当前位置:网站首页>[Shell]常用shell命令及测试判断语句总结
[Shell]常用shell命令及测试判断语句总结
2022-07-07 01:25:00 【alwaysrun】
文章目录
Shell既是一个连接用户和Linux内核的程序,又是一门管理Linux系统的脚本语言。
shell命令
linux下提供了各种命令,方便处理。
通过&&与||可把多个命令组合在一起执行:
command1 && command2:只有command1执行成功(返回结果为0)时,才会执行command2;command1 || command2:只有command1执行失败(返回结果非0)时,才会执行command2;通过
{}可把多个命令(每行一条命令,或通过分号分割命令)组成一个命令组(相当于一条命令);[ -e 2.txt ] && { echo 2.txt echo exists } || { echo 2.txt echo not exts; echo 33 } # 执行结果: 2.txt not exts 33
内容显示
cat
cat用于显示文本文件的内容(一次性全部显示):
cat [options] file
-n:对输出的所有行进行编号(在前面显示行号)-b:对输出的所有非空行进行编号(在前面显示行号)-E:每行行尾显示$(表示回车符)
head
head显示文件前若干行内容(默认显示10行)
head [options] file
-n k:显示前k行(若k<0,表示最后k行不显示,其余都显示);-c k:显示前k个字节(若k<0,表示最后k行不显示,其余都显示);-v:先显示文件名,接着显示内容
# 显示前两行
head -n 2 test.sh
# 显示除最后两行外的所有行
head -n -2 test.sh
tail
tail用于查看文件尾部数据
tail [options] file
-f:循环读取,当文件更新时自动读取;-f -s=m:每m秒更新一次(读取新的变更);
-n k:显示最后k行(默认10行);-n +k:显示第k行到末尾;
-v:先显示文件名,接着显示内容;
echo
echo是显示后面的内容(默认带换行);
输出内容不带换行符(-n)
# first与second连在一行
echo -n "first" > 1.txt
echo "second" > 1.txt
输出内容带控制符(此时必须使用引号括起)
# first后有一个空行
echo -e "first\n" > 1.txt
文本处理
在所有有效行(非空,非注释)行首添加前缀,并合并为一行:
cat test.txt | awk '!(!NF || /^#/){print "prefix",$0}' | tr -t ['\n'] [' ']
grep
grep可在一个或多个文件中搜索某一特定的字符模式(可以是单一的字符、字符串、单词或句子)。
grep [选项] '搜寻字符串' file
| 选项 | 含义 |
|---|---|
| -c | 仅列出文件中包含模式的行数。 |
| -i | 忽略模式中的字母大小写。 |
| -l | 列出带有匹配行的文件名。 |
| -n | 在每一行的最前面列出行号。 |
| -v | 列出没有匹配模式的行。 |
| -w | 把表达式当做一个完整的单字符来搜寻(匹配完整的单词) |
搜索字符串中可用通配符:
| 通配符 | 功能 |
|---|---|
| c* | 将匹配 0 个(即空白)或多个字符 c(c 为任一字符)。 |
| . | 将匹配任何一个字符,且只能是一个字符。 |
| [xyz] | 匹配方括号中的任意一个字符。 |
| [^xyz] | 匹配除方括号中字符外的所有字符。 |
| ^ | 锁定行的开头。 |
| $ | 锁定行的结尾。 |
sed
sed根据脚本命令来处理文件(依次读取每一行内容进行操作),主要是用来进行数据选取、替换、删除、新増。
sed [选项] [脚本命令] file
| 选项 | 含义 |
|---|---|
| -e | 指定sed编辑命令;多条命令时必须带-e,如:-e 's/first//g; s/second//g' ,同时替换两个 |
| -f | 指定sed编辑命令的文件(命令来源于文件) |
| -n | 寂静模式(只显示那些被改变的行),否则会显示所有内容 |
| -i | 直接修改源文件 |
指定行:脚本命令可指定处理的行(默认会处理每一行)
line命令
# 或者,多行命令
line{
命令
}
- 行编号从1开始;
- 多行用逗号分割:如
m,n,表示操作[m,n]行; $表示文件尾:如2,$,表示操作从第2行开始的所有行;$=表示行数
