当前位置:网站首页>常用消息队列有哪些?
常用消息队列有哪些?
2022-07-06 23:41:00 【勤天】
目录
一、常用消息队列介绍
常见的MQ产品包括Kafka、ActiveMQ、RabbitMQ、RocketMQ

1、ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。
ActiveMQ特性如下:
⒈ 多种语言和协议编写客户端。语言: Java,C,C++,C#,Ruby,Perl,Python,PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
⒉ 完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
⒊ 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性
⒋ 通过了常见J2EE服务器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
⒌ 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
⒍ 支持通过JDBC和journal提供高速的消息持久化
⒎ 从设计上保证了高性能的集群,客户端-服务器,点对点
⒏ 支持Ajax
⒐ 支持与Axis的整合
⒑ 可以很容易得调用内嵌JMS provider,进行测试
2、RabbitMQ
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是AMQP(高级消息队列协议)的标准实现。支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗
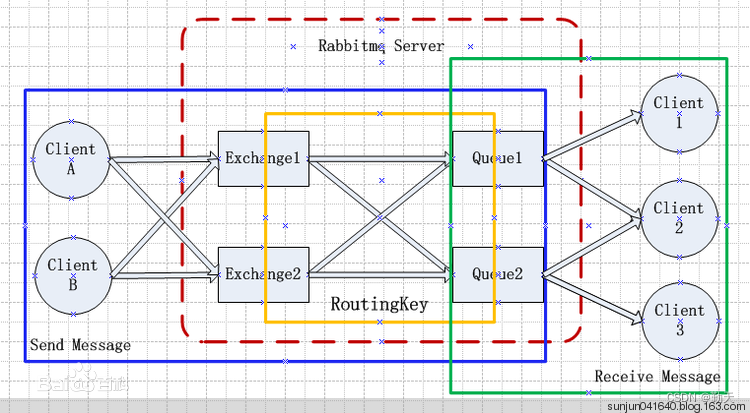
几个重要概念:
- Broker:简单来说就是消息队列服务器实体。
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- producer:消息生产者,就是投递消息的程序。
- consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程,如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
3、ZeroMQ
号称史上最快的消息队列,它实际类似于Socket的一系列接口,他跟Socket的区别是:普通的socket是端到端的(1:1的关系),而ZMQ却是可以N:M 的关系,人们对BSD套接字的了解较多的是点对点的连接,点对点连接需要显式地建立连接、销毁连接、选择协议(TCP/UDP)和处理错误等,而ZMQ屏蔽了这些细节,让你的网络编程更为简单。ZMQ用于node与node间的通信,node可以是主机或者是进程。
引用官方的说法: “ZMQ(以下ZeroMQ简称ZMQ)是一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ的明确目标是“成为标准网络协议栈的一部分,之后进入Linux内核”。现在还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD套接字之上的一 层封装。ZMQ让编写高性能网络应用程序极为简单和有趣。”
特点是:
- 高性能,非持久化;
- 跨平台:支持Linux、Windows、OS X等。
- 多语言支持; C、C++、Java、.NET、Python等30多种开发语言。
- 可单独部署或集成到应用中使用;
- 可作为Socket通信库使用。
与RabbitMQ相比,ZMQ并不像是一个传统意义上的消息队列服务器,事实上,它也根本不是一个服务器,更像一个底层的网络通讯库,在Socket API之上做了一层封装,将网络通讯、进程通讯和线程通讯抽象为统一的API接口。支持“Request-Reply “,”Publisher-Subscriber“,”Parallel Pipeline”三种基本模型和扩展模型。
