当前位置:网站首页>write文件一个字节后何时发起写磁盘IO
write文件一个字节后何时发起写磁盘IO
2020-11-08 16:12:00 【张彦飞allen】
在前文《read文件一个字节实际会发生多大的磁盘IO?》写完之后,本来想着偷个懒,只通过读操作来让大家了解下Linux IO栈的各个模块就行了。但很多同学表示再让我写一篇关于写操作的。既然不少人都有这个需求,那我就写一下吧。
Linux内核真的是太复杂了,源代码的行数已经从1.0版本时的几万行,到现在已经是千万行的一个庞然大物了。直接钻进去的话,很容易在各种眼花缭乱的各种调用中迷失了自己,再也钻不出来了。我分享给大家一个我在琢磨内核的方法。一般我自己先想一个自己很想搞清楚的问题。不管在代码里咋跳来跳去,时刻都要记得自己的问题,无关的部分尽量少去发散,只要把自己的问题搞清楚了就行了。
现在我想搞明白的问题是,在最常用的方式下,不开O_DIRECT、不开O_SYNC(写文件的方法有很多,有sync模式、direct模式、mmap内存映射模式),write是怎么写的。c的代码示例如下:
#include <fcntl.h>
int main()
{
char c = 'a';
int out;
out = open("out.txt", O_WRONLY | O_CREAT | O_TRUNC);
write(out,&c,1);
...
}
进一步细化我的问题,我们对打开的问题写入一个字节后
- write函数在内核里是怎么执行的?
- 数据在什么时机真正能写入到磁盘上?
我们在讨论的过程中不可避免地要涉及到内核代码,我使用的内核版本是3.10.1。如果有需要,你可以到这里来下载。https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/。
write函数实现剖析
我花了不短的时候跟踪write写到ext4文件系统时的各种调用和返回,大致理出来了一个交互图。当然为了突出重点,我抛弃了不少细节,比如DIRECT IO、ext4日志记录啥的都没有体现出来,只抽取出来了一些我认为关键的调用。
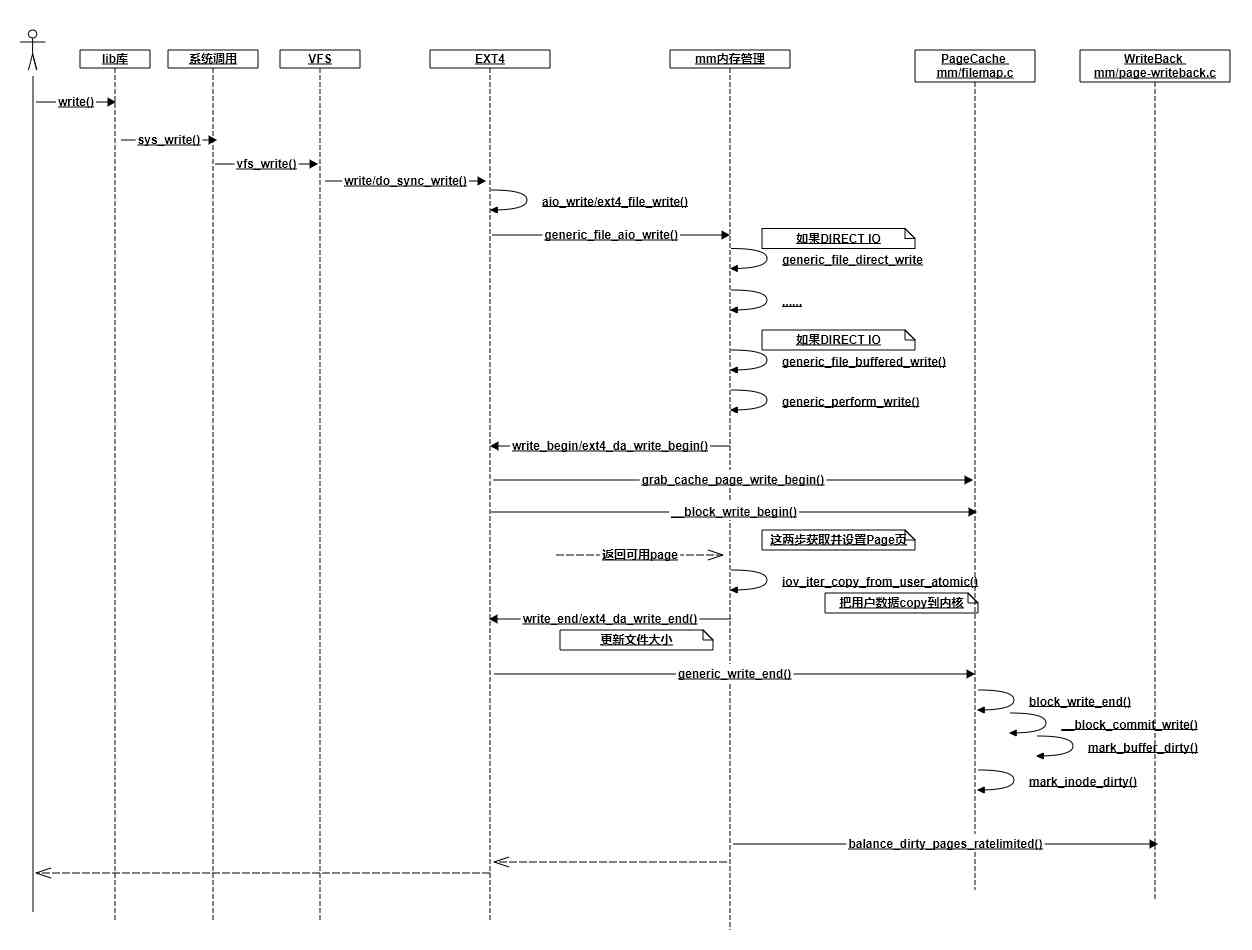
在上面的流程图里,所有的写操作最终到哪儿了呢?在最后面的__block_commit_write中,只是make dirty。然后大部分情况下你的函数调用就返回了(稍后再说balance_dirty_pages_ratelimited)。数据现在还在内存中的PageCache里,并没有真正写到硬盘。
为什么要这样实现,不直接写硬盘呢?原因就在于硬盘尤其是机械硬盘,性能是在是太慢了。一块服务器级别的万转盘,最坏随机访问平均延迟都是毫秒级别的,换算成IOPS只有100多不到200。设想一下,假如你的后端接口里每个用户来访问都需要一次随机磁盘IO,不管你多牛的服务器,每秒200的qps都将直接打爆你的硬盘,相信作为为百万/千万/过亿用户提供接口的你,这个是你绝对不能忍的。
Linux这么搞也是有副作用的,如果接下来服务器发生掉电,内存里东西全丢。所以Linux还有另外一个“补丁”-延迟写,帮我们缓解这个问题。注意下,我说的是缓解,并没有彻底解决。
再说下balance_dirty_pages_ratelimited,虽然绝大部分情况下,都是直接写到Page Cache里就返回了。但在一种情况下,用户进程必须得等待写入完成才可以返回,那就是对balance_dirty_pages_ratelimited的判断如果超出限制了。该函数判断当前脏页是否已经超过脏页上限dirty_bytes、dirty_ratio,超过了就必须得等待。这两个参数只有一个会生效,另外1个是0。拿dirty_ratio来说,如果设置的是30,就说明如果脏页比例超过内存的30%,则write函数调用就必须等待写入完成才能返回。可以在你的机器下的/proc/sys/vm/目录来查看这两个配置。
