当前位置:网站首页>Reading notes of Clickhouse principle analysis and Application Practice (6)
Reading notes of Clickhouse principle analysis and Application Practice (6)
2022-07-07 05:49:00 【Aiky WOW】
Begin to learn 《ClickHouse Principle analysis and application practice 》, Write a blog and take reading notes .
The whole content of this article comes from the content of the book , Personal refining .

The first 7 Chapter - The first 8 Chapter :
The first 9 Chapter Data query
In a real production environment , In most scenarios , Should avoid using SELECT * Form to query data , Because wildcards * For column storage ClickHouse It doesn't do any good .
ClickHouse The currently supported query clauses are as follows :
[WITH expr |(subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]] ] JOIN (subquery)|table ON|USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]The query clause wrapped in square brackets indicates that it is optional , Only SELECT Clause is necessary .
9.1 WITH Clause
ClickHouse Support CTE(Common Table Expression, Common table expressions ), To enhance the expression of query statements . For example, the following functions are nested :
SELECT pow(pow(2, 2), 3)Using CTE After the form :
WITH pow(2, 2) AS a SELECT pow(a, 3)CTE adopt WITH Clause means , Currently, the following four usages are supported .
1. Defining variables
You can define variables , These variables can be accessed directly in subsequent query clauses .
WITH 10 AS start
SELECT number FROM system.numbers
WHERE number > start
LIMIT 5
┌number─┐
│ 11 │
│ 12 │
│ 13 │
│ 14 │
│ 15 │
└─────┘
2. Call function
You can visit SELECT Column fields in clause , And call the function for further processing .
WITH SUM(data_uncompressed_bytes) AS bytes
SELECT database , formatReadableSize(bytes) AS format FROM system.columns
GROUP BY database
ORDER BY bytes DESC
┌─database────┬─format───┐
│ datasets │ 12.12 GiB │
│ default │ 1.87 GiB │
│ system │ 1.10 MiB │
│ dictionaries │ 0.00 B │
└─────────┴───────┘In the example ,data_uncompressed_bytes After summing with the aggregate function , Followed by SELECT Clause is formatted .
3. Define subqueries
Sub queries can be defined .
WITH (
SELECT SUM(data_uncompressed_bytes) FROM system.columns
) AS total_bytes
SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.columns
GROUP BY database
ORDER BY database_disk_usage DESC
┌─database────┬──database_disk_usage─┐
│ datasets │ 85.15608638238845 │
│ default │ 13.15591656190217 │
│ │ │
│ system │ 0.007523354055850406 │
│ dictionaries │ 0 │
└──────────┴──────────────┘WITH Use subquery statements , Only one row of data can be returned , If the data in the result set is larger than one row, an exception will be thrown .
4. Reuse... In subqueries WITH
Can be nested in subqueries WITH Clause
WITH (
round(database_disk_usage)
) AS database_disk_usage_v1
SELECT database,database_disk_usage, database_disk_usage_v1
FROM (
-- nesting
WITH (
SELECT SUM(data_uncompressed_bytes) FROM system.columns
) AS total_bytes
SELECT database , (SUM(data_uncompressed_bytes) / total_bytes) * 100 AS database_disk_usage
FROM system.colum
GROUP BY database
ORDER BY database_disk_usage DESC
)
┌─database────┬───database_disk_usage─┬─database_disk_usage_v1───┐
│ datasets │ 85.15608638238845 │ 85 │
│ default │ 13.15591656190217 │ 13 │
│ system │ 0.007523354055850406 │ 0 │
└─────────┴───────────────┴─────────────────┘9.2 FROM Clause
Three forms are supported :
- Get data from the data table .
- Get data from subquery .
- Get data from table function .( such as SELECT number FROM numbers(5))
FROM Keywords can be omitted , At this time, data will be fetched from the virtual table . stay ClickHouse in , There is no common in database DUAL Virtual table , In its place system.one.
-- The following two queries are equivalent
SELECT 1
SELECT 1 FROM system.one
┌─1─┐
│ 1 │
└───┘stay FROM After clause , have access to Final Modifier , Can trigger merge , But it reduces performance .
9.3 SAMPLE Clause
SAMPLE Clause can realize the function of data sampling , In this way, only sampling data is returned during query .
Idempotent design is used , In the case of constant data , The same sampling rule always returns the same data .
SAMPLE Clause can only be used for MergeTree Data table of series engine .
Ask for in CREATE TABLE Declare that SAMPLE BY Sampling expression .
CREATE TABLE hits_v1 (
CounterID UInt64,
EventDate DATE,
UserID UInt64
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, intHash32(UserID))
--Sample Key The declared expression must also be included in the declaration of the primary key
SAMPLE BY intHash32(UserID)The example shows that according to intHash32(UserID) The distributed result sampling query .
