当前位置:网站首页>YOLOV5 study notes (2) - environment installation + operation + training
YOLOV5 study notes (2) - environment installation + operation + training
2022-07-31 02:40:00 【Birch without tears】
目录
2.2 VisDroneData set training practice
一、环境安装测试
1、创建环境
conda create -n yolo python=3.7
conda activate yolo
2、安装pytorch
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
11.3为cuda版本号
3、克隆yolov5
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
//In order to avoid installation errors, mirror installation is usedhttps://pypi.tuna.tsinghua.edu.cn/simple在githubDownload the pretrained weights file on ,将权重文件放到weights文件夹下.

测试
python detect.py --source ./inference/images/ --weights weights/yolov5s.pt --conf 0.4
二、数据集训练
2.1 yaml配置
2.1.1 数据集配置文件
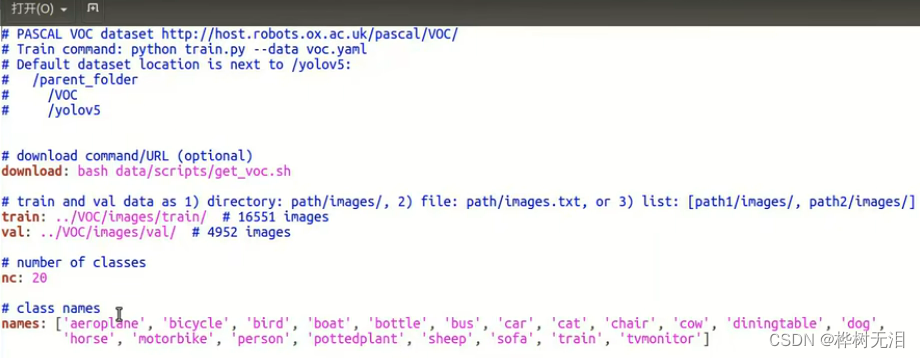
例如VOC.yaml,The paths to the training set and validation set are given in the file,种类数量为20以及名称.
2.1.2 模型配置文件
为训练模型的配置文件
gives the number of kinds of model training(Usually needs to be changed)and the structure of the network

2.2 VisDroneData set training practice
2.2.1下载数据集
Datasets`: [VisDrone] (http://aiskyeye.com/download/object-detection-2/)

under each folderannotations和image两个文件,并没有label,So need to generatelabel,好在yolov5Feature packs are provided.
2.2.2 label转yolov5
和train.py同一个目录下,新建文件visdronetoyolo.py并执行,即可自动生成label文件
from utils.general import download, os, Path
def visdrone2yolo(dir):
from PIL import Image
from tqdm import tqdm
def convert_box(size, box):
# Convert VisDrone box to YOLO xywh box
dw = 1. / size[0]
dh = 1. / size[1]
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
(dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
for f in pbar:
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
lines = []
with open(f, 'r') as file: # read annotation.txt
for row in [x.split(',') for x in file.read().strip().splitlines()]:
if row[4] == '0': # VisDrone 'ignored regions' class 0
continue
cls = int(row[5]) - 1
box = convert_box(img_size, tuple(map(int, row[:4])))
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
fl.writelines(lines) # write label.txt
dir = Path('/home/cxl/ros_yolov5/src/yolov5/data/VisDrone') # dataset文件夹下Visdrone2019文件夹路径
# Convert
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
2.2.3 训练
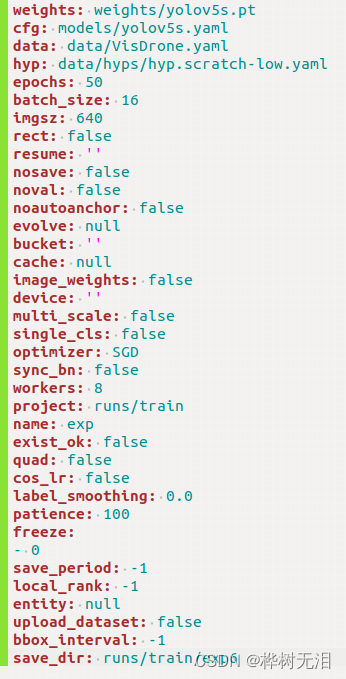
python train.py --data data/VisDrone.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 16 --epochs 50- --data data/VisDrone.yaml 数据集配置
- --cfg models/yolov5s.yaml 模型配置
- --weights weights/yolov5s.pt 预训练模型
- --batch-size 16 How many samples to train each time,Depends on your computer
- --epochs 50 How many iterations to train
This problem occurs during training
RuntimeError: result type Float can't be cast to the desired output type long int
修改【utils】中的【loss.py】里面的两处内容
1.打开你的【utils】文件下的【loss.py】
2.按【Ctrl】+【F】打开搜索功能,输入【for i in range(self.nl)】Find the following line and replace it with : 
anchors, shape = self.anchors[i], p[i].shape 3.按【Ctrl】+【F】打开搜索功能,输入【indices.append】Find the following line and replace it with :

indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid4.保存刚才的两个替换操作 再次运行

每个EpochThe second row is the loss value for each parameter,在整个Epoch训练结束后,Gives general information such as accuracy,并将这个EpochThe process file is saved in ./runs/train/exp 文件夹中
labels.jpg: Coordinate distribution of the center point of the bounding box
results.csv: 每个EpochGeneral overview after training
weights: Loaded with training weights
hyp.yaml: is the value of the hyperparameter
opt.yaml: is the configuration file for the entire training process

train_batch.jpg是一组batchGraph of the training results,我们设置一个batch是16,所以16个图片
 2.2.4 可视化
2.2.4 可视化
tensorboard --logdir=./runs
=The back is storageexpPath to the training process file
三、改成ROS节点
Note that the load network model is written outside the loop,This way you don't have to train it every time you load an image
#!/usr/bin/env python
# YOLOv5 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (MacOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
"""
import os
import roslib
import rospy
from std_msgs.msg import Header
from std_msgs.msg import String
from sensor_msgs.msg import Image
import numpy as np
import argparse
import os
import sys
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
@torch.no_grad()
class SubscribeAndPublish:
def __init__(self):
self.all_obstacle_str=''
self.sub1_name="/cam_rgb1/usb_cam/image_raw"
self.sub1= rospy.Subscriber(self.sub1_name, Image,self.callback_rgb)
self.pub1_name="detect_rgb"
self.pub1= rospy.Publisher(self.pub1_name, Image,queue_size=1)
self.model=model
self.device=device
self.img_rgb=[]
def callback_rgb(self,data):
print('callback1')
img_rgb = np.frombuffer(data.data, dtype=np.uint8).reshape(data.height, data.width, -1)
img_rgb=img_rgb[:,:,::-1]
self.img_rgb=img_rgb
cv2.imwrite('./temp/rgb/rgb.jpg',img_rgb)
img_rgb=self.run(**vars(opt))
if len(img_rgb)>0:
print('send img')
self.publish_image(self.pub1,img_rgb,'base_link')
def publish_image(self,pub, data, frame_id='base_link'):
assert len(data.shape) == 3, 'len(data.shape) must be equal to 3.'
header = Header(stamp=rospy.Time.now())
header.frame_id = frame_id
msg = Image()
msg.height = data.shape[0]
msg.width = data.shape[1]
msg.encoding = 'rgb8'
msg.data = np.array(data).tostring()
msg.header = header
msg.step = msg.width * 1 * 3
pub.publish(msg)
def run(self, weights=ROOT / 'yolov5s.pt', # model.pt path(s) #在类里面+self
source=ROOT / './temp/rgb/', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
# (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im=torch.from_numpy(im).to(self.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
return im0
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / '/home/cxl/ros_yolov5/src/yolov5/weights/yolov5x.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / './temp/rgb/', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')#概率大于0.25显示出来
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')#The probability of detecting a box
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')#实时查看结果
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')#保存标注结果
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')#保存标注结果
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes') #保存置信度
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3') #Only detect specific categories
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')#增强算法
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')#Where are the results saved
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')#Whether to save in the original folder or a new folder
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args() #parameters will be placedopt
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt,model,device):
rospy.init_node('yolov5', anonymous=True)
#####################
t=SubscribeAndPublish()
#####################
rospy.spin()
if __name__ == "__main__":
opt = parse_opt()
device = ''
weights = '/home/cxl/ros_yolov5/src/yolov5/weights/yolov5x.pt'
dnn=False
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn)
main(opt,model,device)运行
python ros_detect.py边栏推荐
猜你喜欢

全流程调度——MySQL与Sqoop

What level of software testing does it take to get a 9K job?
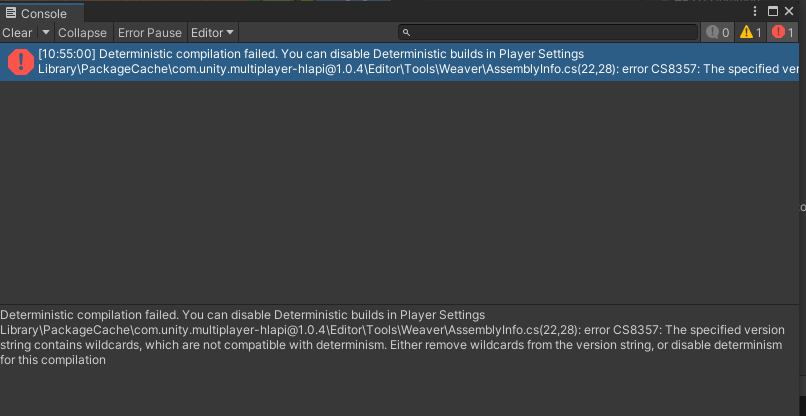
multiplayer-hlap 包有问题,无法升级的解决方案

