当前位置:网站首页>Flink并行度和Slot详解
Flink并行度和Slot详解
2022-07-07 17:37:00 【锋火连天】
Flink并行度和Slot详解
地址:
https://blog.csdn.net/zuodaoyong/article/details/106178488?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=2
一、概念
1、Task:一个阶段多个功能相同的subTask的集合,类似Spark的TaskSet
2、SubTask:是任务最小的执行单元,是一个Java类的实例,完成具体的计算逻辑
3、Slot:计算资源的隔离单元,一个Slot可以运行多个SubTask,但是这些SubTask必须是来自同一个application的不同阶段的subTask。
注意:Flink划分Task主要有四种情况:
(1)类似keyBy,broadcast,rebalance等算子产生shuffer
(2)Parallelism(并行度)变化
(3)new chain,即在算子上执行startNewChain()后,该算子与前面执行的算子分开。
(4)disableChaining,在算子上执行disableChaining(),即算子的开始到结束,单独生成一个task。使用场景,比如该算子逻辑复杂,让算子独自使用一个task内的SubTask。
二、slot
Flink中每一个TaskManager都是一个JVM进程,它可能会在slot上执行一个或多个subTask。
slot数量通常与每个TaskManager节点的可用CPU内核数成比例。一般Slot数量是每个节点的CPU内核数。
Slot的数量由集群中flink-conf.yml配置文件中taskmanager.numberOfTaskSlots设置的。
注意:同一个slot不能执行同一个task的多个subTask。
扩展:slotSharingGroup(String slotSharingGroup)即共享slot
假设flink集群有3个节点,一个jobManager,2个TaskManager。每个TaskManager有2个Slot。即该集群是一共4个slot
任务分配的slot默认名称是default。
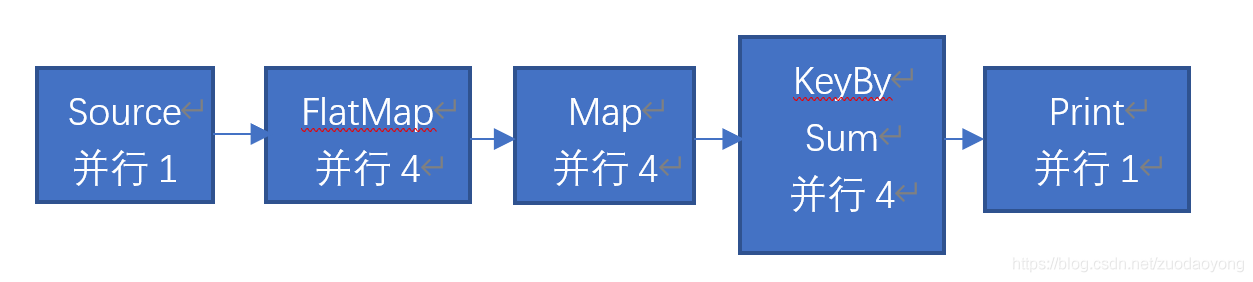
拿wordcount为例,运行该application,5个task,14个subTask都运行在共享slot名为"default"上。
如果flatMap上调用slotSharingGroup(“slot_name”),则flatMap放在名称叫slot_name的slot上。
后面算子map,keyBy,print都会分配slot名称为slot_name上运行。
那么,异常情况出现了 ,集群中的4个slot,有一个default的slot中运行的是source,flatMap的并行度为4,需要分配到4个叫slot_name的slot上。但是slot_name只有3个。导致资源不够,任务部署失败。
解决方法可以调整并行度为3,或者取消slotSharingGroup的设置。
总结:
(1)Flink的任务资源槽默认名称是default
(2)通过算子调用slotSharingGroup设置算子运行的槽位
(3)如果改变了共享槽位的名称,后面的算子没有设置共享槽位的名称,那么就和上一次改变的槽位名称一致
(4)槽位名称不同的subTask不能在同一个槽位中执行
三、并行度
1、并行度的设定
(1)Operator Level(算子层面)
(2)Execution Environment Level(执行环境层面)
(3)Client Level(客户端层面)
(4)System Level(系统层面,即配置文件中配置)
并行度设定优先级:Operator Level > Execution Environment Level > Client Level > System Level
边栏推荐
- Le PGR est - il utile au travail? Comment choisir une plate - forme fiable pour économiser le cœur et la main - d'œuvre lors de la préparation de l'examen!!!
- 小试牛刀之NunJucks模板引擎
- Unable to link the remote redis server (solution 100%
- Key points of anti reptile: identifying reptiles
- 干货分享|DevExpress v22.1原版帮助文档下载集合
- R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
- 8 CAS
- How to estimate the value of "not selling pens" Chenguang?
- Is PMP beneficial to work? How to choose a reliable platform to make it easier to prepare for the exam!!!
- My creation anniversary
猜你喜欢

