当前位置:网站首页>Summer Challenge database Xueba notes, quick review of exams / interviews~
Summer Challenge database Xueba notes, quick review of exams / interviews~
2022-07-05 19:15:00 【51CTO】
This article is participating in the starlight project 3.0– Summer Challenge
Introduction to Database System
Four basic concepts
data : The basic object stored in a database , A symbolic record of something , Data and its semantics cannot be separated
database (DB): It's stored in a computer for a long time 、 organized 、 A collection of large amounts of data that can be shared .
Database management system : A software for managing data
The main function :
Data definition function :
(1) Provide data definition language (DDL): Create table (CREATE), Modify table (ALTER), Delete table (DROP);
(2) Define data objects in the database
Control function :
Provide data manipulation language (DML, That is, the operation of adding, deleting, modifying and checking ), Realize the basic operation of the database ( Inquire about 、 Insert 、 Delete and modify )
Transaction management and operation management :
Database by DBMS Unified management and control to ensure data security , integrity 、 Concurrent use of data by multiple users 、 System recovery after failure
Build and maintain functions :(1) Database initial data loading conversion ;(2) Database dump ;(3) Media recovery ;(4) The reorganization of the database ;(5) Performance monitoring and analysis, etc
Database system : By database 、 DBMS applications and database administrators (DBA) And so on 、 management 、 A system that processes and maintains data .
Data model
Two types of data models
conceptual model : The first abstraction , For database design
Logical model and physical model : The second abstraction
1) Logic model mainly includes mesh model 、 hierarchical model 、 relational model 、 Object oriented model, etc , Modeling data from the point of view of a computer system , be used for DBMS Realization
2) Physical models are the lowest level abstraction of data , Describe the representation and access method of data in the system , Storage and access on disk or tape
The components of the data model
data structure
1) Describe the constituent objects of the database , And the connections between objects
2) Describe objects related to the connection between data
3) It is a description of the static characteristics of the system
4) classification :(1) Non relational : Reticular , level ;(2) Relational type ;(3) Object oriented
Data manipulation
1) For various objects in the database ( type ) Example ( value ) The operation allowed to be carried out and the relevant operation rules
2) Additions and deletions
3) It is a description of the dynamic characteristics of the system
Data integrity constraints
1) A set of integrity rules
2) Integrity rules : The constraints and storage rules of data and its relations in a given data model
3) It is used to define the state of the database in accordance with the data model and the change of the state , To make sure the data is correct 、 It works 、 Compatible with
Entity integrity : Whether the attribute information of specific data is complete
Referential integrity : The value corresponding to this property exists
User defined integrity : Look at the mood
relational model
Basic concepts :
1) Relationship (Relation): A relation corresponds to a table as is often said
2) Tuples (Tuple): A row in the table is a tuple
3) attribute (Attribute): A column in the table is an attribute , Give each attribute a name, that is, the attribute name
4) code (Key) : An attribute or attribute group that uniquely identifies a tuple
5) Domain (Domain) : Is a set of values with the same data type
6) component : An attribute value in a tuple
7) Relationship model : A description of the relationship , It is generally expressed as
Relationship name ( attribute 1, attribute 2,……, attribute n)
Student ( Student number , full name , Age , Gender , system , grade )
8) Pay attention to norms : There should be no big watch set and small watch set .
Data manipulation : Additions and deletions , A set of operations on several tuples
Data integrity constraints :
1) Entity integrity
2) Referential integrity
3) User defined integrity
Database system structure
The concept of database system schema
type : A description of the structure and properties of a class of data ,( Student number , full name , Gender , Is don't , Age , Native place )
value : A concrete assignment of type ,(201315130, Li Ming , male , Computer ,19, jiangsu )
Pattern : Description of logical structure and characteristics of database , It's a description of type , It reflects the structure of the data and its connections , The pattern is relatively stable , A collection of property names
example : A specific value of the pattern , Reflect the state of the database at a certain time , There can be many instances of the same pattern , Instance changes as data in the database is updated
If it's a report card : So the subject line represents the pattern ( It's not just that , There's also other information ), Each person's score line represents an example
Three level pattern structure of database system
Pattern : Description of logical structure and characteristics of all data in database , Common data view for all users , Integrated the needs of all users , A database has only one schema , The pattern is relatively stable , But the entity is relatively variable
status :1) It is the middle layer of database system pattern structure ;2) Independent of the physical storage details and hardware environment of the data ;3) And specific applications 、 Development tools and advanced programming languages are irrelevant
Definition :1) Logical structure of data ( The name of the data item 、 type 、 Value range, etc );2) The connection between data ;3) Data related security 、 Integrity requirements
External mode : A subset of patterns , A database can have multiple , It is the description of logical structure and characteristics of local data in database
Internal mode :1) Is a description of the physical structure and storage of data ;2) Is the representation of data within the database
A database has only one internal schema .
The secondary image function of database and the independence of data
External mode / Pattern image : Ensure the logical independence of data . Is not the only
1) When the pattern changes , The database administrator modifies the external schema / Pattern mapping , Keep the outer mode unchanged
2) The application is written according to the external pattern of data , So the application doesn't have to be modified , Ensure the logical independence of data and program , The logical independence of data .
Pattern / Internal mode image : Ensure the physical independence of data . only
1) When the storage structure of the database changes ( For example, another storage structure is selected ), The database administrator modifies the schema / Inner pattern mapping , Leave the mode unchanged , The pattern of going in and out doesn't change
2) Application is not affected . Ensure the physical independence of data and program , Physical independence of data
Data access by DBMS The benefits of Management :
1) Users do not need to consider access path and other details
2) Simplified application programming
3) Greatly reduces application maintenance and modification
Composition of database system
Hardware , operating system , Database designers , Database manager , Database management system , Users and so on .
Relationship
Domain : A set of values with the same data type ( That's the range )
The cartesian product : A set operation on a field . The result is a set , Each element of a set is a tuple , Each component of a tuple comes from a different field .
base : The number of different values allowed in a field .
The cardinal number of the Cartesian product : The product of the number of different values in each field , Or the number of tuples
Relationship : A subset of the Cartesian product of a field is called a relation on the field , The number of fields is called the order or degree of a relation .( Number of columns , Number of attributes ), Note that Cartesian products in the general sense cannot be called relations , Because there is invalid data .
Relationship : surface
Column : attribute
That's ok : Tuples
Candidate code : The value of an attribute group can uniquely identify a tuple , And its subset can't be , The attribute group is called candidate code
Main attribute : All the attributes in the candidate code are called primary attributes , Be careful : The primary attribute is not empty .
Main attribute : Attributes other than the candidate code are called non primary attributes
Full size : All the attributes of a relational schema are the candidates for the relational schema
Main code : Select a group of attribute groups that can uniquely determine a tuple from the candidate codes as the main code .
Three kinds of relationships :
1) Basic relationship : The actual table , Is the logical representation of the actual stored data
2) Query table : The table corresponding to the query result
3) View table : A table derived from a base table or other view table , It's a virtual watch , Not the data that should actually be stored .
Be careful : Relationships in a relational data model must be finite sets .
Each column of a relationship must have an attribute name attached to it , Property names cannot be duplicate , This method cancels the order of relational attributes .
① Columns are homogeneous (Homogeneous): The components in each column come from the same domain , It's the same type of data
② Different columns can come from the same field
Each of these columns is called an attribute
Different attributes should be given different attribute names
③ The order of the columns doesn't matter , The order of the columns can be exchanged arbitrarily
④ The candidate codes of any two tuples cannot be the same : The same is not a candidate
⑤ The order of the lines doesn't matter , The order of the lines can be exchanged at will
⑥ The component must be atomic ( Nested tables are not allowed )
Relationship model
Relationship model : A description of the relationship , Is static 、 The stability of the
Relationship : The state or content of a relationship pattern at a certain time , Is dynamic 、 Changing over time , It refers to the relationship behind
Formal representation of relational schema :
// Relationship model
R(U, D, DOM, F)
R Relationship name
U The set of attribute names that make up the relationship
D Attribute group U The domain from which the attribute in the
DOM The set of mappings of attributes to fields
F A collection of data dependencies between attributes
// It can be abbreviated as
R (U) or R (A1,A2,…,An)
R: Relationship name
A1,A2,…,An : Property name
notes : The mapping of domain name and attribute to domain is often directly described as the type of attribute 、 length
relational database
In a given application area , The collection of all relationships forms a relational database
Types and values of relational databases , It's not the type and value of a relationship
1) The type of relational database is also called relational database schema , It's a description of a relational database
2) The value of a relational database is the set of relationships corresponding to the relational schema at a certain time , It's called relational database for short
Basic relationship operations
Common basic operations :
** Inquire about :** choice 、 Projection 、 Connect 、 except 、 and 、 hand over 、 Bad
** Data update :** Insert 、 Delete 、 modify
**5 Basic operations :** choice 、 Projection 、 and 、 Bad 、 The cartesian product Be careful : Not to mention
Characteristics of relationship operation :
Set operation mode : The objects and results of the operation are collections , One set at a time , The operands are collections , The operation result is also a set .
The integrity of the relationship
Entity integrity ( That is, the main attribute is not empty )
If attribute A It's the basic relationship R The main attribute of , Property A Can't take null value
Referential integrity
References between relationships : There is a connection between relationships
Outer code : set up F It's the basic relationship R One or a set of attributes of , But it's not the relationship R The main code of ,Ks It's the basic relationship S The main code of . If F And Ks Corresponding , said F It's the basic relationship R The outer code of , The basic relationship of external code is called reference relationship ,Ks The relationship is called the referenced relationship .
notes :
1)R、S It doesn't have to be a different relationship .
