当前位置:网站首页>[speech processing] speech signal denoising and denoising based on MATLAB low-pass filter [including Matlab source code 1709]
[speech processing] speech signal denoising and denoising based on MATLAB low-pass filter [including Matlab source code 1709]
2022-07-05 22:46:00 【Purple light】
One 、 How to get the code
How to get the code 1:
The complete code has been uploaded to my resources :【 Voice Processing 】 be based on matlab Low pass filter speech signal denoising and denoising 【 contain Matlab Source code 1709 period 】
How to get the code 2:
By subscribing to Ziji Shenguang blog Paid column , With proof of payment , Private Blogger , This code is available .
remarks :
Subscribe to Ziji Shenguang blog Paid column , Free access to 1 Copy code ( The period of validity From the Subscription Date , Valid for three days );
Two 、 Introduction to speech processing ( Attached course assignment report )
1 Characteristics of voice signal
Through the observation and analysis of a large number of speech signals, it is found that , Voice signal mainly has the following two characteristics :
① In the frequency domain , The spectral components of speech signals are mainly concentrated in 300~3400Hz Within the scope of . Take advantage of this feature , An anti aliasing band-pass filter can be used to extract the frequency components of the speech signal in this range , Then press 8kHz The voice signal is sampled at the sampling rate of , You can get discrete speech signals .
② In the time domain , The voice signal has “ Short term ” Characteristics , That is, in general , The characteristics of speech signal change with time , But in a short time interval , The voice signal remains stable . In the voiced segment, it shows the characteristics of periodic signal , In the unvoiced segment, it shows the characteristics of random noise .
2 Voice signal acquisition
Before digitizing the voice signal , Anti aliasing pre filtering must be carried out first , There are two purposes of pre filtering :① Suppress the frequency exceeding in each domain component of input signal guidance fs/2 All the components of (fs Is the sampling frequency ), To prevent aliasing interference .② Inhibition 50Hz Power frequency interference of power supply . such , The prefilter must be a bandpass filter , Set on it 、 The lower cut-off color ratio is fH and fL, For most speech codecs ,fH=3400Hz、fL=60~100Hz、 The sampling rate is fs=8kHz; For Ding speech recognition , When used for telephone users , The index is the same as that of speech codec . When used in occasions with high or high requirements fH=4500Hz or 8000Hz、fL=60Hz、fs=10kHz or 20kHz.
In order to change the original analog voice signal into digital signal , It must go through two steps of sampling and quantization , Thus, the digital speech signal with discrete time and amplitude is obtained . Sampling is also called sampling , Is the discretization of the signal in time , That is, according to a certain time interval △t In analog signal x(t) Take its instantaneous value point by point . The Nyquist theorem must be satisfied when sampling , Sampling frequency fs Sampling must be carried out at a speed more than twice the maximum frequency of the signal under test , It is realized by multiplying the sampling pulse and the analog signal .
In the process of sampling, attention should be paid to the selection of sampling interval and signal confusion : The sampling interval of the analog signal should be determined first . How to choose △t Many technical factors need to be considered . generally speaking , The higher the sampling frequency , The denser the number of sampling points , The resulting discrete signal is closer to the original signal . But too high sampling frequency is not desirable , For fixed length (T) The signal of , Excessive amount of data collected (N=T/△t), Add unnecessary calculation workload and storage space to the computer ; If the amount of data (N) limit , The sampling time is too short , It will result in some data information being excluded . The sampling frequency is too low , Sampling points are too far apart , Then the discrete signal is not enough to reflect the waveform characteristics of the original signal , The signal cannot be restored , Cause signal confusion . According to the sampling theorem , When the sampling frequency is greater than twice the bandwidth of the signal , The sampling process does not lose information , The original signal waveform can be reconstructed without distortion from the sampled signal by using the ideal filter . Quantization is the discretization of amplitude , That is, the vibration amplitude is expressed by binary quantization level . The quantization level changes in series , The actual vibration value is a continuous physical quantity . The specific vibration value is rounded to the nearest quantization level .
The speech signal is pre filtered and sampled , from A/D The converter is transformed into a two address digital code . This anti aliasing filter is usually made in an integrated block with analog-to-digital converter , So for now , The digital quality of voice signal is guaranteed .