PMP每日一练 | 考试不迷路-7.7

干货分享|DevExpress v22.1原版帮助文档下载集合
Jürgen Schmidhuber回顾LSTM论文等发表25周年:Long Short-Term Memory. All computable metaverses. Hierarchical reinforcement learning (RL). Meta-RL. Abstractions in generative adversarial RL. Soccer learn

论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》

# 欢迎使用Markdown编辑器
ASP.NET幼儿园连锁管理系统源码
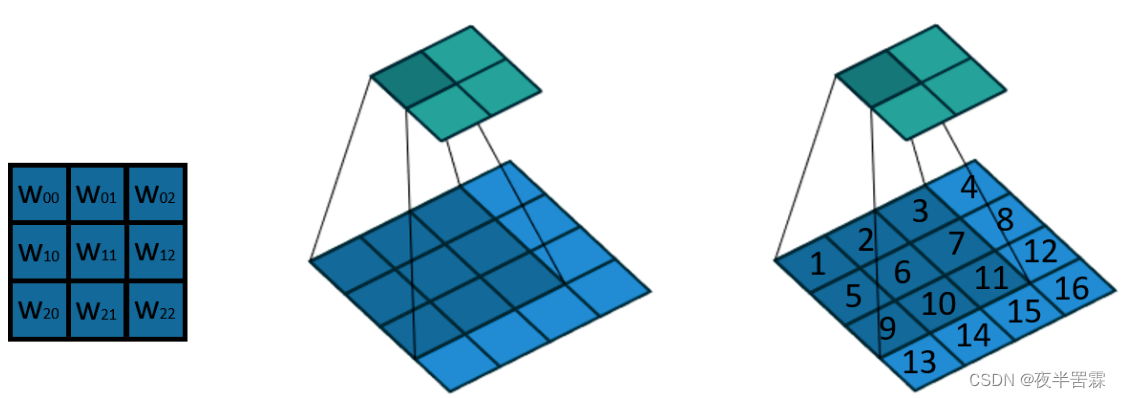
转置卷积理论解释(输入输出大小分析)
ASP. Net kindergarten chain management system source code
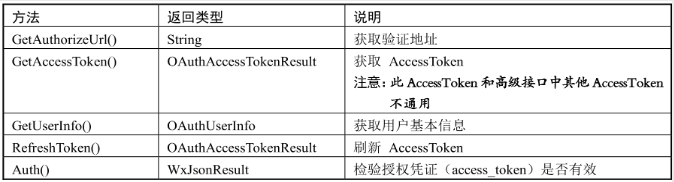
微信公众号OAuth2.0授权登录并显示用户信息
PMP對工作有益嗎?怎麼選擇靠譜平臺讓備考更省心省力!!!
随机推荐
Throughput
el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
【RT-Thread env 工具安装】
杰理之测试盒配置声道【篇】
What does "true" mean
[confluence] JVM memory adjustment
Interpretation of transpose convolution theory (input-output size analysis)
吞吐量Throughout
Numpy——2.数组的形状
Automatic classification of defective photovoltaic module cells in electroluminescence images-论文阅读笔记
转置卷积理论解释(输入输出大小分析)
Longest common prefix (leetcode question 14)
LeetCode1051(C#)
My creation anniversary
Zhong Xuegao wants to remain innocent in the world
IP 工具类
华南X99平台打鸡血教程
2022.07.05
索引总结(突击版本)
PMP practice once a day | don't get lost in the exam -7.7