当前位置:网站首页>《ClickHouse原理解析与应用实践》读书笔记(6)
《ClickHouse原理解析与应用实践》读书笔记(6)
2022-07-07 00:03:00 【Aiky哇】
开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第7章-第8章:
第9章 数据查询
真正的生产环境中,在绝大部分场景中,都应该避免使用SELECT * 形式来查询数据,因为通配符*对于采用列式存储的ClickHouse而言没有任何好处。
ClickHouse目前支持的查询子句如下所示:
[WITH expr |(subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]] ] JOIN (subquery)|table ON|USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]方括号包裹的查询子句表示其为可选项,只有SELECT子句是必须的。
9.1 WITH子句
ClickHouse支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达。例如下面的函数嵌套:
SELECT pow(pow(2, 2), 3)在改用CTE的形式后:
WITH pow(2, 2) AS a SELECT pow(a, 3)CTE通过WITH子句表示,目前支持以下四种用法。
1.定义变量
可以定义变量,这些变量能够在后续的查询子句中被直接访问。
WITH 10 AS start
SELECT number FROM system.numbers
WHERE number > start
LIMIT 5
┌number─┐
│ 11 │
│ 12 │
│ 13 │
│ 14 │
│ 15 │
└─────┘
2.调用函数
可以访问SELECT子句中的列字段,并调用函数做进一步的加工处理。
WITH SUM(data_uncompressed_bytes) AS bytes
SELECT database , formatReadableSize(bytes) AS format FROM system.columns
GROUP BY database
ORDER BY bytes DESC
┌─database────┬─format───┐
│ datasets │ 12.12 GiB │
│ default │ 1.87 GiB │
│ system │ 1.10 MiB │
│ dictionaries │ 0.00 B │
└─────────┴───────┘例子中,data_uncompressed_bytes使用聚合函数求和后,又紧接着在SELECT子句中对其进行了格式化处理。
3.定义子查询
可以定义子查询。
WITH (
SELECT SUM(data_uncompressed_bytes) FROM system.columns
) AS total_bytes
SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.columns
GROUP BY database
ORDER BY database_disk_usage DESC
┌─database────┬──database_disk_usage─┐
│ datasets │ 85.15608638238845 │
│ default │ 13.15591656190217 │
│ │ │
│ system │ 0.007523354055850406 │
│ dictionaries │ 0 │
└──────────┴──────────────┘WITH使用子查询语句,只能返回一行数据,如果结果集的数据大于一行则会抛出异常。
4.在子查询中重复使用WITH
在子查询中可以嵌套使用WITH子句
WITH (
round(database_disk_usage)
) AS database_disk_usage_v1
SELECT database,database_disk_usage, database_disk_usage_v1
FROM (
--嵌套
WITH (
SELECT SUM(data_uncompressed_bytes) FROM system.columns
) AS total_bytes
SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.colum
GROUP BY database
ORDER BY database_disk_usage DESC
)
┌─database────┬───database_disk_usage─┬─database_disk_usage_v1───┐
│ datasets │ 85.15608638238845 │ 85 │
│ default │ 13.15591656190217 │ 13 │
│ system │ 0.007523354055850406 │ 0 │
└─────────┴───────────────┴─────────────────┘9.2 FROM子句
支持三种形式:
- 从数据表中获取数据。
- 从子查询中获取数据。
- 从表函数中获取数据。(比如SELECT number FROM numbers(5))