# cat /proc/sys/vm/dirty_bytes
0
# cat /proc/sys/vm/dirty_ratio
30
内核延迟写
内核是什么时候真正把数据写到硬盘中呢?为了快速摸清楚全貌,我想到的办法是用systemtap工具,找到内核写IO过程中的一个关键函数,然后在其中把函数调用堆栈打出来。查了半天资料以后,我决定用do_writepages这个函数。
#!/usr/bin/stap
probe kernel.function("do_writepages")
{
printf("--------------------------------------------------------\n");
print_backtrace();
printf("--------------------------------------------------------\n");
}
systemtab跟踪以后,打印信息如下:
0xffffffff8118efe0 : do_writepages+0x0/0x40 [kernel]
0xffffffff8122d7d0 : __writeback_single_inode+0x40/0x220 [kernel]
0xffffffff8122e414 : writeback_sb_inodes+0x1c4/0x490 [kernel]
0xffffffff8122e77f : __writeback_inodes_wb+0x9f/0xd0 [kernel]
0xffffffff8122efb3 : wb_writeback+0x263/0x2f0 [kernel]
0xffffffff8122f35c : bdi_writeback_workfn+0x1cc/0x460 [kernel]
0xffffffff810a881a : process_one_work+0x17a/0x440 [kernel]
0xffffffff810a94e6 : worker_thread+0x126/0x3c0 [kernel]
0xffffffff810b098f : kthread+0xcf/0xe0 [kernel]
0xffffffff816b4f18 : ret_from_fork+0x58/0x90 [kernel]
从上面的输出我们可以看出,真正的写文件过程操作是由worker内核线程发出来的(和我们自己的应用程序进程没有半毛钱关系,此时我们的应用程序的write函数调用早就返回了)。这个worker线程写回是周期性执行的,它的周期取决于内核参数dirty_writeback_centisecs的设置,根据参数名也大概能看出来,它的单位是百分之一秒。
# cat /proc/sys/vm/dirty_writeback_centisecs
500
我查看到我的配置是500,就是说每5秒会周期性地来执行一遍。回顾我们的问题,我们最关心的问题的啥时候写入的,围绕这个思路不过多发散。于是沿着这个调用栈不断地跟踪,跳转,终于找到了下面的代码。如下代码里我们看到,如果是for_background模式,且over_bground_thresh判断成功,就会开始回写了。
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
work->older_than_this = &oldest_jif;
...
if (work->for_background && !over_bground_thresh(wb->bdi))
break;
...
if (work->for_kupdate) {
oldest_jif = jiffies -
msecs_to_jiffies(dirty_expire_interval * 10);
} else ...
}
static long wb_check_background_flush(struct bdi_writeback *wb)