SAMPLE BY We need to pay attention to :
- SAMPLE BY The declared expression must also be included in the declaration of the primary key ;
- Sample Key Must be Int type , Otherwise, although you can create , But an error will be reported when querying .
SAMPLE BY Three uses of :
1.SAMPLE factor
Represents sampling by factor coefficient ,factor Value support 0 ~1 Decimal between .
-- Press 10% Factor sampling data :
SELECT CounterID FROM hits_v1 SAMPLE 0.1
SELECT CounterID FROM hits_v1 SAMPLE 1/10
-- To get approximate results , The final result needs to be magnified 10 times
SELECT count() * 10 FROM hits_v1 SAMPLE 0.1
-- With the help of virtual fields _sample_factor To obtain the sampling coefficient is more elegant .
-- _sample_factor You can return the sampling coefficient corresponding to the current query
SELECT CounterID, _sample_factor FROM hits_v1 SAMPLE 0.1 LIMIT 2
┌─CounterID─┬─_sample_factor───┐
│ 57 │ 10 │
│ 57 │ 10 │
└────────┴─────────────┘
-- The query statement is rewritten as :
SELECT count() * any(_sample_factor) FROM hits_v1 SAMPLE 0.1
-- clickHouse Aggregate function of any(), It means to select the first encountered value 2.SAMPLE rows
SAMPLE rows Indicates that samples are taken according to the number of samples .rows > 1, Integers . If it is greater than all data , The effect is equal to rows=1( That is, sampling is not used ).
-- sampling 10000 Row data , Is the approximate range
SELECT count() FROM hits_v1 SAMPLE 10000
┌─count()─┐
│ 9576 │
└──────┘
-- The minimum granularity of sampling data is determined by index_granularity Index granularity determines , Less than this value makes no sense
-- Use virtual fields _sample_factor To obtain the sampling coefficient corresponding to the current query
SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 100000 LIMIT 1
┌─CounterID─┬─_sample_factor─┐
│ 63 │ 13.27104 │
└───────┴──────────┘3.SAMPLE factor OFFSET n
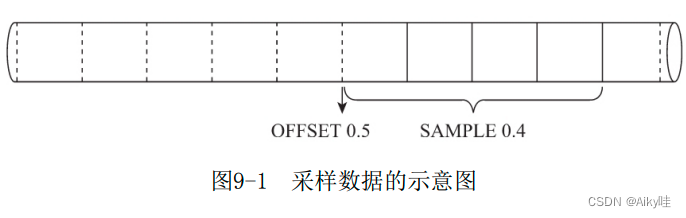
Represents sampling by factor coefficient and offset , among factor Represents the sampling factor ,n Indicates how much data is offset before sampling starts , The values of both of them are 0~1 Decimal between .
-- The offset for the 0.5 And press 0.4 Coefficient sampling
SELECT CounterID FROM hits_v1 SAMPLE 0.4 OFFSET 0.5
-- This usage supports the use of decimal expressions , Virtual fields are also supported _sample_factor:
SELECT CounterID,_sample_factor FROM hits_v1 SAMPLE 1/10 OFFSET 1/29.4 ARRAY JOIN Clause
ARRAY JOIN Clause allows inside the data table , With fields of array or nested type JOIN operation , This expands a row array into multiple rows .
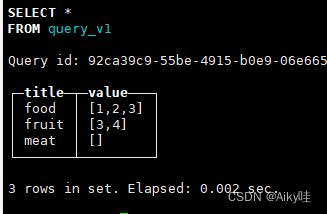
-- Build table :
CREATE TABLE query_v1
(
title String,
value Array(UInt8)
) ENGINE = Memory
INSERT INTO query_v1 VALUES ('food', [1,2,3]), ('fruit', [3,4]), ('meat', [])
One SELECT In the sentence , There can only be one ARRAY JOIN( Except using subqueries ). At present, we support INNER and LEFT Two kinds of JOIN Strategy :
1.INNER ARRAY JOIN
-- ARRAY JOIN By default, we use INNER JOIN Strategy
SELECT title,value FROM query_v1 ARRAY JOIN value
┌─title─┬─value─┐
│ food │ 1 │
│ food │ 2 │
│ food │ 3 │
│ fruit │ 3 │
│ fruit │ 4 │
└───────┴───────┘The final data is based on value The array is expanded into multiple rows , And exclude empty arrays .
-- Add an alias to the original array field , You can access the array fields before expansion
SELECT title,value,v FROM query_v1 ARRAY JOIN value AS v
┌─title─┬─value───┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
└───────┴─────────┴───┘2.LEFT ARRAY JOIN
-- Use left Strategy
SELECT title,value,v FROM query_v1 LEFT ARRAY JOIN value AS v
┌─title─┬─value───┬─v─┐
│ food │ [1,2,3] │ 1 │
│ food │ [1,2,3] │ 2 │
│ food │ [1,2,3] │ 3 │
│ fruit │ [3,4] │ 3 │
│ fruit │ [3,4] │ 4 │
│ meat │ [] │ 0 │
└───────┴─────────┴───┘
With ARRAY JOIN Nested data types are also supported .