After collecting the voice signal , The voice signal needs to be analyzed , Such as time domain analysis of speech signal 、 Spectrum analysis 、 Spectrogram analysis and noise filtering .
3 Speech signal analysis technology
Speech signal analysis is the premise and foundation of speech signal processing , Only by analyzing the parameters that can represent the essential characteristics of speech signal , It is possible to use these parameters for efficient voice communication 、 Speech synthesis and speech recognition [8]. and , The sound quality of speech synthesis is good or bad , The level of speech recognition rate , It also depends on the accuracy and accuracy of the speech signal bridge . Therefore, speech signal analysis plays an important role in the application of speech signal processing .
Throughout the whole process of speech analysis is “ Short term analysis technology ”. because , As a whole, the characteristics of speech signal and the parameters characterizing its essential characteristics change with time , So it's an unsteady process , It cannot be analyzed and processed with digital signal processing technology for processing unstable signals . however , Because different speech is the response of a certain shape of the vocal tract formed by the movement of human oral muscles , This kind of oral muscle movement is very slow relative to speech frequency , So on the other hand , Although the phonetic multiple sign has time-varying characteristics , But in a short time range ( It is generally believed that in 10~30ms In a short time ), Its characteristics remain basically unchanged, that is, relatively stable , Because it can be regarded as a quasi steady state process , That is, the speech signal has short-term stability . Therefore, any speech signal analysis and processing must be based on “ short-term ” On the basis of . That is to say “ Short term analysis ”, The speech signal is divided into segments to analyze its characteristic parameters , Each paragraph is called a “ frame ”, The frame length is generally taken as 10~30ms. such , For the overall voice signal , The time series of characteristic parameters composed of characteristic parameters of each frame is analyzed .
According to the different properties of the analyzed parameters , Speech signal analysis can be divided into time domain analysis 、 Frequency domain analysis 、 Inverted domain analysis, etc ; The time domain analysis method is simple 、 A small amount of calculation 、 Clear physical meaning and other advantages , However, because the most important perceptual characteristics of speech signal are reflected in the power spectrum , The phase change only plays a small role , Therefore, compared with time domain analysis, frequency domain analysis is more important .
4 Time domain analysis of speech signal
The time domain analysis of speech signal is to analyze and extract the time domain parameters of speech signal . When performing speech analysis , The first and most intuitive thing is its time domain waveform . Speech signal itself is time domain signal , Therefore, time domain analysis is the earliest use , It is also the most widely used analysis method , This method directly uses the time-domain waveform of speech signal . Time domain analysis is usually used for the most basic parameter analysis and application , Such as speech segmentation 、 Preprocessing 、 Large classification, etc . The characteristics of this analysis method are :① It means that the voice signal is more intuitive 、 The physical meaning is clear .② It's easy to implement 、 Less computation .③ Some important parameters of speech can be obtained .④ Only use general equipment such as oscilloscope , Easy to use, etc .
The time domain parameters of speech signal have short-term energy 、 Short time zero crossing rate 、 Short time white correlation function and short time average amplitude difference function, etc , This is a set of basic short-time parameters of speech signal , It should be applied in various speech signal digital processing technologies [6]. The square window or Hamming window is generally used in calculating these parameters .
5 Frequency domain analysis of speech signal
The frequency domain analysis of speech signal is to analyze the frequency domain characteristics of speech signal . In a broad sense , The frequency domain analysis of speech signal includes the spectrum of speech signal 、 Power spectrum 、 Cepstrum 、 Spectrum envelope analysis, etc , The commonly used frequency domain analysis method is band-pass filter bank method 、 Fourier transform method 、 Line prediction method, etc .