YOLOV5 study notes (3) - detailed explanation of network module
Pythagorean tuple od js

Live Preview | KDD2022 Doctoral Dissertation Award Champion and Runner-up Dialogue
Huawei od dice js
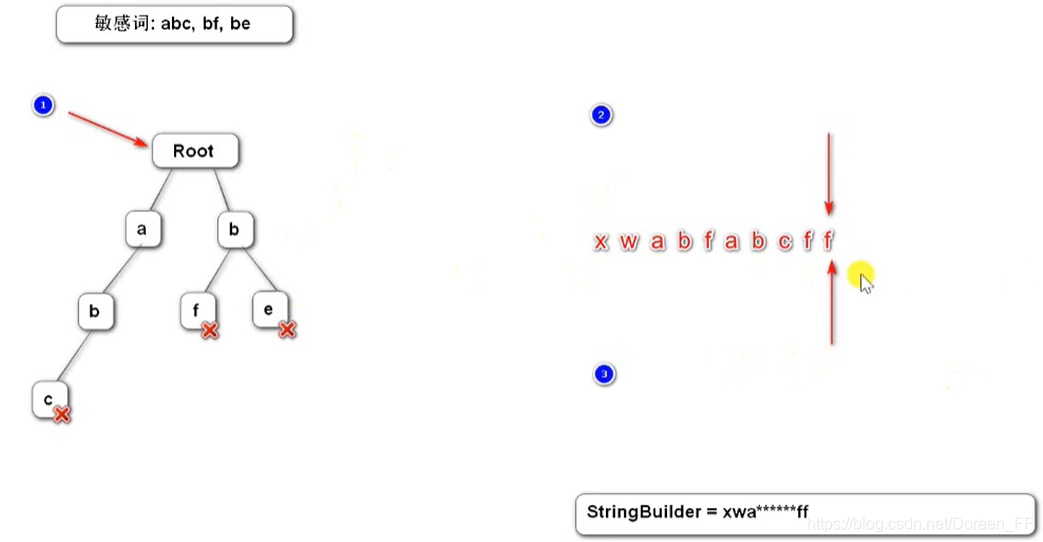
4、敏感词过滤(前缀树)
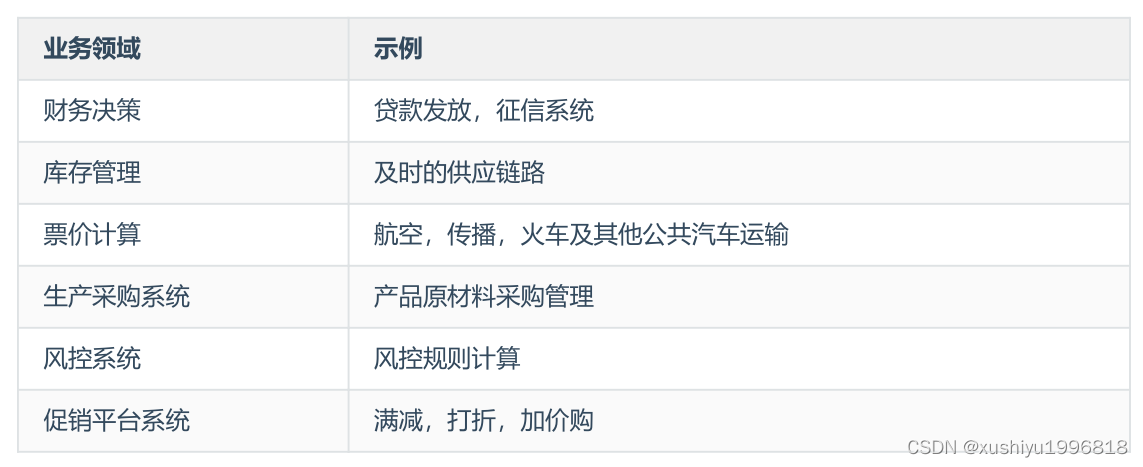
Drools basic introduction, introductory case, basic syntax
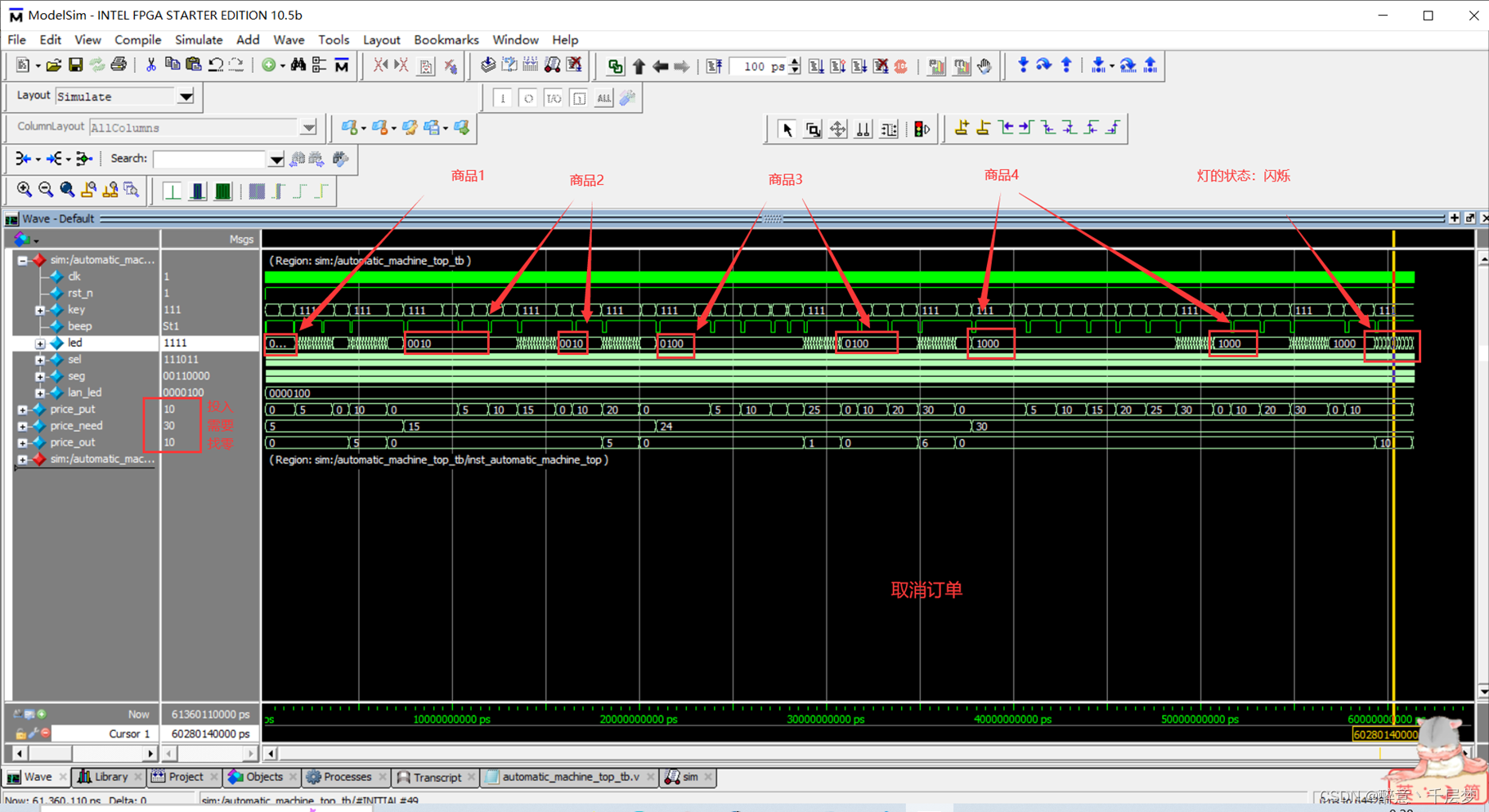
FPGA-based vending machine
随机推荐
Problems that need to be solved by the tcp framework
How to design the changing system requirements
Observer mode (1)
BAT卖不动「医疗云」:医院逃离、山头林立、行有行规
Face detection based on opencv
tcp框架需要解决的问题
Introduction to flask series 】 【 flask - using SQLAlchemy
MPPT太阳能充放电控制器数据采集-通过网关采集电池电压容量电量SOC,wifi传输
Real-time image acquisition based on FPGA
Static routing + PAT + static NAT (explanation + experiment)
拒绝加班,程序员开发的效率工具集
Software testing basic interface testing - getting started with Jmeter, you should pay attention to these things
LeetCode 1161 最大层内元素和[BFS 二叉树] HERODING的LeetCode之路
YOLOV5 study notes (3) - detailed explanation of network module
CMOS和TTL的区别?
Go 项目实战-获取多级分类下的全部商品
Intranet Infiltration - Privilege Escalation
golang GUI for nuxui — HelloWorld
TCP/IP四层模型
19. Support Vector Machines - Intuitive Understanding of Optimization Objectives and Large Spacing