CREATE TABLE query_v2
(
title String,
nest Nested(
v1 UInt32,
v2 UInt64)
) ENGINE = Log
INSERT INTO query_v2 VALUES ('food', [1,2,3], [10,20,30]), ('fruit', [4,5], [40,50]), ('meat', [], [])
SELECT title, nest.v1, nest.v2 FROM query_v2;
┌─title─┬─nest.v1─┬─nest.v2────┐
│ food │ [1,2,3] │ [10,20,30] │
│ fruit │ [4,5] │ [40,50] │
│ meat │ [] │ [] │
└───────┴─────────┴────────────┘
-- Use nested Columns
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest;
┌─title─┬─nest.v1─┬─nest.v2─┐
│ food │ 1 │ 10 │
│ food │ 2 │ 20 │
│ food │ 3 │ 30 │
│ fruit │ 4 │ 40 │
│ fruit │ 5 │ 50 │
└───────┴─────────┴─────────┘
-- Use a value in a nested column
SELECT title, nest.v1, nest.v2 FROM query_v2 ARRAY JOIN nest.v1;
┌─title─┬─nest.v1─┬─nest.v2────┐
│ food │ 1 │ [10,20,30] │
│ food │ 2 │ [10,20,30] │
│ food │ 3 │ [10,20,30] │
│ fruit │ 4 │ [40,50] │
│ fruit │ 5 │ [40,50] │
└───────┴─────────┴────────────┘
-- Access the original array by alias :
SELECT title, nest.v1, nest.v2, n.v1, n.v2 FROM query_v2 ARRAY JOIN nest as n
┌─title─┬─nest.v1─┬─nest.v2────┬─n.v1─┬─n.v2─┐
│ food │ [1,2,3] │ [10,20,30] │ 1 │ 10 │
│ food │ [1,2,3] │ [10,20,30] │ 2 │ 20 │
│ food │ [1,2,3] │ [10,20,30] │ 3 │ 30 │
│ fruit │ [4,5] │ [40,50] │ 4 │ 40 │
│ fruit │ [4,5] │ [40,50] │ 5 │ 50 │
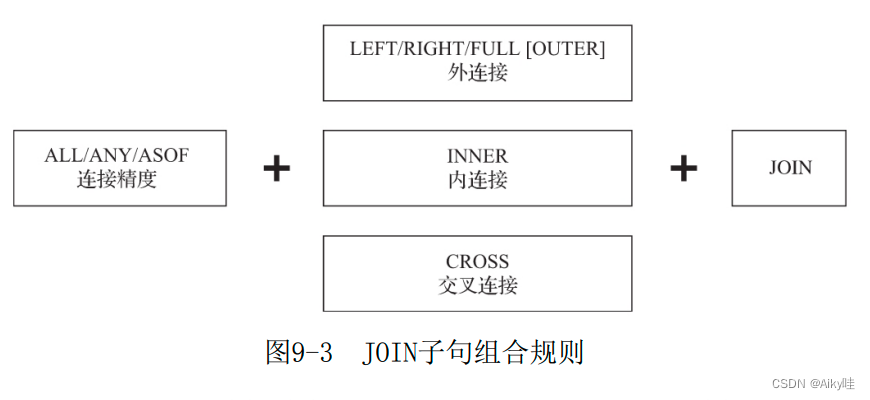
└───────┴─────────┴────────────┴──────┴──────┘9.5 JOIN Clause
join It is also divided into local and remote . Here we focus on local queries .
At present, only equation is supported (EQUAL JOIN). Cross connect (CROSS JOIN) No need to use JOIN KEY, Because it produces Cartesian product .
9.5.1 Connection accuracy
At present, we support ALL、ANY and ASOF Three types of , The default is ALL, Can pass join_default_strictness Configure parameters to modify the default connection accuracy type .
1.ALL
natural join, about join key Equal lines do join.
2.ANY
Each row of data in the left table matches only one row of data in the right table .
3.ASOF
Fuzzy connection . It is allowed to define a matching condition of fuzzy connection after the connection key asof_column.
SELECT a.id,a.name,b.rate,a.time,b.time
FROM join_tb1 AS a
ASOF INNER JOIN join_tb2 AS b
ON a.id = b.id
AND a.time = b.timeamong a.id=b.id It's an ordinary connection key , And next to that a.time=b.time It is asof_column Fuzzy connection condition .
Equate to a.id = b.id AND a.time >= b.time.
Finally, the returned query results meet the connection conditions a.id=b.id AND a.time>=b.time, And only the data matching the first row of the right table is returned .
Support use USING Short form of .