ZeroMQ高性能设计要点:
1、无锁的队列模型
对于跨线程间的交互(用户端和session)之间的数据交换通道pipe,采用无锁的队列算法CAS;在pipe两端注册有异步事件,在读或者写消息到pipe的时,会自动触发读写事件。
2、批量处理的算法
对于传统的消息处理,每个消息在发送和接收的时候,都需要系统的调用,这样对于大量的消息,系统的开销比较大,zeroMQ对于批量的消息,进行了适应性的优化,可以批量的接收和发送消息。
3、多核下的线程绑定,无须CPU切换
区别于传统的多线程并发模式,信号量或者临界区, zeroMQ充分利用多核的优势,每个核绑定运行一个工作者线程,避免多线程之间的CPU切换开销。
4、Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。(文件追加的方式写入数据,过期的数据定期删除)
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
Kafka相关概念:
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer:负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用。
二、如何选择消息队列
作为一个程序员,相信你一定听过“没有银弹”这个说法,这里面的银弹是指能轻松杀死狼人、用白银做的子弹,什么意思呢?我对这句话的理解是说,在软件工程中,不存在像“银弹”这样可以解决一切问题的设计、架构或软件,每一个软件系统,它都是独一无二的,你不可能用一套方法去解决所有的问题。
在消息队列的技术选型这个问题上,也是同样的道理。并不存在说,哪个消息队列就是“最好的”。常用的这几个消息队列,每一个产品都有自己的优势和劣势,你需要根据现有系统的情况,选择最适合你的那款产品。
1、选择消息队列产品的基本标准
虽然这些消息队列产品在功能和特性方面各有优劣,但我们在选择的时候要有一个最低标准,保证入选的产品至少是及格的。
首先,必须是开源的产品,这个非常重要。开源意味着,如果有一天你使用的消息队列遇到了一个影响你系统业务的 Bug,你至少还有机会通过修改源代码来迅速修复或规避这个 Bug,解决你的系统火烧眉毛的问题,而不是束手无策地等待开发者不一定什么时候发布的下一个版本来解决。
其次,这个产品必须是近年来比较流行并且有一定社区活跃度的产品。流行的好处是,只要你的使用场景不太冷门,你遇到 Bug 的概率会非常低,因为大部分你可能遇到的 Bug,其他人早就遇到并且修复了。你在使用过程中遇到的一些问题,也比较容易在网上搜索到类似的问题,然后很快的找到解决方案。
还有一个优势就是,流行的产品与周边生态系统会有一个比较好的集成和兼容,比如,Kafka 和 Flink 就有比较好的兼容性,Flink 内置了 Kafka 的 Data Source,使用 Kafka 就很容易作为 Flink 的数据源开发流计算应用,如果你用一个比较小众的消息队列产品,在进行流计算的时候,你就不得不自己开发一个 Flink 的 Data Source。
最后,作为一款及格的消息队列产品,必须具备的几个特性包括:
- 消息的可靠传递:确保不丢消息;
- Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;
- 性能:具备足够好的性能,能满足绝大多数场景的性能要求。
2、可供选择的消息队列产品
1)RabbitMQ
首先,我们说一下老牌儿消息队列 RabbitMQ,俗称兔子 MQ。RabbitMQ 是使用一种比较小众的编程语言:Erlang 语言编写的,它最早是为电信行业系统之间的可靠通信设计的,也是少数几个支持 AMQP 协议的消息队列之一。
RabbitMQ 就像它的名字中的兔子一样:轻量级、迅捷,它的 Slogan,也就是宣传口号,也很明确地表明了 RabbitMQ 的特点:Messaging that just works,“开箱即用的消息队列”。也就是说,RabbitMQ 是一个相当轻量级的消息队列,非常容易部署和使用。
