当前位置:网站首页>"Parse" focalloss to solve the problem of data imbalance
"Parse" focalloss to solve the problem of data imbalance
2022-07-07 06:18:00 【ViatorSun】
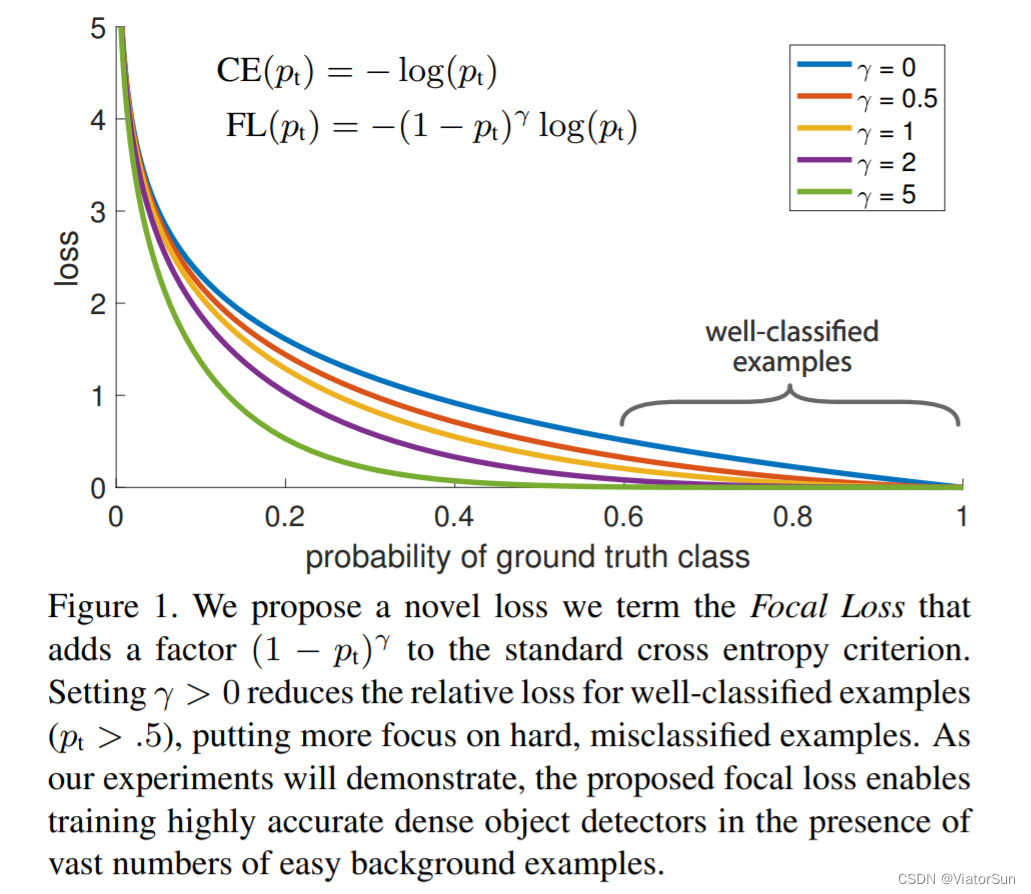
FocalLoss Appearance , Mainly to solve anchor-based (one-stage) Classification of target detection networks . Later instance segmentation is also often used .
Be careful
Here is Classification of target detection networks , It is not a simple classification problem , The two are different .
The difference lies in , For the distribution problem , A picture must belong to a certain class ; And the classification in the detection task , There are a lot of anchor Aimless ( It can be called negative sample ).
Classification task
natural K Class classification task The label of , Use one. K Length vector as label , use one-hot( perhaps +smooth, Don't think about it here ) To code , The final label is a shape like [1,…, 0, …, 0] In this way . So if you want to separate the background , Naturally, you can think of adding one 1 dimension , If the target detection task has K class , Here just use K+1 Dimension represents classification , among 1 Dimension represents no goal . For classified tasks , Finally, it is generally used softmax Laiguiyi , Make the output of all categories add up to 1.
But in the detection task , For aimless anchor, We don't want the final result to add up to 1, Instead, all probability outputs are 0. Then it can be like this , We regard a multi classification task as Multiple binary tasks (sigmoid), For each category , I output a probability , If you are close to 0 It means that it is not in this category , If you are close to 1, It stands for this anchor Is this category .
So the network output does not need to use softmax Laiguiyi , It's right K Each component of the length vector sigmoid Activate , Let its output value represent the probability of two classifications . For aimless anchor,gt All components in are 0, The probability of belonging to each class is 0, That is, marked as background .
thus ,FocalLoss The problem to be solved is not a multi classification problem , It is Multiple binary classification problems .
Formula analysis
First look at the formula : Only label y = 1 y=1 y=1 when , The formula / Cross entropy makes sense , p t p_t pt That is, the label is 1 The predicted value corresponding to / Probability of correct model classification
p t = ( 1 − p r e d _ s i g m o i d ) ∗ t a r g e t + p r e d _ s i g m o i d ∗ ( 1 − t a r g e t ) p_t = (1 - pred\_sigmoid) * target + pred\_sigmoid * (1 - target) pt=(1−pred_sigmoid)∗target+pred_sigmoid∗(1−target)
C E ( p t ) = − α t log ( p t ) F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) F L ( p ) = { − α ( 1 − p ) γ log ( p ) , i f y = 1 − ( 1 − α ) p γ log ( 1 − p ) , i f y = 0 CE(p_t)=-\alpha_t \log(p_t) \\ \quad \\ FL(p_t)=-\alpha_t(1-p_t)^\gamma \log(p_t) \\ \quad \\ FL(p) = \begin{cases} \quad -\alpha(1-p)^\gamma \log(p) &, if \quad y=1 &\\ -(1-\alpha)p^\gamma \log(1-p)&,if \quad y=0 \end{cases} CE(pt)=−αtlog(pt)FL(pt)=−αt(1−pt)γlog(pt)FL(p)={ −α(1−p)γlog(p)−(1−α)pγlog(1−p),ify=1,ify=0
- Parameters p[ The formula 3]: When p->0 when ( The probability is very low / It is difficult to distinguish which category ), Modulation factor (1-p) near 1, The loss is not affected , When p->1 when ,(1-p) near 0, So as to reduce the total number of easy samples loss The contribution of
- Parameters γ \gamma γ: When γ = 0 \gamma=0 γ=0 when ,Focal loss Is the traditional cross entropy ,
When γ \gamma γ increases , Adjustment factor ( 1 − p t ) (1-p_t) (1−pt) Also increases .
When γ \gamma γ When it is a fixed value , such as γ = 2 \gamma=2 γ=2 ️ about easy example(p>0.5) p=0.9 Of loss Smaller than the standard cross entropy 100 times , When p=0.968 when , smaller 1000+ times ;️ about hard example(p<0.5) loss smaller 4 times
In this case , hard example The weight of has increased a lot , Thus increasing the importance of what misclassification .
Experiments show that , γ = 2 , α = 0.75 \gamma=2,\alpha=0.75 γ=2,α=0.75 It works best when - α \alpha α Adjust the unbalance coefficient of positive and negative samples , γ \gamma γ Control the imbalance of difficult and easy samples
Code reappearance
In the official code , did not target = F.one_hot(target, num_clas) This line of code , This is because
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
import torch
from torch.nn import functional as F
def sigmoid_focal_loss( inputs: torch.Tensor, targets: torch.Tensor, alpha: float = -1,
gamma: float = 2, reduction: str = "none") -> torch.Tensor:
inputs = inputs.float()
targets = targets.float()
p = torch.sigmoid(inputs)
target = F.one_hot(target, num_clas+1)
ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
p_t = p * targets + (1 - p) * (1 - targets)
loss = ce_loss * ((1 - p_t) ** gamma)
if alpha >= 0:
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
loss = alpha_t * loss
if reduction == "mean":
loss = loss.mean()
elif reduction == "sum":
loss = loss.sum()
return loss
sigmoid_focal_loss_jit: "torch.jit.ScriptModule" = torch.jit.script(sigmoid_focal_loss)
Besides ,torchvision China also supports focal loss
Complete code
Official full code :https://github.com/facebookresearch/
Reference resources
- https://zhuanlan.zhihu.com/p/391186824
边栏推荐
- Red hat install kernel header file
- JVM monitoring and diagnostic tools - command line
- A very good JVM interview question article (74 questions and answers)
- Dc-7 target
- ML之shap:基于adult人口普查收入二分类预测数据集(预测年收入是否超过50k)利用shap决策图结合LightGBM模型实现异常值检测案例之详细攻略
- 软件测试知识储备:关于「登录安全」的基础知识,你了解多少?
- 3428. 放苹果
- SubGHz, LoRaWAN, NB-IoT, 物联网
- Experience of Niuke SQL
- From "running distractor" to data platform, Master Lu started the road of evolution
猜你喜欢