# 显示1~3行
sed -n '1,3p' test.sh
# 显示总行数
sed -n '$=' test.sh
匹配行:也可指定处理匹配的行(满足文本匹配的行)
/pattern/命令
- 多个匹配时时用逗号分割:如
/pattern1/,/pattern2/命令
# 显示有echo的行
sed -n '/echo/p' test.sh
# 显示所有for循环
sed -n '/for/,/done/p' test.sh
替换
替换命令,用replacement替换pattern:
s/pattern/replacement/flags
| flags | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换; |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作 |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 () 指定。 |
| \ | 转义(转义替换部分包含:&、\ ,以及路径分隔符/)。 |
替换后保存到新文件:
sed 's/test/trial/gw test.txt' data.txt
删除
通过d命令,删除匹配的行;如删除1~3行:
sed '1,3d' test.sh
添加行
在指定行前(i)或行后(a)追加一行内容:
a(或 i)\追加行
- 斜线
\可省略,但若添加以空格开始的文本,必须以斜线分割
在行后添加内容:
# 在第二行后(第三行)添加一行(内容为hello)
sed '2a hello' test.sh
# 在2~5行后(3,5,7,9)添加" hello"
sed '2,5a\ hello' test.sh
行替换
替换满足条件的行:
c\新行
# 把2~5行删除,然后添加一个新行" hello"
sed '2,5c\ hello' test.sh
字符替换
把in中的每个字符,替换为out中的字符(对应位置替换,in与out要长度相等)
y/inchars/outchars/
小写替换为大小
# 把三个字符f、o、r改为大写
sed 'y/for/FOR/' test.sh
打印
打印满足添加的行(一般与-n参数一起使用):p
# 打印1~3行
sed -n '1,3p' test.sh
写文件
把内容写入指定的文件:
w file
把1~3行写入新的文件:
sed -n '1,3w new.sh' test.sh
插入文件
把文件内容插入到指定位置
r file
把new.sh插入的文件尾:
sed '$r new.sh' test.sh
退出命令
通过q命令,可在指定位置退出(不再处理后续行)。
只替换前10行:
sed 'y/for/FOR/; 10q' test.sh
多行命令
sed有处理多行文本的特殊命令(都为大写);如要搜索跨行的单词,必须就要多行一起处理了:
N:查找到符合条件的行后,自动读取下一行;两行组合在一起作为整体来处理;D:删除多行组中的一行。P:打印多行组中的一行。
把包含for的行与下一行合并:
sed -n '/for/{N; s/\n//; p}' test.sh
awk
awk 命令逐行扫描文件,寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作。
awk [选项] '脚本命令' 文件名
| 选项 | 含义 |
|---|---|
| -F fs | 设定分隔符为fs;默认分隔符为空格或制表符 如以点号为分隔符 awk -F. '{print $1}'同时以“.”和“/”作为分隔符 -F[./] |
| -f file | 从文件中读取脚本指令 |
| -v var=val | 在执行处理过程之前,设置一个变量 var,并给其设备初始值为 val。 |
脚本命令由模式与操作(位于大括号内的命令;多条直接用分号分割:模式或条件{操作})两部分组成;模式可为:
- 正则表达式:字符串必须使用反斜线括起(
/匹配内容/); - 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试;
- 模式匹配表达式:用运算符
~(匹配)和!~不匹配; - 完整命令由:BEGIN 语句块,pattern语句块,END语句块,三步组成(每一部分都是可选):
- BEGIN语句块:在读取行之前执行(只执行一次);适合变量初始化,打印表头等操作;
- pattern语句块:读取每一行,执行pattern命令;若忽略,则为直接打印行内容;
- ND语句块:读取完所有行后执行(只执行一次);适合打印结果或信息汇总等操作。
示例说明:
$ awk 'END{print NR}' test.txt # 获取文件的行数
$ awk 'END{print $0}' test.txt # 打印最后一行
$ awk '/^$/ {print "Blank line"}' test.txt # 打印空行
$ awk 'NR < 5 {print $0}' # 打印前四行
$ awk 'NR==1,NR==4 {print $0}' # 打印前四行
$ awk '/linux/ {print $0}' # 打印包含linux的行
$ awk '!/linux/ {print $0}' # 打印不包含linux的行
# 逻辑操作&&,||,!
awk -F: '!($1~/root/ || $3<15)' /etc/passwd # 以冒号分割,非(字段1为root,且字段三小于15)
# 获取所有有效行(非空,非注释)
cat test.txt | awk '!(/^$/ || /^#/){print "prefix-",$0}'
# 或者:!NF表示没有字段; 使用if时,要放在{}中
cat test.txt | awk '{if(!NF || /^#/){next} {print "prefix-",$0}}'
输出
print可依次输出各参数,会自动换行;
printf可格式化输出(类似C语言);默认不换行,要手动添加换行符:
printf "|%-15s| %d | %f |\n", $1,$2,$3
next
next表示跳过当前行,并忽略后续所有语句
# 输出偶数行(跳过当前行时,后面的print的行也不会执行)
awk 'NR%2==1{next}{print NR,$0;}' test.sh
getline
读入下一行(因当前行已自动读入,getline相当于隔行读)
# 输出偶数行(跳过当前行时,后面的print的行也不会执行)
awk '{getline; print NR,$0}' test.sh
内置变量
awk命令操作时,可使用内置变量:
- $n : 当前记录(行)的第n个字段(从1开始);
- $0 : 当前行的文本内容。
- NR : 表示记录数,在执行过程中对应于当前的行号;
- FNR : 同NR,多文件时为相对于当前文件。
- NF : 表示字段数(当前行可拆分为多少字段);
!NF可用于判断是空行 - FS : 字段分隔符(默认为空格或制表位)与"-F"作用相同;
- OFS : 输出字段分隔符(默认值是一个空格)
- RS : 记录分隔符(默认换行符);
- ORS : 输出记录分隔符(默认换行符);
- FILENAME : 当前输入文件的名;
- OFMT : 数字的输出格式(默认值是%.6g);
以分号分割输出(输出每行的前两个字段):
awk -v OFS=";" '{print $1,$2}' test.sh
字符串函数
awk命令中可使用以下字符串处理函数:
length(string):返回字符串string的长度。index(string, search_string):返回search_string在字符串string中出现的位置。split(string, array, delimiter):以delimiter作为分隔符,分割字符串string,将生成的字符串存入数组array。substr(string, start-position, end-position):返回字符串string中以start-position和end-position作为起止位置的子串。sub(regex, replacement_str, string):将正则表达式regex匹配到的第一处内容替换成replacment_str。gsub(regex, replacement_str, string):和sub()类似。不过该函数会替换正则表达式regex匹配到的所有内容。match(regex, string):检查正则表达式regex是否能够在字符串string中找到匹配。如果能够找到,返回非0值;否则,返回0。match()有两个相关的特殊变量,分别是RSTART和RLENGTH。变量RSTART包含了匹配内容的起始位置,而变量RLENGTH包含了匹配内容的长度。
find
find用于搜索文件
按文件名
按文件名(支持通配符?与*)搜索:
find 路径 -name "文件名"
find 路径 -iname "文件名" # 不区分大小写
如,搜索当前目录下所有cpp文件:
find . -name "*.cpp"
按文件类型
搜索指定类型的文件:
find 路径 -type 类型
- d: 目录
- f: 普通文件
- l: 链接文件(link)
- s: socket文件
- p: 管道文件(pipe)
- b: 块设备文件
- c: 字符设备文件
搜索当前目录下所有普通文件:
find . -type f
按文件大小
根据文件大小范围搜索:
find 路径 -size [+,-][c,w,k,M,G]
- +:表示大于
- -:表示小于
c,w,k,M,G:分别表示字节、双字节、千、兆、吉;
如查询100~200字节大小的文件:
find . -type f -size +110c -size -200c -ls
find . -type f -size 148c # 大小为148字节文件
按修改日期
按文件的创建、修改或访问日期进行搜索:
find 路径 -atime/-ctime/-mtime [-/+]n
- n为数字,意义为在n天之前的一天以内被更改过的文件。0就表示今天修改过的文件;
- +n:列出n天之前(不含n天本身)被更改过的文件;
- -n:列出n天之内(含有n天本身)被更改过的文件;
如查询今天创建的文件:
find . -ctime 0
组合查找
通过把多个条件进行组合,可构造出更复杂的查找:
- -a: and
- -o: or
- -not:
如查询今天创建文件(不包括文件夹)
find . -type f -a -ctime 0
查找深度
查找深度可限制搜索目录的层数
find 路径 -maxdepth/-mindepth n