FROM关键字可以省略,此时会从虚拟表中取数。在ClickHouse 中,并没有数据库中常见的DUAL虚拟表,取而代之的是system.one。
-- 以下两条查询等价
SELECT 1
SELECT 1 FROM system.one
┌─1─┐
│ 1 │
└───┘在FROM子句后,可以使用Final修饰符,可以触发合并,但是会降低性能。
9.3 SAMPLE子句
SAMPLE子句能够实现数据采样的功能,这样查询时只返回采样数据。
使用了幂等设计,在数据不变的情况下,相同的采样规则一直返回相同的数据。
SAMPLE子句只能用于MergeTree系列引擎的数据表。
要求在CREATE TABLE时声明SAMPLE BY抽样表达式。
CREATE TABLE hits_v1 (
CounterID UInt64,
EventDate DATE,
UserID UInt64
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, intHash32(UserID))
--Sample Key声明的表达式必须也包含在主键的声明中
SAMPLE BY intHash32(UserID)例子表示按照intHash32(UserID)分布后的结果采样查询。
SAMPLE BY需要注意:
- SAMPLE BY所声明的表达式必须同时包含在主键的声明内;
- Sample Key必须是Int类型,否则虽然能创建,但是查询时会报错。
SAMPLE BY的三种用法:
1.SAMPLE factor
表示按因子系数采样,factor取值支持0 ~1之间的小数。
-- 按10%的因子采样数据:
SELECT CounterID FROM hits_v1 SAMPLE 0.1
SELECT CounterID FROM hits_v1 SAMPLE 1/10
-- 为得到近似结果,需要将最终结果放大10倍
SELECT count() * 10 FROM hits_v1 SAMPLE 0.1
-- 借助虚拟字段_sample_factor来获取采样系数更优雅。
-- _sample_factor可以返回当前查询所对应的采样系数
SELECT CounterID, _sample_factor FROM hits_v1 SAMPLE 0.1 LIMIT 2
┌─CounterID─┬─_sample_factor───┐
│ 57 │ 10 │
│ 57 │ 10 │
└────────┴─────────────┘
-- 查询语句改写为:
SELECT count() * any(_sample_factor) FROM hits_v1 SAMPLE 0.1
-- clickHouse的聚合函数any(),意思是选择第一个遇到的值2.SAMPLE rows
SAMPLE rows表示按样本数量采样。rows > 1,整数。如果大于全部数据,效果等于 rows=1(即不使用采样)。
-- 采样10000行数据,为近似范围
SELECT count() FROM hits_v1 SAMPLE 10000
┌─count()─┐
│ 9576 │
└──────┘
-- 采样数据的最小粒度是由index_granularity索引粒度决定,小于此值没有意义
-- 使用虚拟字段_sample_factor来获取当前查询所对应的采样系数
SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 100000 LIMIT 1
┌─CounterID─┬─_sample_factor─┐
│ 63 │ 13.27104 │
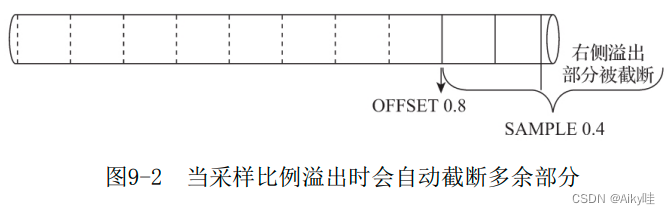
└───────┴──────────┘3.SAMPLE factor OFFSET n
表示按因子系数和偏移量采样,其中factor表示采样因子,n表示偏移多少数据后才开始采样,它们两个的取值都是0~1之间的小数 。
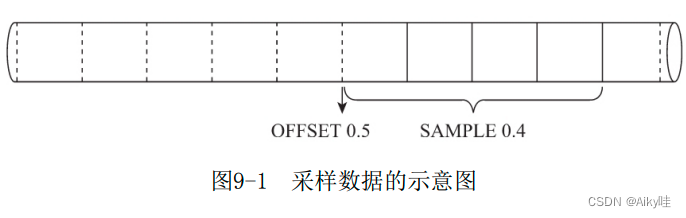
-- 偏移量为0.5并按0.4的系数采样
SELECT CounterID FROM hits_v1 SAMPLE 0.4 OFFSET 0.5
-- 这种用法支持使用十进制的表达形式,也支持虚拟字段_sample_factor:
SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 1/10 OFFSET 1/29.4 ARRAY JOIN子句
ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行。
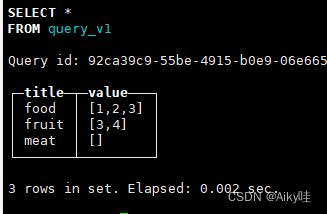
-- 构建表:
CREATE TABLE query_v1
(
title String,
value Array(UInt8)
) ENGINE = Memory
INSERT INTO query_v1 VALUES ('food', [1,2,3]), ('fruit', [3,4]), ('meat', [])
一条SELECT语句中,只能存在一个ARRAY JOIN(使用子查询除外)。目前支持INNER和LEFT两种 JOIN策略:
1.INNER ARRAY JOIN
-- ARRAY JOIN在默认情况下使用的是INNER JOIN策略