2) Target relationship S The main code of Ks And the outer code of the reference relation F Must be defined in the same ( Or a group ) On domain
3) The outer code does not have to have the same name as the corresponding main code , When the outer code and the corresponding main code belong to different relations , It's always the same name , To make it easy to identify
4) The value of outer code : If the external code is the primary attribute of the reference relationship , Can't be empty ( Entity integrity ), It can only be the value of the main code in the referenced relation . If the external code is not the primary attribute of the reference relationship , It can be blank or the value of the primary code of the referenced relationship
Two invariants : Entity integrity and referential integrity
User defined integrity
Constraints for a specific relational database , It reflects the semantic requirements that the data involved in a specific application must meet
A relational model should provide a mechanism for defining and verifying such integrity , In order to deal with them in a unified and systematic way , Instead of the application taking on this function
Relational algebra
Traditional set operations
Traditional relational operations :
and 、 hand over 、 Bad 、 The cartesian product
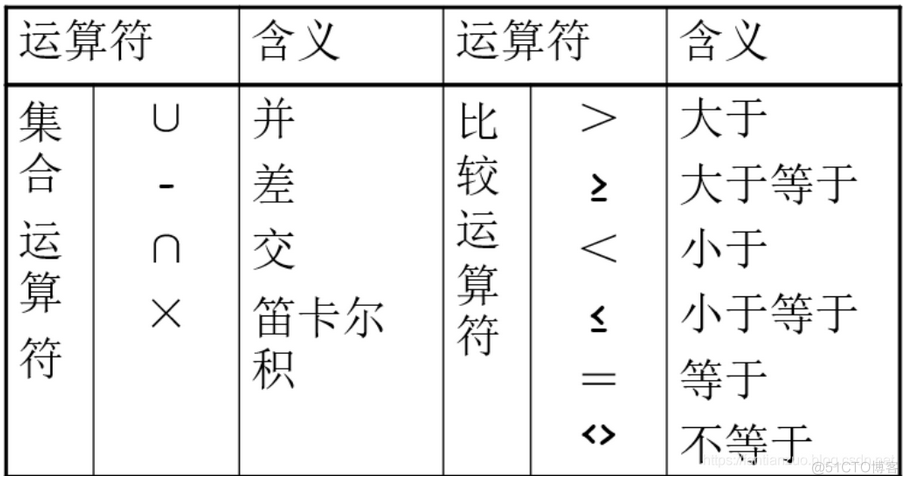
Manipulating object relationships :
Mode of operation : It's the same as the Union in mathematics 、 hand over 、 Bad 、 The cartesian product . It's just that the elements of the operation object are tuples . In addition, we need to pay attention to the conditions that we need to meet when we can carry out the operation .
For union 、 hand over 、 The relationship between difference and need to be satisfied :1) The number of attributes is the same ;2) The corresponding attributes are taken from the same domain
Special relational operations
The common relational operations are selection 、 Projection 、 Connect 、 except
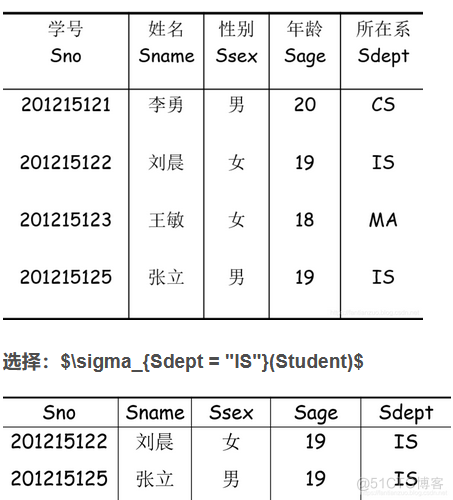
choice :
In relation R Select the tuples that satisfy the given conditions in .
expression :$\sigma_F(R) = {t | t \in R \and F(t) = ''true''}$
F: To choose conditions , It's a logical expression , The basic form is :$X_1 \theta Y_1$, among $\theta$ For more than 、 Less than 、 be equal to 、 It's not equal to waiting .
give an example :
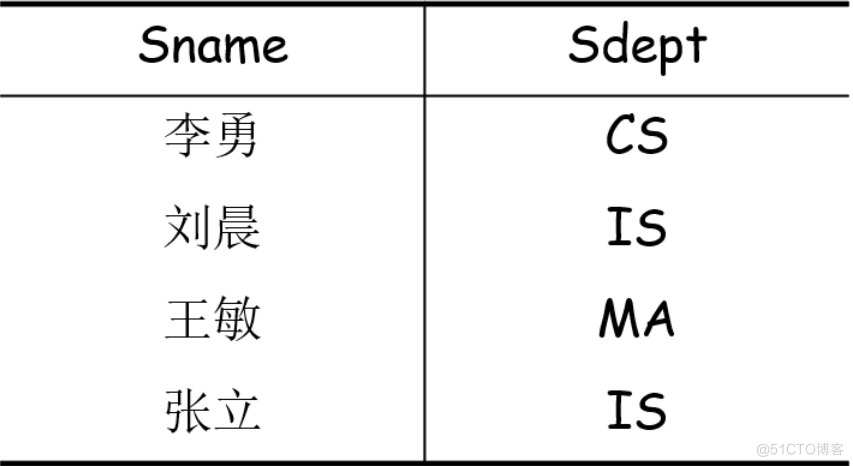
Projection :
from R Select several attribute columns to form a new relationship
expression :$\prod_{A} (R)= {t[A] | t\in R}$
A For attribute column , From R Choose from A The tuple of the attribute column in , Of course, some tuples may be deleted after selection , Because avoid repetition .
give an example : Or the relationship above , After projection $\prod_{Sname, Sdept}(Student)$, give the result as follows :
Connect
1)** General connection :** From the Cartesian product of two relations, we select tuples that satisfy certain conditions between attributes
(1) expression :$R\bowtie_ {A \theta B} S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] \theta t_s[B] }$
(2)A and B: Respectively R and S A set of attributes with equal and comparable degrees
(3)$\theta$ Represents the comparison operator ,
(4) The join operation starts from R and S The generalized Cartesian product of R×S Select the (R Relationship ) stay A The value on the property group is the same as (S Relationship ) stay B The values on the attribute group satisfy the comparison relation θ tuples
2)** Equivalent connection :** When the above operator is equal sign
(1) meaning : From the relationship R And S In the generalized Cartesian product of A、B Those tuples with equal property values , The equivalent connection is :
(2) expression :$R\bowtie_ {A = B} S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] = t_s[B] }$
(3) It's still from the perspective of lines , It's not about columns
(4) Attribute groups can be different
3)** Natural join :** A special equivalent connection
(1) Different from the equivalent connection : Two relationships R and S Must have the same property group
(2) Remove the same attribute column from the result
(3) expression :$R\bowtie S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] = t_s[B] }$
4) A series of problems caused by natural connection :
(1) Floating tuples : Tuples that are discarded when making natural connections
(2) External connection : If the discarded tuples are also stored in the result relation , And fill in blank values for other attributes (Null), This connection is called external connection , External connection = The left outer join + Right connection
(3) The left outer join : If only the left side of the relationship R The tuple reservation to be discarded in is called left outer join
(4) Right connection : If only the right side of the relationship S The tuple reservation to be discarded in is called right outer join
except
1) The meaning of division :
(1) Hypothetical relationship R,S,RS,R The attribute of a relationship is name ,S The attribute of relationship is curriculum ,RS The attribute of relationship is the connection between name and course , be RS/S It means that at least all the tables have been selected S The tuples of students in the courses listed in .
(2) Here's the picture :
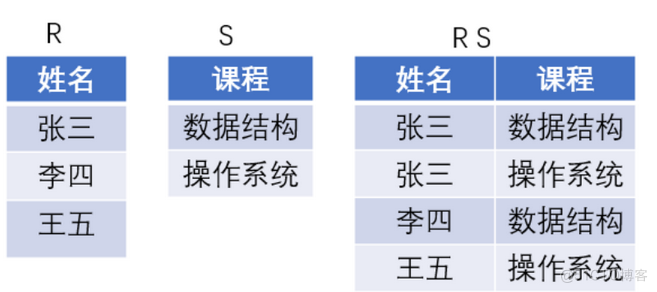
notes :RS/S Get the relationship : The table composed of Zhang San and Li Si , A collection of students who have taken all the courses .
give an example :
R:
A B C
a1 b1 c2
a2 b3 c7
a3 b4 c6
a1 b2 c3
a4 b6 c6
a2 b2 c3
a1 b2 c1
S:
B C D
b1 c2 d1
b2 c1 d1
b2 c3 d2
R÷S
A
a1
(1) look for S And R The common properties of , In the formula Y attribute
(2) Calculation R Each of them X The image set of attributes , If an image set contains S stay Y Projections on properties , Then the genus is R/S One of the results .
The answer is as follows :
In relation R in ,A You can take four values {a1,a2,a3,a4}, among :
a1 The set of images is :{(b1,c2),(b2,c3),(b2,c1)}
a2 The set of images is :{(b3,c7),(b2,c3)}
a3 The set of images is :{(b4,c6)}
a4 The set of images is :{(b6,c6)}
S stay (B,C) The projection on is {(b1,c2),(b2,c3),(b2,c1)}.
Obviously only R A collection of images a1 contain S stay (B,C) Projections on attribute groups , therefore R÷S={a1}.
Summary of data types
Integer types :
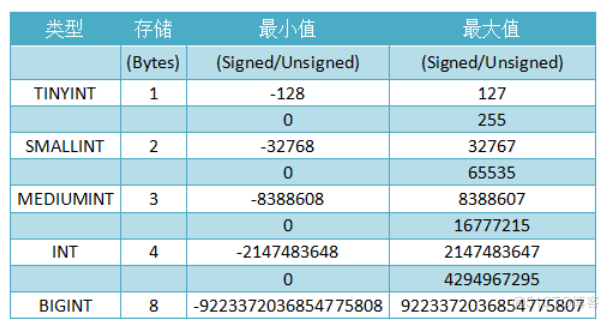
Real number type :
Fixed-point number :DECIMAL and NUMERIC Type in the MySQL The same type as seen in . They are used to hold values that must be of exact precision .
