当前位置:网站首页>【深度学习】3分钟入门
【深度学习】3分钟入门
2022-07-07 15:40:00 【SmartBrain】
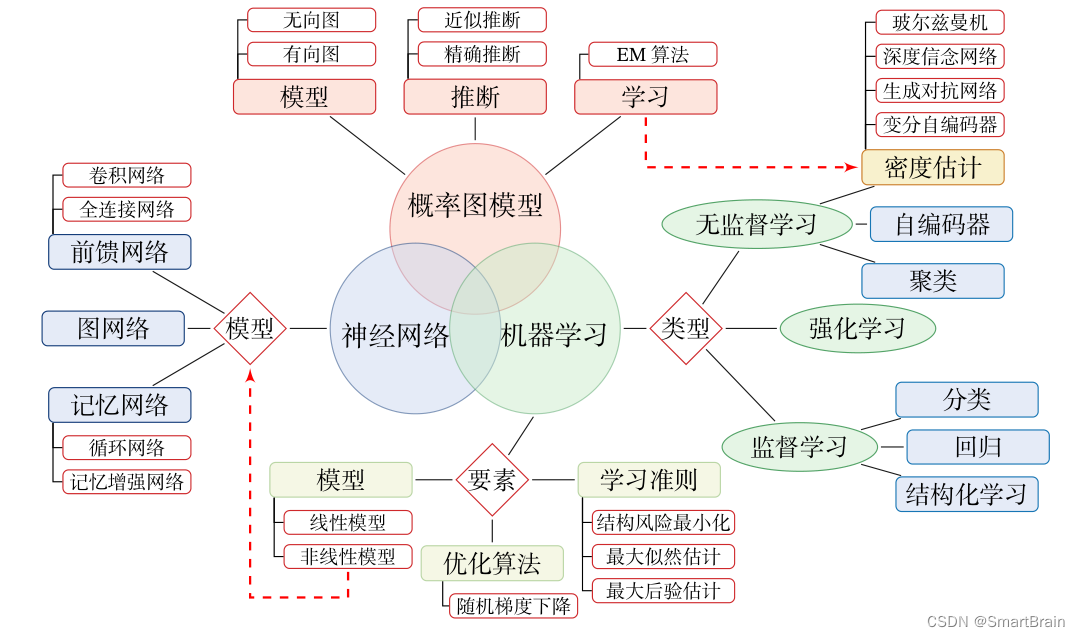
先说明AI和深度学习的关系:人工智能是一个大圈,包括计算机视觉、自然人处理、数据挖掘等;叫什么叫机器学习?画一下小圈。什么叫深度学习?相当于深度学习也是机器学习当中一部分。
机器学习( Machine Learning , ML )是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法.
机器学习是人工智能的一个重要分支,并逐渐成为推动人工智能发展的关键因素。传统的机器学习主要关注如何学习一个预测模型.一般需要首先将数据表示为一组特征( Feature ),特征的表示形式可以是连续的数值、离散的符号或其他形式。然后将这些特征输入到预测模型,并输出预测结果.这类机器学习可以看作浅层学习( Shallow Learning ).浅层学习的一个重要特点是不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取。
当我们用机器学习来解决实际任务时,会面对多种多样的数据形式,比如声音、图像、文本等.不同数据的特征构造方式差异很大.对于图像这类数据,我们可以很自然地将其表示为一个连续的向量.将图像数据表示为向量的方法有很多种,比如直接将一幅图像的所有像素值(灰度值或RGB 值)组成一个连续向量。而对于文本数据,因为其一般由离散符号组成,并且每个符号在计算机内部都表示为无意义的编码,所以通常很难找到合适的表示方式.因此,在实际任务中使用机器学习模型一般会包含以下几个步骤:
( 1 ) 数据预处理:经过数据的预处理,如去除噪声等.比如在文本分类中,去除停用词等;
( 2 ) 特征提取:从原始数据中提取一些有效的特征.比如在图像分类中,提取边缘、尺度不变特征变换( Scale Invariant Feature Transform , SIFT )特征等;
( 3 ) 特征转换:对特征进行一定的加工,比如降维和升维。很多特征转换方法也都是机器学习方法。降维包括特征抽取( Feature Extraction )和特征选择( Feature Selection )两种途径.常用的特征转换方法有主成分分析( Principal Components Analysis , PCA )、主成分分析。
深度学习它到底是做了一件什么事?就是深度学习神经网络不应该把它称之分为一种算法,应该当什么,应该当做一种特征提取的方法。在机器学习和数据挖掘或者其他任务当中,所有的智能任务最拼的是什么?最拼的其实并不是你的一个算法,是一个数据层面上,就像这个人,他要去做一桌好菜好饭,那没有一些好食材他能做出来吗?肯定也做不出来。这一点就跟大家说一点,特征是非常非常重要的,什么样的特征,什么样数据拿来之后能够更适合咱们模型更适合你。当前这个问题这个方向是更重要一些的。来总结一下,咱们继续当中基本的一个流程。
第一步,先拿数据;
第二步,讲一份工程;
第三步,选择一个算法建模;
第四步,平衡应用
深度学习和机器学习在处理特征工程上有什么样的一个区别吗?我拿出来下面数据,就是这个特征我怎么选,那个特征该怎么组合?这个特征我该怎么样去提取些信息,把数据怎么样做更容易变换,能得到更有价值的一些输入。我们经常有考虑一个问题,想那大家在考虑这个问题的过程当中,有没有想过一件事?有没有一种算法他就拿到了数据之后,他自己会在这里边选择一些特征呢?比如说现在有的算法来了之后,他就自己去学一下什么样特征好,什么样不好,他把好的特征慢慢想办法,哪些特征组合在一起合适,哪些特征怎么做分解合适怎么再做融合合适?如果有这样一种算法来去帮我们做任务,是不是我们自己来轻松多了?深度学习可以。
