当前位置:网站首页>Distributed cache
Distributed cache
2022-07-07 00:38:00 【Henrik-Yao】
List of articles
Single point Redis The problem of
- Data loss problem :Redis It's memory storage , Data may be lost when the service is restarted
- Concurrency problem : A single node Redis Although the concurrency ability is good , But it can't be satisfied, such as 618 Such a high concurrency scenario
- Recovery issues : If Redis Downtime , The service is not available , An automatic fault recovery method is needed
- Storage capacity issues :Redis Memory based , The amount of data that a single node can store is difficult to meet the needs of massive data
One .Redis Persistence
1.RDB Persistence
RDB Full name Redis Database Backup file(Redis Data backup file ), It's also called Redis Data snapshot . Simply put, it is to record all the data in memory to disk . When Redis After instance failure and restart , Read snapshot file from disk , Restore data .
The snapshot file is called RDB file , By default, it is saved in the current running Directory
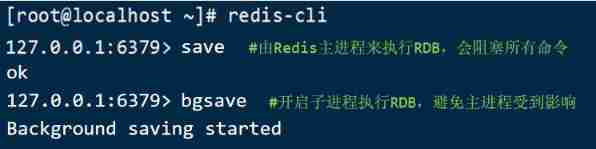 Redis There is an internal trigger RDB The mechanism of , Can be in redis.conf Found in file , The format is as follows
Redis There is an internal trigger RDB The mechanism of , Can be in redis.conf Found in file , The format is as follows
# 900 Seconds , If at least 1 individual key Be modified , execute bgsave
# If it is save "" It means to disable RDB
save 900 1
RDB Other configurations of can also be in redis.conf Set in file
# Is it compressed? , It is not recommended to open , Compression also consumes cpu, Disks are worthless
rdbcompression yes
# RDB File name
dbfilename dump.rdb
# The path and directory where the file is saved
dir ./
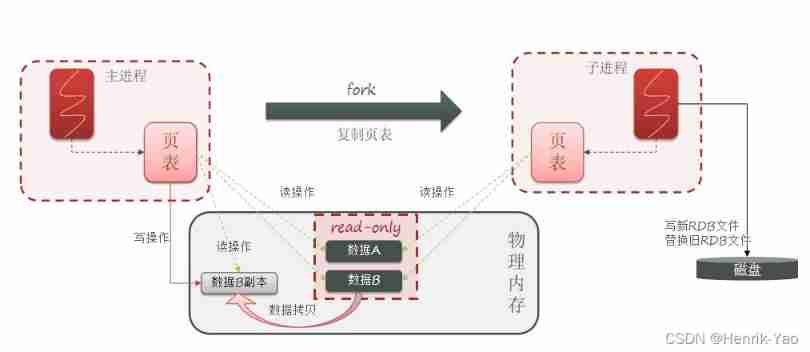
bgsave At the beginning fork The main process gets the child process , Child processes share the memory data of the main process
complete fork After reading the memory data and writing RDB file
fork It's using copy-on-write technology :
- When the main process performs a read operation , Access shared memory
- When the main process performs a write operation , Will copy a copy of the data , Perform write operations
RDB The shortcomings of :
- RDB Long execution interval , two RDB There is a risk of loss of data written between
- fork Subprocesses 、 Compress 、 Write RDB The files are time-consuming
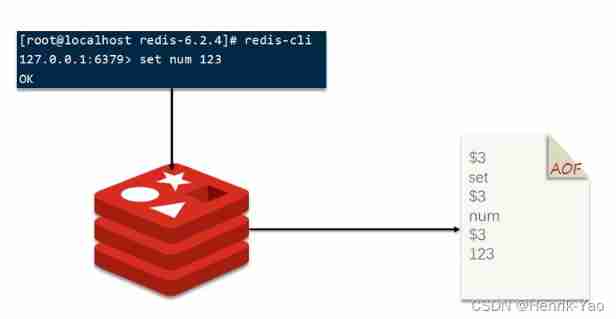
2.AOF Persistence
AOF Its full name is Append Only File( Additional documents ).Redis Every write command processed will be recorded in AOF file , It can be regarded as a command log file
AOF The default is off , Need modification redis.conf Configuration file to open AOF:
# Open or not AOF function , The default is no
appendonly yes
# AOF The name of the document
appendfilename "appendonly.aof"
AOF The frequency of command recording can also be through redis.conf File to match :
# Indicates that every time a write command is executed , Immediately record to AOF file
appendfsync always
# After the write command is executed, put it first AOF buffer , Then it means every 1 Seconds to write buffer data to AOF file , Is the default scheme
appendfsync everysec
# After the write command is executed, put it first AOF buffer , It's up to the operating system to decide when to write the contents of the buffer back to disk
appendfsync no