DECIMAL(M,D), among M Represents the total number of decimal digits ,D The number of digits after the decimal point .
If in storage , The integer part is out of range ( As in the example above , Add a value of 1000.01),MySql You're going to report a mistake , It is not allowed to store such value .
If in storage , If the decimal part is out of range , In the following cases :
If after rounding , The integer part is not out of range , Just a warning , But it can operate successfully and delete the extra decimal places and save it . Such as 999.994 Actually saved as 999.99.
If after rounding , The integer part is out of range , be MySql Report errors , And refuse to deal with . Such as 999.995 and -999.995 All will report wrong. .
M The default value of is 10,D The default value is 0. If you create a table , A field is defined as decimal Type without any parameters , Equate to decimal(10,0). With a parameter ,D Take the default value .
M The value range of is 1~65, take 0 Will be set to the default value , Out of range error will be reported .
D The value range of is 0~30, And must <=M, Out of range error will be reported .
therefore , Obviously , When M=65,D=0 when , Maximum and minimum values can be obtained .
Floating point type
:float,double and real. They define it as :FLOAT(M,D) 、 REAL(M,D) 、 DOUBLE PRECISION(M,D). “(M,D)” Indicates that the value shows M An integer , among D Place after decimal point
FLOAT and DOUBLE Medium M and D The default values of are 0, That is, except for the maximum and minimum value , No limit on the number of digits .
M The value range is 0~255.FLOAT Ensure that only 6 The accuracy of the significant digits , therefore FLOAT(M,D) in ,M<=6 when , The numbers are usually accurate . If M and D It's all clearly defined , The treatment after exceeding the scope is the same as decimal.
D The value range is 0~30, At the same time, we must <=M.double Ensure that only 16 The accuracy of the significant digits , therefore DOUBLE(M,D) in ,M<=16 when , The numbers are usually accurate . If M and D It's all clearly defined , The treatment after exceeding the scope is the same as decimal.
In the memory ,FLOAT Occupy 4-byte(1 Bit sign bit 8 Bitwise index 23 Bits represent mantissa ),DOUBLE Occupy 8-byte(1 Bit sign bit 11 Bitwise index 52 Bits represent mantissa )
Floating point numbers have less storage space than fixed-point numbers , Fast calculation , But it's not accurate enough .
Because of the need to compute extra space and computing overhead , So we should try our best to calculate the decimals exactly Only use DECIMAL. But when the amount of data is large , Consider using BIGINT Instead of DECIMAL, Multiply the monetary unit to be stored by the number of decimal places by the corresponding multiple .
BIT data type
Can be used to save bit field values .BIT(M) Type allows storage M A value .M The scope is 1~64, The default is 1.
BIT It's actually a binary value , similar 010110.
If you deposit a BIT Type value , The number of digits is less than M value , Then left complement 0.
If you deposit a BIT Type value , There are more digits than M value ,MySQL The operation depends on the effective SQL Pattern :
If the mode is not set ,MySQL Crop the value to the corresponding end of the range , And save the cut value .
If the mode is set to traditional(“ Strict mode ”), Out of range values will be rejected with an error , And according to SQL Standard insertion will fail .
MySQL hold BIT As string type , Not the number type .
String type
String type means CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM and SET.
CHAR & VARCHAR
CHAR and VARCHAR The length of the type declaration represents the maximum number of characters you want to save . for example ,CHAR(30) It can occupy 30 Characters . The default length is 255.
CHAR The length of the column is fixed to the length declared when the table is created . The length can be from 0 To 255 Any value . When saving CHAR When the value of , Fill in the spaces to the right of them to achieve the specified length . When the retrieved CHAR When the value of , The trailing space is removed , therefore , We can't have spaces to the right of the string when we store it , Even if there is , It will also be deleted after the query . No case conversion during storage or retrieval .
So when char When a field of type is a unique value , Whether the added value already exists to exclude trailing spaces ( There may be more than one space ) The value of , When comparing, it will be compared with the existing value after filling the blank space at the end .
VARCHAR The value in the column is a variable length string . Length can be specified as 0 To 65,535 Between the value of the ( The actual maximum length that can be specified is related to encoding and other fields , such as ,MySql Use utf-8 Coding format , The size is standard format size 2 times , There is only one varchar The measured maximum value in the field is only 21844, If you add a char(3), Then the maximum value is reduced 3. The overall maximum length is 65,532 byte ).
Same as CHAR contrast ,VARCHAR When the value is saved, only the number of characters needed is saved , Add another byte to record the length ( If the length of the column declaration exceeds 255, Then use two bytes ).
VARCHAR Values are saved without padding . When the value is saved and retrieved, the trailing space remains , Meet the standard SQL.
If assigned to CHAR or VARCHAR The value of the column exceeds the maximum length of the column , Then crop the value to fit . If the cut character is not a space , A warning will be generated . If you crop non whitespace characters , It will lead to mistakes ( Not a warning ) And by using strictly SQL Mode disable value insertion .
BINARY & VARBINARY
BINARY and VARBINARY The type is similar to CHAR and VARCHAR type , But here's the difference , They don't store strings , It's a binary string . So they don't have a coding format , And sort and compare numeric values based on column value bytes .
When saving BINARY When the value of , Fill them to the right 0x00( Zero byte ) Value to reach the specified length . The last byte is not deleted when the value is taken . All bytes are important when comparing ( Because of the spaces and 0x00 Is different ,0x00< Space ), Include ORDER BY and DISTINCT operation . For example, insert 'a ' Will become 'a \0'.
about VARBINARY, Insert without filling characters , Do not crop bytes when selecting . All bytes are important when comparing .
BLOB & TEXT
BLOB Is a binary large object , Can hold a variable amount of data . Yes 4 Kind of BLOB type :TINYBLOB、BLOB、MEDIUMBLOB and LONGBLOB. They just have different maximum length of accommodation values .
Yes 4 Kind of TEXT type :TINYTEXT、TEXT、MEDIUMTEXT and LONGTEXT. These correspondences 4 Kind of BLOB type , Same maximum length and storage requirements .
BLOB Columns are treated as binary strings .TEXT Columns are treated as character strings , similar BINARY and CHAR.
stay TEXT or BLOB Column storage or retrieval process , There is no case conversion .
When not running in strict mode , If you are BLOB or TEXT Column assigns a value that exceeds the maximum length of the column type , The value is truncated to ensure that it is suitable for . If the truncated character is not a space , There will be a warning . Use strictly SQL Pattern , There will be mistakes , And the value will be rejected instead of intercepted and given a warning .
In most ways , Can be BLOB A column is considered to be large enough VARBINARY Column . Again , Can be TEXT Column as VARCHAR Column .
BLOB and TEXT It is different from VARBINARY and VARCHAR:
When saving or retrieving BLOB and TEXT The value of the column does not delete trailing spaces .( This is related to VARBINARY and VARCHAR The columns are the same ).
When comparing, you will use spaces to TEXT Expand to fit the object of comparison , just as CHAR and VARCHAR.
about BLOB and TEXT Column index , You must specify the length of the index prefix . about CHAR and VARCHAR, Prefix length is optional .
BLOB and TEXT Column cannot have default value .
BLOB or TEXT The maximum size of an object is determined by its type , But the maximum value that can actually be passed between the client and the server is determined by the amount of memory available and the size of the communication cache . You can change max_allowed_packet The value of the variable changes the size of the message cache , But you have to modify both the server and the client .
Every BLOB or TEXT Values are represented by internally assigned objects .
they (TEXT and BLOB Same as ) The length of :
Tiny: Maximum length 255 Characters (2^8-1)
BLOB or TEXT: Maximum length 65535 Characters (2^16-1)
Medium: Maximum length 16777215 Characters (2^24-1)
LongText Maximum length 4294967295 Characters (2^32-1)
The actual length is related to the coding , such as utf-8 It's going to be halved .
When BLOB and TEXT When the value is too high ,InnoDB Special external storage area will be used for storage , In this case, a single value needs to be 1~4 Bytes store a pointer , Then store the actual value in the external storage area .
MySQL Meeting BLOB and TEXT Sorting is different from other types : It's only for the first of each class max_sort_length Byte instead of the whole string .
MySQL Can't be BLOB and TEXT Column full length string to index , You can't use these indexes to eliminate sorting .
ENUM Use enumeration instead of string type
MySQL Very compact when storing enumerations , Will be compressed into one or two bytes based on the number of list values .MySQL Internally save the position of each value in the list as an integer , And on the watch .frm Save in file “ Array —— character string ” Lookup table for mapping .
Enumeration fields are sorted by internally stored integers rather than defined strings ;
because MySQL Save each enumeration value as an integer , And it has to be looked up to convert to a string , So enumerating columns has some overhead . In certain circumstances , hold CHAR/VARCHAR Column and enumeration column JOIN May be more relevant than direct connection CHAR/VARCHAR More slowly .
Time and date type
DATE, DATETIME, and TIMESTAMP type These three are actually related , Are used to indicate a date or time .
Use... When you need values that contain both date and time information DATETIME type .MySQL With 'YYYY-MM-DD HH:MM:SS' Format search and display DATETIME value . The scope of support is '1000-01-01 00:00:00' To '9999-12-31 23:59:59'.
Use... When you only need the date value and not the time part DATE type .MySQL use 'YYYY-MM-DD' Format search and display DATE value . The scope of support is '1000-01-01' To '9999-12-31'.
TIMESTAMP Type also includes date and time , Range from '1970-01-01 00:00:01' UTC To '2038-01-19 03:14:07' UTC.
