当前位置:网站首页>Loss function and positive and negative sample allocation in target detection: retinanet and focal loss
Loss function and positive and negative sample allocation in target detection: retinanet and focal loss
2022-07-07 05:53:00 【cartes1us】
RetinaNet
In the field of target detection , For the first time, the accuracy of single-stage algorithm exceeds that of two-stage algorithm , Namely RetinaNet.
Network structure :
The network structure designed by the author is not very innovative , This is what the article says :
The design of our RetinaNet detector shares many similarities with
previous dense detectors, in particular the concept of ‘anchors’
introduced by RPN [3] and use of features pyramids as in SSD [9] and
FPN [4]. We emphasize that our simple detector achieves top results
not based on innovations in network design but due to our novel loss.
Detection head is Classification and BBox Regression decoupling Of , And it is based on anchor frame , after FPN After that, five characteristic maps with different scales are output , Each layer corresponds to 32~512 Anchor frame of scale , And each layer is based on scale and ratios There are different combinations of 9 Seed anchor frame , Finally, the anchor frame size of the whole network is 32 ~ 813 Between . Use the offset predicted by the network relative to the anchor box to calculate BBox Methods and Faster R-CNN identical . The following figure is the picture of thunderbolt .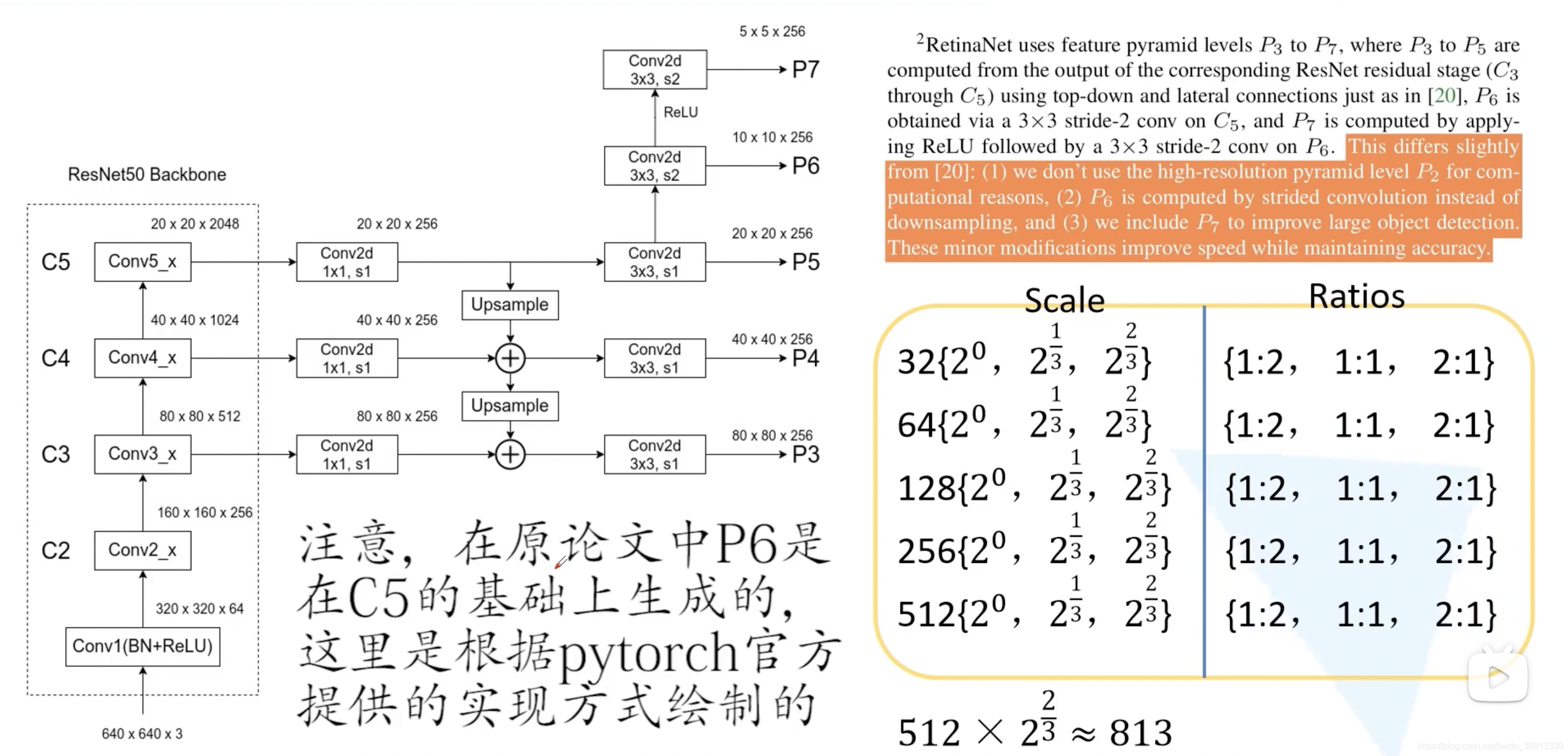
