当前位置:网站首页>Superscalar processor design yaoyongbin Chapter 2 cache -- Excerpt from subsection 2.2
Superscalar processor design yaoyongbin Chapter 2 cache -- Excerpt from subsection 2.2
2022-06-11 21:56:00 【Qi Qi】
2.2 Improve Cache Performance of
In real-world processors , Will adopt more complex methods to improve Cache Performance of , These methods include write caching write buffer、 Assembly line pipeline cache、 Multistage structure multilevel cache、victim cache And expectations prefetch. besides , For superscalar processors that execute out of order , According to its characteristics , There are other ways to improve Cache Performance of , For example, non blocking non-blocking cache、 Keyword first critical word first And early start early restart Other methods .
2.2.1 Write cache
Whether it's load perhaps store Instructions , When D-Cache When a loss occurs , Need to read data from the next level of memory , And write a selected Cache line in , If this line yes dirty, First, you need to write it to the lower level memory , Consider general sub memory , for example L2 Cache Or physical memory , Generally, there is only one read / write port , This requires that the above process be completed serially . First the dirty Of Cache line The data is written to the lower level memory , Then the lower level memory can be read and the missing data can be obtained , Because the access time of lower level memory is relatively long , This serial process leads to D-Cache The processing time for missing items becomes very long , At this point, you can use write buffer Write cache to solve this problem ,dirty Of Cache line First put it in the write cache , Wait until the lower level memory is free , Will write the data in the write cache to the lower level memory .

about write back Type of D-Cache Come on , When one dirty Of Cache line When it's replaced , This line The data in will be put into the write cache first , Then you can read data from the lower level memory .
about write through Type of D-Cache Come on , After using write cache , Every time the data is written to D-Cache At the same time , It will not be written to the lower level memory at the same time , Instead, put it in the write cache , This reduces write through Type of D-Cache Time required for write operations , This improves the performance of the processor , as well as write through Type of Cache Because it is easy to manage memory consistency , So in a multi-core processor ,L1 Cache This structure is often used .
After adding write cache , It will increase the complexity of system design , for instance , When reading D-Cache When a loss occurs , It is not only necessary to look up this data from the lower level memory , You also need to look in the write cache .
Write cache is equivalent to L1 Cache A buffer to lower level storage , Through it , The action of writing data to lower level memory will be hidden , Thus, the execution efficiency of the processor can be improved , Especially for write through Type of D-Cache for .
2.2.2 Assembly line
For reading D-Cache Come on , because Tag SRAM and Data SRAM It can be read at the same time , So when the cycle time requirement of the processor is not very strict , The read operation can be completed in one cycle ; And for writing D-Cache Come on , The situation is quite special , Read Tag SRAM And write Data SRAM The operation of can only be done serially . Only through Tag Compare , Make sure that the address you need to write is Cache In the following , To write Data SRAM, In a processor with a high dominant frequency , These operations are difficult to complete in one cycle . It needs to be right D-Cache The write operation of adopts pipeline structure . A typical way is to Tag SRAM Read and compare in one cycle , Write D-Cache In the next cycle .
It should be noted that when executing load When instruction , The data it wants may just be in store In the pipeline register of the instruction , Not from Data SRAM, Therefore, a mechanism is needed to detect this situation , take load The address carried by the instruction and store Pipeline registers of instructions .
Antithetical writing D-Cache After using the pipeline , It not only increases the hardware of the pipeline itself , It also brings some additional hardware overhead .
2.2.3 Multistage structure
Modern processors are eager to have a large capacity , At the same time, fast memory , But in the silicon process , For memory , Capacity and speed are a pair of mutually restrictive factors , Large capacity leads to slow speed .
In order to make the processor seem to use a large capacity and fast memory , Multi level structure can be used Cache:
![]()
In general ,L1 Cache The capacity is very small , Can maintain the same speed level as the processor ,L2 Cache Access to the processor usually consumes several clock cycles of the processor , But the capacity should be larger ,L1 and L2 Cache On the same chip as the processor , Now? L3 Cache Also on the film .
Usually in the processor ,L2 Cache Will use write back The way , however L1 Cache Prefer to use wirte through, This can simplify the pipeline design , Especially in the case of multi-core , Manage consistency between storage .
For multi-level structure Multilevel Cache, There are two more concepts to understand ,Inclusive and Exclusive:
Inclusive: If L2 Cache It includes L1 Cache All of , said L2 Cache yes Inclusive;
Exclusive: If L2 Cache And L1 Cache The contents of are different from each other , said L2 Cache yes Exclusive;
Inclusive Type of Cache It is a waste of hardware resources , Because it keeps one piece of data in two places , The advantage is that the data can be written directly to L1 Cache in , Although at this time will Cache line The data from the central plains are overwritten , But in L2 Cache A backup of this data is stored in , So such coverage doesn't cause any problems ( Of course , Covered line It can't be dirty), And also simplifies consistency coherence Management of .
For example, in a multi-core processor , perform store When an instruction changes data at an address in memory , If it is Inclusive Type of Cache, Then just check the lowest level Cache that will do (L2 Cache), Avoid disturbing superiors Cache(L1 Cache) And processor pipelining ;
If it is Exclusive Type of Cache, It's obvious to check all Cache, And check L1 Cache This means that it interferes with the pipeline of the processor . If the data to be read by the processor is not L1 Cache in , And in the L2 Cache in , So, we're moving data from L2 Cache Put it in L1 Cache At the same time , We also need to L1 Cache The overwritten data in is written to L2 Cache in , Such data exchange will obviously reduce the efficiency of the processor , however Exclusive Type of Cache Avoid hardware waste , Get more usable capacity .
2.2.4 Victim Cache
Cache Middle quilt “ Kicked out ” The data may be used again soon , because Cache Data stored in is often used . For example, for a 2-way Group connected D-Cache Come on , If data is used frequently 3 All the data are located in the same Cache set in , Then it will lead to a way The data in is often “ Kicked out ”Cache, Then it is often written back to Cache.