{
if (over_bground_thresh(wb->bdi)) {
...
return wb_writeback(wb, &work);
}
}
那么over_bground_thresh函数判断的是啥呢?其实就是判断当前的脏页是不是超过内核参数里dirty_background_ratio或dirty_background_bytes的配置,没超过的话就不写了(代码位于fs/fs-writeback.c:1440,限于篇幅我就不贴了)。这两个参数只有一个会真正生效,其中dirty_background_ratio配置的是比例、dirty_background_bytes配置的是字节。
在我的机器上的这两个参数配置如下,表示脏页比例超过10%就开始回写。
# cat /proc/sys/vm/dirty_background_bytes
0
# cat /proc/sys/vm/dirty_background_ratio
10
那如果脏页一直都不超过这个比例怎么办呢,就不写了吗? 不是的。在上面的wb_writeback函数中我们看到了,如果是for_kupdate模式,会记录一个过期标记到work->older_than_this,再往后面的代码中把符合这个条件的页面也写回了。dirty_expire_interval这个变量是从哪儿来的呢? 在kernel/sysctl.c里,我们发现了蛛丝马迹。哦,原来它是来自/proc/sys/vm/dirty_expire_centisecs这个配置。
1158 {
1159 .procname = "dirty_expire_centisecs",
1160 .data = &dirty_expire_interval,
1161 .maxlen = sizeof(dirty_expire_interval),
1162 .mode = 0644,
1163 .proc_handler = proc_dointvec_minmax,
1164 .extra1 = &zero,
1165 },
在我的机器上,它的值是3000。单位是百分之一秒,所以就是脏页过了30秒就会被内核线程认为需要写回到磁盘了。
# cat /proc/sys/vm/dirty_expire_centisecs
3000
结论
我们demo代码中的写入,其实绝大部分情况都是写入到PageCache中就返回了,这时并没有真正写入磁盘。我们的数据会在如下三个时机下被真正发起写磁盘IO请求:
- 第一种情况,如果write系统调用时,如果发现PageCache中脏页占比太多,超过了dirty_ratio或dirty_bytes,write就必须等待了。
- 第二种情况,write写到PageCache就已经返回了。worker内核线程异步运行的时候,再次判断脏页占比,如果超过了dirty_background_ratio或dirty_background_bytes,也发起写回请求。
- 第三种情况,这时同样write调用已经返回了。worker内核线程异步运行的时候,虽然系统内脏页一直没有超过dirty_background_ratio或dirty_background_bytes,但是脏页在内存中呆的时间超过dirty_expire_centisecs了,也会发起会写。
如果对以上配置不满意,你可以自己通过修改/etc/sysctl.conf来调整,修改完了别忘了执行sysctl -p。
最后我们要认识到,这套write pagecache+回写的机制第一目标是性能,不是保证不丢失我们写入的数据的。如果这时候掉电,脏页时间未超过dirty_expire_centisecs的就真的丢了。如果你做的是和钱相关非常重要的业务,必须保证落盘完成才能返回,那么你就可能需要考虑使用fsync。

开发内功修炼之硬盘篇专辑:
- 1.磁盘开篇:扒开机械硬盘坚硬的外衣!