为什么这么说,深度学习是跟人工智能最接轨的,因为它一定程度上解决了智能问题,为什么?因为你要人工的选择数据,人工选择特征,人工的选择一个算法,在人工的得到一个结果,体现出来一些特别智能的感觉吗?给我们感觉好像在做任务过程当中,就是把这个数学公式实现出来了而已。这可是我对机器学习的理解。
但深度学习,从原始数据拿了之后,我们可以让这个网络真正地去学习一下什么样的特征,它是比较合适的,该怎么样组合是比较合适的。这个是深度学习它能够达到的一个境界。深度学习是在机器学习当中的一部分,也是现实当中最核心的一部分。其中最大的一点解决什么?解决了特征工程这个问题。到底如何做呢?
总结出来一句话,什么数据特征决定什么,决定了你当前要做一个模型。所以说,数据预处理和特征提取永远是第一步,永远是最核心的一部分而你的算法的选择,比如说我用SVM,还用逻辑回归,还用随机森林。我这个参数该怎么去调呢?这些无论你算法怎么选和参数怎么选,都只是决定了咱们要怎么样去逼近于这样一个上限?所以大家要知道一点,特殊工程是更重要一些的,这个东西要比算法比参数还要去核心的。那大家可能会问一个问题,特征我该怎么去选比如说现在,对于一些数值特征我还比较好理解。那如果是拿到一些文本数据,如果拿到一些图像数据,我也怎么选特征?这点数非常非常难。
我们要尽可能多地去想这个参数,就是不是这个参数这个特征怎么去做的?然后拿到了一个 X 之后,比如一个 x1 在逻辑会当中是不是有一个吉特页,然后有一个 x2 之及特征难,你想得到哪些特征?它对解耦影响是不是也比较难。找特征难,这是最核心的一个大难点。然后深度学习当中怎么样深度学习大家会把它当做一个黑盒子。
神经网络就是一个黑盒子,它怎么去做的?他把原始数据拿走之后,会对这个原始数据做非常复杂的各种各样变换操作,我可以统把我先把这个东西涂黑,大家可以把这个东西当做一个黑盒子,因为中间做了很多的东西,现在可能还不知道几点细节在一块慢慢去讲其中的一个细节,现在大家就需要知道一点就行为。
有了一个输入数据来之后,神经网络这个大黑盒子能够对这个输入数据自动地进行特征提取,把它俩可取出来各种各样的特征。这个特征让计算机它能够认识。比如说计算机认为怎么样能认识这个3,他就会把这个三个数字提取出来,他认识的一系列特征。所以说这里他有一个学习的过程,计算机真的会学,学习什么样的特征是他觉着最合适的。这个就是深度学习他的一个核心了以后大家就是遇到一些深度学习问题,在想的过程当中你就知道一点行了。可能你会看到就是大家到百度查的时候会听到各种各样深度去的解释。我觉得这些解释可能有些人比较片面,我建议大家按照我的形式来深度学习,它是真正的去学什么样特征是最合适的。有特征之后你后面愿意加什么?你愿意加逻辑回归不逻辑会做分类型,你甚至可以把这个特征传到 SM 当中是也行。所以这个却想解决的一个核心是怎么样去体刻。然后在他。
说一下,深度学习它都能做哪些个事?现在说的比较火的叫什么?一个无人驾驶汽车。无人驾驶汽车什么意思啊?现在这个车不需要人来开了,他自己自己去开,自己去开过程当中他是不是得看前面有没有车,后面有没有人?前车以每小时 80 公里速行驶,我以每小时 100 公里速行驶,特斯拉这公司,他那个无人驾驶汽车出过一起人命的一个事件。为什么高速路上一个车在开呢?前面停了一个拖拉机,这个拖拉机就是国外它有一些踩喷踩绘之类的,喷的跟一个蓝天白云似的,特斯拉这个无人驾驶系统没有识别出来,前面是一个拖拉机,还以为是蓝天白云,叮当一下就撞上去了,是不是出问题了?