- -maxdepth:在<=n层目录内搜索(1表示当前层);
- -mindepth:在>=n层目录内搜索(1表示当前层);
在当前目录,及其下层目录内搜索(只搜索两侧)
find . -maxdepth 2
find -exec
配合-exec参数,可以对查询的文件进行进一步的操作
find 路径 查找方式 -exec shell命令 {} \;
- 命令以
\;结束; {}表示查找出来的文件名;
显示查找到文件的详情:
find . -type f -exec ls -l {} \;
查找passwd中是否存在root:
find /etc -name "passwd*" -exec grep "root" {} \;
tr字符处理
tr(translate的简写)主要用于压缩重复字符,删除文件中的控制字符以及进行字符转换操作。
tr [OPTION]... SET1 [SET2]
-s:压缩重复字符;压缩SET1中指定字符(去重)-cs:压缩除SET1中指定字符外的所有字符(去重)
$ echo 'aaaa111bbbb22aaa3' | tr -s [ab] a111b22a3 $ echo 'aaaa111bbbb22aaa3' | tr -cs [ab] aaaa1bbbb2aaa3 # 移除文件中的空行 cat test.txt | tr -s ['\n']-d:删除字符;删除SET1中指定的字符-cd:删除出SET1中指定字符外的所有字符
$ echo 'aaaa111bbbb22aaa3' | tr -d [ab] 111223 # 删除非字符(且保留换行) $ echo 'aaaa111bbbb22aaa3' | tr -cd [ab'\n'] aaaabbbbaaa-t:替换字符,将SET1中字符用SET2对应位置的字符进行替换# 大小写转换 $ echo 'aaaa111bbbb22aaa3' | tr -t [a-z] [A-z] AAAA111BBBB22AAA3 # 所有行合并为一行 cat test.txt | tr -t ['\n'] [' ']-c:补集替换,用SET2替换SET1中没有包含的字符# 把数字替换为# # 若SET中不加'\n',则末尾换行符也会被替换,最后会是##,且不换行 $ echo 'aaaa111bbbb22aaa3' | tr -c [ab'\n'] '#' aaaa###bbbb##aaa#
字符集
SET中字符集合,可单独列举所需字符,也可通过-指定范围,以及使用预定义的集合:
\NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
\\ 反斜杠
\a Ctrl-G 铃声
\b Ctrl-H 退格符
\f Ctrl-L 走行换页
\n Ctrl-J 新行
\r Ctrl-M 回车
\t Ctrl-I tab键
\v Ctrl-X 水平制表符
[CHAR*] in SET2, copies of CHAR until length of SET1
[CHAR*REPEAT] REPEAT copies of CHAR, REPEAT octal if starting with 0
[:alnum:] 所有的字母和数字
[:alpha:] 所有字母
[:blank:] 水平制表符,空白等
[:cntrl:] 所有控制字符
[:digit:] 所有的数字
[:graph:] 所有可打印字符,不包括空格
[:lower:] 所有的小写字符
[:print:] 所有可打印字符,包括空格
[:punct:] 所有的标点字符
[:space:] 所有的横向或纵向的空白
[:upper:] 所有大写字母
统计字符数
统计变量中点号的数量:
- 删除除点号外的所有字符;
- 统计字符数;
#!/bin/bash
TAG_TEST=1.2.3
BUILD_NO=20220612
echo $TAG_TEST
COUNT=$(echo $TAG_TEST | tr -cd "." | wc -c)
if [ $COUNT -eq 2 ]; then
echo $TAG_TEST.$BUILD_NO >VERSION
elif [ $COUNT -eq 3 ]; then
echo $TAG_TEST >VERSION
else
echo "invalid Tag echo $TAG_TEST"
exit -1
fi
cat VERSION
seq序列
seq用于输出序列化的东西:
seq [选项]... 尾数
seq [选项]... 首数 尾数
seq [选项]... 首数 增量 尾数
选项:
-f fmt:指定格式化方式(类似printf);-s str:使用str作为分隔符;-w:在列前添加0,使得宽度相同;
$ seq -s '#' 5
1#2#3#4#5
$ seq -w 1 10
01
。。。
10
xargs
xargs命令是将标准输入转为命令行参数;在管道操作(|)时,连接无法接收管道传参的命令(即命令不能从stdin直接接收输入参数,如ls等)。
命令格式(默认以空格与换行作为分隔符,把每一部分作为参数传递给[command]命令):
xargs [-options] [command]
-L n:指定n行组成一个参数,传递给[command]命令;-n n:指定n项组成一个参数,传递给[command]命令;如,三个参数组成一组:$ echo {1..9} | xargs -n 3 echo 1 2 3 4 5 6 7 8 9-I:用参数替换指定的字符串(且此时分隔符为换行)$ echo {1..9} | xargs -I num bash -c "echo num; echo num" 1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9
查找以s开头的文件/文件夹,并输出其详细信息:
find . -maxdepth 1 -name "s*" | xargs ls -l
shell脚本
shell脚本一般以.sh作为扩展名,首行标识使用哪种shell解析器,以test.sh为例:
#!/bin/bash
echo "Hello World !"