SELECT a.id,a.name,b.rate,a.time,b.time
FROM join_tb1 AS a
ASOF INNER JOIN join_tb2 AS b
USING(id,time)USING After time The field will be converted to asof_colum.
about asof_colum There are two points to note about the use of fields :
- asof_colum It has to be integer 、 Data types of ordered sequences such as floating-point and date types ;
- asof_colum Cannot be the only field in the data table , In other words , Connection key (JOIN KEY) and asof_colum Cannot be the same field .
9.5.2 Connection type
1.INNER
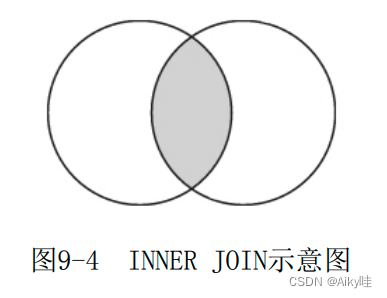
2.OUTER
It can be further subdivided into left outer connection (LEFT)、 Right connection (RIGHT) And all outside connection (FULL) Three forms .
[LEFT|RIGHT|FULL [OUTER]] ] JOIN1)left
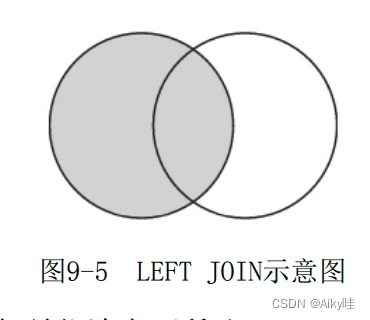
The values of columns without connections are supplemented by the default values .
2) right
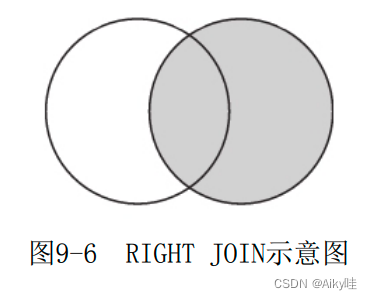
Internal logic :
- Carry out similar work internally INNER JOIN Internal connection query , While calculating the intersection part , Record the data rows in the right table that cannot be connected .
- Append the data rows that cannot be connected to the tail of the intersection .
- Fill the column fields belonging to the left table in the appended data with default values .
3)FULL
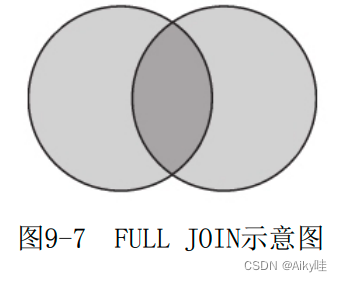
The full outer join query will return the union of the two data sets of the left table and the right table .
Internal logic :
- It will be carried out internally LEFT JOIN Query for , In the process of left outer connection , Record the connected data rows in the right table .
- By recording the connected data rows in the right table , Get unconnected data rows .
- Append the unconnected data in the right table to the result set , And fill in the column fields belonging to the left table with default values .
3.CROSS
Returns the Cartesian product of the two data sets of the left table and the right table . No declaration required JOIN KEY.
Based on the left table , Multiply row by row with the complete set of the right table .
9.5.3 Multiple table joins
When querying the connection of multiple data tables ,ClickHouse Will turn them into a form of pairwise connection .
SELECT a.id,a.name,b.rate,c.star
FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
LEFT JOIN join_tb3 AS c ON a.id = c.idWill be will be join_tb1 And join_tb2 Make internal connections , Then compare their result sets with join_tb3 Left connection .
ClickHouse Although the syntax of associated queries is also supported , But it will be automatically converted into the specified connection query .
- Convert to CROSS JOIN: If the query statement does not contain WHERE Conditions , Will be converted to CROSS JOIN.
SELECT a.id,a.name,b.rate,c.star FROM join_tb1 AS a , join_tb2 AS b ,join_tb3 AS c
- Convert to INNER JOIN: If the query statement contains WHERE Conditions , Will be converted to INNER JOIN.
SELECT a.id,a.name,b.rate,c.star FROM join_tb1 AS a , join_tb2 AS b ,join_tb3 AS c WHERE a.id = b.id AND a.id = c.id
9.5.4 matters needing attention
1. About performance
We should follow the principle of big left and small right .
Because no matter which connection method is used , The right table will be loaded into memory and compared with the left table .
JOIN There is currently no cache support for queries .
Even if the same... Is performed continuously SQL, A new execution plan will also be generated .
If it is in a query scenario with a large number of dimension attribute completion , It is recommended to use a dictionary instead of JOIN Inquire about .
Because when you perform a join query of multiple tables , The query will be converted into two The form of connection , such “ snowball ” Type queries are likely to cause performance problems .
