当前位置:网站首页>MySQL 索引检索原理和B+Tree数据结构详解
MySQL 索引检索原理和B+Tree数据结构详解
2022-08-03 05:11:00 【张童瑶】
思考
试想下,如果MySQL中没有数据结构,那么查询过程会是个什么样的?
假设,表格中的圆圈,都是每一行数据,然后查询的话,得每次去一个一个比对数据,如果最后一个是想要的数据,那么得比对7次,如果2000万条数据呢?是不是很可怕?所以MySQL中的数据结构就起到了至关的作用(图有些潦草,不过不影响我单手开法拉利!~)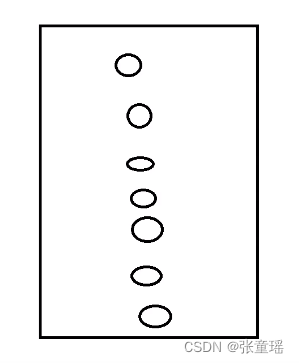
数据结构
二叉树
首二叉树中数据必须是有序的,二叉树必须是有一个跟,在根父级下面,数据比父级大的,放左边,小的放右边,以此类推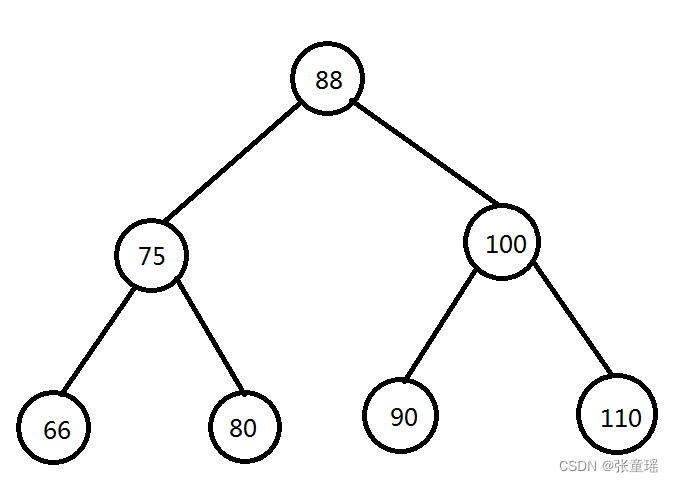
二叉树查找原理:如果查询数据为66,那么只需要比对2次,就可以查到,剩下的,100、90、110这些数据就不用在比对了,效率高的不是一点半点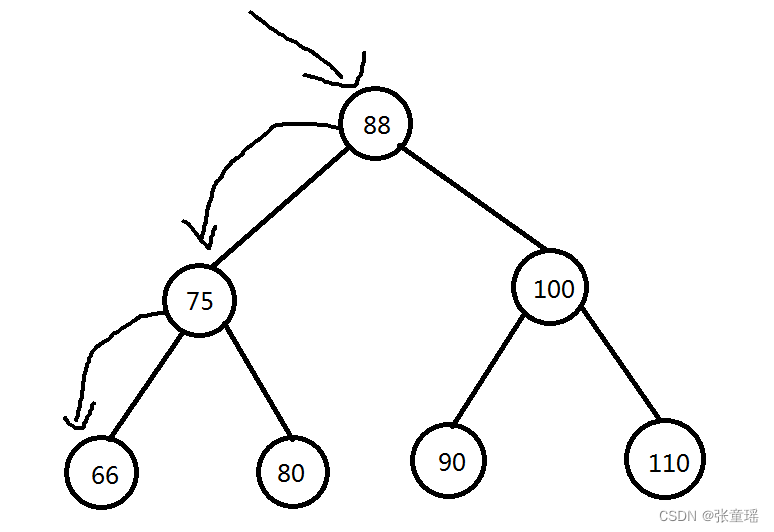
如果数据库表中的数据再多,直接继续在二叉树中分叉就可以了,不管再多多少数据,只要用到二叉树就在多比对一次,就无需在做多次比对了,这就是二叉树数据结构。skr~
如果数据是2000万条,在二叉树中又分很多叉,会很占用IO的,性能极地,显然这种数据结构是不够用的,然后网上大神又延伸了BTree数据结构!