SELECT title,value FROM query_v1 ARRAY JOIN value
┌─title─┬─value─┐
│ food │ 1 │
│ food │ 2 │
│ food │ 3 │
│ fruit │ 3 │
│ fruit │ 4 │
└───────┴───────┘最终的数据基于value数组被展开成了多行,并且排除掉了空数组。
-- 为原有的数组字段添加一个别名,则能够访问展开前的数组字段
SELECT title,value,v FROM query_v1 ARRAY JOIN value AS v
┌─title─┬─value───┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
└───────┴─────────┴───┘2.LEFT ARRAY JOIN
-- 使用left 策略
SELECT title,value,v FROM query_v1 LEFT ARRAY JOIN value AS v
┌─title─┬─value───┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
│ meat │ [] │ 0 │
└───────┴─────────┴───┘
以ARRAY JOIN也支持嵌套数据类型。
CREATE TABLE query_v2
(
title String,
nest Nested(
v1 UInt32,
v2 UInt64)
) ENGINE = Log
INSERT INTO query_v2 VALUES ('food', [1,2,3], [10,20,30]), ('fruit', [4,5], [40,50]), ('meat', [], [])
SELECT title, nest.v1, nest.v2 FROM query_v2;
┌─title─┬─nest.v1─┬─nest.v2────┐
│ food │ [1,2,3] │ [10,20,30] │
│ fruit │ [4,5] │ [40,50] │
│ meat │ [] │ [] │
└───────┴─────────┴────────────┘
-- 使用嵌套列
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest;
┌─title─┬─nest.v1─┬─nest.v2─┐
│ food │ 1 │ 10 │
│ food │ 2 │ 20 │
│ food │ 3 │ 30 │
│ fruit │ 4 │ 40 │
│ fruit │ 5 │ 50 │
└───────┴─────────┴─────────┘
-- 使用嵌套列中的某个值
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest.v1;
┌─title─┬─nest.v1─┬─nest.v2────┐
│ food │ 1 │ [10,20,30] │
│ food │ 2 │ [10,20,30] │
│ food │ 3 │ [10,20,30] │
│ fruit │ 4 │ [40,50] │
│ fruit │ 5 │ [40,50] │
└───────┴─────────┴────────────┘
-- 通过别名的形式访问原始数组:
SELECT title, nest.v1, nest.v2, n.v1, n.v2 FROM query_v2 ARRAY JOIN nest as n
┌─title─┬─nest.v1─┬─nest.v2────┬─n.v1─┬─n.v2─┐
│ food │ [1,2,3] │ [10,20,30] │ 1 │ 10 │
│ food │ [1,2,3] │ [10,20,30] │ 2 │ 20 │
│ food │ [1,2,3] │ [10,20,30] │ 3 │ 30 │
│ fruit │ [4,5] │ [40,50] │ 4 │ 40 │
│ fruit │ [4,5] │ [40,50] │ 5 │ 50 │
└───────┴─────────┴────────────┴──────┴──────┘9.5 JOIN子句
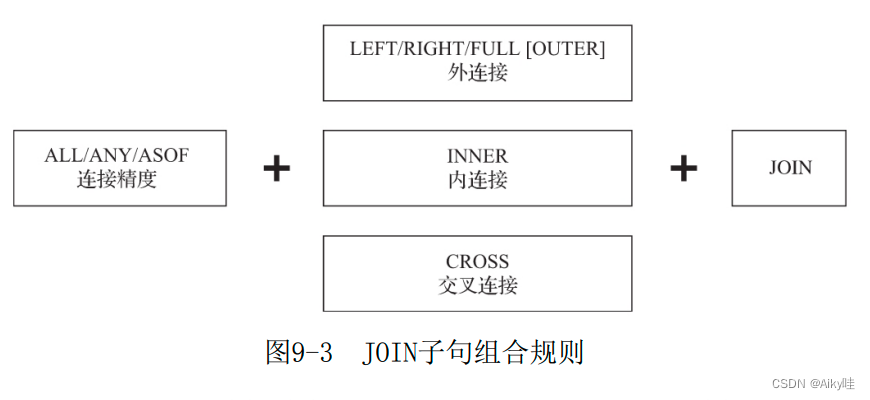
join还分为本地和远程。这里着重讲解本地查询。
目前只支持等式(EQUAL JOIN)。交叉连接(CROSS JOIN)不需要使用JOIN KEY,因为它会产生笛卡儿积。
9.5.1 连接精度
目前支持 ALL、ANY和ASOF三种类型,默认是ALL,可以通过 join_default_strictness配置参数修改默认的连接精度类型。
1.ALL
正常的join,左右join key相等的行做join。
2.ANY
左表的每行数据只匹配右表一行数据。
3.ASOF
模糊连接。允许在连接键之后追加定义一个模糊连接的匹配条件asof_column。
SELECT a.id,a.name,b.rate,a.time,b.time
FROM join_tb1 AS a
ASOF INNER JOIN join_tb2 AS b
ON a.id = b.id
AND a.time = b.time其中a.id=b.id是寻常的连接键,而紧随其后的a.time=b.time则是asof_column模糊连接条件。