所以,深度学习当中最大核心在于什么?对传统的一些数据挖掘任务可能用的不是那么特别多,当然这个东西是没有一个限制的,更多的是用到视觉。其实文本数据还要做建模。对于人脸检测比较多的一些人脸识别,人脸检测到机场了,以前人拿着机票,手上手上手下的,看你是不是一个人盯你半天吧,现在人家检票都不用怎么瞅你了,身份证拿出来对应摄像头看吧,人家系统说识别过了,那就能过。
深度学习,它在移动端支持不是特别好。为什么?因为深度学习它有的一个就是相当于一个缺点,计算的量太大了,咱之前说那个逻辑回归或者说随机分或者说随机分之类的,你说一共能有多少个参数撑死能有几十个是不是?但是在神经网当中,我先说一个数,大家可能听着比较吓人,成百万上千万级别的一个参数,它为什么能去自动取决特征?靠的就是这么庞大级别的一个参数,几千万的一个参数说实在的都是比较少的了,几亿的一个参数都是很常见的。
让大家来想,我接下来要用一种优化算法去优化这个深度学习的网络,优化这个神经网络,那是不是速度会非常非常慢啊?因为你千万级别的参数每一次都要调 1000 万个参数,和你每一次要调 50 个参数,那速度能一样吗?肯定不能一样。所以说深度学习最大的问题就是速度可能太慢了。在一些移动端,比如说你想要把这个一些产品移植到一些手机上,你用深度学习算法肯定这比传统机型算法强得多,但是速度它就是提不上来,这可能是它最大的一个问题。
然后我再给大家说一说,现在医学在做社会学习是特别火了,做一些比如说一些细胞当中的检测,检测一些癌细胞这东西是比较常见的。期检测细胞发生的变异,检测预期就是挫折,做一些复杂东西都什么样了。
比如,这些变脸性操作看起来好像挺复杂的过程。其实并不难,神经网络来做这件事情都是比较轻松的,还有干什么?现在大家没看过一些就是一些老片,然后新上映的比如周日职业电影,然后之前好久当时我是上什么时候记不太清。后刚入大学的时候,刚入大学的时候有那个泰坦尼克号,泰尼克号是不是出 3D 版本啊?那你说 3D 版本跟老版本有什么区别?那无非就是说 3D 版本它看的一个更清晰了,是不是更清晰的一版,谈什么是不是分辨率的一个重构在这里你让神经网络自动地去做一个上色,可以,自动地做一些超分辨率重构也是可以的。
神经网当中它的变动非常非常多,能做的事情基本上是这样,只要你基本上你能想到的东西,网络 80% 都能给你去完成的。每年在各大会议当中,神经网络它各种变形体,各种延时版本太多了,能玩的东西其实上是覆盖了,是生活当中基本上方方面面也领域了,但是核心还是在图像和文本当中做的比较多。然后这张图这张图可以说是深度学习崛起的一个点。首先给大家讲讲这个历史,李飞飞,是专门做计算机视觉的,她想能不能创建一个数据集呢?六年,她就号召了全美多少所高校,去标注图像。什么叫做收集和标注呢?咱玩这个深度学习或者积极学习,咱们是不是通常情况下都是一个有监督问题。接下来在讲的神经网络当中,所算法也都是一个有监督问题。所以说比如说比如说上面任务当中,你是不是得有一个标注什么?人脸的一个真实位置是在哪?你要做关键语言检测,你是不是在训练过程当中,你知道它真实的一个位置在哪?大家不要小看这样一个标注工作。
完成了一个数据集,叫做一个 imagine net 现在也是存在的,到时候大家可以看一下里边数据都是一个公开拍到,到时大家可以下来。百度网盘网盘里边数据非常非常大,但是我不建议大家去玩,因为太庞大,这个数据集你不做一些科研,不做一些大影项目,咱们是可能暂时用不上。
你看多少个 14m 的一个 imagine 22k 的一个种类,基本上它的一个数据量可以说是当前最庞大的一个图像分类的库了。里边涉及到的物体基本上你看 22 乘以个 1000 有多少种 2 万多种类表,包括了生活当中基本你能想到所有类表了。然后这是当时他创建了这样一个数据集,创建完数据集之后,紧接他又举办了这样一个比赛,叫做一个 imagenet 同样分类比赛,当时就是 09 年 ,深度学习这个东西压根都没人提,就没有人做这个东西。为什么?因为第一点它速度比较慢。第二点,这个东西在图样上有效果,大家之前也没玩过,因为效果可能也一般,直到12年。
