当前位置:网站首页>[paper reading] semi supervised left atrium segmentation with mutual consistency training
[paper reading] semi supervised left atrium segmentation with mutual consistency training
2022-07-07 05:33:00 【xiongxyowo】
[ Address of thesis ] [ Code ] [MICCAI 21]
Abstract
Semi supervised learning has attracted great attention in the field of machine learning , Especially for the task of medical image segmentation , Because it reduces the heavy burden of collecting a large number of dense annotation data for training . However , Most existing methods underestimate challenging areas during training ( Such as small branches or fuzzy edges ) Importance . We think , These unmarked areas may contain more critical information , To minimize the uncertainty of the model prediction , And should be emphasized in the training process . therefore , In this paper , We propose a new mutual consistent network (MC-Net), For from 3D MR Semi supervised segmentation of left atrium in image . especially , our MC-Net It consists of an encoder and two slightly different decoders , The prediction difference between the two decoders is transformed into unsupervised loss by our cyclic pseudo tag scheme , To encourage mutual consistency . This mutual consistency encourages the two decoders to have consistent 、 Low entropy prediction , And enable the model to gradually capture generalization features from these unmarked challenging areas . We are in the public left atrium (LA) Our MC-Net, It has achieved impressive performance improvements by effectively utilizing unlabeled data . our MC-Net In terms of left atrial segmentation, it is superior to the recent six semi supervised methods , And in LA New and most advanced performance has been created in the database .
Method
The general idea of this paper is to design a better pseudo tag to improve the semi supervised performance , The process is as follows :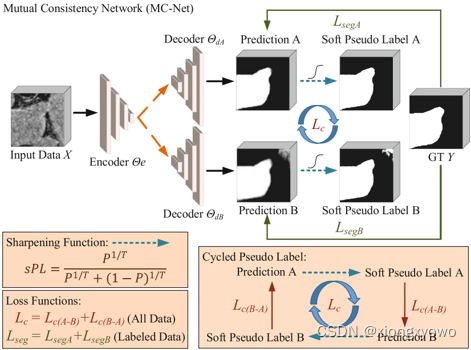
The first is how to measure uncertainty (uncertainty) The problem of . This paper believes that popular methods such as MC-Dropout You need to reason many times during training , It will bring extra time overhead , So here is a " Space for time " The way , That is, an auxiliary decoder is designed D B D_B DB, The decoder is structurally " Very simple ", It is directly multiple up sampling interpolation to obtain the final result . And the original decoder D A D_A DA Then with V − N e t V-Net V−Net bring into correspondence with .
It's like this , Without introducing large network parameters ( Because the structure of the auxiliary decoder is too simple ), The model can obtain two different results in the case of one reasoning , Obviously, the result of the auxiliary decoder will be " Worse "( This can also be seen from the picture ). In the final calculation of uncertainty, we only need to compare the differences between the two results .
Although this approach seems very simple , But it's amazing to think about it ; One is strong and the other is weak , If the sample is simple , So weak classification header can also get a better result , At this time, the difference between the two results is small , The degree of uncertainty is low . For some samples with large amount of information , The result of weak classification header is poor , At this time, there is a big difference between the two results , The uncertainty is higher .
And for the two results obtained , First, use a sharpening function to deal with it , To eliminate some potential noise in the prediction results . The sharpening function is defined as follows : s P L = P 1 / T P 1 / T + ( 1 − P ) 1 / T s P L=\frac{P^{1 / T}}{P^{1 / T}+(1-P)^{1 / T}} sPL=P1/T+(1−P)1/TP1/T When using false label supervision , Then use B To monitor A, Use A To monitor the results B. In this way, the strong decoder D A D_A DA Can learn the invariant features in the weak encoder to reduce over fitting , Weak encoder D B D_B DB You can also learn strong encoder D A D_A DA Advanced features in .
边栏推荐
- Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
- 删除文件时提示‘源文件名长度大于系统支持的长度’无法删除解决办法
- batch size设置技巧
- 京东商品详情页API接口、京东商品销量API接口、京东商品列表API接口、京东APP详情API接口、京东详情API接口,京东SKU信息接口
- Leakage relay jd1-100
- 1. AVL tree: left-right rotation -bite
- Wonderful express | Tencent cloud database June issue
- 漏电继电器JD1-100
- LabVIEW is opening a new reference, indicating that the memory is full
- [opencv] image morphological operation opencv marks the positions of different connected domains
猜你喜欢
Mapbox Chinese map address
K6el-100 leakage relay
Lombok插件
How does mapbox switch markup languages?
Harmonyos fourth training

阿里云的神龙架构是怎么工作的 | 科普图解
AOSP ~binder communication principle (I) - Overview
Two person game based on bevy game engine and FPGA
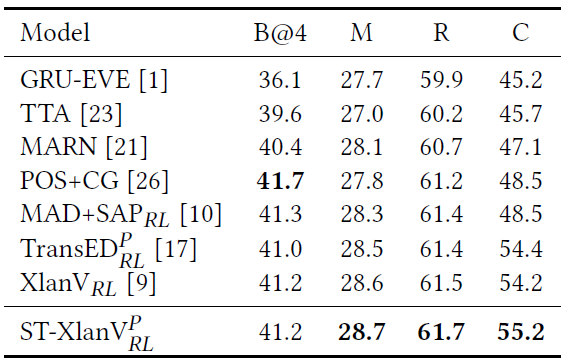
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
《2》 Label
随机推荐
Zero sequence aperture of leakage relay jolx-gs62 Φ one hundred
【js组件】date日期显示。
[JS component] custom select
人体传感器好不好用?怎么用?Aqara绿米、小米之间到底买哪个
Where is NPDP product manager certification sacred?
Mybaits之多表查询(联合查询、嵌套查询)
DJ-ZBS2漏电继电器
淘寶商品詳情頁API接口、淘寶商品列錶API接口,淘寶商品銷量API接口,淘寶APP詳情API接口,淘寶詳情API接口
Preliminary practice of niuke.com (9)
Egr-20uscm ground fault relay
Sorry, I've learned a lesson
LabVIEW is opening a new reference, indicating that the memory is full
项目经理如何凭借NPDP证书逆袭?看这里
Unity让摄像机一直跟随在玩家后上方
Zhang Ping'an: accelerate cloud digital innovation and jointly build an industrial smart ecosystem
sql优化常用技巧及理解
Photo selector collectionview
TabLayout修改自定义的Tab标题不生效问题
Leetcode (417) -- Pacific Atlantic current problem
pytest测试框架——数据驱动