等同于a.id = b.id AND a.time >= b.time。
最终返回的查询结果符合连接条件a.id=b.id AND a.time>=b.time,且仅返回了右表中第一行连接匹配的数据。
支持使用USING的简写形式。
SELECT a.id,a.name,b.rate,a.time,b.time
FROM join_tb1 AS a
ASOF INNER JOIN join_tb2 AS b
USING(id,time)USING后的time字段会被转换成asof_colum。
对于asof_colum字段的使用有两点需要注意:
- asof_colum必须是整型、浮点型和日期型这类有序序列的数据类型;
- asof_colum不能是数据表内的唯一字段,换言之,连接键(JOIN KEY)和asof_colum不能是同一个字段。
9.5.2 连接类型
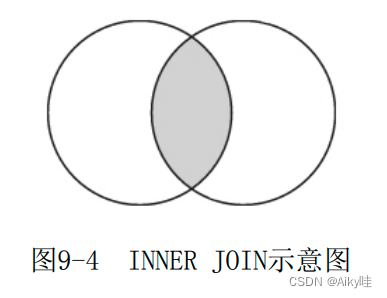
1.INNER
2.OUTER
它可以进一步细分为左外连接 (LEFT)、右外连接(RIGHT)和全外连接(FULL)三种形式。
[LEFT|RIGHT|FULL [OUTER]] ] JOIN1)left
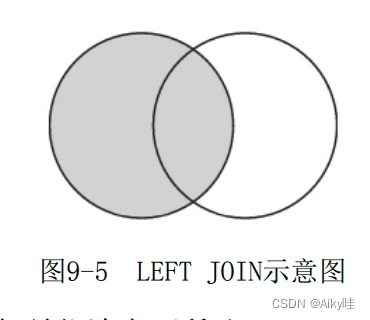
没有连接的列值由默认值补全。
2) right
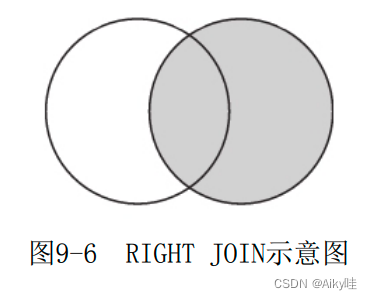
内部逻辑:
- 在内部进行类似INNER JOIN的内连接查询,在计算交集部分的同时,顺带记录右表中那些未能被连接的数据行。
- 将那些未能被连接的数据行追加到交集的尾部。
- 将追加数据中那些属于左表的列字段用默认值补全。
3)FULL
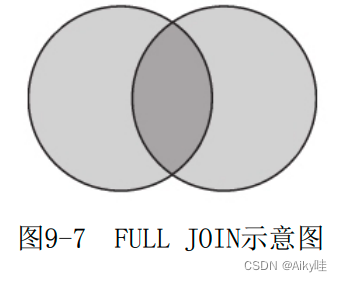
全外连接查询会返回左表与右表两个数据集合的并集。
内部逻辑:
- 会在内部进行类似LEFT JOIN的查询,在左外连接的过程中,顺带记录右表中已经被连接的数据行。
- 通过在右表中记录已被连接的数据行,得到未被连接的数据行。
- 将右表中未被连接的数据追加至结果集,并将那些属于左表中的列字段以默认值补全。
3.CROSS
返回左表与右表两个数据集合的笛卡儿积。 不需要声明JOIN KEY。
会以左表为基础,逐行与右表全集相乘。
9.5.3 多表连接
多张数据表的连接查询时,ClickHouse会将它们转为两两连接的形式。
SELECT a.id,a.name,b.rate,c.star
FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
LEFT JOIN join_tb3 AS c ON a.id = c.id会先将join_tb1与join_tb2进行内连接,之后再将它们的结果集与join_tb3左连接。
ClickHouse虽然也支持关联查询的语法,但是会自动将其转换成指定的连接查询。
- 转换为CROSS JOIN:如果查询语句中不包含WHERE条件,则会转为CROSS JOIN。
SELECT a.id,a.name,b.rate,c.star FROM join_tb1 AS a , join_tb2 AS b ,join_tb3 AS c
- 转换为INNER JOIN:如果查询语句中包含WHERE条件,则会转为INNER JOIN。
SELECT a.id,a.name,b.rate,c.star FROM join_tb1 AS a , join_tb2 AS b ,join_tb3 AS c WHERE a.id = b.id AND a.id = c.id
9.5.4 注意事项
1.关于性能
应该遵循左大右小的原则。
因为无论使用哪种连接方式,右表都会被全部加载到内存中与左表进行比较。
JOIN查询目前没有缓存的支持。
即便是连续执行相同的SQL,也都会生成一次全新的执行计划 。
如果是在大量维度属性补全的查询场景中,则建议使用字典代替JOIN查询 。
因为在进行多表的连接查询时,查询会转换成两两 连接的形式,这种“滚雪球”式的查询很可能带来性能问题。
2.关于空值策略与简写形式
连接查询的空值 (那些未被连接的数据)是由默认值填充的,这与其他数据库所采取 的策略不同(由Null填充)。
通过 join_use_nulls参数指定的,默认为0。当参数值为0时,空值由数据类型的默认值填充;而当参数值为1时,空值由Null填充。
JOIN KEY支持简化写法,当数据表的连接字段名称相同时,可以 使用USING语法简写。
SELECT a.id,a.name,b.rate
FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
-- 使用USING简写
SELECT id,name,rate FROM join_tb1 INNER JOIN join_tb2 USING id9.6 WHERE与PREWHERE子句
WHERE子句是一条查询语句能否启用索引的判断依据(前提是表引擎支持索引特性)。
WHERE表达式中包含主键,那么能够使用索引过滤数据区间。
【这里应该是包含主键前缀】
PREWHERE可以看作对WHERE的一种优化。不同之处在于,使用PREWHERE时,首先只会读取PREWHERE指定的列字段数据,用于数据过滤的条件判断。待数据过滤之后再读取SELECT声明的列字段以补全其余属性。