可极大提升编程思想与能力的书有哪些?
PowerPivot - DAX (function)

蚂蚁庄园安全头盔 7.8蚂蚁庄园答案
How to keep accounts of expenses in life

3531. 哈夫曼树

From "running distractor" to data platform, Master Lu started the road of evolution
![[SQL practice] a SQL statistics of epidemic distribution across the country](/img/ba/639a23d87094d24572a69575b565b9.png)
[SQL practice] a SQL statistics of epidemic distribution across the country
![A freshman's summary of an ordinary student [I don't know whether we are stupid or crazy, but I know to run forward all the way]](/img/fd/7223d78fff54c574260ec0da5f41d5.png)
A freshman's summary of an ordinary student [I don't know whether we are stupid or crazy, but I know to run forward all the way]
On the discrimination of "fake death" state of STC single chip microcomputer
JVM命令之 jinfo:实时查看和修改JVM配置参数
随机推荐
Ctfshow-- common posture
为不同类型设备构建应用的三大更新 | 2022 I/O 重点回顾
一名普通学生的大一总结【不知我等是愚是狂,唯知一路向前奔驰】
ST表预处理时的数组证明
VScode进行代码补全
Software testing knowledge reserve: how much do you know about the basic knowledge of "login security"?
ML's shap: Based on the adult census income binary prediction data set (whether the predicted annual income exceeds 50K), use the shap decision diagram combined with the lightgbm model to realize the
Flask1.1.4 werkzeug1.0.1 source code analysis: start the process
MySQL performance_ Schema common performance diagnosis query
Bypass open_ basedir
360 Zhiyu released 7.0 new products to create an exclusive "unified digital workspace" for the party, government and army, and central and state-owned enterprises
postgresql 数据库 timescaledb 函数time_bucket_gapfill()报错解决及更换 license
搞懂fastjson 对泛型的反序列化原理
Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
POI excel export, one of my template methods
开发者别错过!飞桨黑客马拉松第三期链桨赛道报名开启
[SOC FPGA] custom IP PWM breathing lamp
Cloud acceleration helps you effectively solve attack problems!
Say sqlyog deceived me!
生活中的开销,怎么记账合适