当前位置:网站首页>Mmcv expanding CUDA operator beginner level chapter
Mmcv expanding CUDA operator beginner level chapter
2022-06-30 08:31:00 【Wu lele~】
List of articles
Preface
This paper mainly introduces mmcv in ops The expansion process of the operator under the folder , Because I am also a vegetable chicken , Many code details are not understood . Just give a general idea , If you have questions or are interested , Welcome to discuss :+q2541612007, Make progress together .
1、 Overall directory structure
mmcv Medium ops As shown in the figure below : In this paper , In order to facilitate the readers to understand and expand the process from easy to difficult , I will flashback and explain with roi_align operator For example .
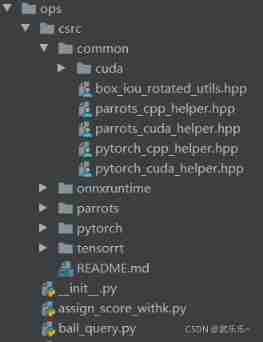
This article only focuses on common and pytorch Folder contents , because parrots and onnx and tensorrt I didn't get it. . among common It implements kernel functions and some common header files ( such as .hpp Those documents );pytorch Include cuda Kernel function declarations and cpp Encapsulate kernel functions and complete Python In the binding ; Last remaining .py The file is inherited from Function Class pytorch The file that calls the kernel function .
1、roi_align_cuda_kernel.cu
The code in this section is the bottom layer roi_align The bottom layer of the module cuda Code implementation . stay common/cuda/roi_align_cuda_kernel.cu In the file . The core is to use cuda Realized roi_align Of forward and backward Two kernel functions , here cuda I won't elaborate on the code of , I will write later when I am free . The names of these two kernel functions are == roi_align_forward_cuda_kernel and roi_align_backward_cuda_kernel==.
/*** Forward ***/
template <typename T>
__global__ void roi_align_forward_cuda_kernel()
/*** Backward ***/
template <typename T>
__global__ void roi_align_backward_cuda_kernel()
2、 Declaration and dynamic distribution of kernel functions
stay pytorch/cuda/roi_align_cuda.cu It mainly declares the two kernel functions in the previous section , And distribute them dynamically ( I don't understand this , Welcome the big guy to give directions ). Here still belongs to cuda Code section .
#include "pytorch_cuda_helper.hpp"
#include "roi_align_cuda_kernel.cuh" // Import the defined kernel function
// Kernel function declaration
void ROIAlignForwardCUDAKernelLauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
int output_size = output.numel();
int channels = input.size(1);
int height = input.size(2);
int width = input.size(3);
at::cuda::CUDAGuard device_guard(input.device());
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
// Dynamic distribution mechanism
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
input.scalar_type(), "roi_align_forward_cuda_kernel", [&] {
roi_align_forward_cuda_kernel<scalar_t>
<<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>(
output_size, input.data_ptr<scalar_t>(),
rois.data_ptr<scalar_t>(), output.data_ptr<scalar_t>(),
argmax_y.data_ptr<scalar_t>(), argmax_x.data_ptr<scalar_t>(),
aligned_height, aligned_width,
static_cast<scalar_t>(spatial_scale), sampling_ratio, pool_mode,
aligned, channels, height, width);
});
AT_CUDA_CHECK(cudaGetLastError());
}
// Kernel function Launcher Statement
void ROIAlignBackwardCUDAKernelLauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned) {
int output_size = grad_output.numel();
int channels = grad_input.size(1);
int height = grad_input.size(2);
int width = grad_input.size(3);
at::cuda::CUDAGuard device_guard(grad_output.device());
cudaStream_t stream = at::cuda::getCurrentCUDAStream();
// Dynamic distribution
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
grad_output.scalar_type(), "roi_align_backward_cuda_kernel", [&] {
roi_align_backward_cuda_kernel<scalar_t>
<<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>(
output_size, grad_output.data_ptr<scalar_t>(),
rois.data_ptr<scalar_t>(), argmax_y.data_ptr<scalar_t>(),
argmax_x.data_ptr<scalar_t>(), grad_input.data_ptr<scalar_t>(),
aligned_height, aligned_width,
static_cast<scalar_t>(spatial_scale), sampling_ratio, pool_mode,
aligned, channels, height, width);
});
AT_CUDA_CHECK(cudaGetLastError());
}
3、roi_align.cpp With the help of c++ Call the kernel function
After the above dynamic distribution , Need to use .cpp Complete the wrapper kernel , stay pytorch/roi_align.cpp Next :
// Copyright (c) OpenMMLab. All rights reserved
#include "pytorch_cpp_helper.hpp"
#ifdef MMCV_WITH_CUDA
//” Start the kernel function “ Statement of ( The naming method is the uppercase of the kernel function plus a Launcher)
void ROIAlignForwardCUDAKernelLauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned);
void ROIAlignBackwardCUDAKernelLauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned);
// This is used here roi_align_forwar_cuda Encapsulate the startup kernel .
void roi_align_forward_cuda(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignForwardCUDAKernelLauncher(
input, rois, output, argmax_y, argmax_x, aligned_height, aligned_width,
spatial_scale, sampling_ratio, pool_mode, aligned);
}
void roi_align_backward_cuda(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignBackwardCUDAKernelLauncher(
grad_output, rois, argmax_y, argmax_x, grad_input, aligned_height,
aligned_width, spatial_scale, sampling_ratio, pool_mode, aligned);
}
#endif
// The bottom is cpu Version of Launcher
void ROIAlignForwardCPULauncher(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned);
void ROIAlignBackwardCPULauncher(Tensor grad_output, Tensor rois,
Tensor argmax_y, Tensor argmax_x,
Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode,
bool aligned);
//cpp Yes cpu Version of Launcher encapsulate
void roi_align_forward_cpu(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
ROIAlignForwardCPULauncher(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