-- 执行set optimize_move_to_prewhere=0关闭PREWHERE自动优化
SELECT WatchID,Title,GoodEvent FROM hits_v1 WHERE JavaEnable = 1
981110 rows in set. Elapsed: 0.095 sec. Processed 1.34 million rows, 124.65 MB (639.61 thousand rows/s., 59.50 MB
-- 总共处理了134万行数据,其数据大小为 124.65 MB
-- 使用prewhere
SELECT WatchID,Title,GoodEvent FROM hits_v1 PREWHERE JavaEnable = 1
981110 rows in set. Elapsed: 0.080 sec. Processed 1.34 million rows, 91.61 MB (740.98 thousand rows/s., 50.66 MB/
-- 数据大小从124.65 MB减少至91.61 MB观察两次查询的执行计划。
--WHERE查询
Union
Expression × 2
Expression
Filter
MergeTreeThread
--PREWHERE查询
Union
Expression × 2
Expression
MergeTreeThreadPREWHERE查询省去了一次Filter操作。
ClickHouse实现了自动优化的功能,会在条件合适的情况下将WHERE替换为PREWHERE。
optimize_move_to_prewhere设置为1(默认值为1,即开启状态)
9.7 GROUP BY子句
如果SELECT后只声明了聚合函数,则可以省略GROUP BY关键字 。
--如果只有聚合函数,可以省略GROUP BY
SELECT SUM(data_compressed_bytes) AS compressed ,
SUM(data_uncompressed_bytes) AS uncompressed
FROM system.parts
--除了聚合函数外,只能使用聚合key中包含的table字段
SELECT table,COUNT() FROM system.parts GROUP BY table
--使用聚合key中未声明的rows字段,则会报错
SELECT table,COUNT(),rows FROM system.parts GROUP BY table
--但是在某些场合下,可以借助any、max和min等聚合函数访问聚合键之外的列字段:
SELECT table,COUNT(),any(rows) FROM system.parts GROUP BY table当聚合查询内的数据存在NULL值时,ClickHouse会将NULL作为 NULL=NULL的特定值处理。
即,所有的NULL值都被聚合到了NULL分组。
聚合查询目前还能配合WITH ROLLUP、WITH CUBE和WITH TOTALS三种修饰符获取额外的汇总信息。
9.7.1 WITH ROLLUP
ROLLUP能够按照聚合键从右向左上卷数据,基于聚合函数依次生成分组小计和总计。
如果设聚合键的个数为n,则最终会生成小计的个数为n+1。
-- 例如
SELECT table, name, SUM(bytes_on_disk) FROM system.parts
GROUP BY table,name
WITH ROLLUP
ORDER BY table
┌─table───────────────────┬─name─────────────────────┬─sum(bytes_on_disk)─┐
│ │ │ 440833384 │
│ asynchronous_metric_log │ │ 384103205 │
│ asynchronous_metric_log │ 20220622_7337_7337_0 │ 6525 │
│ asynchronous_metric_log │ 20220624_12731_13060_94 │ 2594507 │
│ asynchronous_metric_log │ 20220706_46580_46580_0 │ 10831 │
│ asynchronous_metric_log │ 20220706_46418_46569_45 │ 1192486 │
│ asynchronous_metric_log │ 20220624_10219_12730_100 │ 19988721 │
...
│ asynchronous_metric_log │ 20220706_46576_46576_0 │ 10626 │
│ asynchronous_metric_log │ 20220620_1_1185_99 │ 9201998 │
│ asynchronous_metric_log │ 20220704_41423_41816_93 │ 3093175 │
│ metric_log │ │ 56468784 │
│ metric_log │ 20220630_29867_30376_103 │ 581564 │
│ metric_log │ 20220706_46562_46562_0 │ 20668 │
