当前位置:网站首页>Data analysis - Thinking foreshadowing
Data analysis - Thinking foreshadowing
2022-07-05 23:13:00 【Dutkig】
Three parts of data analysis
Data collection
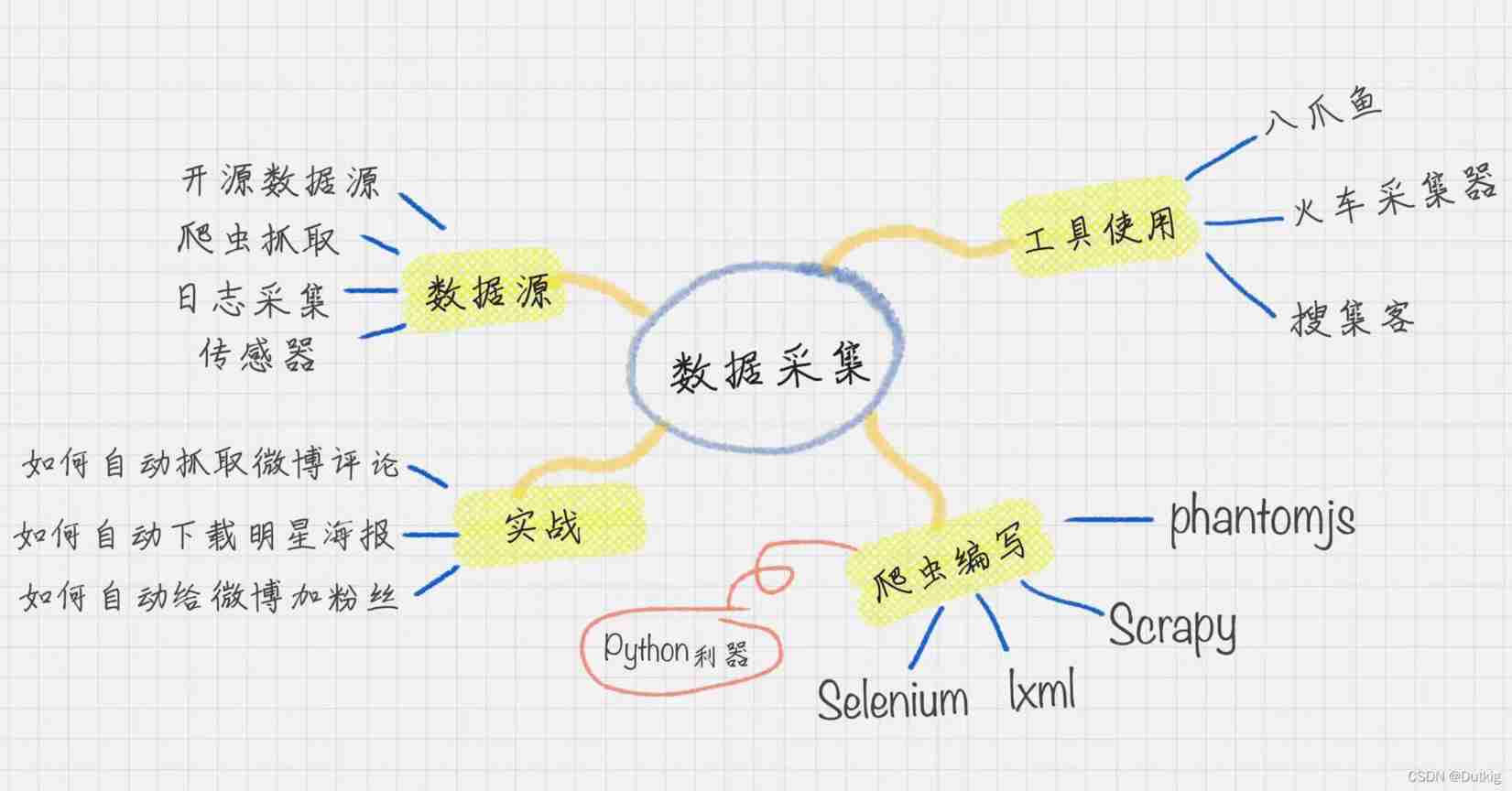
data mining
—— The core of data mining is to mine the commercial value of data , That is what we are talking about business intelligence (BI)
You need to master and understand the following contents :
① The basic flow
② Ten algorithms
③ A certain mathematical foundation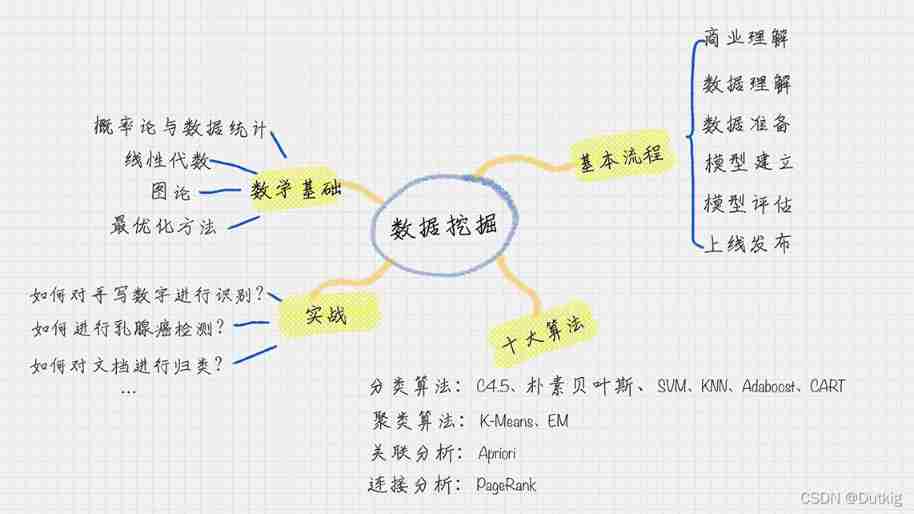
Data visualization
This part is mainly to learn how to use relevant tools
Two principles
- Try to use third-party class libraries to complete your own ideas
- Try to choose the tool with the most users ,bug Less , All the documents , Many cases
The basic flow
- Business understanding : Understand project requirements from a business perspective , Better serve the business ;
- Data understanding : Explore the data , Including data description , Data quality verification , So as to have a preliminary understanding of the data ;
- Data preparation : Data cleaning and inheritance ;
- model : Apply the mining model and optimize , In order to get better classification results ;
- Model to evaluate : Evaluate the model , Check every step of building the model , Confirm whether the model has achieved the business objectives ;
- Launch online
Ten algorithms of data mining
For different purposes , The above ten algorithms are divided into the following four categories :
- Classification algorithm :C4.5 , Naive Bayes ,SVM,KNN,Adaboost,CART;
- clustering algorithm :K—Means,EM
- Correlation analysis :Apriori
- Connection analysis :PageRank
First of all, let's have a preliminary understanding of the above 10 Algorithms :
C4.5
A decision tree algorithm , Prune in the process of creating the decision tree , And can handle continuous attributes , It can also process incomplete data .
Naive Bayes
Based on the principle of probability theory , Want to classify the given unknown objects , We need to solve the probability of each category under the condition of occurrence , Which is the biggest , Which classification do you think it belongs to .
SVM