3、 ... and 、 Partial source code
% Do the original time domain waveform analysis and spectrum analysis of the language signal
[y,fs,bits]=wavread('6.wav');
fs
sound(y,fs) % Playback voice signal
pause(19);
n=length(y) % Select the number of points to transform
y_p=fft(y,n); % Yes n Points are Fourier transformed to the frequency domain
f=fs*(0:n/2-1)/n; % The frequency of the corresponding point
figure(1)
subplot(2,1,1);
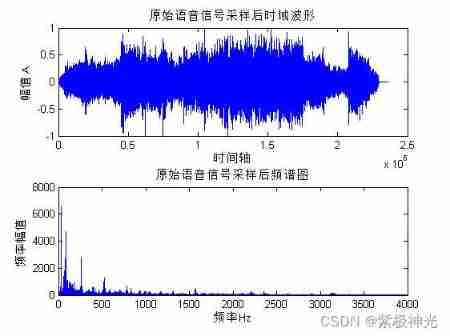
plot(y); % Time domain waveform of speech signal
title(' The time domain waveform of the original speech signal after sampling ');
xlabel(' time axis ')
ylabel(' amplitude A')
subplot(2,1,2);
plot(f,abs(y_p(1:n/2))); % Spectrum diagram of speech signal
title(' Spectrum diagram of original speech signal after sampling ');
xlabel(' frequency Hz');
ylabel(' Frequency amplitude ');
% Generate noise to audio signal
L=length(y) % Calculate the length of the audio signal
noise=0.1*randn(L,1); % Generate random noise signals of equal length ( The size of the noise here depends on the amplitude multiple of the random function )
y_z=y+noise; % Superimpose the two signals into a new signal —— Add noise treatment
sound(y_z,fs)
pause(19)
% Analyze the noisy speech signal
n=length(y); % Select the number of points to transform
y_zp=fft(y_z,n); % Yes n Points are Fourier transformed to the frequency domain
f=fs*(0:n/2-1)/n; % The frequency of the corresponding point
figure(2)
subplot(2,1,1);
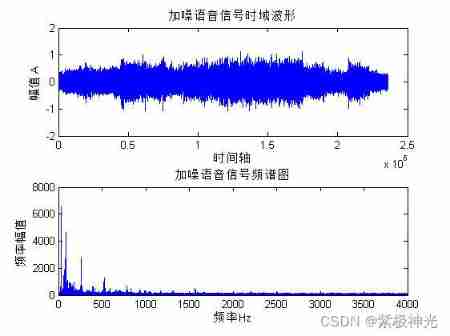
plot(y_z); % Time domain waveform of noisy speech signal
title(' Time domain waveform of noisy speech signal ');
xlabel(' time axis ')
ylabel(' amplitude A')
subplot(2,1,2);
plot(f,abs(y_zp(1:n/2))); % Spectrum of noisy speech signal
title(' Spectrum diagram of noisy speech signal ');
xlabel(' frequency Hz');
ylabel(' Frequency amplitude ');
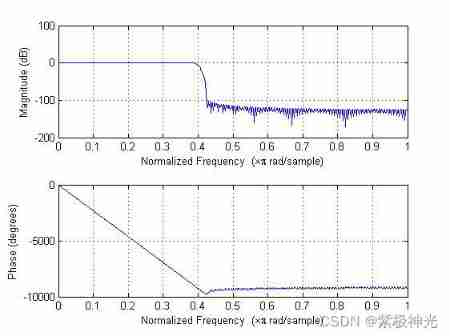
% The denoising procedure for the noisy speech signal is as follows :
fp=1500;fc=1700;As=100;Ap=1;
figure(4);
subplot(2,2,1);
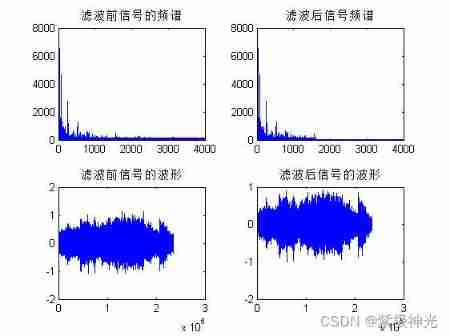
plot(f,abs(y_zp(1:n/2)));
title(' The spectrum of the signal before filtering ');
subplot(2,2,2);
plot(f,abs(X(1:n/2)));
title(' Filtered signal spectrum ');
subplot(2,2,3);
plot(y_z);
title(' The waveform of the signal before filtering ')
subplot(2,2,4);
plot(x);
title(' The waveform of the filtered signal ')
sound(x,fs,bits) % Play back the filtered audio
3、 ... and 、 Running results
5、 ... and 、matlab Edition and references
1 matlab edition
2014a
2 reference
[1] Han Jiqing , Zhang Lei , Zheng tieran . Voice signal processing ( The first 3 edition )[M]. tsinghua university press ,2019.