This can lead to Cache The data required by the name is always unavailable , Obviously, it reduces the execution efficiency of the processor , If you add Cache Medium way Number , It will waste a lot of space .Victim Cache It is to solve such a problem , It can save recently kicked out Cache The data of , So all Cache set Can use it to improve way The number of , Usually Victim Cache In a fully connected way , The capacity is quite small ( General storage 4~16 Data ).

Victim Cache In essence, it is equivalent to increasing Cache in way The number of , Avoid multiple data competitions Cache Limited location in , So it reduces Cache The missing rate of . In general ,Cache and Victim Cache There is a mutually exclusive relationship , That is, they do not contain the same data , The processor core can read them at the same time .
Again ,Victim Cache The data will be written to Cache in , and Cache The replaced data in will be written to Victim Cache in , This is equivalent to exchanging data .
There is a more Victim Cache Similar design ideas , be called Filter Cache, Only used in Cache Before , and Victim Cache Use in Cache after , When a data is first used , It's not going to go right away Cache in , But first it will be put in Filter Cache in , When this data is used again , It will be moved to Cache in , Doing so will prevent accidental use of data from taking up Cache.

2.2.5 Prefetch
influence Cache Missing rate 3C One of them is Compulsory, When the processor first accesses an instruction or a data , This instruction or data will definitely not be in Cache in , The absence caused by this situation seems inevitable , But actually using prefetching prefetch Can alleviate this problem . Prefetching , In essence, it is also a prediction technology , It guesses what instructions or data the processor might use in the future , Then put it in advance Cache in , This process can be done with hardware or software .
1. Hardware prefetching
For instructions , It is relatively easy to guess what instructions will be executed later , Because the program itself is executed serially , Although due to the existence of branch instructions , This kind of speculation sometimes goes wrong , Resulting in instructions that will not be used I-Cache, On the one hand, it reduces I-Cache Actual available capacity , On the one hand, it takes up instructions that might have been useful , This is called “Cache Pollution ”, It's not just a waste of time , It also affects the execution efficiency of the processor , To avoid that , You can put prefetched instructions into a separate cache .
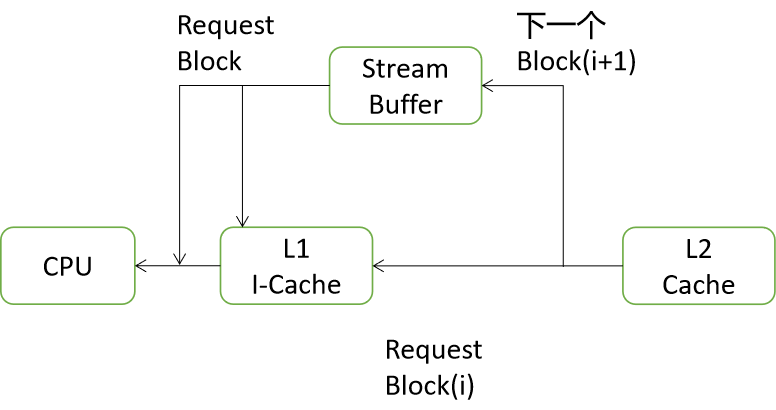
When I-Cache When a loss occurs , Processing the data blocks that will be needed data block Take it out of the lower level memory and put it in I-Cache in , It will also drop a data block and read it out , But it won't be put in I-Cache in , It's about putting Stream Buffer The place of . In subsequent execution , If in I-Cache Missing in , But in Stream Buffer Found the desired command , So in addition to using Stream Buffer Out of the instructions read in , The corresponding data blocks will also be moved to I-Cache in , At the same time, continue to read the next data block from the next level of memory and put it into Stream Buffer, When no branch instruction is encountered in the program , This method will always work correctly , So that I-Cache The deletion rate of is reduced . But branch instructions can lead to Stream Buffer The instruction of is invalid , Prefetching at this time is equivalent to doing useless work , Wasted bus bandwidth and power consumption . Prefetching is a double-edged sword , It may reduce Cache The missing rate of , It may also waste power and performance due to incorrect prefetching .
