当前位置:网站首页>dried food! Accelerating sparse neural network through hardware and software co design
dried food! Accelerating sparse neural network through hardware and software co design
2022-07-06 01:28:00 【Aitime theory】
Click on the blue words

Pay attention to our
AI TIME Welcome to everyone AI Fans join in !

Pruning to remove redundant weights is a common method of compressing neural networks . However , Because the sparse pattern generated by pruning is relatively random , Difficult to be effectively utilized by hardware , There is a big gap between the compression ratio realized by the previous method and the reasoning acceleration of the actual time on the hardware . The structured pruning method limits the pruning process , Only a relatively limited compression ratio can be achieved . To solve this problem , In this work , We designed a hardware friendly compression method . By decomposing the original weight matrix , We decompose the original convolution into two steps , Linear combination of input features and convolution operation using base convolution kernel . Based on this structure , Accordingly, we designed a sparse neural network accelerator to efficiently skip redundant operations , Achieve the purpose of improving reasoning performance and energy consumption ratio .
In this issue AI TIME PhD studio , We invite doctoral students from the Department of electronic and computer engineering at Duke University —— Li Shiyu , Bring us report sharing 《 Accelerate the sparse neural network through software and hardware co design 》.

Li Shiyu :
I graduated from Automation Department of Tsinghua University , At present, he is a third year doctoral student in the Department of electronic and computer engineering at Duke University , Learn from Li Hai and Chen Yiran . His main research interests are computer architecture and software and hardware co design of deep learning system .
The inflation of model size
While pursuing the accuracy of neural network recognition , We find that the new generation of neural network models are increasing in both the amount of computation and the number of parameters , At the same time, it also introduces many complex operations .
This complexity also hinders the deployment of the model on the application side , Because these devices, such as mobile phones 、IOT Devices and so on have strict power consumption and computing power limitations .
This also leads to our demand for designing more efficient neural network algorithms and corresponding hardware platforms .
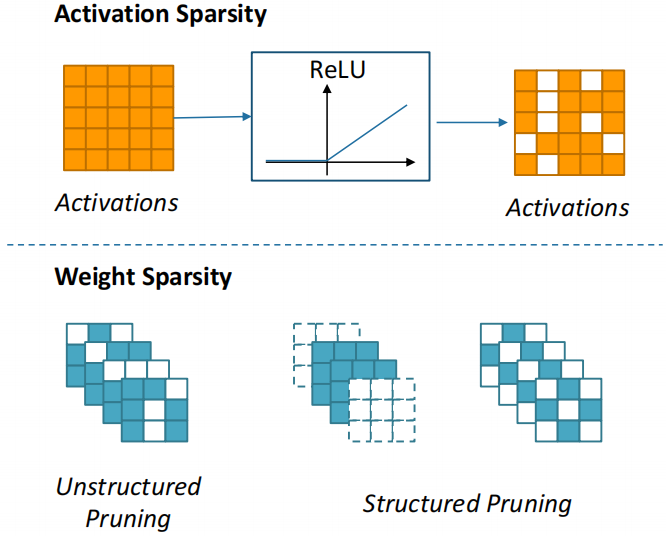
Sparse CNN
Nowadays, there are many redundancies in convolutional Networks , That is to say, it is unnecessary to have some weights or inputs . If we can remove these redundancies in the training stage , You can infer the computing power and resources needed . When people are looking for sparse neural networks , Sparse is often divided into two categories :
One is the sparsity of activation values , That is, the input is sparse . This kind of sparsity is often caused by the activation function , We will find that after a similar ReLU Many inputs will become 0. So these 0 It can be skipped in our calculation .
The other is the sparsity of weights . The sparsity of weights is often obtained by pruning algorithm . Pruning algorithm we have two kinds of classification :
● Unstructured pruning Unstructured Pruning
We compare the importance of each weight with the threshold , If the weight is small, you can skip in the calculation .
● Structured pruning Structured Pruning
When we prune, we restrict the removal of the whole structure , Or pruning according to a predefined fixed pattern . Such structured pruning can help us get a predictable sparse structure when reasoning in hardware , Better skip unnecessary operations .