2. About null strategy and short form
Null value of connection query ( Those unconnected data ) Is populated by default values , This is different from other databases The strategy is different ( from Null fill ).
adopt join_use_nulls Parameter specified , The default is 0. When the parameter value is 0 when , Null values are populated by the default values of the data type ; When the parameter value is 1 when , Null values are defined by Null fill .
JOIN KEY Support simplified writing , When the connection field names of the data table are the same , Sure Use USING Grammar shorthand .
SELECT a.id,a.name,b.rate
FROM join_tb1 AS a
INNER JOIN join_tb2 AS b ON a.id = b.id
-- Use USING Abbreviation
SELECT id,name,rate FROM join_tb1 INNER JOIN join_tb2 USING id9.6 WHERE And PREWHERE Clause
WHERE Clause is the basis for judging whether an index can be enabled in a query statement ( The premise is that the table engine supports indexing ).
WHERE The expression contains a primary key , Then you can use indexes to filter data ranges .
【 This should include the primary key prefix 】
PREWHERE Can be seen as right WHERE An optimization of . The difference is , Use PREWHERE when , First, only read PREWHERE The specified column field data , Condition judgment for data filtering . Read after data filtering SELECT Declared column fields to complete the remaining properties .
-- perform set optimize_move_to_prewhere=0 close PREWHERE Automatic optimization
SELECT WatchID,Title,GoodEvent FROM hits_v1 WHERE JavaEnable = 1
981110 rows in set. Elapsed: 0.095 sec. Processed 1.34 million rows, 124.65 MB (639.61 thousand rows/s., 59.50 MB
-- All in all 134 Ten thousand rows of data , Its data size is 124.65 MB
-- Use prewhere
SELECT WatchID,Title,GoodEvent FROM hits_v1 PREWHERE JavaEnable = 1
981110 rows in set. Elapsed: 0.080 sec. Processed 1.34 million rows, 91.61 MB (740.98 thousand rows/s., 50.66 MB/
-- The data size ranges from 124.65 MB Reduce to 91.61 MBObserve the execution plan of two queries .
--WHERE Inquire about
Union
Expression × 2
Expression
Filter
MergeTreeThread
--PREWHERE Inquire about
Union
Expression × 2
Expression
MergeTreeThreadPREWHERE A query is omitted Filter operation .
ClickHouse Realize the function of automatic optimization , Will, if the conditions are right WHERE Replace with PREWHERE.
optimize_move_to_prewhere Set to 1( The default value is 1, I.e. on )
9.7 GROUP BY Clause
If SELECT After that, only the aggregate function is declared , You can omit GROUP BY keyword .
-- If there are only aggregate functions , It can be omitted GROUP BY
SELECT SUM(data_compressed_bytes) AS compressed ,
SUM(data_uncompressed_bytes) AS uncompressed
FROM system.parts
-- In addition to aggregate functions , Only aggregates can be used key It contains table Field
SELECT table,COUNT() FROM system.parts GROUP BY table
-- Use aggregation key Not stated in rows Field , May be an error
SELECT table,COUNT(),rows FROM system.parts GROUP BY table
-- But in some cases , Can use any、max and min Wait for aggregate functions to access column fields other than aggregate keys :
SELECT table,COUNT(),any(rows) FROM system.parts GROUP BY tableWhen the data in the aggregate query exists NULL When the value of ,ClickHouse Will NULL As NULL=NULL Specific value processing of .
namely , be-all NULL Values are aggregated to NULL grouping .
Aggregate query can also cooperate with WITH ROLLUP、WITH CUBE and WITH TOTALS Three modifiers get additional summary information .
9.7.1 WITH ROLLUP
ROLLUP The data can be rolled up from right to left according to the aggregation key , Group subtotal and total are generated based on aggregate function .
If the number of aggregate keys is n, The number of subtotals that will eventually be generated is n+1.
-- for example
SELECT table, name, SUM(bytes_on_disk) FROM system.parts
GROUP BY table,name
WITH ROLLUP
ORDER BY table
┌─table───────────────────┬─name─────────────────────┬─sum(bytes_on_disk)─┐
│ │ │ 440833384 │
│ asynchronous_metric_log │ │ 384103205 │
│ asynchronous_metric_log │ 20220622_7337_7337_0 │ 6525 │
│ asynchronous_metric_log │ 20220624_12731_13060_94 │ 2594507 │
│ asynchronous_metric_log │ 20220706_46580_46580_0 │ 10831 │
│ asynchronous_metric_log │ 20220706_46418_46569_45 │ 1192486 │
│ asynchronous_metric_log │ 20220624_10219_12730_100 │ 19988721 │
...
│ asynchronous_metric_log │ 20220706_46576_46576_0 │ 10626 │
│ asynchronous_metric_log │ 20220620_1_1185_99 │ 9201998 │
│ asynchronous_metric_log │ 20220704_41423_41816_93 │ 3093175 │
│ metric_log │ │ 56468784 │
│ metric_log │ 20220630_29867_30376_103 │ 581564 │
│ metric_log │ 20220706_46562_46562_0 │ 20668 │
│ metric_log │ 20220703_36137_38513_277 │ 2759474 │
...