Different from instruction prefetching , For data prefetching , Its laws are more difficult to capture . In general , When accessing D-Cache When a loss occurs , In addition to extracting the required data blocks from the lower level memory , The next data block will also be read out .Intel Pentium 4 and IBM Power5 In the processor , It uses a method called Strided Prefetch Method , It can use hardware to observe the rules of the data used in the program .
2. Software prefetching
Use hardware to prefetch data , It's hard to get satisfactory results , In fact, in the compilation stage of the program , compiler complier You can analyze the program , Then we can know which data needs to be prefetched , If there are prefetch instructions in the instruction set prefetch instruction, Then the compiler can directly control the program to prefetch .
The prefetching method of application software has a premise , Is the time to prefetch . If the data is prefetched too late , So when you really need to use data , It may not have been prefetched yet , So prefetching loses its meaning ; If the prefetch time is too early , Then it's possible to kick it out D-Cache Some useful data in , cause Cache Pollution .
Attention is also needed , Use the software prefetching method , When the prefetch instruction is executed , The processor needs to be able to continue , That is, we can continue from D-Cache Read data from , The prefetch instruction should not be allowed to hinder the execution of subsequent instructions , This requires D-Cache yes non-blocking structure .
In implementing virtual storage Virtual memory In the system , Prefetch instructions may cause some exceptions exception happen , for example Page fault、 Virtual address error virtual address fault Or protect against violations Protection Violation. At this time, if the exception is handled , This is called a prefetch instruction that handles errors Faulting Prefetch Instruction, conversely , It is called a prefetch instruction that does not handle errors nonfaulting prefetch instruction.
边栏推荐
- 高考结束,人生才刚刚开始,10年职场老鸟给的建议
- win10字体模糊怎么调节
- Go OS module
- 领先企业推进智慧财务的同款效率工具,赶快了解一下?
- 实验10 Bezier曲线生成-实验提高-交互式生成B样条曲线
- 二分查找 - 学习
- Latex combat notes 3- macro package and control commands
- All inherited features
- Experiment 10 Bezier curve generation - experiment improvement - control point generation of B-spline curve
- 2022-02-28(2)
猜你喜欢

类和对象(4)
![[niuke.com] DP30 [template] 01 Backpack](/img/a2/9bcfbe6f78f30282fd8940c57477b1.jpg)
[niuke.com] DP30 [template] 01 Backpack

如何查看win系统的安装日期

Master of a famous school has been working hard for 5 years. AI has no paper. How can the tutor free range?

Why is rpa+ low code a powerful tool to accelerate the digital transformation of finance?

The college entrance examination is over, and life has just begun. Suggestions from a 10-year veteran in the workplace

Carry and walk with you. Have you ever seen a "palm sized" weather station?
Huawei equipment configuration hovpn

RPA+低代码助推品牌电商启新创变、重启增长

How does the chief financial officer of RPA find the "super entrance" of digital transformation?
随机推荐
The network connection is normal, but Baidu web page can not be opened and displayed. You can't access this website solution
【学术相关】申请审核制下,到双一流大学读博的难度有多大?
JVM | virtual machine stack (local variable table; operand stack; dynamic link; method binding mechanism; method call; method return address)
go encoding包
C语言实现迷宫问题
Matlab: solution of folder locking problem
B. Phoenix and Beauty
Flutter series: detailed explanation of container layout commonly used in flutter
Customer information management software
189. 轮转数组
JVM | runtime data area; Program counter (PC register);
自定义实现offsetof
判断大小端存储两种办法
Leetcode-110-balanced binary tree
How to use RPA robot to start the first step of digital transformation of freight forwarding industry?
Carry and walk with you. Have you ever seen a "palm sized" weather station?
How to use the transaction code sat to find the name of the background storage database table corresponding to a sapgui screen field
Nmap performs analysis of all network segment IP survivals in host detection
Sword finger offer 29 Print matrix clockwise
Redis transaction