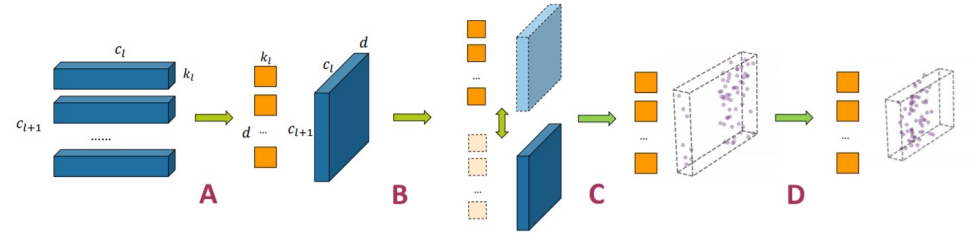
Motivation
The starting point of our research is , We can see in the neural network compression algorithm , Structured pruning is hardware friendly , We can use these compressed structures very efficiently , Unstructured pruning can bring us a relatively high compression ratio . meanwhile , Another low rank approximation method can better get an easy to control acceleration effect . So we want to , Can we propose a method , Combine the advantages of these previous compression methods ?
We observed that , The convolution kernel of these convolution neural networks usually has a relatively sparse expression . If we treat convolution kernel as a vector , These vectors can be projected into a lower dimensional subspace . Based on this , Our first work is algorithm level optimization . We project the convolution kernel into a low dimensional subspace , And find a set of bases in this subspace . We use the linear combination of these bases to approximate the original convolution kernel . This is our first algorithmic framework ——PENNI Framework.
PENNI Framework
● A. Kernel Decomposition – Low-Rank Approximation
We decompose the convolution kernel .
● B. Alternative Retraining – Sparsity Regularization
We train the decomposed network structure , To restore the original accuracy , And in the training process, some regularization methods are applied to get the sparse network .
● C. Pruning – Unstructured Pruning
We pruned the whole network after training . We use a pruning method based on absolute value .
● D. Model Shrinking – Structural Pruning
We identify a redundant structure according to the pruned network , Such as input channel or output channel and directly remove .
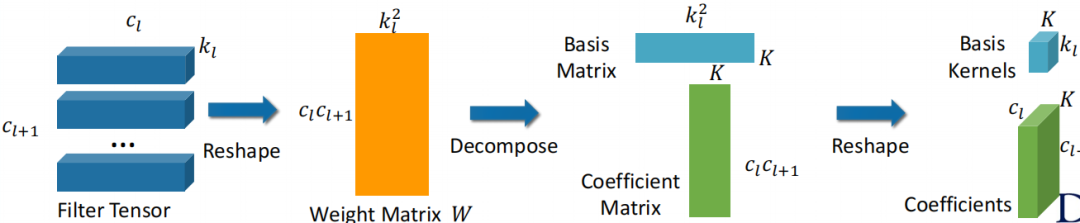
Kernel Decomposition
First , Let's see how to decompose convolution kernel . The usual neural network weights will express a form of tensor .
Our first step is to transform the tensor into a matrix . We combine the input and output channels , Then the width and height of the convolution kernel are combined to get a weight matrix .
We can see that each row of this matrix actually represents the original convolution kernel , We now use a vector instead of the previous two-dimensional form to represent the original convolution kernel . After this step , We can use the method of matrix decomposition , Such as singular value decomposition .
Then we choose the eigenvector after matrix decomposition according to the eigenvalue ranking , That is our new base vector . This process also projects our original matrix into a relatively low dimensional space .
After getting the matrix of the base , We can also get a projection matrix , At the same time, the original convolution kernel can be projected into a new space and a set of coefficient matrices can be obtained . Each row of the matrix represents how to obtain an original convolution kernel approximation with a new set of linear combinations of bases .
In this way, we have completed the process of matrix decomposition , The purpose of compression through decomposition is achieved .
Retraining and Pruning
● Next, we will train the decomposed network , In the training, a regularization method will be used to obtain a sparse sparse matrix .
● The second step is pruning . Prune according to the absolute value of the coefficient after training , And carry on fine-tuning To restore the recognition accuracy of the whole network after pruning .