另外 RabbitMQ 还号称是世界上使用最广泛的开源消息队列,是不是真的使用率世界第一,我们没有办法统计,但至少是“最流行的消息中间之一”,这是没有问题的。
RabbitMQ 一个比较有特色的功能是支持非常灵活的路由配置,和其他消息队列不同的是,它在生产者(Producer)和队列(Queue)之间增加了一个 Exchange 模块,你可以理解为交换机。
这个 Exchange 模块的作用和交换机也非常相似,根据配置的路由规则将生产者发出的消息分发到不同的队列中。路由的规则也非常灵活,甚至你可以自己来实现路由规则。基于这个 Exchange,可以产生很多的玩儿法,如果你正好需要这个功能,RabbitMQ 是个不错的选择。
RabbitMQ 的客户端支持的编程语言大概是所有消息队列中最多的,如果你的系统是用某种冷门语言开发的,那你多半可以找到对应的 RabbitMQ 客户端。
缺点:
第一个问题是,RabbitMQ 对消息堆积的支持并不好,在它的设计理念里面,消息队列是一个管道,大量的消息积压是一种不正常的情况,应当尽量去避免。当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。
第二个问题是,RabbitMQ 的性能是我们介绍的这几个消息队列中最差的,根据官方给出的测试数据综合我们日常使用的经验,依据硬件配置的不同,它大概每秒钟可以处理几万到十几万条消息。其实,这个性能也足够支撑绝大多数的应用场景了,不过,如果你的应用对消息队列的性能要求非常高,那不要选择 RabbitMQ。
最后一个问题是 RabbitMQ 使用的编程语言 Erlang,这个编程语言不仅是非常小众的语言,更麻烦的是,这个语言的学习曲线非常陡峭。大多数流行的编程语言,比如 Java、C/C++、Python 和 JavaScript,虽然语法、特性有很多的不同,但它们基本的体系结构都是一样的,你只精通一种语言,也很容易学习其他的语言,短时间内即使做不到精通,但至少能达到“会用”的水平。
2) RocketMQ
RocketMQ 是阿里巴巴在 2012 年开源的消息队列产品,后来捐赠给 Apache 软件基金会,2017 正式毕业,成为 Apache 的顶级项目。阿里内部也是使用 RocketMQ 作为支撑其业务的消息队列,经历过多次“双十一”考验,它的性能、稳定性和可靠性都是值得信赖的。作为优秀的国产消息队列,近年来越来越多的被国内众多大厂使用。
我在总结 RocketMQ 的特点时,发现很难找出 RocketMQ 有什么特别让我印象深刻的特点,也很难找到它有什么缺点。
RocketMQ 就像一个品学兼优的好学生,有着不错的性能,稳定性和可靠性,具备一个现代的消息队列应该有的几乎全部功能和特性,并且它还在持续的成长中。
RocketMQ 有非常活跃的中文社区,大多数问题你都可以找到中文的答案,也许会成为你选择它的一个原因。另外,RocketMQ 使用 Java 语言开发,它的贡献者大多数都是中国人,源代码相对也比较容易读懂,你很容易对 RocketMQ 进行扩展或者二次开发。
RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。
RocketMQ 的性能比 RabbitMQ 要高一个数量级,每秒钟大概能处理几十万条消息。
缺点:
RocketMQ 的一个劣势是,作为国产的消息队列,相比国外的比较流行的同类产品,在国际上还没有那么流行,与周边生态系统的集成和兼容程度要略逊一筹。
3)Kafka
Kafka 最早是由 LinkedIn 开发,目前也是 Apache 的顶级项目。Kafka 最初的设计目的是用于处理海量的日志。
在早期的版本中,为了获得极致的性能,在设计方面做了很多的牺牲,比如不保证消息的可靠性,可能会丢失消息,也不支持集群,功能上也比较简陋,这些牺牲对于处理海量日志这个特定的场景都是可以接受的。这个时期的 Kafka 甚至不能称之为一个合格的消息队列。
但是,请注意,重点一般都在后面。随后的几年 Kafka 逐步补齐了这些短板,你在网上搜到的很多消息队列的对比文章还在说 Kafka 不可靠,其实这种说法早已经过时了。当下的 Kafka 已经发展为一个非常成熟的消息队列产品,无论在数据可靠性、稳定性和功能特性等方面都可以满足绝大多数场景的需求。
Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所有的相关开源软件系统都会优先支持 Kafka。
Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。Kafka 的性能,尤其是异步收发的性能,是三者中最好的,但与 RocketMQ 并没有量级上的差异,大约每秒钟可以处理几十万条消息。
我曾经使用配置比较好的服务器对 Kafka 进行过压测,在有足够的客户端并发进行异步批量发送,并且开启压缩的情况下,Kafka 的极限处理能力可以超过每秒 2000 万条消息。
缺点:
但是 Kafka 这种异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发送,在它的 Broker 中,很多地方都会使用这种“先攒一波再一起处理”的设计。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。所以,Kafka 不太适合在线业务场景。
3、第二梯队的消息队列
除了上面给你介绍的三大消息队列之外,还有几个第二梯队的产品,我个人的观点是,这些产品之所以没那么流行,或多或少都有着比较明显的短板,不推荐使用。在这儿呢,我简单介绍一下,纯当丰富你的知识广度。
先说 ActiveMQ,ActiveMQ 是最老牌的开源消息队列,是十年前唯一可供选择的开源消息队列,目前已进入老年期,社区不活跃。无论是功能还是性能方面,ActiveMQ 都与现代的消息队列存在明显的差距,它存在的意义仅限于兼容那些还在用的爷爷辈儿的系统。
接下来说说 ZeroMQ,严格来说 ZeroMQ 并不能称之为一个消息队列,而是一个基于消息队列的多线程网络库,如果你的需求是将消息队列的功能集成到你的系统进程中,可以考虑使用 ZeroMQ。
最后说一下 Pulsar,很多人可能都没听说过这个产品,Pulsar 是一个新兴的开源消息队列产品,最早是由 Yahoo 开发,目前处于成长期,流行度和成熟度相对没有那么高。与其他消息队列最大的不同是,Pulsar 采用存储和计算分离的设计,我个人非常喜欢这种设计,它有可能会引领未来消息队列的一个发展方向,建议你持续关注这个项目。
4、总结
在了解了上面这些开源消息队列各自的特点和优劣势后,我相信你对于消息队列的选择已经可以做到心中有数了。我也总结了几条选择的建议供你参考。
1)如果说,消息队列并不是你将要构建系统的主角之一,你对消息队列功能和性能都没有很高的要求,只需要一个开箱即用易于维护的产品,我建议你使用 RabbitMQ。
2)如果你的系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,那 RocketMQ 的低延迟和金融级的稳定性是你需要的。
3)如果你需要处理海量的消息,像收集日志、监控信息或是前端的埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合你的消息队列。
如果我说的这些场景和你的场景都不符合,你看了我之前介绍的这些消息队列的特点后,还是不知道如何选择,那就选你最熟悉的吧,毕竟这些产品都能满足大多数应用场景,使用熟悉的产品还可以快速上手不是?
边栏推荐
- DJ-ZBS2漏电继电器
- 设f(x)=∑x^n/n^2,证明f(x)+f(1-x)+lnxln(1-x)=∑1/n^2
- 淘宝商品详情页API接口、淘宝商品列表API接口,淘宝商品销量API接口,淘宝APP详情API接口,淘宝详情API接口
- 张平安:加快云上数字创新,共建产业智慧生态
- Leetcode (46) - Full Permutation
- Simulate thread communication
- Jhok-zbl1 leakage relay
- Record a pressure measurement experience summary
- 消息队列:消息积压如何处理?
- Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
猜你喜欢
K6EL-100漏电继电器

JVM (XX) -- performance monitoring and tuning (I) -- Overview
一条 update 语句的生命经历
Leetcode 1189 maximum number of "balloons" [map] the leetcode road of heroding
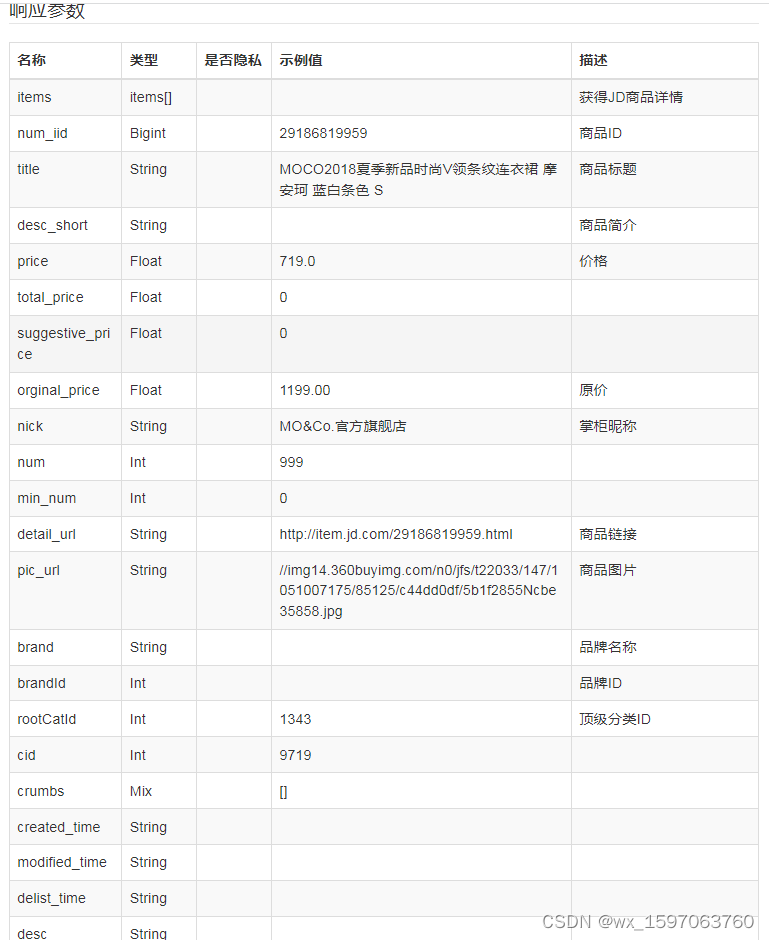
JD commodity details page API interface, JD commodity sales API interface, JD commodity list API interface, JD app details API interface, JD details API interface, JD SKU information interface
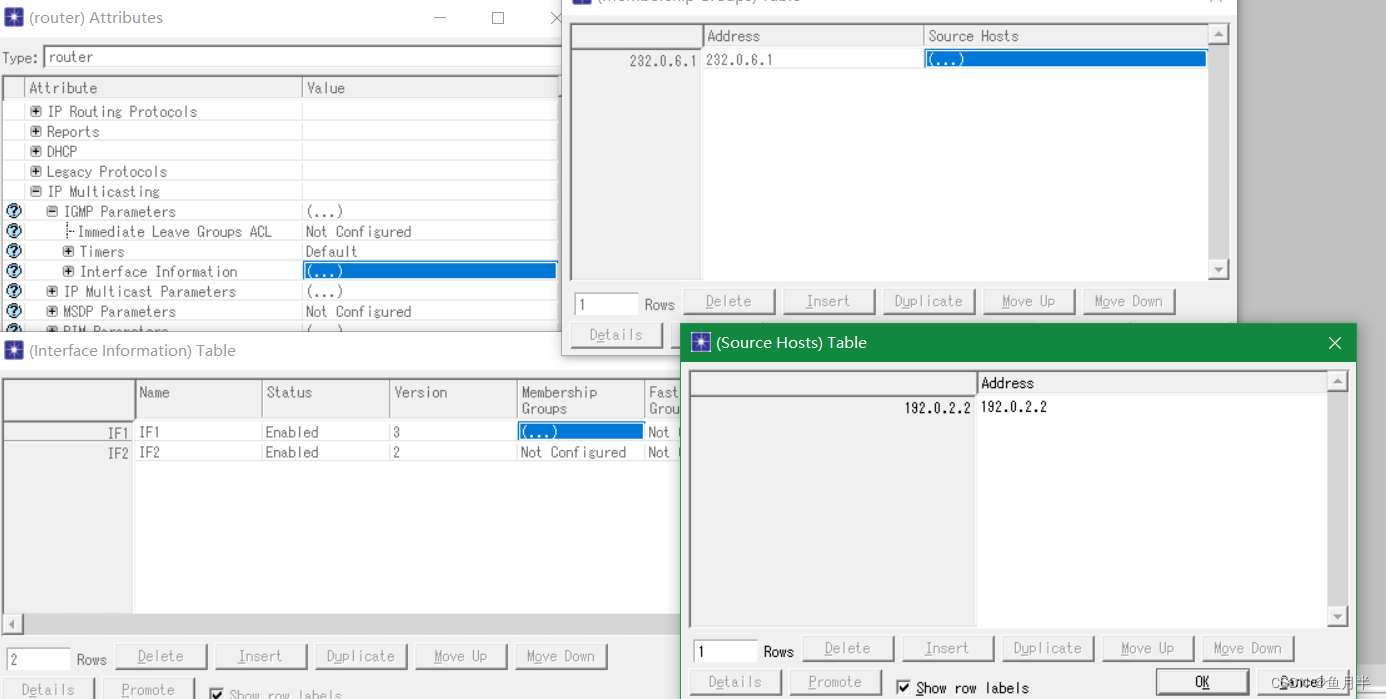
Design, configuration and points for attention of network specified source multicast (SSM) simulation using OPNET

Common skills and understanding of SQL optimization

在米家、欧瑞博、苹果HomeKit趋势下,智汀如何从中脱颖而出?
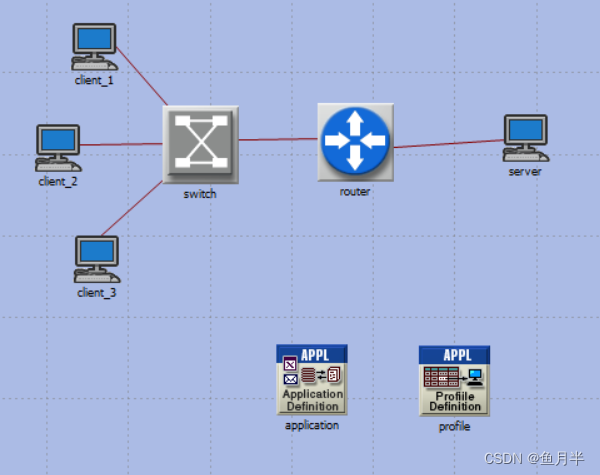
Design, configuration and points for attention of network unicast (one server, multiple clients) simulation using OPNET

Digital innovation driven guide
随机推荐
As we media, what websites are there to download video clips for free?
Digital innovation driven guide
[论文阅读] A Multi-branch Hybrid Transformer Network for Corneal Endothelial Cell Segmentation
淘宝商品详情页API接口、淘宝商品列表API接口,淘宝商品销量API接口,淘宝APP详情API接口,淘宝详情API接口
Taobao Commodity details page API interface, Taobao Commodity List API interface, Taobao Commodity sales API interface, Taobao app details API interface, Taobao details API interface
利用OPNET进行网络指定源组播(SSM)仿真的设计、配置及注意点
Dj-zbs2 leakage relay
利用OPNET进行网络任意源组播(ASM)仿真的设计、配置及注意点
Vector and class copy constructors
Leetcode: maximum number of "balloons"
基于 hugging face 预训练模型的实体识别智能标注方案:生成doccano要求json格式
DJ-ZBS2漏电继电器
When deleting a file, the prompt "the length of the source file name is greater than the length supported by the system" cannot be deleted. Solution
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
Leetcode (417) -- Pacific Atlantic current problem
做自媒体视频剪辑,专业的人会怎么寻找背景音乐素材?
How digitalization affects workflow automation
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
导航栏根据路由变换颜色
4. Object mapping Mapster