[2] Liu ruobian . Deep learning : Speech recognition technology practice [M]. tsinghua university press ,2019.
[3] Song Yunfei , Jiang zhancai , Wei Zhonghua . be based on MATLAB GUI Voice processing interface design [J]. Technology Information . 2013,(02)
边栏推荐
- 513. Find the value in the lower left corner of the tree
- New 3D particle function in QT 6.3
- Go语言学习教程(十五)
- Thinkphp5.1 cross domain problem solving
- 从 1.5 开始搭建一个微服务框架——日志追踪 traceId
- Overriding equals() & hashCode() in sub classes … considering super fields
- Metaverse Ape猿界应邀出席2022·粤港澳大湾区元宇宙和web3.0主题峰会,分享猿界在Web3时代从技术到应用的文明进化历程
- Platformio create libopencm3 + FreeRTOS project
- 2022.02.13 - SX10-30. Home raiding II
- 2022 Software Test Engineer salary increase strategy, how to reach 30K in three years
猜你喜欢
Distance entre les points et les lignes
Exponential weighted average and its deviation elimination
![[untitled]](/img/98/aa874a72f33edf416f38cb6e92f654.png)
[untitled]
2022软件测试工程师涨薪攻略,3年如何达到30K
2022 Software Test Engineer salary increase strategy, how to reach 30K in three years
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
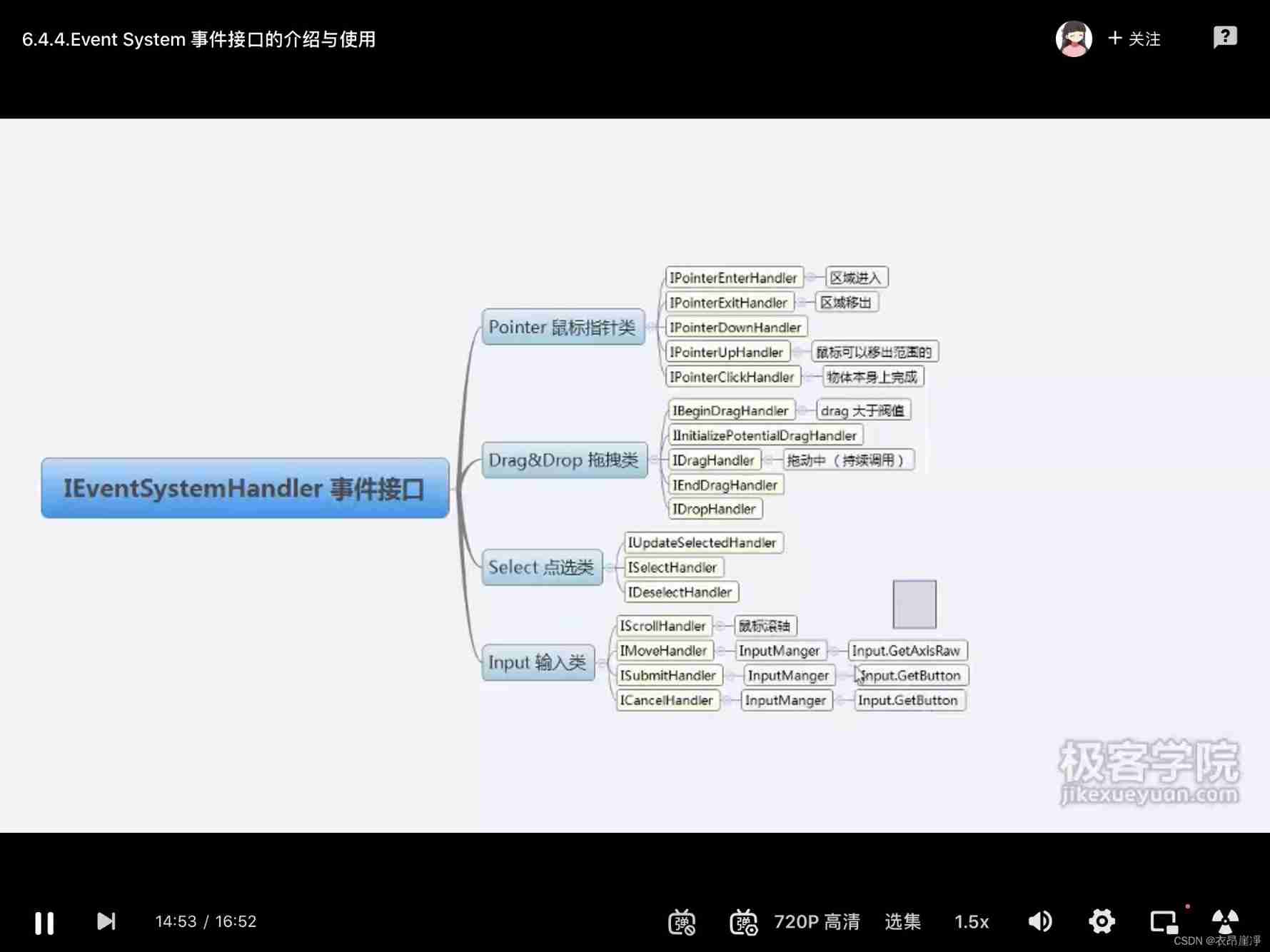
Ieventsystemhandler event interface
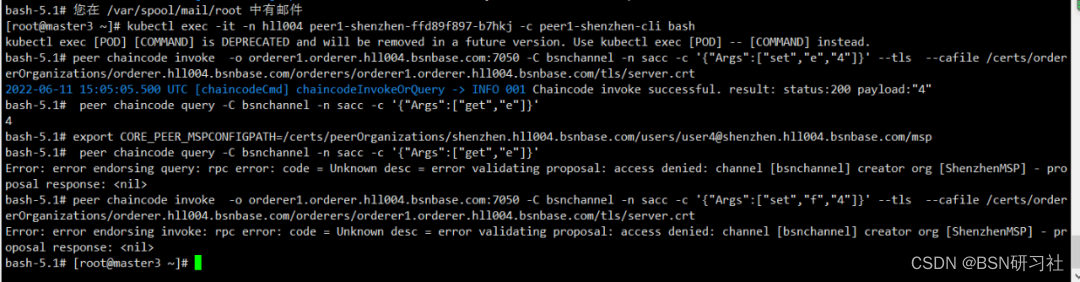
Practice: fabric user certificate revocation operation process