TIME The range of values can be from '-838:59:59' To '838:59:59'. The reason why the hour part is so big is TIME Type can be used not only to represent the time of day ( Must be less than 24 Hours ), It may also be the time in the past of an event or the time interval between two events ( Can be greater than 24 Hours , Or even negative )
They are not stored in the same way
about TIMESTAMP, It converts the time inserted by the client from the current time zone to UTC( World standard time ) For storage . When inquiring , Convert it to the current time zone of the client to return .
And for DATETIME, Don't make any changes , It's basically the original input and output .
YEAR Type is a single byte type used to represent year .
MySQL With YYYY Format search and display YEAR value . The scope is 1901 To 2155.
Relational database standard language SQL
Basic concepts
SQL Language is a powerful relational database language . It is also a structured query language between relational algebra and relational calculus (Structured Query Language), Its functions include data definition 、 Data query 、 Data manipulation and data control .
SQL Characteristics :
1) Integrate and unify : Set data definition 、 Data query 、 Data manipulation and data control are integrated .
2) Highly unprocessed : Facing the design of the elephant
3) Set oriented operations : The operands are collections , And the result of the operation is also a set
4) Two ways of use , Unified grammatical structure : As an independent language , Another embedded language ,( Embedded refers to embedding other high-level languages ).
5) Simple and easy to learn
Database creation and basic concepts
One 、 Create database :
Code :
create database Student; -- Create database
use Student; -- Using a database
drop database Student; -- Delete database
Be careful :
1) Two ways to annotate :(1) Two minus signs --, Note a single line (2)/* */ Comment lines
2) The current database cannot be deleted from the current database
data type :
201902279
Be careful :
1) What kind of data type an attribute uses is determined by two parts :(1) The value range of this property ;(2) What kind of operation does this property perform .
Pattern creation and deletion
Pattern , A non repeating namespace independent of database users , In this space, you can define the database objects that the schema contains , For example, the basic table 、 View 、 Index, etc. .
Code :
/** Create mode zhang, Next key table student*/
create schema zhang
create table student
(
Sno char(9) primary key,
Sname varchar(20) unique,
Ssex char(4) not null,
Sage smallint,
Sdept varchar(5)
);
/** Delete tables in schema */
drop table zhang.student;
/** Delete the pattern */
drop schema zhang; -- Note that there are no objects in this mode
Be careful :
1) When deleting a pattern, you should first delete all objects in the pattern , To delete the mode
2) In deleting a non dbo Table in mode , You need to add a pattern name
3) This pattern is not a pattern in a three-level pattern, two-level image , It is equivalent to a namespace ( It can mainly solve the problem of duplicate names )
4)CASCADE( cascade ): Delete the schema and delete all database objects in the schema (SQL Server I won't support it )
5)RESTRICT( Limit ): Only when there are no subordinate objects in the pattern can it be executed
The definition of the table 、 Delete and modify
One 、 Create table ( Three sheets ):(1) Student list (Student)(2) The curriculum (Course)(3) Student schedule (SC)
1) Student list (Student)
Code :
/** No data added */
create table student
(
Sno char(9) primary key, --primary key Indicates the main code
Sname varchar(20) unique, --unique Indicates that the value is unique ,
Ssex char(4) not null, --not null The value is not empty
Sage smallint,
Sdept varchar(5)
);
2) The curriculum (Course)
201903132
Code :
/** Create a curriculum */
create table Course
(
Cno char(2) primary key,
Cname varchar(10) unique,
Cpno char(2), --Cpno It's the outside code , The reference is self Cno
Ccredit smallint,
foreign key (Cpno) references Course(Cno) -- Outer code
);
3) Student - The curriculum
Code :
/** Creating students - The curriculum */
create table SC
(
Sno char(9),
Cno char(2),
Grade int,
primary key(Sno, Cno), -- Multiple attribute columns constitute the main code , At the end
foreign key(Sno) references student(Sno), -- Outer code , Write one line per outer code
foreign key(Cno) references Course(Cno)
);
Be careful :
1) There are three integrity constraints to consider when creating a table : Entity integrity , Referential integrity , User-defined integrity
2) Two ways to define integrity constraints :
Column level integrity constraints : Integrity constraints involving the corresponding attribute column , After the attribute column, define .
Table level integrity constraints : Integrity constraints involving one or more attribute columns , After you have listed the attributes, define .
3) The external code should be the same as the main code type . For table level integrity constraints, attribute columns need to be bracketed .
Two 、 Modify table
Add column
alter table student add graduation date;
/*
1. Specify the table to modify
2. add keyword
3. New column property name
4. New column data type
*/
Delete column
alter table student drop column graduation;
Change the data type of the column
alter table student alter column graduation varchar(20);
Add constraints
/* It's not easy to add constraints from the box on the left ( key ) I can see */
alter table student add unique(graduation);
/* A custom alias for the added constraint , Easy to distinguish */
alter table student add constraint S_un unique(graduation);
/* Be careful */
--1. You can't use add not null constraint , If you want to add, you can only remove the tick in the design
-- Although the following way seems to add not null constraint , But it doesn't work
alter table student add constraint cc check(sname is not null);
--2. Add a primary key to an attribute column , You need to ensure that the attribute column is not allowed to be empty , The new table just built without constraints , The default property column allows null values
alter table student add primary key(sno,cno);
--3. Add foreign keys , You need to ensure that the data type of the external code and the primary attribute of the referenced table are consistent
alter table student add foreign key (sno) references student(sno);
Delete constraints
/* Delete the specified constraint by the specified constraint name */
alter table student drop constraint S_un;
/* Right click to delete on the left */
3、 ... and 、 Delete table
/* When deleting a table, you must first kill the reference table , Then delete the referenced table */
drop table student;
Index creation and deletion
The purpose of indexing is to speed up data query .DBA Or the owner of the table can index the table as needed ; But some DBMS The following indexes can be built automatically ,1)PRIMARY KEY Indexes ( Cluster index )2)UNIQUE Indexes ( Uniqueness index )
One 、 Create index
/* Create a unique index */
/*
* stu For index name , You must have an index name to create an index
* The column name is followed by the sort type ,ASC In ascending order ,DESC For the descending order , The default is ASC, There can be multiple columns , Separated by commas .
* For attribute columns that already contain duplicate values, the unique index cannot be added
*/
create unique index S_nn on student(graduation asc);
/* Create a clustered index ( Gather )*/
Create clustered index stu on student(sage desc);
/*
* The keyword of cluster index is clustered, It's not in the book , It is sqlserver It's like this
* Again , The column name is followed by the sort type , There can be multiple columns , Separated by commas .
* Cluster indexes are sorted strictly by physical storage location .
* You cannot create an index in a table with a primary key
* A table can only create one clustered index
*/
Two 、 Delete index
/* Be careful : Drop index must be a table name + Index name */
drop index student.stu
sql Inquire about
Single table query
Simple query operations :
-- Projection ,select The following indicates the selected column ,from Indicates the table accessed
select sno, sname, sdept
from student;
-- Select the specified column , You can add arithmetic expressions , And add a new property name to it
select sno, 2019-sage as birthday
from student;
-- After projection , Modify property name
select sno num, 2019-sage birthday
from student;
--* Represents the selection of all columns
select *
from student;
-- except int,smallint, The rest of the data types need single quotes ''
select sname,'2017' year
from student;
-- String splicing
--5) The names of all the students 、 contact number , And add the string before it ‘ Contact information ’
select sname, ' Contact information '+tel
from student;
--select The additive function
--count The null value of the function is ignored , Repeat value repeat count
-- When count Function counts as tuples when it acts on all columns
select COUNT(sno)
from student;
--COUNT It means counting ,* Represents all columns ,COUNT(*) Represents the number of tuples , Null values for one or some of the attribute columns do not affect count The statistical results
select COUNT(*)
from student;
-- duplicate removal ,distinct The scope is the entire tuple , Is the de duplication of tuples of all specified columns
select distinct sno, cno
from sc;
-- Check the student number of female students , full name
select sno, sname
from student
where ssex = ' Woman ';
-- The inquiry credits are 4 The name of the credit course
select cname
from course
where ccredit = 4;
-- The results are in 85 The student number of a student with a score above ( The student number is not heavy )
select distinct sno
from sc
where grade > 85;
-- The age of inquiry is 20~23 year ( Include 20 Age and 23 year ) Between the names of the students 、 Department and age .
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
-- Can not write sdept='CS','IS','MA'
select sname,ssex
from student
where sdept='CS' or sdept='IS' or sdept = 'MA';
--IS NULL, IS NOT NULL Null value : Only use “is”, Out-of-service “=”
--WHERE NOT Sage >= 20;not Must be in sage in front , instead of >= in front
select sname,ssex
from student
where sdept in ('CS','IS','MA');
-- Fuzzy query
--% Any length ,_ Single character ,__ Two or less than two
-- Escape character \, Need to add escape '\' mark
select *
from student
where sname like ' Liu __';
select * -- If the character itself has an underline , Use any character as an escape character
from Course
where Cname like 'DB\_%i_ _' escape '\';
order by Clause :
--order by Clause
-- choice sno Column , from sc In the table ,cno by '3', In descending order of grades
--desc Represents a descending order ,asc Indicates ascending order , When it defaults, it means asc
-- stay SqlServer When there is a null value in the sorted attribute column , The default null value is displayed first in the tuple ,desc( Descending ) The null tuple is displayed at the end
select sno
from sc
where cno = '3'
order by grade desc;
-- Multi attribute column sorting , First click ccredit In ascending order , When ccredit On equal terms , Press cpno Arrange in descending order
select *
from course
order by ccredit, cpno desc;
Be careful :
First of all, it will conform to where The tuple of the clause is filtered out , And then according to order by Clause to sort .
