evaluation report was released
STM32按键状态机2——状态简化与增加长按功能