执行:
- 直接执行;
chmod a+x test.sh:添加执行权限;./test.sh:执行脚本;
bash test.sh:明确以bash解析器执行,且test脚本文件不需要执行权限;
变量
每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储。
变量定义三种方式:
name=value
name='value'
name="value"
- 若变量中有空格,必须使用引号;
- 以单引号
' '包围变量的值时,原样输出; - 以双引号
" "包围变量的值时,输出时会先解析里面的变量和命令;
变量删除通过unset命令(删除后将不能再次使用):
unset name
命令结果赋给变量
将命令的执行结果赋值给变量,常见的有以下两种方式:
variable=`command` # 不能直接嵌套
variable=$(command) # 可嵌套
特殊变量
| 变量 | 含义 |
|---|---|
| $0 | 当前脚本的文件名 |
| $n | 传递给脚本或函数的参数。n表示第几个参数。如,第一个参数是$1,第二个参数是$2。 |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| [email protected] | 传递给脚本或函数的所有参数。 |
| $? | 上个命令的退出状态,或函数的返回值。一般0为成功,其他为失败; |
| $$ | 当前Shell进程ID。对于 Shell 脚本,就是这些脚本所在的进程ID。 |
$ 和 [email protected] 的区别*
$* 和 [email protected] 都表示传递给函数或脚本的所有参数,不被双引号(" “)括起来时,都以”$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数;当它们被双引号(" ")括起时:
- “$*” 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;
- “[email protected]” 会将各个参数分开,仍以"$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。
以下输出两者可查看其区别(以引号括起时):
#!/bin/bash
echo "print each param from \"\$*\""
for var in "$*"
do
echo "$var"
done
echo "print each param from \"\[email protected]\""
for var in "[email protected]"
do
echo "$var"
done
# $ test.sh a b c d
# print each param from "$*"
# a b c d
# print each param from "[email protected]"
# a
# b
# c
# d
变量替换
变量替换可以根据变量的状态(是否为空、是否定义等)来改变它的值
| 形式 | 说明 |
|---|---|
| ${var} | 变量本来的值 |
| ${var:-word} | 如果变量 var 为空或已被删除(unset),那么返回 word,但不改变 var 的值。 |
| ${var:=word} | 如果变量 var 为空或已被删除(unset),那么返回 word,并将 var 的值设置为 word。 |
| ${var:?message} | 如果变量 var 为空或已被删除(unset),那么将消息 message 送到标准错误输出,可以用来检测变量 var 是否可以被正常赋值。 若此替换出现在Shell脚本中,那么脚本将停止运行。 |
| ${var:+word} | 如果变量 var 被定义,那么返回 word,但不改变 var 的值。 |
字符串
字符串索引从0开始。
| 表达式 | 含义 |
|---|---|
| ${#str} | $str的长度 |
| ${str:position} | 在$str中,从位置position开始提取子串 |
| ${str:position:length} | 在$str中 ,从位置position开始提取长度为length的子串 |
| ${str#substr} | 从变量$str的 开 头,删除最短匹配substr的子串 |
| ${str##substr} | 从变量$str的 开 头,删除最长匹配substr的子串 |
| ${str%substr} | 从变量$str的 结 尾,删除最短匹配substr的子串 |
| ${str%%substr} | 从变量$str的 结 尾 ,删除最长匹配substr的子串 |
| ${str/substr/newstr} | 使用newstr来代替第一个匹配的substr |
| ${str//substr/newstr} | 使用newstr代替所有匹配的substr |
| ${str/#substr/newstr} | 替换开头:如果$str以substr开头,那么就用newstr替换 |
| ${str/%substr/newstr} | 替换结尾:如果$str以substr结尾,那么就用newstr替换 |
说明:"$substr”可以是一个正则表达式.