Aggregation function :
--count Statistics sc In the table sno Number of , Null values are ignored , Repeat value repeat count
--distinct keyword , Duplicate values in the formula de duplicate column
select count (distinct sno)
from sc;
-- Count the number of tuples
select count(*)
from sc;
-- Find the sum of the values of the column
select sum (grade)
from sc;
-- averaging , The result is rounded down
select AVG (grade)
from sc;
-- Find the minimum
select min (grade)
from sc;
-- Ask for the biggest
select max (grade)
from sc;
Be careful :
All aggregate functions ignore null values
where Aggregate function cannot be used as a conditional expression in clause , Aggregation functions can only be used in select Clause or group by Medium having Clause .
The tuple of aggregation function is to satisfy where The tuple of a condition in a clause
group by Clause :
--GROUP BY
-- There is GROUP BY The statement of ,select Only grouped attribute columns or aggregate functions can appear after the clause , Other names are not allowed ,
-- The average value is calculated over the null value
-- First click cno Grouping , Each group was statistically analyzed sno The number of and the average in each group , Finally, alias each new column
select cno, count(sno) cnt,AVG (grade) av
from sc
group by cno;
-- have access to HAVING The final output of phrase filtering is , Acting on the group , Select the group that meets the conditions
-- As above, first of all cno grouping , Through having Statement to select the group that meets the specified conditions
select cno, count(sno) cnt, AVG (grade) av
from sc
group by cno
having COUNT(sno)>=2;
-- Check the elective course 3 Student ID of more than one course
-- use first group by Grouping , And then use having Select the group that meets the criteria
select sno,COUNT(cno)
from sc
group by sno
having COUNT(cno)>=3
Be careful :
where Clause acts on the base table or view , Select the tuples that meet the conditions .
having Phrases act on groups , Select the tuples that meet the conditions
Use group by After clause ,select Only grouping attributes and aggregate functions can appear in the list of column names in clause
Link query
Basic concepts
Column names in join predicates are called join fields
The connection field types in a join condition must be comparable , But it doesn't have to be the same
SQL There is no automatic removal of duplicate Columns
Basic operation
--from Two tables are involved , No connection conditions , We get the generalized Cartesian product ,select Followed by the final displayed column
select student.*,sc.*
from student,sc;
-- Plus the connection conditions , What we get is to select tuples from the generalized Cartesian product that satisfy the specified conditions
--select Followed by the final displayed column , The common attribute columns of two tables need to be distinguished by the table name , Those that do not belong to the public column do not need to
--SqlServer There is no automatic removal of duplicate Columns
select student.*,cno,grade -- Remove duplicate Columns
from student,sc
where student.sno=sc.sno; -- Connection condition : Or the generalized Cartesian product
-- perhaps --
select sc.sno,sname,sage,ssex,sdept,cno,grade -- Remove duplicate Columns
from student,sc
where student.sno=sc.sno;
A possible execution process :
1) First of all, in the table 1 Find the first tuple in , And then scan the table from scratch 2, Find the tuples that satisfy the join condition one by one , When you find it, you'll find it 1 The first tuple in is concatenated with the tuple , Form a tuple in the result table .
2) surface 2 When you're done searching all of them , Look for the watch again 1 The second tuple in , And then scan the table from scratch 2, Find the tuples that satisfy the join condition one by one , When you find it, you'll find it 1 The second tuple in is concatenated with the tuple , Form a tuple in the result table .
3) Repeat the above operation , Until the watch 1 All tuples in are processed .
Self connect
select first.cno, second.cpno
from course first, course second
where first.cpno = second.cno;
Be careful :
Because the names of all attribute columns in the two tables are the same , So we need to distinguish them by alias .
The above code indicates that the first self table and the second self table are generalized Cartesian products , Then choose the first one of your own cpno It's the second one of your own cno The attribute column corresponding to the tuple of .
External connection
-- External connection
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student full outer join sc
on student.sno = sc.sno;
-- The left outer join
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student left outer join sc
on student.sno = sc.sno;
-- Right connection
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student right outer join sc
on student.sno = sc.sno;
Be careful :
The original conditions where Turn into on
The outer join operator after the table name indicates the principal table .
nested queries
Basic concepts
Query block : One select-from-where sentence
nested queries : Nesting a query block in the... Of another query block where Clause or having Query in the condition of phrase
Subquery cannot be used order by Clause , Because nested queries return a set or Boolean value , Sorting doesn't make any sense , So the rules can't be used order by sentence ( Rats )
Some nested queries can use join queries instead of , But some can't .
Uncorrelated subqueries : The query conditions of a subquery do not depend on the parent query
Correlation subquery : The query conditions of the child query depend on the parent query
Possible execution of unrelated subqueries : Layer by layer from the inside out . In other words, each subquery is solved before the next level query processing , The results of a subquery are used to establish the search criteria for its parent query .
The possible execution process of related subqueries :1) First take the first tuple of the table in the outer query , The inner query is processed according to its attribute values related to the inner query , if where Clause returns true , Then take this tuple and put it into the result table ;2) Then take the next tuple of the outer table ;3) Repeat the process , Until all the outer tables have been checked .
with IN Subquery of predicate
A typical example :
20190402
The query is an uncorrelated subquery , It is called ,1) stay course Find out the course number of information system in the table ;2) According to the course number , stay sc The student number of the student can be found in the table ;3) According to the student number , stay student Find out the names of the students in the table .
Subqueries with comparison operators
Applicable conditions : When you know exactly that the inner query returns a single value , You can use the comparison operator (>,<,=,>=,<=,!= or < >)
for example :
Find out the course number that each student has exceeded the average score of his elective course .
SELECT Sno, Cno
FROM SC x
WHERE Grade >=
(SELECT AVG(Grade)
FROM SC y
WHERE y.Sno = x.Sno);
The query process :
201904022
20190403
This example is a related subquery .
with any perhaps all Subquery of predicate
Statement :
any: Any one of them is OK ,> any It means greater than any one
all: Express all ,> all Indicates that it needs to be greater than all values
Common predicate interpretation :
with EXISTS Subquery of predicate :
Introduce :
There are quantifiers
exists
1) No data is returned , Only return true perhaps false. Returns when the inner query is not empty true, Returns when the inner query is empty false.
2) from EXISTS The resulting subquery , Its target list expression is usually expressed with *, Because the belt EXISTS Returns only true or false values , There is no practical significance in giving names ( Or bullshit )
not exists
1) If the inner query result is not empty , Then the outer layer WHERE Clause returns a false value
2) If the inner query result is empty , Then the outer layer WHERE Clause returns the true value
Example :
exists Example :
not exists Example :
201904027
difficulty 1: Use exists/not exists Realize the full quantifier
1) Check the names of the students who have taken all the courses
-- Change of words : That is, for a student , No course , Make yourself have no choice
select sname
from student
where not exists(
select *
from course
where not exists(
select s*
from sc
where student.sno = sno and cno = course.cno));
explain :
(1) For the first not exists The query inside is the current student Are there any courses not taken , If the current student has an elective course , after not exists return false, That is, the student's information will not be recorded .
(2) For the second not exists Inside the query is the current student object , For the current course , If you take this course ,not exists It's true inside , after not exists return false, The course will not be recorded , conversely , If the student does not take the course , The course will be recorded .
(3) It's a bit like double for loop , Traverse all student Tuples in , In every one of them student Under the circumstances , In a traverse course, Last in one not exists Medium where Clause .
difficulty 2: Use exists/not exists Realize logical implication
2) At least students are selected 201215122 The student number of all the elective courses .
SELECT DISTINCT Sno
FROM SC SCX
WHERE NOT EXISTS
(SELECT *
FROM SC SCY
WHERE SCY.Sno = '201215122' AND
NOT EXISTS
(SELECT *
FROM SC SCZ
WHERE SCZ.Sno=SCX.Sno AND SCZ.Cno=SCY.Cno));
explain :
(1) Basically the same as above
Set query
And operate :
Inquire about the students of computer science department and their age is not older than 19 Year old student .
/* Use UNION Union and collection */
SELECT *
FROM Student
WHERE Sdept= 'CS'
UNION
SELECT *
FROM Student
WHERE Sage<=19;
Cross operation :
Query computer science department students with age not older than 19 The intersection of a year old student (INTERSECT).
/* Use INTERSECT Realize the intersection operation */
SELECT *
FROM Student
WHERE Sdept='CS'
INTERSECT
SELECT *
FROM Student
WHERE Sage<=19;
Poor operation :
Query computer science department students with age not older than 19 The difference set of a year old student .
/* Use EXCEPT Realize the difference operation */
SELECT *
FROM Student
WHERE Sdept='CS'
EXCEPT
SELECT *
FROM Student
WHERE Sage <=19;
sql Additions and deletions
Data insertion
Insert Yuanzu
--1. There is no attribute column specified after the table name : Indicates that a complete tuple is to be inserted , And the attributes of the attribute column are consistent with the order in the table definition
insert into student
values ('201215128', ' Chen2 dong ', '18', ' male ', 'IS');
--2. After indicating, specify the table name and attribute column to insert data , The order of attribute columns can be inconsistent with the order in the table definition
insert into student(sno, sname, sage, ssex, sdept)
values ('201215138', ' Chen Dongdong ', '18', ' male ', 'CS');
--3. Insert partial column , Columns not shown are calculated as null values , Of course, the premise is that those columns can be null
insert into student(sno, sname)
values ('201215148', ' Chen Dong ');
2. Insert the result of a subquery
-- The result of the subquery must contain and insert As many fields as a list of fields , And data types are compatible
insert into depavg
select sdept,AVG(sage) avgage
from student
group by sdept;
3.5.2 Modification of data
--1. Modify some of them in line with where The value of the tuple of the condition in clause
update student
set sage = 92
where sno = '200215121';
--2. where Clause default , Modify the value of this attribute of all tuples by default
-- Be careful : When you modify data, you should first write where The condition in clause
update student
set sage = 92;
--3. Modification of subquery
update sc
set grade = 100
where 'CS' in (
select sdept
from student
where sc.sno = student.sno
);
--set Clause null You can only use the equal sign ,where Clause can only use is null
update student
set sage = null
where sno = '201811012';
Be careful :
DBMS When a modification statement is executed, it checks whether the modification operation breaks the integrity rules defined on the table .