│ metric_log │ 20220706_46538_46558_5 │ 44010 │
│ metric_log │ 20220702_35650_36136_99 │ 573225 │
│ metric_log │ 20220628_21737_24418_276 │ 3138365 │
│ metric_log │ 20220706_46573_46573_0 │ 20720 │
│ part_log │ │ 4303 │
│ part_log │ 20220627_1_11_3 │ 2386 │
│ part_log │ 20220705_12_18_2 │ 1917 │
│ partition_v1 │ │ 232 │
│ partition_v1 │ 201906_2_2_0_3 │ 232 │
│ query_log │ │ 135372 │
│ query_log │ 20220706_98_106_2 │ 9523 │
│ query_log │ 20220622_8_12_1 │ 10512 │
...You can see in the final returned result , The subtotal summary row with empty display name is returned additionally , Include the total disk size of all table partitions and each table Total information of all partition sizes in .
9.7.2 WITH CUBE
CUBE It will be like a cube model , Generate subtotals based on all combinations between aggregate keys Information . If the number of aggregate keys is n, Then the number of final subtotal combination is 2 Of n Power .
9.7.3 WITH TOTALS
Use TOTALS After the embellishment , All data will be aggregated based on the aggregation function , Execute the following statement, for example :
SELECT database, SUM(bytes_on_disk),COUNT(table) FROM system.parts
GROUP BY database WITH TOTALS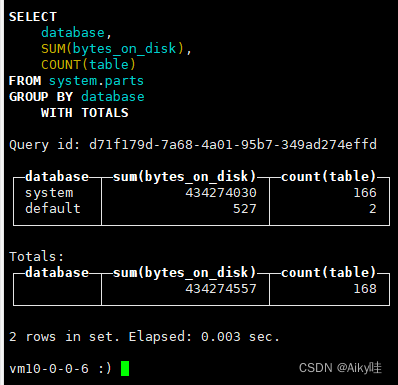
The result is appended with a line Totals Summary total , This result is based on the aggregation function pair The total result of all data aggregation .
9.8 HAVING Clause
HAVING Clause needs to be associated with GROUP BY At the same time , Not to be used alone .
It can filter data twice after aggregation calculation .
SELECT COUNT() FROM system.parts GROUP BY table
-- Implementation plan
Expression
Expression
Aggregating
Concat
Expression
One
SELECT COUNT() FROM system.parts GROUP BY table HAVING table = 'query_v3'
-- Implementation plan
Expression
Expression
Filter
Aggregating
Concat
Expression
OneFind out HAVING The essence of is to add Filter Filter action .
-- By nesting WHERE Can achieve the same goal
SELECT COUNT() FROM
(SELECT table FROM system.parts WHERE table = 'query_v3')
GROUP BY table
-- Implementation plan
Expression
Expression
Aggregating
Concat
Expression
Expression
Expression
Filter
OneCompared with HAVING, nesting WHERE The implementation plan of is more efficient . because WHERE It is equivalent to using predicate push down , Data filtering is done before aggregation , This reduces the amount of data that needs to be processed during subsequent aggregation .
But if you need to follow poly Combined value for filtering , You have to rely on HAVING Realization .
9.9 ORDER BY Clause
stay MergeTree It is specified in ORDER BY after , The data will be sorted according to the rules defined in each partition , This is a local sort within a partition .
If necessary, data can always be returned in the desired order , We need help from ORDER BY Clause to specify the global order .
-- Two article SQL Equivalent
-- according to v1 Ascending 、v2 null
SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1 ASC, v2 DESC
SELECT arrayJoin([1,2,3]) as v1 , arrayJoin([4,5,6]) as v2
ORDER BY v1, v2 DESC
For data NULL Order of values , at present ClickHouse Have NULL Value last and NULL Value first two strategies , Can pass NULLS Modifier to set .
NULL Value last , This is also the default behavior , The modifier can be omitted .
-- The order is value -> NaN -> NULL
WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS LAST
┌───v1─┐
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
│ nan │
│ nan │
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
└──────┘
-- The order is NULL -> NaN -> value
WITH arrayJoin([30,null,60.5,0/0,1/0,-1/0,30,null,0/0]) AS v1
SELECT v1 ORDER BY v1 DESC NULLS FIRST
┌───v1─┐
│ ᴺᵁᴸᴸ │
│ ᴺᵁᴸᴸ │
│ nan │
│ nan │
│ inf │
│ 60.5 │
│ 30 │
│ 30 │
│ -inf │
└──────┘9.10 LIMIT BY Clause
LIMIT BY Clauses and common LIMIT All the different , It runs on ORDER BY And And after LIMIT Before , Can be grouped according to the specified , Return to the front... At most n Row data ( If the data is less than n That's ok , Return by actual quantity ), Commonly used in TOP N The query scenario of .