条件测试
shell脚本中逻辑运算通过[ express ]实现的,注意
[]与测试表达式间要有空格;- 放在判断语句if等时,也要注意中间保留空格;
- 变量要用引号括起来;
- 字符串比较时,推荐使用双括号
[[ ]]:双中括号时,变量自动作为一个整体处理;
三类测试:
- [ “$A” = 123 ]:是字串测试,判断是否为字符串"123"。
- [ “$A” -eq 123 ]:是整数测试,判断是否为数字123。
- [ -e “$A” ]:是文件测试,判断文件"123"是否存在。
双括号[[ ]]与单括号[]区别:
- 双括号中用
&&和||表示逻辑与和逻辑或;而单括号中用-a和-o表示逻辑与和逻辑或; - 双括号支持字符串匹配,用=~操作符时支持shell的正则表达式;
- 双括号中可用匹配符:如
[[ hello == hell? ]],结果为真
数字比较
只支持数字(或值为数字的字符串)
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 true。 |
| -ne | 检测两个数是否相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
[ 5 -ne 3 ] 返回 true 方括号与变量以及变量与运算符之间需要有空格
字符串比较
只用于字符串比较
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否为0,不为0返回 true。 | [ -z $a ] 返回 true。 |
| str | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
如,以a="test"为例
[ -z $a ] # 返回 false
[ $a ] # 返回 true
文件测试
检测文件的各种属性
-b file:文件是否是块设备文件,如果是,则返回 true。-c file:文件是否是字符设备文件,如果是,则返回 true。-d file:文件是否是目录,如果是,则返回 true。-f file:文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。-r file:文件是否可读,如果是,则返回 true。-w file:文件是否可写,如果是,则返回 true。-x file:文件是否可执行,如果是,则返回 true。-s file:文件是否为空(文件大小是否大于0),不为空返回 true。-e file:文件(包括目录)是否存在,如果是,则返回 true。-g file:文件是否设置了 SGID 位,如果是,则返回 true-k file:文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。-p file:文件是否是具名管道,如果是,则返回 true。-u file:文件是否设置了 SUID 位,如果是,则返回 true。
如:
[ -d $file ] # 是目录,返回true
[ -e $file ] # 文件存在,返回true
布尔运算
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
if语句
shell语句默认使用回车分隔(每条语句一行),若要在一行中输入多条语句可通过分号分隔实现。
条件语句中的测试条件默认使用方括号[ express ],注意中间的空格;如:
if [ $COUNT -eq 2 ]; then
# Command
fi
针对数字与字符串判断有扩展特性:
双括号(( expression )):用于数学表达式,内部可是任意的数学计算或比较表达式:
#COUNT=5 COUNT=2 if (($COUNT ** 2 > 10)); then ((var2 = $COUNT * 2)) echo "Large: $var2" else ((var2 = $COUNT + 10)) echo "Small: $var2" fi双方括号[[ expression ]]:用于字符串处理,expression两边要加空格:
if [[ "$a" > "$b" ]]; then echo "$a is large" elif [[ "$a" < "$b" ]]; then echo "$a is small" else echo "$a equal $b" fi
case语句
分支比较多,且判断较简单时,使用case in语句更方便:
case expression in
pattern1)
statement1
;;
pattern2)
statement2
;;
pattern3)
statement3
;;
……
*)
statementn
esac
pattern 表示匹配模式,可以是一个数字、一个字符串,甚至是一个简单的正则表达式;case 会将逐个进行匹配:
- 当与某一个模式匹配成功时,就会执行后面对应的语句,直到遇见双分号;;才停止;然后整个 case 语句就执行完了;
- 若没有匹配到任何一个模式,那么就执行
*)后面的语句; - 除最后一个分支外,其它的每个分支都必须以
;;结尾;
case支持的正则表达式:
*表示任意字符串。[abc]表示 a、b、c 三个字符中的任意一个。比如,[15ZH] 表示 1、5、Z、H 四个字符中的任意一个。[m-n]表示从 m 到 n 的任意一个字符。比如,[0-9] 表示任意一个数字,[0-9a-zA-Z] 表示字母或数字。|表示多重选择,类似逻辑运算中的或运算。比如,abc | xyz表示匹配字符串 “abc” 或者 “xyz”。
for语句
for循环有:
- 列表for循环:
for 变量 in 串行 - 类C风格的for循环:
for (())
列表for循环
依次循环执行后面列表中元素。
数字
for a in {1..10} # 等价:for a in $(seq 1 10)
do
echo "number ${a}"
done
# 添加不熟
for a in {1..10..2} #只获取奇数
字符串
list="Earth is the Home of Human! ";
for i in $list;
do
echo word is $i;
done
文件
for file in $( ls ) # for file in ./*
do
echo "file: $file"
done
类C风格
与C语言风格类似的循环:
for ((i=1;i<=10;i++))
do
echo "num is $i"
done
边栏推荐
- CMD permanently delete specified folders and files
- 980. Different path III DFS
- window下面如何安装swoole
- Say sqlyog deceived me!