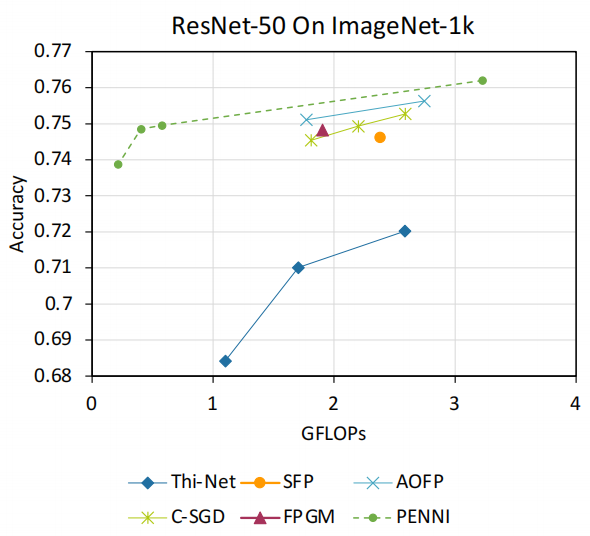
Experiments
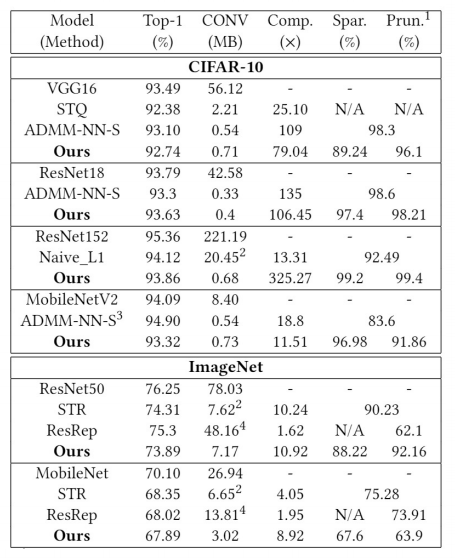
We compared our framework with some previous structured pruning methods , It is found that the compression ratio can be greatly improved , And maintain the recognition accuracy similar to that of the previous method .
● CIFAR-10:
■ VGG16: 93.26% FLOPs reduction with 0.4% accuracy loss
■ ResNet-56:79.4% FLOPs reduction with 0.2% accuracy loss
● ImageNet:
■ AlexNet:70.4% FLOPs reduction with 1% accuracy loss
■ ResNet-50:90.1% FLOPs reduction with ~1% accuracy loss
Computation Reorganization
Having finished the algorithm framework , Our ultimate goal is to hope that such a compression decomposition algorithm can provide some guidance for the design of our accelerator , Especially in the previously compressed part, a sparse coefficient will be obtained . How to make efficient use of this sparse coefficient , Skipping all redundant calculations is the purpose of our later research . The relevant formula is as follows :
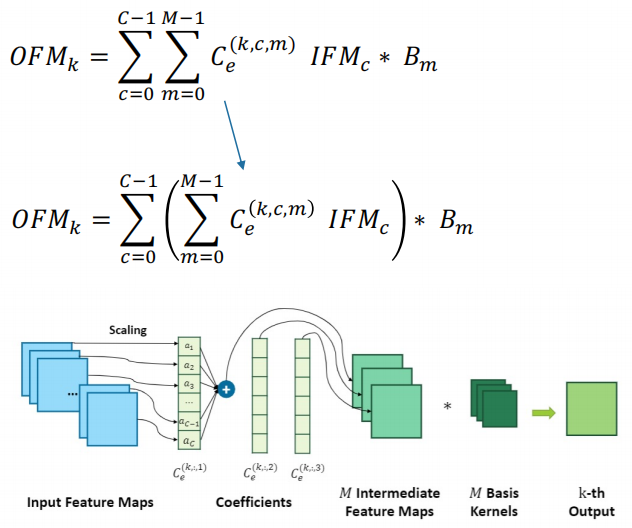
We found that , Convolution is actually a linear operation . We can change the order of operations , First, calculate the linear combination of the input characteristic graph , Then, the convolution kernel of each base is calculated . Although the operation of changing the order looks very simple , But it can really bring us many benefits .
● It can reduce the intermediate results that need to be cached .
● It can better reuse the input characteristic graph
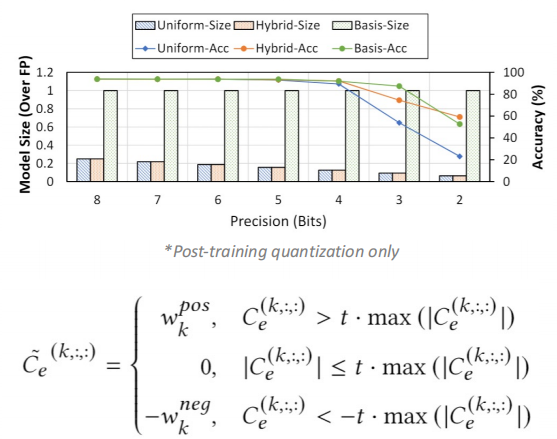
Hybrid Quantization
We found that after decomposition , Because our original weight is divided into two parts —— Convolution kernel and coefficient of basis . The frequency of these two parts is also different , The basic convolution kernel needs to be used by all input and output channels , Each coefficient is only used by a pair of input and output channels . According to this feature , We can use different precision for the weights of these two parts —— Use high precision for the weight of the base , Use low precision for coefficients .