-- limit n by
-- Based on database and data table grouping , The data returned by the query takes up the largest amount of disk space 3 A watch
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY database ,bytes DESC
LIMIT 3 BY database
┌─database─┬─table───────────────────┬────bytes─┐
│ default │ ttl_table_v1 │ 295 │
│ default │ partition_v1 │ 232 │
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
└──────────┴─────────────────────────┴──────────┘
LIMIT BY Skip is also supported OFFSET Offset .
LIMIT n OFFSET y BY express
-- Abbreviation
LIMIT y,n BY express9.11 LIMIT Clause
LIMIT Clause is used to return the specified prefix n Row data , Commonly used in paging scenarios ,
LIMIT Clauses can be compared with LIMIT BY Use together .
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY bytes DESC
LIMIT 3 BY database
┌─database─┬─table───────────────────┬────bytes─┐
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
│ default │ ttl_table_v1 │ 295 │
│ default │ partition_v1 │ 232 │
└──────────┴─────────────────────────┴──────────┘
SELECT database,table,MAX(bytes_on_disk) AS bytes FROM system.parts
GROUP BY database,table ORDER BY bytes DESC
LIMIT 3 BY database
LIMIT 4
┌─database─┬─table───────────────────┬────bytes─┐
│ system │ asynchronous_metric_log │ 22547602 │
│ system │ metric_log │ 3333300 │
│ system │ query_log │ 26134 │
│ default │ ttl_table_v1 │ 295 │
└──────────┴─────────────────────────┴──────────┘Use LIMIT There is one thing to pay attention to when clause , If the data spans multiple partitions , Before use ORDER BY Specify the global order , Every time LIMIT The data returned by the query may be different .
9.12 SELECT Clause
After the execution of other clauses ,SELECT The selected field or expression will be applied to each row of data .
ClickHouse It also provides a form based on regular queries for specific scenarios .
-- The query will return the name in letters n The beginning and contain letters p Column fields for :
SELECT COLUMNS('^n'), COLUMNS('p') FROM system.databases
┌─name──────┬─data_path──────────────────────────┬─metadata_path───────────────────────────────────────────────────────────────┐
│ aikytest1 │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/92a/92a393fc-4273-4575-92a3-93fc42737575/ │
│ default │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/500/50049df5-cb66-4498-9004-9df5cb66f498/ │
│ system │ /data/clickhouse/clickhouse/store/ │ /data/clickhouse/clickhouse/store/63e/63eb7fce-251d-4419-a3eb-7fce251db419/ │
└───────────┴────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────┘9.13 DISTINCT Clause
DISTINCT Clause can remove duplicate data .
DISTINCT Can also be associated with GROUP BY Use at the same time , So they are complementary rather than mutually exclusive .
When DISTINCT And ORDER BY When used at the same time , The priority of its implementation is DISTINCT after ORDER BY.
9.14 UNION ALL Clause
UNION ALL Clause can combine two sets of subqueries on the left and right , Return the results together .
UNION ALL Subqueries on both sides need :
- The number of column fields must be the same ;
- The data type of column fields must be the same or Compatible with ;
- The names of column fields can be different , The column names in the query results will appear on the left Sub query of .
at present ClickHouse Only support UNION ALL Clause .
expect UNION DISTINCT The effect of clause , Nested queries can be used to disguise .
9.15 see SQL Implementation plan
【 This chapter is overdue , Now? clickhouse Can already support explain Inquire about sql Implementation plan 】
9.16 Summary of this chapter
Usage of various query clauses .
It only introduces ClickHouse Local query part of , The next chapter will further introduce and ClickHouse Distributed knowledge .
边栏推荐
- Paper reading [semantic tag enlarged xlnv model for video captioning]
- Leakage relay llj-100fs
- SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
- 淘寶商品詳情頁API接口、淘寶商品列錶API接口,淘寶商品銷量API接口,淘寶APP詳情API接口,淘寶詳情API接口
- C nullable type
- 4. 对象映射 - Mapping.Mapster
- 消息队列:消息积压如何处理?