The structure diagram in the paper is as follows , Only by FPN The characteristic diagrams of three scales are drawn ,W,H,K,A Respectively represent the width of the feature map , high , Number of categories ( Does not contain background classes ), Number of anchor frames (9). 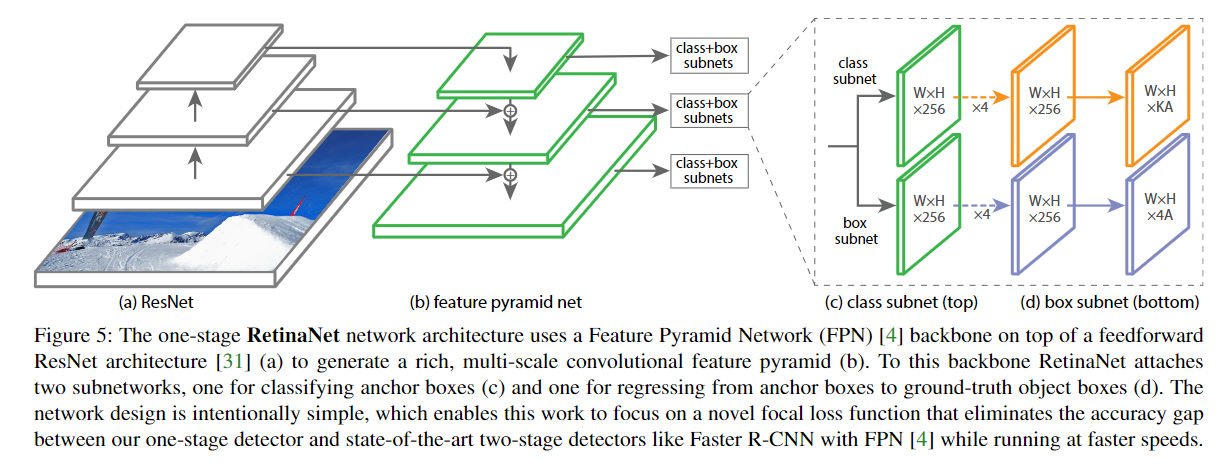
Positive and negative samples match
Positive sample : Predicted BBox And gt IoU>=0.5,
Negative sample : Predicted BBox And gt IoU<0.4,
Other samples are discarded
prospects , Background quantity imbalance
CE Variants of loss
The biggest innovation of this work :Focal loss, Rewrite the classic cross entropy loss , Apply to class subnet Branch , The weight of the loss of easily classified samples is greatly reduced , Beautiful form . In the paper γ \gamma γ Recommended 2, if γ \gamma γ take 0, be FL It degenerates into CE.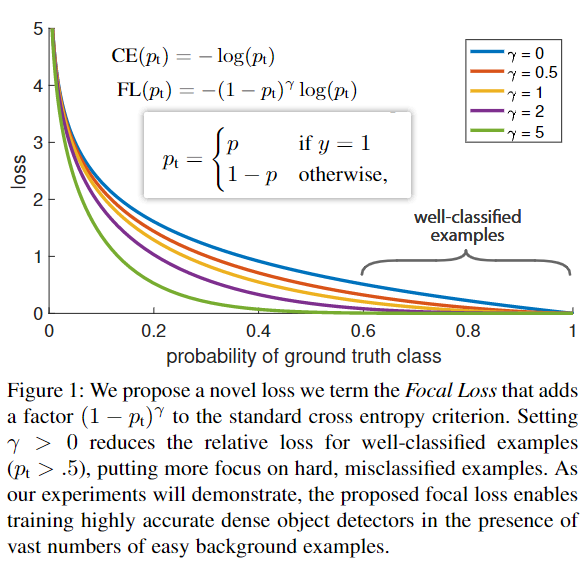
Loss :
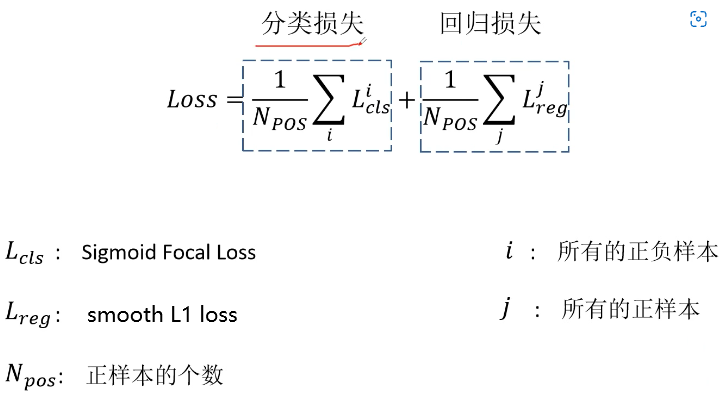
The first category loss is to calculate all samples ( Including positive and negative ) Of Focal loss, Then remove the number of positive samples N p o s N_{pos} Npos.BBox The return loss is Fast R-CNN Proposed in smooth L1 loss.
To be continued
边栏推荐
- 拼多多新店如何获取免费流量,需要从哪些环节去优化,才能有效提升店内免费流量
- 成为资深IC设计工程师的十个阶段,现在的你在哪个阶段 ?
- 【日常训练--腾讯精选50】235. 二叉搜索树的最近公共祖先
- Three level menu data implementation, nested three-level menu data
- zabbix_get测试数据库失败
- 力扣102题:二叉树的层序遍历
- Add salt and pepper noise or Gaussian noise to the picture