- 2.磁盘分区也是隐含了技术技巧的
- 3.我们怎么解决机械硬盘既慢又容易坏的问题?
- 4.拆解固态硬盘结构
- 5.新建一个空文件占用多少磁盘空间?
- 6.只有1个字节的文件实际占用多少磁盘空间
- 7.文件过多时ls命令为什么会卡住?
- 8.理解格式化原理
- 9.read文件一个字节实际会发生多大的磁盘IO?
- 10.write文件一个字节后何时发起写磁盘IO?
- 11.机械硬盘随机IO慢的超乎你的想象
- 12.搭载固态硬盘的服务器究竟比搭机械硬盘快多少?
我的公众号是「开发内功修炼」,在这里我不是单纯介绍技术理论,也不只介绍实践经验。而是把理论与实践结合起来,用实践加深对理论的理解、用理论提高你的技术实践能力。欢迎你来关注我的公众号,也请分享给你的好友~~~
版权声明
本文为[张彦飞allen]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4746202/blog/4707204
边栏推荐
- Xiaoqingtai officially set foot on the third day of no return
- laravel8更新之速率限制改进
- Blockchain weekly: the development of digital currency is written into the 14th five year plan; Biden invited senior adviser of MIT digital currency program to join the presidential transition team; V
- 我用 Python 找出了删除我微信的所有人并将他们自动化删除了
- AQS解析
- What is SVG?
- Elasticsearch 学习一(基础入门).
- Ubuntu20.04 access FTP server garbled problem + upload files
- 三、函数的参数
- Flink from introduction to Zhenxiang (10. Sink data output elasticsearch)
猜你喜欢

华为在5G手机市场占据绝对优势,市调机构对小米的市占出现分歧
How to solve the difference between NAT IP and port IP
GopherChina 2020大会
Application of four ergodic square of binary tree
Flink from introduction to Zhenxiang (7. Sink data output file)

I used Python to find out all the people who deleted my wechat and deleted them automatically

rabbitmq(一)-基础入门
构建者模式(Builder pattern)
How to solve the conflict when JD landed on Devops platform?
Solution to the problem of offline connection between ADB and mobile phone
随机推荐
laravel8更新之速率限制改进
我用 Python 找出了删除我微信的所有人并将他们自动化删除了
学习记录并且简单分析
VIM configuration tutorial + source code
Apache Kylin远程代码执行漏洞复现(CVE-2020-1956)
Windows下快递投递柜、寄存柜的软件初探
阿里云的MaxCompute数加(原ODPS)用的怎样?
契约式设计(Dbc)以及其在C语言中的应用
Learn to record and analyze
wanxin finance
Golang 系统ping程序探测存活主机(任意权限)
STM32CubeIDE下载安装-GPIO基本配置操作-Debug调试(基于CMSIS DAP Debug)
Arduino IDE搭建ESP8266开发环境,文件下载过慢解决方法 | ESP-01制作WiFi开关教程,改造宿舍灯
Is there no way out for older programmers?
小青台正式踏上不归路的第3天
华为在5G手机市场占据绝对优势,市调机构对小米的市占出现分歧
This paper analyzes the top ten Internet of things applications in 2020!
京东落地DevOps平台时爆发的冲突如何解决?
软件开发中如何与人协作? | 每日趣闻
我用 Python 找出了删除我微信的所有人并将他们自动化删除了