│ metric_log │ 20220703_36137_38513_277 │ 2759474 │
...
│ metric_log │ 20220706_46538_46558_5 │ 44010 │
│ metric_log │ 20220702_35650_36136_99 │ 573225 │
│ metric_log │ 20220628_21737_24418_276 │ 3138365 │
│ metric_log │ 20220706_46573_46573_0 │ 20720 │
│ part_log │ │ 4303 │
│ part_log │ 20220627_1_11_3 │ 2386 │
│ part_log │ 20220705_12_18_2 │ 1917 │
│ partition_v1 │ │ 232 │
│ partition_v1 │ 201906_2_2_0_3 │ 232 │
│ query_log │ │ 135372 │
│ query_log │ 20220706_98_106_2 │ 9523 │
│ query_log │ 20220622_8_12_1 │ 10512 │
...可以看到在最终返回的结果中,附加返回了显示名称为空的小计汇总行,包括所有表分区磁盘大小的汇总合计以及每张table内所有分区大小的合计信息。
9.7.2 WITH CUBE
CUBE会像立方体模型一样,基于聚合键之间所有的组合生成小计 信息。如果设聚合键的个数为n,则最终小计组合的个数为2的n次方。
9.7.3 WITH TOTALS
使用TOTALS修饰符后,会基于聚合函数对所有数据进行总计,例如执行下面的语句:
SELECT database, SUM(bytes_on_disk),COUNT(table) FROM system.parts
GROUP BY database WITH TOTALS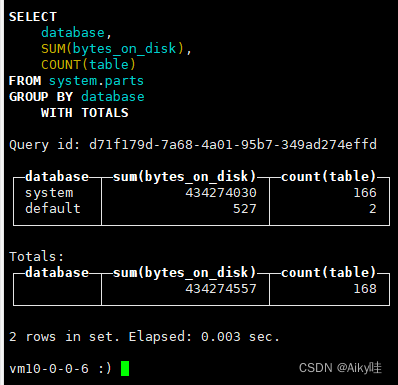
其结果附加了一行Totals汇总合计,这一结果是基于聚合函数对 所有数据聚合总计的结果。
9.8 HAVING子句
HAVING子句需要与GROUP BY同时出现,不能单独使用。
它能够在聚合计算之后实现二次过滤数据。
SELECT COUNT() FROM system.parts GROUP BY table
--执行计划
Expression
Expression
Aggregating
Concat
Expression
One
SELECT COUNT() FROM system.parts GROUP BY table HAVING table = 'query_v3'
--执行计划
Expression
Expression
Filter
Aggregating
Concat
Expression
One发现HAVING的本质是在聚合之后增加了Filter过滤动作。
-- 通过嵌套的WHERE也能达到相同的目的
SELECT COUNT() FROM
(SELECT table FROM system.parts WHERE table = 'query_v3')
GROUP BY table
--执行计划
Expression
Expression
Aggregating
Concat
Expression
Expression
Expression
Filter
One相比使用HAVING,嵌套WHERE的执行计划效率更高。因为WHERE等同于使用了谓词下推,在聚合之前就进行了数据过滤,从而减少了后续聚合时需要处理的数据量。
但是如果需要按照聚 合值进行过滤,就必须借助HAVING实现。
9.9 ORDER BY子句
在MergeTree中指定ORDER BY 后,数据在各个分区内会按照其定义的规则排序,这是一种分区内的局部排序。
如果需要数据总是能够按照期望的顺序返回,就需要借助ORDER BY子句来指定全局顺序。
-- 两条SQL等价
--按照v1升序、v2降序排序
SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1 ASC, v2 DESC
SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1, v2 DESC
对于数据中NULL值的排序,目前ClickHouse拥有NULL值最后和 NULL值优先两种策略,可以通过NULLS修饰符进行设置。
NULL值排在最后,这也是默认行为,修饰符可以省略。
-- 顺序是value -> NaN -> NULL
WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS LAST
┌───v1─┐
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
│ nan │
│ nan │
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
└──────┘
-- 顺序是NULL -> NaN -> value
WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS FIRST
┌───v1─┐
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