Wonderful review of the digital Expo | highlight scientific research strength, and Zhongchuang computing power won the digital influence enterprise award
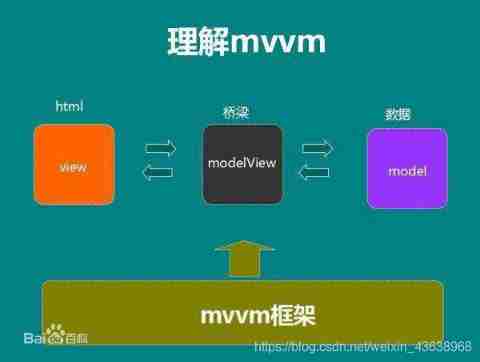
The difference between MVVM and MVC
随机推荐
Postman core function analysis - parameterization and test report
Metasploit (MSF) uses MS17_ 010 (eternal blue) encoding:: undefined conversionerror problem
Unity Max and min constraint adjustment
Starting from 1.5, build a micro Service Framework -- log tracking traceid
Google Maps case
[groovy] groovy dynamic language features (automatic type inference of function arguments in groovy | precautions for function dynamic parameters)
Shelved in TortoiseSVN- Shelve in TortoiseSVN?
VIM tail head intercept file import
二叉树(三)——堆排序优化、TOP K问题
Vcomp110.dll download -vcomp110 What if DLL is lost
點到直線的距離直線的交點及夾角
Tiktok__ ac_ signature
Understand the basic concept of datastore in Android kotlin and why SharedPreferences should be stopped in Android
Opencv judgment points are inside and outside the polygon
audiopolicy
点到直线的距离直线的交点及夹角
如何创建线程
Global and Chinese market of networked refrigerators 2022-2028: Research Report on technology, participants, trends, market size and share
Event trigger requirements of the function called by the event trigger
700. Search in a Binary Search Tree. Sol