BTree
BTree又叫平衡多路搜索树,它不仅有二叉,还有n个叉,它是多路平衡树,它也有序的数据结构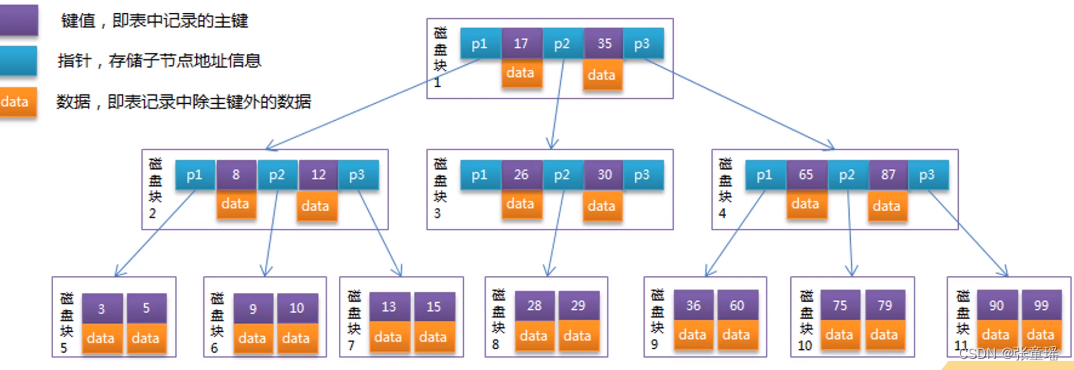
区别就是通过二叉树,把一个圈,一个单行数据变为一个BTree数据结构的区块,就是BTree根父节点可以存储多个数据,形成区块。
区块里面可以有主键、子节点的指针、数据,主键都对应一个data数据,因为有多叉了,所以必须得用指针来记录子节点!
使用BTree查找数据原理:采用的二分查找法,大白话就是一半一半的去查,比如说我查找一个,键值28的数据:
- 首先查找28在17和35的区间,找到是p2子节点
- 然后去单独加载p2的节点
- 再p2节点中查找28又在26和30之间子节点
- 再去单独加载下面子节点,找到28这个data数据
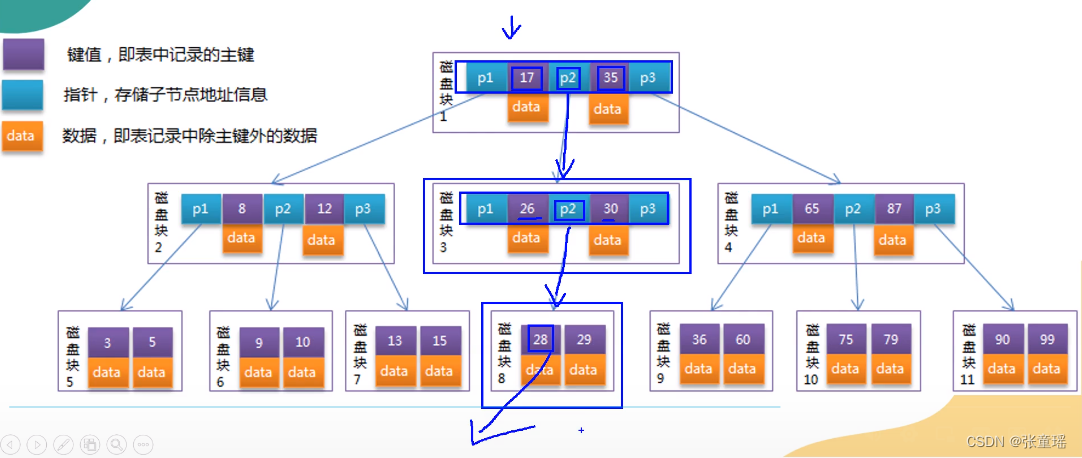
相比之前二叉树来说,IO次数减少,采用这区块分叉树,避免二叉树多层判断,提高IO性能
这种方式少数量可以实现性能提升,但是有个缺陷,就是每个区块有大小限制,16kb,里面又有数据又有键值、又有指针,本来有50个子节点,因为同时存储数据导致指针减少了,只剩下20个指针,就意味着只能有20个子节点,层数会变多,IO次数少了,性能下降了,于是又双叒叕再次升级了,就是所谓的B+Tree!