Because it's a record command ,AOF The document will compare with RDB The files are much bigger . and AOF Will record for the same key Multiple write operations , But only the last write operation makes sense . Through execution bgrewriteaof command , It can make AOF The file performs the rewriting function , Achieve the same effect with the least number of commands

Redis It will also be automatically rewritten when the threshold is triggered AOF file . The threshold can also be in redis.conf Middle configuration :
# AOF The file is older than the last file An increase of more than a certain percentage triggers rewriting
auto-aof-rewrite-percentage 100
# AOF What is the minimum size of the file to trigger rewriting
auto-aof-rewrite-min-size 64mb
3. contrast
RDB and AOF Each has its own advantages and disadvantages , If the requirements for data security are high , In actual development, it is often used in combination with the two 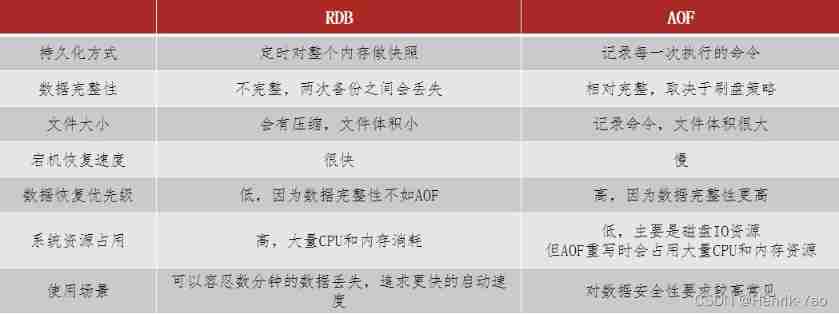
Two .Redis Master-slave
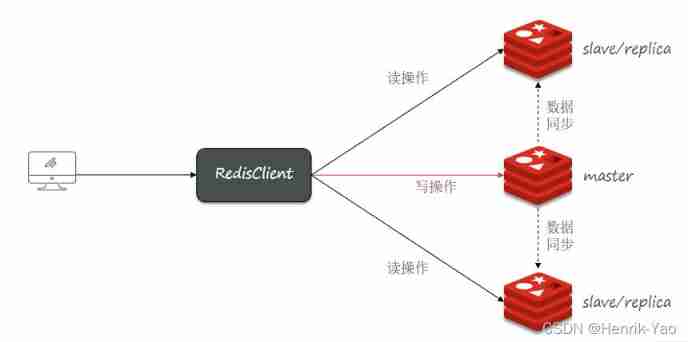
1. Master slave architecture
A single node Redis There is an upper limit to the concurrency of , We should further improve Redis Concurrency capability , You need to build a master-slave cluster , Read and write separation
2. Master slave synchronization
The first synchronization between master and slave is Full amount of synchronization :
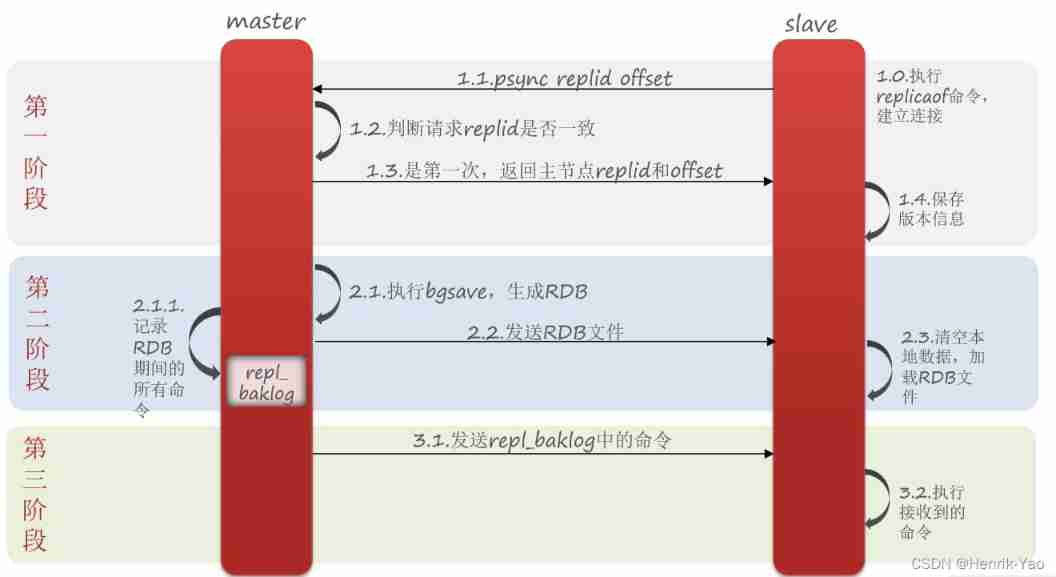
slave Do data synchronization , You have to go to master Declare your own replication id and offset,master To determine which data needs to be synchronized
- Replication Id: abbreviation replid, Is the tag of the dataset ,id Consistent means the same data set . every last master There's only one replid,slave Will inherit master Node replid
- offset: Offset , As recorded in repl_baklog The data in increases gradually .slave When the synchronization is completed, the current synchronization will also be recorded offset. If slave Of offset Less than master Of offset, explain slave The data lag behind master, You need to update
Full synchronization process :
- slave The node requests incremental synchronization
- master Node judgment replid, Find inconsistencies , Reject incremental synchronization
- master Generate complete memory data RDB, send out RDB To slave
- slave Clear local data , load master Of RDB
- master take RDB Commands during are recorded in repl_baklog, And continue to log Send the command in to slave
- slave Execute the received command , Keep up with master Synchronization between
The first synchronization between master and slave is full synchronization , But if slave Synchronization after restart , execute The incremental synchronization