Entity integrity : Ensure that the main code cannot be modified
User-defined integrity :not null constraint ,unique constraint , Range constraints, etc .
3.5.3 Deletion of data
--1. Delete compliance where Some lines of a condition in a clause
delete
from student
where sno = '201215148';
--2. Deletion of subquery
delete
from sc
where 'CS' in (
select sdept
from student
where sc.sno = student.sno
);
--3. Delete all rows
delete
from student;
Be careful :
Same as data update , It turns out to be dangerous , Operate with caution .
mysql Summary of common functions
Text processing function
Left(x,len) – Returns the character to the left of the string ( The length is len)
Right(x,len)
Length(x) – Returns the length of the string
Locate(x,sub_x) – Find a substring of a string
SubString(x, from, to) – Returns the character of the string
Lower(x)
Upper(x)
LTrim(x)
RTrim(x)
Soundex(x) – pronunciation ( For pronunciation matching )
SELECT cust_name, cust_contact FROM customers WHERE Soundex(cust_contact) = Soundex(‘Y Lie’);
Date and time processing functions
Date and time are stored in corresponding data type and special format , So that you can quickly and effectively sort or filter , Save physical storage space .
commonly , The application does not use the format used to store dates and times , So date and time functions are always used to read 、 Statistics and processing of these functions .
Commonly used date and time processing functions :
AddDate() – Add a date ( God , Zhou et al )
AddTime() – Add a time ( when , Grading )
CurDate() – Return current date
CurTime() – Return current time
Date() – Return date part of date time
DateDiff() – Calculate the difference between the two dates
Date_Add() – Date function
Date_Format() – Returns a formatted date or time string
Day() – Returns the days part of a date
DayOfWeek() – The day of the week corresponding to the return date
Hour() – Returns the hour part of a time
Minute() – Returns the minute part of a time
Second() – Returns the second part of a time
Month() – Returns the month part of a date
Now() – Returns the current date and time
Time() – Returns the time part of a date time
Year() – Returns the year part of a date
Date preferred format : yyyy-mm-dd; Such as 2005-09-01
Retrieve data from a date :
SELECT cust_id, order_num FROM orders WHERE Date(order_date) = ‘2005-09-01’;
Retrieve data from a month or date range :
SELECT cust_id, order_num FROM orders WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
– or
SELECT cust_id, order_num FROM orders WHERE date(order_date) BETWEEN ‘2005-09-01’ AND ‘2005-09-30’;
Numerical processing function
Algebra. 、 Trigonometric functions 、 Geometric operations, etc
Commonly used numerical processing functions :
abs(); cos(); exp(); mod()( Remainder ); Pi(); Rand(); Sin(); Sqrt(); Tan();
View / stored procedure / trigger
View
View is a virtual table , Unlike tables that contain data , Views only contain queries that retrieve data dynamically when in use , It is mainly used to query .
Why use views
reusing sql sentence
Simplify complex sql operation , After writing the query , It can be easily reused without knowing its basic query details .
Use parts of the table instead of the entire table .
Protection data . Users can be granted access to specific parts of the table instead of the entire table .
Change data format and presentation . Views can return data that is different from the representation and format of the underlying table .
Be careful :
After view creation , They can be used in much the same way as tables . Can execute on view select operation , Filtering and sorting data , Join a view to another view or table , Can even add and update data .
It's important to know that a view is just a facility for viewing data stored elsewhere . The view itself does not contain data , So the data they return is retrieved from other tables . When adding and changing data in these tables , The view will return the changed data .
Because the view does not contain data , So every time you use a view , Must handle any retrieval required for query execution . If you use multiple joins and filters to create complex views or nested views , It may be found that the performance is greatly reduced . therefore , Before deploying an application that uses a large number of views , It should be tested .
Rules and restrictions for views
Like a watch , Views must be uniquely named ;
You can create as many views as you want ;
To create a view , You must have sufficient access rights . These restrictions are usually granted by the database administrator .
Views can be nested , You can use queries that retrieve data from other views to construct a view .
Order by Can be used in views , But if you retrieve data from this view select It also contains order by, So the order by Will be overwritten .
View cannot be indexed , You cannot have an associated trigger or default
Views can be used with tables
View creation
utilize create view Statement to create a view
Use show create view viewname; To view the statement that created the view
use drop view viewname To delete the view
Update the view first drop stay create, You can also use create or replace view.
Update of view
Whether the view can be updated , It depends on the situation .
Usually the view can be updated , You can do insert,update and delete. Updating a view is updating its base table ( The view itself has no data ). If you add or delete rows to a view , In fact, it is to add or delete rows to the base table .
however , If MySQL Can't determine the updated base table data correctly , Update is not allowed ( Include insert and delete ), This means that the view cannot be updated if the following operations exist in the view :(1) grouping ( Use group by and having );(2) coupling ;(3) Subquery ;(4) and ;(5) Aggregation function ;(6)dictinct;(7) export ( Calculation ) Column .
stored procedure
A stored procedure is one or more stored procedures for later use MySQL Collection of statements . It can be regarded as a batch document , Although their role is not limited to batch processing .
Why use the storage process ?
1. By encapsulating the processing in an easy-to-use unit , Simplify complex operations ;
2. Since it is not required to repeatedly establish a series of processing steps , Data integrity guaranteed . If all developers and applications use the same ( Experiments and tests ) stored procedure , The code used is the same . The extension of this is to prevent mistakes . The more steps you need to take , The more likely it is to make a mistake , Error prevention ensures data consistency .
3. Simplify management of change , If table name . Column name or business logic changes , Just change the code of the stored procedure . People who use it don't even need to know about these changes . This extension is security , Limiting access to base data through stored procedures reduces the chance of data corruption .
4. Improve performance . Because using stored procedures is better than using separate sql Faster sentences .
5. There are some that can only be used for a single request MySQL Elements and properties , Stored procedures can use them to write more powerful and flexible code
Sum up :
Three main benefits : Simple 、 Security 、 High performance .
Two flaws :
1、 The writing of stored procedures is more complicated , Need more skills, more experience .
2、 You may not have security access to create stored procedures . Many database administrators restrict stored procedures Create permissions , Allow to use , Creation of .
Execute stored procedures
Call keyword :Call Accept the name of the stored procedure and any parameters that need to be passed to it . Stored procedures can display results , You can also not show the results .
CREATE PROCEDURE productpricing()
BEGIN
SELECT AVG( prod_price) as priceaverage FROM products;
END;
Create a productpricing The storage process of . If parameters need to be passed in the stored procedure , Then list them in brackets . Brackets must have .BEGIN and END The keyword is used to restrict the stored procedure body . The stored procedure body itself is a simple select sentence . Note that it's just to create the stored procedure without calling .
Use of storage process :
Call productpring();
Stored procedure using parameters
General stored procedures do not show results , Instead, return the result to the variable you specified .
Variable : A specific location in memory , Used to temporarily store data .
MySQL> CREATE PROCEDURE prod(
out pl decimal(8,2),
out ph decimal(8,2),
out pa decimal(8,2)
)
begin
select Min(prod_price) into pl from products;
select MAx(prod_price) into ph from products;
select avg(prod_price) into pa from products;
end;
call PROCEDURE(@pricelow,@pricehigh,@priceaverage);
select @pricelow;
select @pricehigh;
select @pricelow,@pricehigh,@priceaverage;
explain :
This stored procedure accepts 3 Parameters ,pl Lowest price for storage products ,ph The highest price of storage products ,pa Average price of storage products . Each parameter must specify the type , The decimal system is used , keyword OUT Indicates that the corresponding parameter is used to transfer a value from the stored procedure ( Back to the caller ).
MySQL Support in( Pass to stored procedure )、out( Out of stored procedure , Used here ) and inout( Pass in and out of stored procedures ) Parameters of type . The code for the stored procedure is located in begin and end Statement within . They are a series of select sentence , Used to retrieve values . Then save to the corresponding variable ( adopt INTO keyword ).
Parameters of stored procedures allow the same data types as those used in tables . Note that recordsets are not allowed types , therefore , Cannot return more than one row and column with one parameter , That's why it's used 3 Parameters and 3 strip select The reason for the statement .
call : To call this stored procedure , Must specify 3 Variable names . As shown above .3 Parameters are stored in the stored procedure 3 The names of variables . Invocation time , Statement does not display any data , It returns variables that can be displayed later ( Or in other processes ).
Be careful : be-all MySQL Variables are all based on @ start .
CREATE PROCEDURE ordertotal(
IN innumber int,
OUT outtotal decimal(8,2)
)
BEGIN
SELECT Sum(item_price * quantity) FROM orderitems WHERE order_num = innumber INTO outtotal;
end //
CALL ordertotal(20005,@total);
select @total; // obtain 20005 Total of orders
CALL ordertotal(20009,@total);
select @total; // obtain 20009 Total of orders
Stored procedures with control statements
CREATE PROCEDURE ordertotal(
IN onumber INT,
IN taxable BOOLEAN,
OUT ototal DECIMAL(8,2)
)COMMENT 'Obtain order total, optionally adding tax'
BEGIN
-- declear variable for total
DECLARE total DECIMAL(8,2);
-- declear tax percentage
DECLARE taxrate INT DEFAULT 6;
-- get the order total
SELECT Sum(item_price * quantity) FROM orderitems WHERE order_num = onumber INTO total;
-- IS this taxable?