Support vector machine (Support Vector Machine) Build a hyperplane classification model .
KNN
K Nearest neighbor algorithm (K-Nearest Neighbor) Each sample can use its latest k A neighbor represents , If a sample , its k The closest neighbors belong to the classification A, So this sample also belongs to classification A
AdaBoost
AdaBoost A joint classification model is established in the training , Build a classifier Lifting Algorithm , It allows us to form a strong classifier with multiple weak classifiers , therefore Adaboost It is also a commonly used classification algorithm .
CART
CART Represents classification and regression trees , English is Classification and Regression Trees. Like English , It builds two trees : One is a classification tree , The other is the regression tree . and C4.5 equally , It is a decision tree learning method .
Apriori
Apriori Is a kind of mining association rules (association rules) The algorithm of , It does this by mining frequent itemsets (frequent item sets) To reveal the relationship between objects , It is widely used in the fields of business mining and network security . Frequent itemsets are collections of items that often appear together , Association rules imply that there may be a strong relationship between the two objects .
K-Means
K-Means Algorithm is a clustering algorithm . You can think of it this way , Finally, I want to divide the object into K class . Suppose that in each category , There was a “ Center point ”, Opinion leader , It is the core of this category . Now I have a new point to classify , In this case, just calculate the new point and K The distance between the center points , Which center point is it near , It becomes a category .
EM
EM Algorithm is also called maximum expectation algorithm , It is a method to find the maximum likelihood estimation of parameters . The principle is : Suppose we want to evaluate parameters A And parameters B, In the initial state, both are unknown , And got it A You can get B Information about , In turn, I know B And you get A. Consider giving... First A Some initial value , So as to get B Valuation of , And then from B Starting from the valuation of , Reevaluate A The value of , This process continues until convergence .