repl_baklog There is an upper limit on size , When full, the oldest data will be overwritten . If slave Disconnected for too long , The data that has not been backed up is overwritten , Cannot be based on log Do incremental synchronization , Only full synchronization can be performed again
Master slave synchronization optimization
- stay master Middle configuration repl-diskless-sync yes Enable diskless replication , Avoid disk during full synchronization IO.
- Redis Don't use too much memory on a single node , Reduce RDB Resulting in too many disks IO
- To improve properly repl_baklog Size , Find out slave Achieve fault recovery as soon as possible in case of downtime , Avoid full synchronization as much as possible
- Limit one master Upper slave Number of nodes , If it's too much slave, Then the main - from - From the chain structure , Reduce master pressure
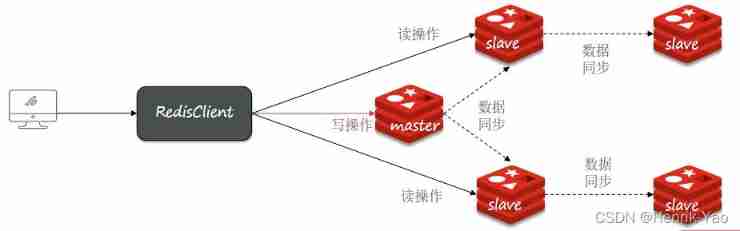
The difference between full synchronization and incremental synchronization
- Full amount of synchronization :master Generate complete memory data RDB, send out RDB To slave. Subsequent commands are recorded in repl_baklog, Send one by one to slave
- The incremental synchronization :slave Submit your own offset To master,master obtain repl_baklog In the from offset After the order to slave
Full synchronization execution time
- slave The node is connected for the first time master Node time
- slave Node disconnected for too long ,repl_baklog Medium offset When it has been covered
Incremental synchronization execution time
- slave The node is disconnected and restored , And in repl_baklog We can find offset when
3、 ... and .Redis sentry
1. Sentinel function and principle
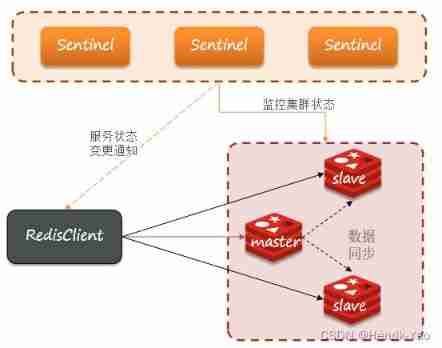
Sentinel role
Redis Provided sentinels (Sentinel) Mechanism to realize automatic fault recovery of master-slave cluster . The structure and function of the sentry are as follows :
- monitor :Sentinel Will keep checking your master and slave Whether it works as expected
- Automatic fault recovery : If master fault ,Sentinel It will slave Upgrade to master. When the fault instance recovers, it will be replaced with a new one master Mainly
- notice :Sentinel act as Redis The service discovery source of the client , When a cluster fails over , Will push the latest information to Redis The client of
Service status monitoring
Sentinel Monitor service status based on heartbeat mechanism , every other 1 Seconds to each instance of the cluster ping command :
- Subjective offline : If a sentinel The node found that an instance did not respond within the specified time , It is considered that the instance is subjective .
- Objective offline : If it exceeds the specified quantity (quorum) Of sentinel It is considered that the example is subjective , Then the instance is offline .quorum The value should preferably exceed Sentinel Half the number of instances
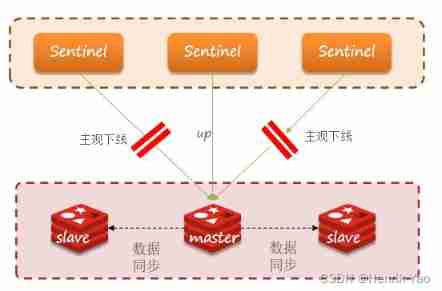
Elect a new master
Once found master fault ,sentinel Need to be in salve Choose one of them as the new master, The selection basis is as follows :