IF taxable THEN
-- yes ,so add taxrate to the total
SELECT total+(total/100*taxrate)INTO total;
END IF;
-- finally ,save to out variable
SELECT total INTO ototal;
END;
We used... In the stored procedure DECLARE sentence , They define two local variables ,DECLARE Requires variable name and data type to be specified . It also supports optional defaults (taxrate Default 6%), Because later we have to decide whether to increase taxes , therefore , We put SELECT The results of the query are stored in local variables total in , And then in IF and THEN With the help of , Check taxable Is it true , And then in the real case , We use the other one SELECT Statement to increase business tax to local variable total in , Then we use SELECT Statement will total( The result of increasing or not increasing taxes ) Save to the general ototal in .
COMMENT keyword above COMMENT Can give or not give , If given , Will be in SHOW PROCEDURE STATUS The results show that .
trigger
Automatically process certain statements when a table changes , This is the trigger .
The trigger is MySQL Respond to delete 、update 、insert 、 be located begin and end An automatic execution of a set of statements between statements MySQL sentence . Other statements do not support triggers .
Create trigger
When creating triggers , Need to give 4 statement ( The rules ):
1. Unique trigger name ;
2. Trigger associated table ;
3. Trigger should respond to the activity ;
4. When the trigger executes ( Before or after handling )
Create trigger Sentence creation trigger
CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added' INTO @info;
CREATE TRIGGER Used to create a file named newproduct New trigger for . Triggers can be executed before or after an operation , here AFTER INSERT This trigger is in INSERT Statement executed after successful execution . This trigger also specifies FOR EACH ROW , So the code will execute on every insert line . Text Product added Will show once for each inserted row .
Be careful :
1、 Triggers are only supported by tables , View , Triggers are not supported for temporary tables .
2、 Triggers are defined each time for each event in each table , Only one trigger per event per table is allowed at a time , therefore , Each table supports up to six triggers (insert,update,delete Of before and after).
3、 A single trigger cannot be associated with multiple events or tables , therefore , You need a right insert and update Trigger for operation execution , You should define two triggers .
4、 Trigger failed : If before Trigger failed , be MySQL The requested operation will not be performed , Besides , If before Trigger or statement itself failed ,MySQL Will not execute after trigger .
Trigger category
INSERT trigger
Is in insert Trigger executed before or after statement execution .
1、 stay insert Trigger code , One can be introduced called new The virtual table of , Access the inserted row ;
2、 stay before insert Trigger ,new Values in can also be updated ( Allow changes to inserted values );
3、 about auto_increment Column ,new stay insert Include... Before execution 0, stay insert Include new auto generated values after execution
CREATE TRIGGER neworder AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num;
Create a file called neworder The trigger of , according to AFTER INSERT ON orders perform . Insert a new order into orders Table time ,MySQL Generate a new order number and save it to order_num in . Trigger from NEW.order_num Take this value and return it . This trigger must follow AFTER INSERT perform , Because in BEFORE INSERT Before statement execution , new order_num Not yet generated . about orders This trigger always returns a new order number for each insert of .
DELETE trigger
Delete Trigger in delete Statement before or after execution .
1、 stay delete Trigger code inside , You can quote a name as OLD The virtual table of , To access the deleted row .
2、OLD The values in are all read-only , Can't update .
CREATE TRIGGER deleteorder BEFORE DELETE ON orders FOR EACH ROW
BEGIN
INSERT INTO archive_orders(order_num,order_date,cust_id) values (OLD.order_num,OLD.order_date,OLD.cust_id);
END;
----------------------------------------------------------------
CREATE TABLE archive_orders(
order_num int(11) NOT NULL AUTO_INCREMENT,
order_date datetime NOT NULL,
cust_id int(11) NOT NULL,
PRIMARY KEY (order_num),
KEY fk_orders1_customers1 (cust_id),
CONSTRAINT fk_orders1_customers1 FOREIGN KEY (cust_id) REFERENCES customers
(cust_id)
) ENGINE=InnoDB AUTO_INCREMENT=20011 DEFAULT CHARSET=utf8
This trigger will be executed before any order is deleted , It uses a INSERT Statement will OLD The value in ( Order to be deleted ) Save to a file named archive_orders In the archive form of ( For practical use of this example , We need to use with orders The same column is created with the name archive_orders Table of )
Use BEFORE DELETE Advantages of triggers ( be relative to AFTER DELETE The trigger says ) by , If for some reason , Orders cannot be filed ,delete Itself will be abandoned .
We used... In this trigger BEGIN and END Statement tag trigger body . This is not necessary in this example , Just to illustrate the use of BEGIN END The advantage of blocks is that triggers can hold multiple SQL sentence ( stay BEGIN END One by one in the block ).
UPDATE trigger
stay update Statement before or after execution
1、 stay update Trigger code inside , You can quote a name as OLD The virtual table of , Used to visit before (UPDATE The statement before ) Value , Quote a name as NEW Virtual table access new updated values .
2、 stay BEFORE UPDATE Trigger ,NEW The values in may also be used to update ( Allow changes to be used for UPDATE Value in statement )
3、OLD The values in are all read-only , Can't update .
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors FOR EACH ROW SET NEW.vend_state = Upper(NEW.vemd_state);
Make sure that state abbreviations are always capitalized ( No matter UPFATE Is capitalization given in the statement ), Every time a line is updated ,NEW.vend_state The value in ( Will be used to update the value of the table row ) Use both Upper(NEW.vend_state) Replace .
summary
1、 Usually before For data validation and purification ( To ensure that the data inserted into the table is really the data needed ) Can also be applied to update trigger .
2、 And others DBMS comparison ,MySQL 5 The triggers supported in are fairly rudimentary , In the future MySQL It is estimated that there will be some improved and enhanced trigger support in the version .
3、 Creating triggers may require special security access , But the trigger executes automatically , If insert,update, perhaps delete Statement can execute , Then the relevant trigger can also execute .
4、 Use triggers to ensure data consistency ( Case write , Format, etc. ). The advantage of doing this type of processing in a trigger is that it always does it , And transparently , Nothing to do with client applications .
5、 A very meaningful use of triggers is to create audit trails . Use triggers , Change ( if necessary , Even before and after ) It's very easy to record to another table .
6、MySQL Trigger does not support call sentence , Cannot call stored procedure from within trigger .
Database recovery
implementation technique
Basic principles of recovery operation : redundancy
Two key issues involved in the recovery mechanism
How to build redundant data
Data dump (backup)
Log in log file (logging)
How to use these redundant data to implement database recovery
Data dump
Data dump definition :
Dump means DBA The process of copying the entire database to other storage media and saving it , Backup data is called a backup copy or backup copy
How to use
After the database is destroyed, the backup copy can be reloaded
Reinstalling a backup copy can only restore the database to the state it was in when it was dumped
Dump method
Static dump and dynamic dump
Mass dump and incremental dump
Static dump :
1) Definition : Dump operation when no transaction is running in the system . The database is in one at the beginning of the dump Sexual state , Dump does not allow any access to the database 、 To amend . Static dump must be a consistent copy of the data .
2) advantage : Implement a simple
3) shortcoming : Reduced database availability
The dump must wait for the end of a running user transaction to proceed ; New transactions must wait for the end of the dump to execute
Dynamic dump :
1) Definition : Allow access to or modification of the database during dump . Dumps and user transactions can be executed concurrently .
2) advantage : Don't wait for a running user transaction to end ; Does not affect the operation of new transactions .
3) Realization : It is necessary to register the modification activities of each transaction to the database during the dump , Establishing a backup copy of the log file and adding the log file can restore the database to the correct state at a certain time .
Mass dump :
1) Definition : Dump all databases at a time
2) characteristic : From the perspective of recovery , It is more convenient to use backup copies from mass dump for recovery .
Incremental dump :
1) Definition : Only the data updated after the last dump is dumped each time
2) characteristic : If the database is large , Transaction processing is very frequent , Then incremental dump is more practical and effective .
Log files
1、 What is a log file
Log files (log) It is used to record the update operation of transaction to database
2、 Format of log file
1) In records :
The contents to be registered in the log file include :
Start mark of each transaction (BEGIN TRANSACTION)
The end tag of each transaction (COMMIT or ROLLBACK)
All update operations for each transaction
All of the above are recorded as a log in the log file
What each log records :
Transaction ID ( Indicate which business )
Operation type ( Insert 、 Delete or modify )
Action object ( Record internal identification )
Old value of data before update ( For insertion operations , This item is null )
The new value of the updated data ( For delete operations , This item is null )
2) In blocks
The log records include :
Transaction ID ( Indicate which business )
Updated data block
3、 The role of log files
Perform transaction recovery
Carry out system fault recovery
Assist backup copy in media recovery
1) Log files must be used for transaction recovery and system recovery
2) Log files must be created in dynamic dump mode , Only by combining backup copy with log files can the database be recovered effectively
3) Log files can also be created in static dump mode ( Reload backup copy , Then use the log file to redo the completed transaction , Undo outstanding transactions )
4、 Register log files :
The basic principle of
The order of registration is strictly in the order of parallel transaction execution
You have to write a log file first , Write database after
Why write a log file first ?