│ nan │
│ nan │
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
└──────┘9.10 LIMIT BY子句
LIMIT BY子句和大家常见的LIMIT所有不同,它运行于ORDER BY之 后和LIMIT之前,能够按照指定分组,最多返回前n行数据(如果数据少于n行,则按实际数量返回),常用于TOP N的查询场景。
-- limit n by
-- 基于数据库和数据表分组的情况下,查询返回数据占磁盘空间最大的前3张表
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY database ,bytes DESC
LIMIT 3 BY database
┌─database─┬─table───────────────────┬────bytes─┐
│ default │ ttl_table_v1 │ 295 │
│ default │ partition_v1 │ 232 │
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
└──────────┴─────────────────────────┴──────────┘
LIMIT BY也支持跳过OFFSET偏移量。
LIMIT n OFFSET y BY express
--简写
LIMIT y,n BY express9.11 LIMIT子句
LIMIT子句用于返回指定的前n行数据,常用于分页场景,
LIMIT子句可以和LIMIT BY一同使用。
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY bytes DESC
LIMIT 3 BY database
┌─database─┬─table───────────────────┬────bytes─┐
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
│ default │ ttl_table_v1 │ 295 │
│ default │ partition_v1 │ 232 │
└──────────┴─────────────────────────┴──────────┘
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY bytes DESC
LIMIT 3 BY database
LIMIT 4
┌─database─┬─table───────────────────┬────bytes─┐
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
│ default │ ttl_table_v1 │ 295 │
└──────────┴─────────────────────────┴──────────┘使用LIMIT子句时有一点需要注意,如果数据跨越了多个分区,在没有使用ORDER BY指定全局顺序的情况下,每次LIMIT查询所返回的数据有可能不同。
9.12 SELECT子句
在其他子句执行之后,SELECT会将选取的字段或表达式作用于每行数据之上。
ClickHouse还为特定场景提供了一种基于正则查询的形式。
-- 查询会返回名称以字母n开头和包含字母p的列字段:
SELECT COLUMNS('^n'), COLUMNS('p') FROM system.databases
┌─name──────┬─data_path──────────────────────────┬─metadata_path───────────────────────────────────────────────────────────────┐
│ aikytest1 │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/92a/92a393fc-4273-4575-92a3-93fc42737575/ │
│ default │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/500/50049df5-cb66-4498-9004-9df5cb66f498/ │
│ system │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/63e/63eb7fce-251d-4419-a3eb-7fce251db419/ │
└───────────┴────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────┘9.13 DISTINCT子句
DISTINCT子句能够去除重复数据。
DISTINCT也能够与GROUP BY同时使用, 所以它们是互补而不是互斥的关系。
当DISTINCT与 ORDER BY同时使用时,其执行的优先级是先DISTINCT后ORDER BY。
9.14 UNION ALL子句
UNION ALL子句能够联合左右两边的两组子查询,将结果一并返回。
UNION ALL两侧的子查询需要:
- 列字段的数量必须相同;
- 列字段的数据类型必须相同或 相兼容;
- 列字段的名称可以不同,查询结果中的列名会以左边 的子查询为准。