- Swagger3 configuration
- Question 102: sequence traversal of binary tree
- [daily training -- Tencent selected 50] 292 Nim games
- jmeter 函数助手 — — 随机值、随机字符串、 固定值随机提取
- 【FPGA教程案例13】基于vivado核的CIC滤波器设计与实现
- @pathvariable 和 @Requestparam的详细区别
猜你喜欢
Find duplicate email addresses
JVM命令之 jstat:查看JVM统计信息
JVM命令之 jinfo:实时查看和修改JVM配置参数
PTA 天梯赛练习题集 L2-004 搜索树判断

How to improve website weight

Career experience feedback to novice programmers

Convert numbers to string strings (to_string()) convert strings to int sharp tools stoi();
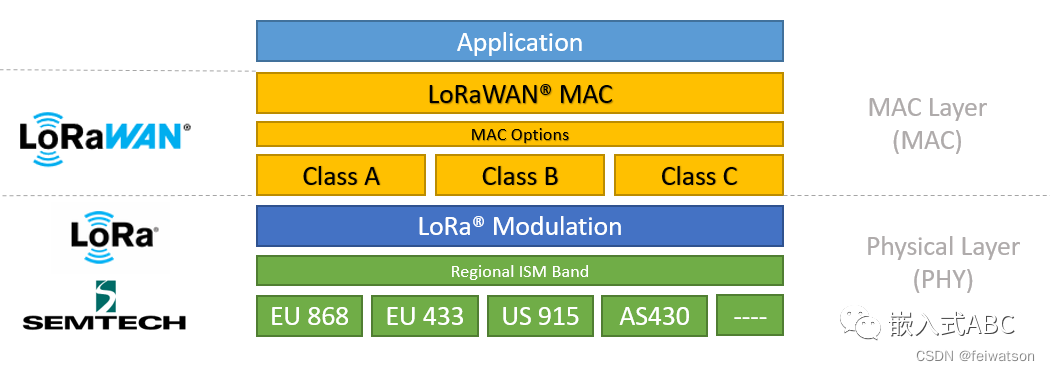
Subghz, lorawan, Nb IOT, Internet of things

蚂蚁庄园安全头盔 7.8蚂蚁庄园答案
Apple CMS V10 template /mxone Pro adaptive film and television website template
随机推荐
cf:C. Column Swapping【排序 + 模擬】
JVM命令之 jstack:打印JVM中线程快照
Chain storage of stack
Cloud acceleration helps you effectively solve attack problems!
软件测试的几个关键步骤,你需要知道
那些自损八百的甲方要求
Go语学习笔记 - gorm使用 - gorm处理错误 | Web框架Gin(十)
牙齿干细胞的存储问题(未完待续)
Career experience feedback to novice programmers
Red hat install kernel header file
PTA ladder game exercise set l2-002 linked list de duplication
Add salt and pepper noise or Gaussian noise to the picture
On the difference between FPGA and ASIC
解决pod install报错:ffi is an incompatible architecture
QT console output in GUI applications- Console output in a Qt GUI app?
Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
Dc-7 target
PTA 天梯赛练习题集 L2-002 链表去重
k8s运行oracle
Industrial Finance 3.0: financial technology of "dredging blood vessels"