1) Writing a database and a log file are two different operations , There may be a fault between these two operations
2) If the database modification is written first , This change is not registered in the log file , Then we can't restore this modification later
3) If you write a log first , But it didn't change the database , It is unnecessary to perform the log file recovery only once more UNDO operation , It doesn't affect the correctness of the database
Recovery strategy
Recovery of transaction failure
Transaction failure : Transaction terminated before running to normal termination
Recovery method
The recovery subsystem should use log files to undo (UNDO) Changes made to the database by this transaction
The recovery of transaction failure is automatically completed by the system , Transparent to users , No user intervention is required
Recovery steps for transaction failure
1. Reverse scan file log , Find the update operation of the transaction .
2. Reverse the update operation of the transaction . Is about to log “ Value before update ” Write to database .
The insert , “ Value before update ” It's empty , It is equivalent to deleting
Delete operation ,“ Updated value ” It's empty , It's equivalent to inserting
If it's a modification , It is equivalent to replacing the modified value with the pre modified value
3. Continue reverse scanning log files , Find other update operations for this transaction , And do the same thing .
4. Deal with it like this , Until you read the start tag of this transaction , Transaction recovery is complete .
Recovery of system failure
The reason of database inconsistency caused by system failure
Incomplete transaction update to database written to database
The update of the committed transaction to the database is still left in the buffer before it can be written to the database
Recovery method
Undo Unfinished transactions at the time of failure
Redo Completed transactions
The recovery of system failure is automatically completed when the system is restarted , No user intervention is required
Recovery steps for system failure
1. Forward scanning log files
redo (REDO) queue : Transactions committed before the failure
These things already have BEGIN TRANSACTION Record , Also have COMMIT Record
revoke (Undo) queue : Unfinished business at the time of failure
These things are just BEGIN TRANSACTION Record , There is no corresponding COMMIT Record
2. To revoke (Undo) Queue transactions to undo (UNDO) Handle
Reverse scan log files , For each UNDO The update operation of the transaction performs the reverse operation
3. To redo (Redo) Queue transactions redo (REDO) Handle
Forward scanning log files , For each REDO The transaction re performs the enlistment operation
Recovery of media failure
Recovery steps
Reload the database
Mount the latest backup copy , Restore the database to the consistency state of the last dump .
For a database copy of a static dump , The database is in a consistent state after loading
For a database copy of a dynamic dump , You must also load a copy of the log file at the time of the dump , Use the method of recovering system failure ( namely REDO+UNDO), To restore the database to a consistent state .
Load a copy of the log file in question , Redo what has been done .
First scan the log file , Find out the ID of the transaction that was committed when the failure occurred , Put it in the redo queue .
Then forward scan the log file , Redo all transactions in the redo queue .
Recovery from media failure requires DBA intervention
DBA The job of
Reinstall the database copy of the latest dump and the copies of the related log files
Execute the recovery command provided by the system , Specific recovery operations are still performed by DBMS complete
checkpoint
There are two problems in using log technology to recover database
Searching the entire log will take a lot of time
REDO Handle : The transaction has actually been executed , And re execute , Wasted a lot of time
With checkpoints (checkpoint) Recovery technology
Add checkpoint records to the log file (checkpoint)
Add restart file , And let the recovery subsystem dynamically maintain the log during log file login
What the checkpoint records
Create a list of all transactions that are executing at checkpoint time
The last logged address of these transactions
Restart the contents of the document
Record the address of each checkpoint recorded in the log file
How to maintain log files dynamically
Periodically do the following : Set up checkpoints , Save database state .
The specific steps are :
1. Write all the log records in the current log buffer to the log file on disk
2. Write a checkpoint record in the log file
3. Write all data records of the current data buffer to the database of the disk
4. Write the address of the checkpoint recorded in the log file to a restart file
Using checkpoint methods can improve recovery efficiency
When a transaction T Submit... Before a checkpoint :
T Changes to the database must have been written to the database
The write time is before or when the checkpoint is established
In recovery processing , There is no need to T perform REDO operation
Use checkpoint recovery steps
1. Find the address of the last checkpoint recorded in the log file... From the restart file , This address finds the last checkpoint record in the log file
2. The checkpoint records the list of all transactions being executed at the checkpoint establishment time ACTIVE-LIST
Create two transaction queues
UNDO-LIST
REDO-LIST
hold ACTIVE-LIST Put in for a while UNDO-LIST queue ,REDO The queue is temporarily empty
3. Scan log files forward from checkpoint , Until the end of the log file
If there is a new beginning Ti, hold Ti Put in for a while UNDO-LIST queue
If there are committed transactions Tj, hold Tj from UNDO-LIST The queue moves to REDO-LIST queue
4. Yes UNDO-LIST Each transaction in performs UNDO operation
Yes REDO-LIST Each transaction in performs REDO operation
Mirror image
In order to avoid hard disk media failure affecting the availability of the database , many DBMS Database image provided (mirror) Function for database recovery .
Copy the entire database or critical data from it to another disk , Whenever the primary database is updated ,DBMS Automatically copy the updated data , from DBMS Automatically ensure the consistency between the image data and the primary database . In case of media failure , It can be used by the mirror disk , meanwhile DBMS Automatic use of disk data for database recovery , There is no need to shut down the system and reinstall the database copy .
When there is no failure , Database mirroring can also be used for concurrent operations , That is, when a user adds an exclusive lock to the database to modify data , Other users can read the data on the mirror database , Instead of waiting for the user to release the lock .
Because database mirroring is achieved by copying data , Assigning data frequently will naturally reduce the efficiency of the system . Therefore, in practical applications, users often only choose to mirror key data and log files .
Summary :
If the database contains only the results of a successful transaction commit , Say the database is in a consistent state . To ensure data consistency is the most basic requirement of database .
A transaction is the logical unit of work of a database
DBMS Ensure the atomicity of all transactions in the system 、 Uniformity 、 Isolation and continuity
DBMS The transaction must fail 、 System failure and medium failure recovery
The most frequently used technology in recovery : Database dump and register log files
The fundamentals of recovery : Use the backup copy stored in 、 Log files and redundant data in the database image to rebuild the database
Common recovery techniques
Recovery of transaction failure
UNDO
Recovery of system failure
UNDO + REDO
Recovery of media failure
Reinstall the backup and restore to a consistent state + REDO
Technology to improve recovery efficiency
Checkpoint Technology
It can improve the recovery efficiency of system failure
To some extent, it can improve the efficiency of media recovery by dynamic dump backup
mirror technique
Image technology can improve the recovery efficiency of media failure
concurrency control
Multi user database : Databases that allow multiple users to use at the same time ( Booking system )
Different multi transaction execution methods :
1. Serial execution : There is only one transaction running at a time , Other transactions must wait until the end of this transaction before running .
2. Cross concurrency :
In a single processor system , The concurrent execution of transactions is actually the cross running of the parallel operations of these parallel transactions ( It's not really concurrency , But it improves the efficiency of the system )
3. Concurrent mode :
In a multiprocessor system , Each processor can run a transaction , Multiple processors can run multiple transactions at the same time , Realize the real parallel operation of multiple transactions
Problems caused by concurrent execution :
Multiple transactions access the same data at the same time ( Shared resources )
Access to incorrect data , Breaking transaction consistency and database consistency
summary
Data inconsistencies caused by concurrent operations include
1) Missing changes (lost update)
2) It can't be read repeatedly (non-repeatable read)
3) Read dirty data (dirty read)
mark :W(x) Writing data x R(x) Reading data x
The task of concurrency control mechanism :
1) Schedule concurrent operations correctly
2) Ensure the isolation of transactions
3) Ensure database consistency
The main technology of concurrency control
1) The blockade (locking)( Mainly used )
2) Time stamp (timestamp)
3) Optimistic control (optimistic scheduler)
4) Multi version concurrency control (multi-version concurrency control ,MVCC)
summary :
Xueba notes ( On ) I hope it helped you , Update Xueba's notes tomorrow ( Next ) Let's hope together ~
边栏推荐
- Ultrasonic ranging based on FPGA
- Oracle Chinese sorting Oracle Chinese field sorting
- JAD installation, configuration and integration idea
- 公司破产后,黑石们来了
- Windows Oracle open remote connection Windows Server Oracle open remote connection
- Password reset of MariaDB root user and ordinary user
- Redhat7.4 configure Yum software warehouse (rhel7.4)
- Startup and shutdown of CDB instances
- Mariadb root用户及普通用户的密码 重置
- How to convert word into PDF? Word to PDF simple way to share!
猜你喜欢

开源 SPL 消灭数以万计的数据库中间表
![[detailed explanation of AUTOSAR 14 startup process]](/img/c4/5b08b43db97d8bb10c7207005f8c0a.png)
[detailed explanation of AUTOSAR 14 startup process]
Mysql database indexing tutorial (super detailed)
Django uses mysqlclient service to connect and write to the database
Fuzor 2020 software installation package download and installation tutorial
2022 the latest big company Android interview real problem analysis, Android development will be able to technology

面试官:Redis中集合数据类型的内部实现方式是什么?
cf:B. Almost Ternary Matrix【对称 + 找规律 + 构造 + 我是构造垃圾】
What are the reliable domestic low code development platforms?
ELK分布式日志分析系统部署(华为云)

随机推荐
Debezium系列之:postgresql从偏移量加载正确的最后一次提交 LSN
数据库 逻辑处理功能
How to quickly advance automated testing? Listen to the personal feelings of the three bat test engineers
#夏日挑战赛# HarmonyOS - 实现消息通知功能
块编辑器如何选择?印象笔记 Verse、Notion、FlowUs
公司破产后,黑石们来了
Hiengine: comparable to the local cloud native memory database engine
Mysql如何对json数据进行查询及修改
手机开户选择哪家券商公司比较好哪家平台更安全
Can Leica capture the high-end market offered by Huawei for Xiaomi 12s?
决策树与随机森林
微波雷达感应模块技术,实时智能检测人体存在,静止微小动静感知
在线协作产品哪家强?微软 Loop 、Notion、FlowUs
618“低调”谢幕,百秋尚美如何携手品牌跨越“不确定时代”?
视频融合云平台EasyCVR增加多级分组,可灵活管理接入设备
ELK分布式日志分析系统部署(华为云)
潘多拉 IOT 开发板学习(HAL 库)—— 实验8 定时器中断实验(学习笔记)
EasyCVR电子地图中设备播放器loading样式的居中对齐优化
Go语言 | 02 for循环及常用函数的使用
Debezium系列之:修改源码支持unix_timestamp() as DEFAULT value