- First of all, I will judge slave Node and master Node disconnection time , If the specified value is exceeded (down-after-milliseconds * 10) Will exclude the slave node
- And then determine slave Node slave-priority value , The smaller, the higher the priority , If it is 0 Never participate in the election
- If slave-prority equally , Then judge slave Node offset value , The bigger the data, the newer , The higher the priority
- The last is judgment slave The operation of the node id size , The smaller, the higher the priority .
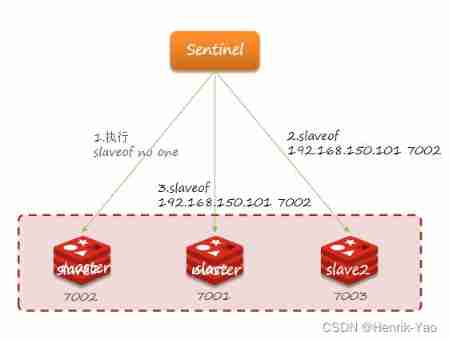
Fail over
When one of them is selected slave For the new master after ( for example slave1), The steps of failover are as follows :
- sentinel Give the alternative slave1 The node sends slaveof no one command , Let the node be master
- sentinel To all the others slave send out slaveof 192.168.150.101 7002 command , Let these slave Become new master The slave node , Start with a new master Up-sync data .
- Last ,sentinel Mark the failed node as slave, When the failed node recovers, it will automatically become a new node master Of slave node
Four .Redis Fragmentation cluster
1. Fragment cluster structure
Master slave and Sentry can solve the problem of high availability 、 The problem of high concurrent reading . But there are still two unsolved problems :
- Massive data storage problem
- The problem of high concurrency writing
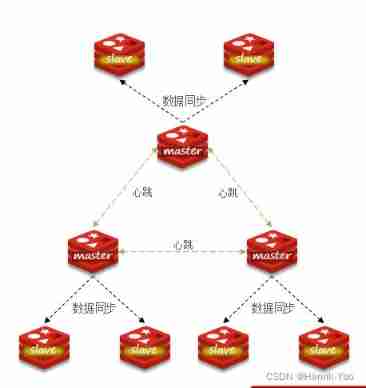
Using sharded clusters can solve the above problems , Piecemeal cluster characteristics :
- There are more than one in the cluster master, Every master Save different data
- Every master There can be multiple slave node
- master Through between ping Monitor each other's health
- Client requests can access any node of the cluster , Will eventually be forwarded to the correct node
2. Hash slot
Redis I'm going to take each of them master Nodes map to 0~16383 common 16384 Slots (hash slot) On , When you view the cluster information, you can see :
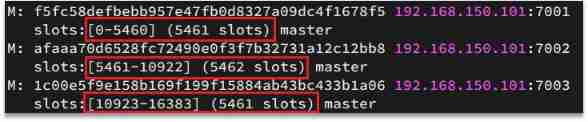
data key Not bound to a node , Instead, it is bound to the slot .redis Will be based on key Calculates the slot value for the valid part of the , There are two situations :
key Contained in the "{}", And “{}” It contains at least 1 Characters ,“{}” The part in is the effective part
key Contains no “{}”, Whole key They're all effective parts
for example :key yes num, So based on num Calculation , If it is {itcast}num, According to itcast Calculation . The calculation method is to use CRC16 The algorithm gets a hash value , Then on 16384 Remainder , The result is slot value .
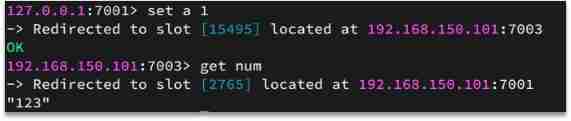
How to keep the same kind of data in the same Redis example ?
This type of data uses the same valid part , for example key Are subject to {typeId} The prefix
3. Cluster scaling
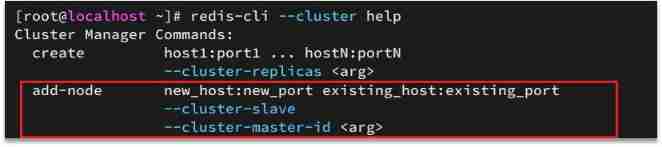
Add a node to the cluster
redis-cli --cluster Provides a lot of commands for cluster operation , You can view :
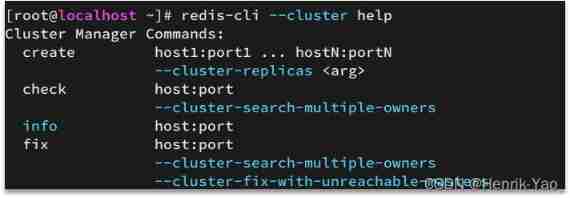
such as , Commands for adding nodes :
4. Fail over
When there is one in the cluster master What happens to downtime ?
First, the instance loses connection with other instances
Then there is a suspected outage :