PageRank
PageRank It originated from the calculation of the influence of the paper , If a literary theory is introduced more times , It means that the stronger the influence of this paper . Again PageRank By Google It is creatively applied to the calculation of web page weight : When a page chains out more pages , Description of this page “ reference ” The more , The more frequently this page is linked , The higher the number of times this page is referenced . Based on this principle , We can get the weight of the website .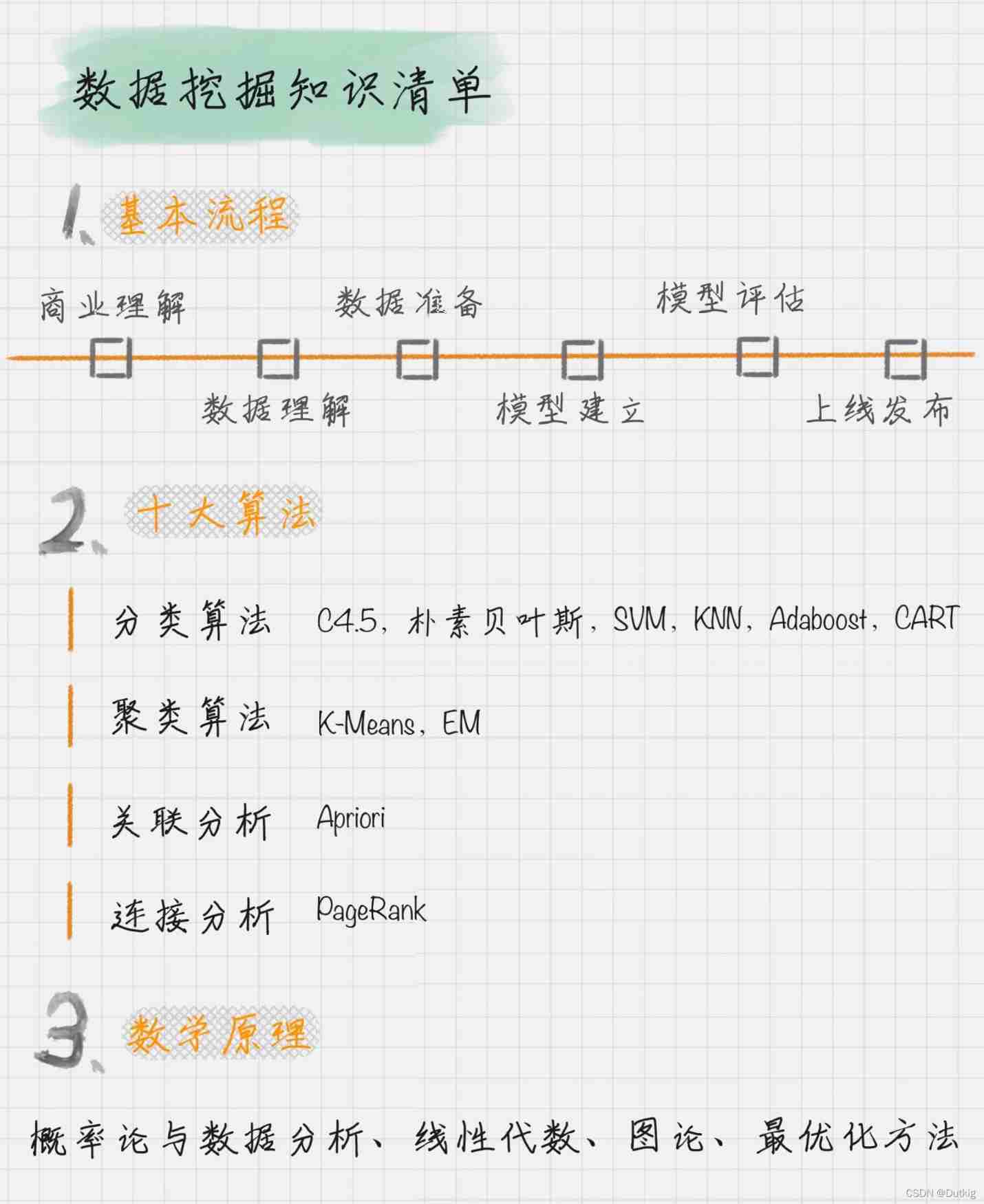
边栏推荐
- Global and Chinese markets for reciprocating seal compressors 2022-2028: Research Report on technology, participants, trends, market size and share
- Multi camera stereo calibration
- 一文搞定垃圾回收器
- 第十七周作业
- Common model making instructions
- openresty ngx_ Lua regular expression
- Using LNMP to build WordPress sites
- LabVIEW打开PNG 图像正常而 Photoshop打开得到全黑的图像
- Ultrasonic sensor flash | LEGO eV3 Teaching
- YML configuration, binding and injection, verification, unit of bean
猜你喜欢
Hcip day 12 (BGP black hole, anti ring, configuration)
![[screen recording] how to record in the OBS area](/img/34/bd06bd74edcdabaf678c8d7385cae9.jpg)
[screen recording] how to record in the OBS area
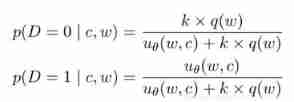
Negative sampling

数学公式截图识别神器Mathpix无限使用教程
一文搞定class的微觀結構和指令