- Question 102: sequence traversal of binary tree
- Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
- Five core elements of architecture design
猜你喜欢
nVisual网络可视化
Five core elements of architecture design

软件测试面试技巧
分布式全局ID生成方案
Question 102: sequence traversal of binary tree
PTA 天梯赛练习题集 L2-004 搜索树判断
![R language [logic control] [mathematical operation]](/img/93/06a306561e3e7cb150d243541cc839.png)
R language [logic control] [mathematical operation]
Realize GDB remote debugging function between different network segments
Differences and introduction of cluster, distributed and microservice
C nullable type
随机推荐
make makefile cmake qmake都是什么,有什么区别?
Digital IC interview summary (interview experience sharing of large manufacturers)
如何提高网站权重
SAP ABAP BDC(批量数据通信)-018
Hcip eighth operation
Question 102: sequence traversal of binary tree
Classic questions about data storage
Web architecture design process
Data storage 3
OpenSergo 即将发布 v1alpha1,丰富全链路异构架构的服务治理能力
随机生成session_id
yarn入门(一篇就够了)
AI人脸编辑让Lena微笑
Paper reading [MM21 pre training for video understanding challenge:video captioning with pre training techniqu]
An example of multi module collaboration based on NCF
Realize GDB remote debugging function between different network segments
SQL query: subtract the previous row from the next row and make corresponding calculations
Five core elements of architecture design
SQLSTATE[HY000][1130] Host ‘host. docker. internal‘ is not allowed to connect to this MySQL server
Simple case of SSM framework