- R语言【逻辑控制】【数学运算】
- Paper reading [open book video captioning with retrieve copy generate network]
- Introduction to distributed transactions
猜你喜欢
产业金融3.0:“疏通血管”的金融科技
C#可空类型

判断文件是否为DICOM文件
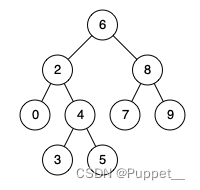
【日常训练--腾讯精选50】235. 二叉搜索树的最近公共祖先
![SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server](/img/05/1e4bdddce1e07f7edd2aeaa59139ab.jpg)
SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
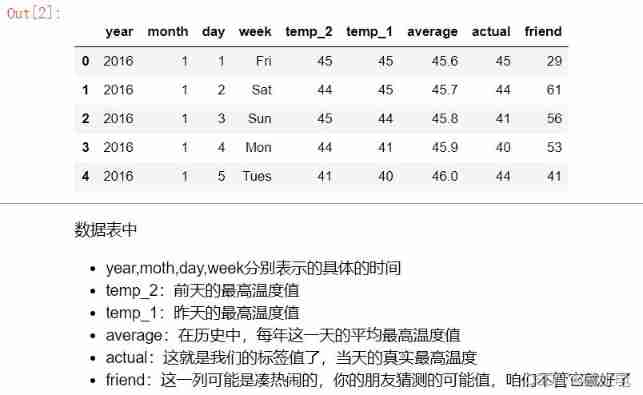
Pytorch builds neural network to predict temperature
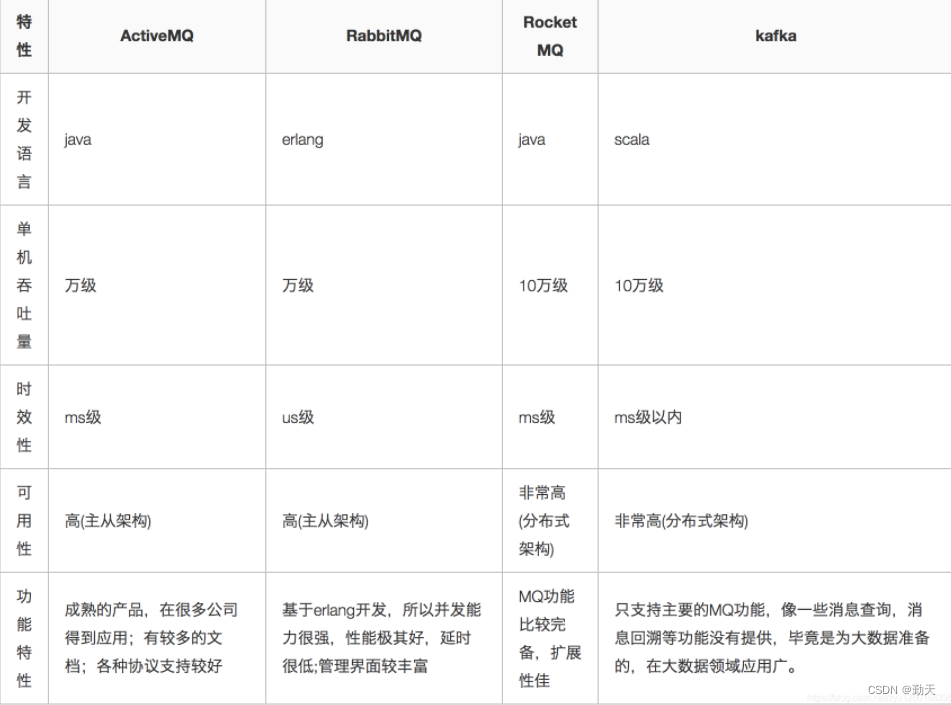
What are the common message queues?
《ClickHouse原理解析与应用实践》读书笔记(6)
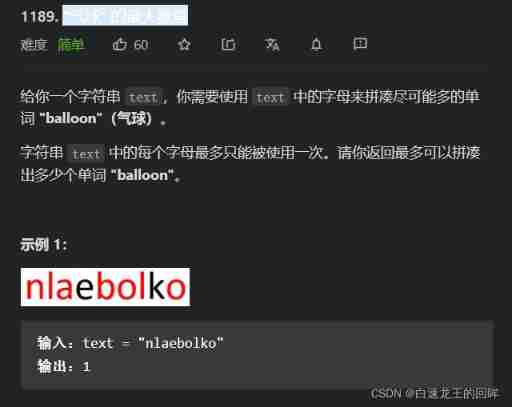
Leetcode: maximum number of "balloons"
5. 数据访问 - EntityFramework集成
随机推荐
Introduction to distributed transactions
Things about data storage 2
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
Taobao Commodity details page API interface, Taobao Commodity List API interface, Taobao Commodity sales API interface, Taobao app details API interface, Taobao details API interface
Sidecar mode
Tablayout modification of customized tab title does not take effect
5阶多项式轨迹
SAP ABAP BDC(批量数据通信)-018
5. 数据访问 - EntityFramework集成
Forkjoin is the most comprehensive and detailed explanation (from principle design to use diagram)
AI face editor makes Lena smile
Three level menu data implementation, nested three-level menu data
win配置pm2开机自启node项目
I didn't know it until I graduated -- the principle of HowNet duplication check and examples of weight reduction
The navigation bar changes colors according to the route
C nullable type
Web authentication API compatible version information
High voltage leakage relay bld-20
An example of multi module collaboration based on NCF
[reading of the paper] a multi branch hybrid transformer network for channel terminal cell segmentation