B+Tree
B+Tree就是BTree的升级版,InnoDB存储引擎就是用B+Tree实现其索引结构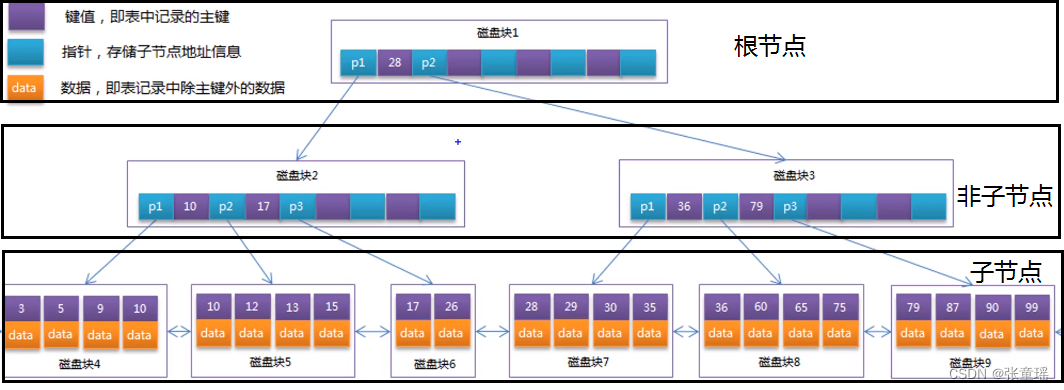
叶子节点才存储data数据,上面都是键值的指针,没有数据,指针数量增多,层数减少了,IO读写减少了,性能提高了,这个就是B+Tree。
底层叶子节点也是有序的,其实也是个链表,更擅长去取中间范围的数据,这也是MySQL中最常用的数据结构。
MySQL索引用的就是B+Tree数据结构,比如查找9,原理就是:
- 通过根节点,查找键值小于28,单独加载p1子节点区块
- 查找p1节点,发现小于10,就去单独加载下一个p1节点
- 然后再子节点力找到键值为9的data数据
ok,我话说完。
我的其他文章
我的网站
边栏推荐
猜你喜欢



随机推荐
如何不耍流氓的做运维之-SHELL脚本
flask 面试题 问题
1059 C语言竞赛 (20 分)(C语言)
Newifi路由器第三方固件玩机教程,这个路由比你想的更强大以及智能_Newifi y1刷机_smzdm
曲线特征----曲线弯曲程度的探究
运行 npm run xxx 如何触发构建命令以及启动Node服务等功能?
web安全-sql注入漏洞
Pr第二次培训笔记
ss-4.1-1个eurekaServer+1个providerPayment+1个consumerOrder
-寻找鞍点-
Odps temporary query can write SQL, turned out to a named?
The problem that the rosbag tool plotjuggler cannot open rosbag
一劳永逸解决vs编译器无法使用scanf函数
力扣561. 数组拆分
D-PHY
高可用 两地三中心
Response 重写设置返回值
【圣诞节给爱的人打印一颗圣诞树吧】超详细代码实现——圣诞树打印
-角谷猜想-
Apache DolphinScheduler版本2.0.5分布式集群的安装