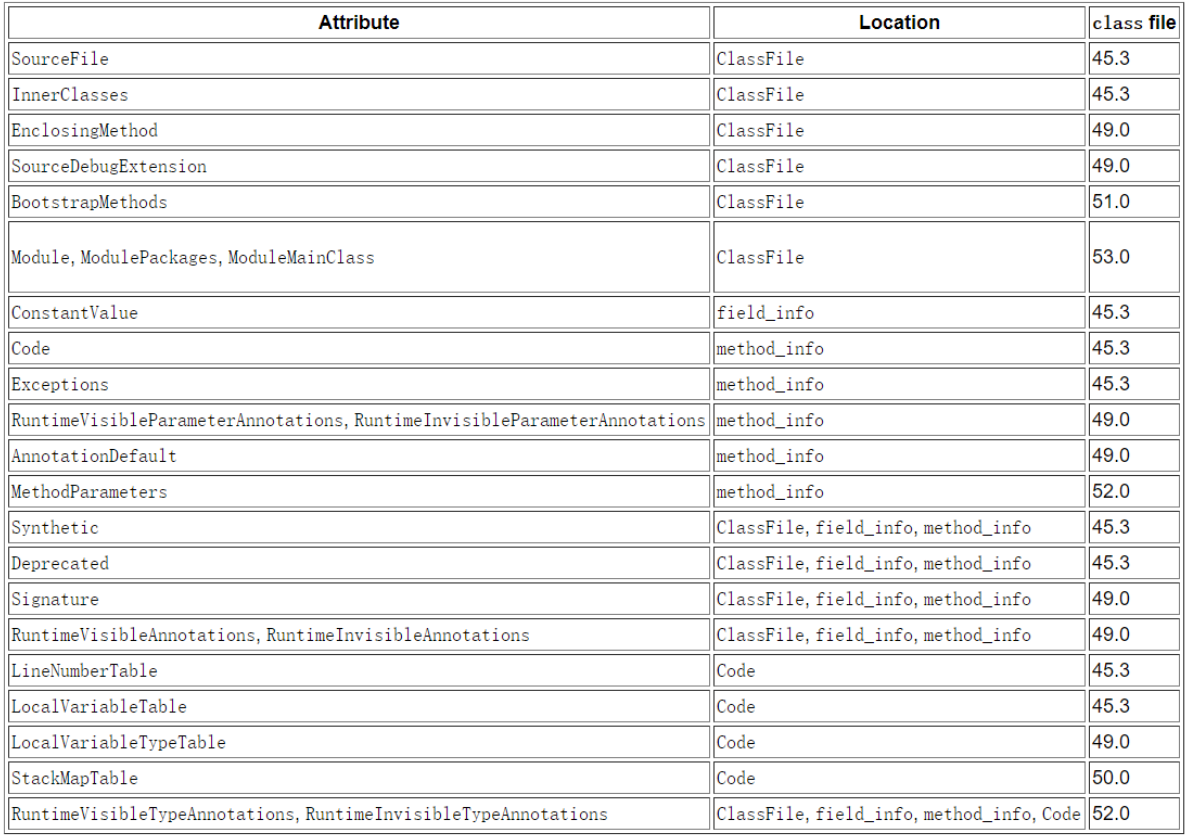
Go language implementation principle -- map implementation principle

Non rigid / flexible point cloud ICP registration
2022 registration examination for safety management personnel of hazardous chemical business units and simulated reexamination examination for safety management personnel of hazardous chemical busines
实现反向代理客户端IP透传
透彻理解JVM类加载子系统
随机推荐
Global and Chinese markets for welding products 2022-2028: Research Report on technology, participants, trends, market size and share
3D point cloud slam
Openresty ngx Lua regular expression
CorelDRAW plug-in -- GMS plug-in development -- new project -- macro recording -- VBA editing -- debugging skills -- CDR plug-in (2)
Detailed explanation of pointer and array written test of C language
【Note17】PECI(Platform Environment Control Interface)
2022 R2 mobile pressure vessel filling review simulation examination and R2 mobile pressure vessel filling examination questions
Negative sampling
查看网页最后修改时间方法以及原理简介
Element positioning of Web Automation
利用LNMP实现wordpress站点搭建
Finally understand what dynamic planning is
派对的最大快乐值
Go语言实现原理——Map实现原理
Tensor attribute statistics
There are 14 God note taking methods. Just choose one move to improve your learning and work efficiency by 100 times!
[untitled]
终于搞懂什么是动态规划的
Masked Autoencoders Are Scalable Vision Learners (MAE)
openresty ngx_lua请求响应