12 年,有一个人叫Alex 的人,他在12年的图像分类比赛的得了一个冠军,他用了一种深度学习当中的神经网络去完成这个比赛。他当年取得的冠军第一名比第二名高出了十几个百分点。第二名的算法就是用什么?就是用咱之前说的那种机器学习算法的提升算法来去做的。这回大家突然发现一件事,神经网这个算法在图像分类任务上,在计算机视觉领域当中竟然能够达到这么好的一个效果。所以说从这个12年开始,深度学习就是可以说是正式的崛起,大家就是开始认可这个东西了。比如深度学有研究,越来越多的学者,越来越多的人来投入到这个领域当中。
咱们的计算机视觉自然处理发展得飞快起来,最主要的原因在于什么? 12 年这样一个历史转折点,每年各大会议一些论文,各大比赛的一些竞赛情况会给发出来很多优秀的文章,这些周的文章就成为了大家自己来去玩,后续实战项目,公司商业级别项目全是应用这些论文来去做的。这个就是开始的一个点。
然后这样的图大家还需要知道一点,就是深度学这个东西怎么做效果能够好一些,这里咱们来看一下。这里是百度当中看的之前他的一个报告拿出一张图,他说这样一件事,百度有很多人工智能产品,在数据规模比较小的时候,你可以看数据规模小的时候,可以说深度学习和传统人工智能算法你看有区别吗?没区别。深度学习算法贼拉慢的,传统算法还挺快的。那你说你在数据规模小的时候用深度学习算法吗?压根都不用去用了。深度学习算法要发挥余地得什么样?数据规模越大越好,通常什么样很少说几千数据集的,通常都说几万万几十万甚至上百万的数据集才能用深度学习算法来去做。
边栏推荐
- 深入浅出图解CNN-卷积神经网络
- Toast will display a simple prompt message on the program interface
- Function and usage of calendar view component
- 【可信计算】第十三次课:TPM扩展授权与密钥管理
- centos7安装mysql笔记
- 【信息安全法律法規】複習篇
- [fan Tan] after the arrival of Web3.0, where should testers go? (ten predictions and suggestions)
- LeetCode 648(C#)
- 使用popupwindow創建对话框风格的窗口
- 【信息安全法律法规】复习篇
猜你喜欢







随机推荐
The top of slashdata developer tool is up to you!!!
青年时代历练和职业发展
大笨钟(Lua)
[source code interpretation] | source code interpretation of livelistenerbus
【TPM2.0原理及应用指南】 1-3章
Lex & yacc of Pisa proxy SQL parsing
MySQL implements the query of merging two fields into one field
LeetCode 515(C#)
Jenkins发布uniapp开发的H5遇到的问题
【网络攻防原理与技术】第3章:网络侦察技术
[fan Tan] after the arrival of Web3.0, where should testers go? (ten predictions and suggestions)
麒麟信安携异构融合云金融信创解决方案亮相第十五届湖南地区金融科技交流会
LeetCode 890(C#)
Ratingbar的功能和用法
【网络攻防原理与技术】第6章:特洛伊木马
智慧物流平台:让海外仓更聪明
Sator推出Web3游戏“Satorspace” ,并上线Huobi
DevOps 的运营和商业利益指南
DNS series (I): why does the updated DNS record not take effect?
[fan Tan] those stories that seem to be thinking of the company but are actually very selfish (I: building wheels)