void roi_align_backward_cpu(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input,
int aligned_height, int aligned_width,
float spatial_scale, int sampling_ratio,
int pool_mode, bool aligned) {
ROIAlignBackwardCPULauncher(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
// Created a unified interface , Yes cuda Version compilation cuda edition , If not, compile cpu. United will cuda and cpu Encapsulated into an interface
// roi_align_forward and roi_align_backward.
void roi_align_forward(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
if (input.device().is_cuda()) {
#ifdef MMCV_WITH_CUDA
CHECK_CUDA_INPUT(input);
CHECK_CUDA_INPUT(rois);
CHECK_CUDA_INPUT(output);
CHECK_CUDA_INPUT(argmax_y);
CHECK_CUDA_INPUT(argmax_x);
roi_align_forward_cuda(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
#else
AT_ERROR("RoIAlign is not compiled with GPU support");
#endif
} else {
CHECK_CPU_INPUT(input);
CHECK_CPU_INPUT(rois);
CHECK_CPU_INPUT(output);
CHECK_CPU_INPUT(argmax_y);
CHECK_CPU_INPUT(argmax_x);
roi_align_forward_cpu(input, rois, output, argmax_y, argmax_x,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
}
void roi_align_backward(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned) {
if (grad_output.device().is_cuda()) {
#ifdef MMCV_WITH_CUDA
CHECK_CUDA_INPUT(grad_output);
CHECK_CUDA_INPUT(rois);
CHECK_CUDA_INPUT(argmax_y);
CHECK_CUDA_INPUT(argmax_x);
CHECK_CUDA_INPUT(grad_input);
roi_align_backward_cuda(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
#else
AT_ERROR("RoIAlign is not compiled with GPU support");
#endif
} else {
CHECK_CPU_INPUT(grad_output);
CHECK_CPU_INPUT(rois);
CHECK_CPU_INPUT(argmax_y);
CHECK_CPU_INPUT(argmax_x);
CHECK_CPU_INPUT(grad_input);
roi_align_backward_cpu(grad_output, rois, argmax_y, argmax_x, grad_input,
aligned_height, aligned_width, spatial_scale,
sampling_ratio, pool_mode, aligned);
}
}
This part mainly uses cpp Encapsulate kernel functions , stay cpp Call in Launcher function , however roi_align Yes cuda Version and cpu edition , But to unify the interface ,mmcv Unify the two versions into one interface :roi_align_forward and roi_align_backward. Decide to call according to the actual situation cpu perhaps gpu.
4、pybind binding –Python call c++
We use it c++ The implementation code should be in Python Call in , Need to use pybind Complete the binding of the two . The binding code is in mmcv in ops/csrc/pytorch/pybind.cpp In file , Paste the corresponding code .
//c++ Two function declarations in
void roi_align_forward(Tensor input, Tensor rois, Tensor output,
Tensor argmax_y, Tensor argmax_x, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned);
void roi_align_backward(Tensor grad_output, Tensor rois, Tensor argmax_y,
Tensor argmax_x, Tensor grad_input, int aligned_height,
int aligned_width, float spatial_scale,
int sampling_ratio, int pool_mode, bool aligned);
// pybind Complete the binding , use Python call c++
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("roi_align_forward", &roi_align_forward, "roi_align forward",
py::arg("input"), py::arg("rois"), py::arg("output"),
py::arg("argmax_y"), py::arg("argmax_x"), py::arg("aligned_height"),
py::arg("aligned_width"), py::arg("spatial_scale"),
py::arg("sampling_ratio"), py::arg("pool_mode"), py::arg("aligned"));
m.def("roi_align_backward", &roi_align_backward, "roi_align backward",
py::arg("grad_output"), py::arg("rois"), py::arg("argmax_y"),
py::arg("argmax_x"), py::arg("grad_input"), py::arg("aligned_height"),
py::arg("aligned_width"), py::arg("spatial_scale")}
Its meaning is to put the third section cpp File encapsulates two api: roi_align_forward and roi_align_backward utilize Python encapsulate , The package name is roi_align_forward and roi_align_backward.
5、roi_align.py
Post the core code :
import torch
import torch.nn as nn
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from torch.nn.modules.utils import _pair
from ..utils import deprecated_api_warning, ext_loader
ext_module = ext_loader.load_ext('_ext',
['roi_align_forward', 'roi_align_backward'])
class RoIAlignFunction(Function):
@staticmethod
def forward(ctx,
input,
rois,
output_size,
spatial_scale=1.0,
sampling_ratio=0,
pool_mode='avg',
aligned=True):
ext_module.roi_align_forward(
input,
rois,
output,
argmax_y,
argmax_x,
aligned_height=ctx.output_size[0],
aligned_width=ctx.output_size[1],
spatial_scale=ctx.spatial_scale,
sampling_ratio=ctx.sampling_ratio,
pool_mode=ctx.pool_mode,
aligned=ctx.aligned)
ctx.save_for_backward(rois, argmax_y, argmax_x)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
return grad_input, None, None, None, None, None, None
roi_align = RoIAlignFunction.apply
After the first four sections , perform setup.py Will generate compiled .so The executable of , and mmcv Unified use ext_module To call these files . stay pytorch in ROIAlign By inheritance Function Class and implement forward and backward After the method , The method called internally is pybind Bound in roi_align_forward and roi_align_backward. So as to achieve pytorch call cuda Of
summary
The above analysis shows that mmcv In the call cuda The whole process , Of course , Our aim must be to be able to extend the operator by ourselves . Here are GitHub On mmcv Expand the process mmcv Of readme. I can't open the link. I've taken this picture :
I didn't understand many code details , If you want to communicate , welcome +q2541612007.
边栏推荐
- 【NVMe2.0b 14-7】Set Features(上篇)
- Tidb v6.0.0 (DMR): initial test of cache table - tidb Book rush
- 我们如何拿到自己满意的薪资呢?这些套路还是需要掌握的
- [flower carving experience] 12 build the Arduino development environment of esp32c3
- Redis design and Implementation (VII) | publish & subscribe
- Dlib database face
- 涂鸦Wi-Fi&BLE SoC开发幻彩灯带
- A troubleshooting of CPU bottom falling
- vite項目require語法兼容問題解决require is not defined
- Oracle expansion table space installed in docker
猜你喜欢