Finally, make sure to go offline , Automatically raise one slave For the new master:

Manual failover
utilize cluster failover The command can manually make one of the clusters master Downtime , Switch to execution cluster failover This of the command slave node , Realize data migration without perception . The process is as follows :
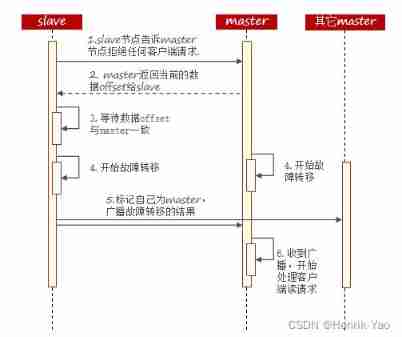
Manual Failover Three different modes are supported :
- default : The default process , Pictured 1~6 A kind of
- force: Omitted right offset Consistency check of
- takeover: Direct execution 5 A kind of , Ignore data consistency 、 Ignore master Status and others master The opinion of the
边栏推荐
- Are you ready to automate continuous deployment in ci/cd?
- AI超清修复出黄家驹眼里的光、LeCun大佬《深度学习》课程生还报告、绝美画作只需一行代码、AI最新论文 | ShowMeAI资讯日报 #07.06
- Win10 startup error, press F9 to enter how to repair?
- 【软件逆向-自动化】逆向工具大全
- Rails 4 asset pipeline vendor asset images are not precompiled
- Mujoco finite state machine and trajectory tracking
- Leecode brush questions record sword finger offer 11 Rotate the minimum number of the array
- 英雄联盟|王者|穿越火线 bgm AI配乐大赛分享
- 37页数字乡村振兴智慧农业整体规划建设方案
- iMeta | 华南农大陈程杰/夏瑞等发布TBtools构造Circos图的简单方法
猜你喜欢

Are you ready to automate continuous deployment in ci/cd?

uniapp中redirectTo和navigateTo的区别
Basic information of mujoco
Idea automatically imports and deletes package settings
Business process testing based on functional testing
Introduction to GPIO

How can computers ensure data security in the quantum era? The United States announced four alternative encryption algorithms

深度学习之数据处理

2022 PMP project management examination agile knowledge points (9)
Uniapp uploads and displays avatars locally, and converts avatars into Base64 format and stores them in MySQL database
随机推荐
Uniapp uploads and displays avatars locally, and converts avatars into Base64 format and stores them in MySQL database
MySQL learning notes (mind map)
Value Function Approximation
学习使用代码生成美观的接口文档!!!
2022/2/12 summary
On February 19, 2021ccf award ceremony will be held, "why in Hengdian?"
Common shortcuts to idea
37 page overall planning and construction plan for digital Village revitalization of smart agriculture
uniapp中redirectTo和navigateTo的区别
Mujoco Jacobi - inverse motion - sensor
Interface master v3.9, API low code development tool, build your interface service platform immediately
Leecode brushes questions and records interview questions 01.02 Determine whether it is character rearrangement for each other
Mujoco finite state machine and trajectory tracking
ldap创建公司组织、人员
一图看懂对程序员的误解:西方程序员眼中的中国程序员
Things like random
The difference between redirectto and navigateto in uniapp
Win10 startup error, press F9 to enter how to repair?
Advanced learning of MySQL -- basics -- multi table query -- inner join
JS import excel & Export Excel