目前ClickHouse只支持UNION ALL 子句。
想得到UNION DISTINCT子句的效果,可以使用嵌套查询来变相实现。
9.15 查看SQL执行计划
【这一章过期了,现在clickhouse已经可以支持explain查询sql执行计划】
9.16 本章小结
各种查询子句的用法。
只介绍了ClickHouse的本地查询部分,下一章将进一步介绍与ClickHouse分布式相关的知识。
边栏推荐
- Summary of the mean value theorem of higher numbers
- 爬虫练习题(三)
- Simple case of SSM framework
- Getting started with DES encryption
- 1.AVL树:左右旋-bite
- Talk about mvcc multi version concurrency controller?
- Egr-20uscm ground fault relay
- AI人脸编辑让Lena微笑
- 消息队列:如何确保消息不会丢失
- How Alibaba cloud's DPCA architecture works | popular science diagram
猜你喜欢
![[论文阅读] Semi-supervised Left Atrium Segmentation with Mutual Consistency Training](/img/d6/e6db0d76e81e49a83a30f8c1832f09.png)
[论文阅读] Semi-supervised Left Atrium Segmentation with Mutual Consistency Training
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
Hcip seventh operation
Web Authentication API兼容版本信息

4. Object mapping Mapster
拼多多商品详情接口、拼多多商品基本信息、拼多多商品属性接口
随机生成session_id

Egr-20uscm ground fault relay
Use, configuration and points for attention of network layer protocol (taking QoS as an example) when using OPNET for network simulation

毕业之后才知道的——知网查重原理以及降重举例
随机推荐
Educational Codeforces Round 22 B. The Golden Age
Photo selector collectionview
How digitalization affects workflow automation
导航栏根据路由变换颜色
Taobao store release API interface (New), Taobao oauth2.0 store commodity API interface, Taobao commodity release API interface, Taobao commodity launch API interface, a complete set of launch store i
Preliminary practice of niuke.com (9)
Cve-2021-3156 vulnerability recurrence notes
JVM (19) -- bytecode and class loading (4) -- talk about class loader again
async / await
SQL query: subtract the previous row from the next row and make corresponding calculations
Leetcode: maximum number of "balloons"
SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
How Alibaba cloud's DPCA architecture works | popular science diagram
Digital innovation driven guide
Jhok-zbl1 leakage relay
ForkJoin最全详解(从原理设计到使用图解)
[reading of the paper] a multi branch hybrid transformer network for channel terminal cell segmentation
Use, configuration and points for attention of network layer protocol (taking QoS as an example) when using OPNET for network simulation
Paper reading [open book video captioning with retrieve copy generate network]
4. Object mapping Mapster