微信公众号第三方平台开发,零基础入门。想学我教你啊

Redis设计与实现(四)| 主从复制

Redis设计与实现(一)| 数据结构 & 对象
![[flower carving experience] 14 line blank board pingpong library test external sensor module (one)](/img/ba/1d1c5b51cdfc4075920a98d64820c2.jpg)
[flower carving experience] 14 line blank board pingpong library test external sensor module (one)

Gilbert Strang's course notes on linear algebra - Lesson 4
![[JUC series] overview of fork/join framework](/img/49/2cadac7818b0c1100539fd32ec0d37.png)
[JUC series] overview of fork/join framework

Gilbert Strang's course notes on linear algebra - Lesson 2

Wsl2 using GPU for deep learning

示波器探头对测量电容负荷有影响吗?

Redis design and Implementation (VIII) | transaction
随机推荐
mysql基础入门 动力节点[老杜]课堂作业
Sword finger offer II 075 Array relative sort (custom sort, count sort)
Map,String,Json之間轉換
Unity simple shader
Is the reverse repurchase of treasury bonds absolutely safe? How to open an account online
[untitled]
Unit Test
swagger使用
电流探头电路分析
[flower carving experience] 12 build the Arduino development environment of esp32c3
Experiment 2 LED button PWM 2021/11/22
codeforces每日5题(均1700)-第三天
Flink Sql -- toAppendStream doesn‘t support consuming update and delete changes which
Cesium learning notes (III) creating instances
C # listbox how to get the selected content (search many invalid articles)
What are the Amazon evaluation terms?
Viteproject require Syntax Compatibility Problem Solving require is not defined
[untitled]
Gilbert Strang's course notes on linear algebra - Lesson 4
Dlib library blink