The advantage of this is that it can give us the storage space needed for our parameters , Low accuracy is also conducive to our subsequent sparse processing of hardware .
Our final framework uses this basic convolution kernel 8-bit Quantify , Three values are used for the coefficients (2-bit) Quantify .
Architecture overview
On the basis of the previous , We propose the hardware design of the accelerator . We also use a hierarchical design , Combine all the arithmetic units into blocks . Each block is divided into rows , Each line is also divided into two parts , One part deals with the linear combination of input characteristic graphs , The other part deals with convolution operations .
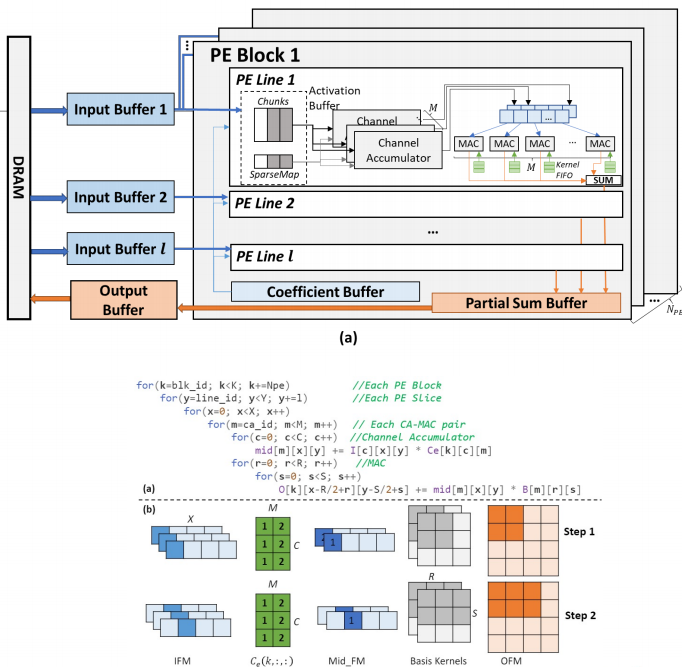
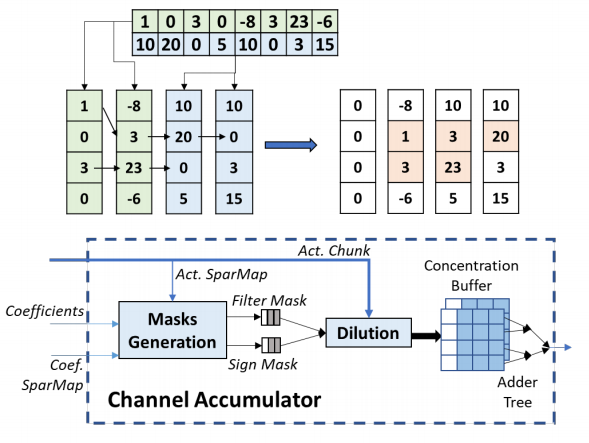
Dilution-Concentration
To deal with sparse parameters , We propose a new mechanism ——Dilution-Concentration. This is also a process of dilution and concentration , We divide the processing of sparse features into two steps :
● Dilution : We match the input and the weight of Central Africa 0 Value , And remove other values .
● concentrate : Because our weight is only positive and negative , All the results after dilution can be reordered and non 0 The value of is placed at the head of the vector .
Coding for sparse vectors , We used a SparseMap Code form of .
We also code each line separately , To ensure that each line of the operation unit can be decoded synchronously , So as to improve the parallelism of the whole operation .
The whole sparse processing is divided into two steps , In the first step of the dilution process, we used Bit gather operation , The purpose of this operation is to put 1 Collect at the head of the vector . This operation can be done efficiently by using butterfly network , The cost of hardware devices is also very low .
This process needs to generate two mask:
● Activation mask The element corresponding to non-zero eigenvalue in the current input element
● Sign mask In the current coefficient, the choice corresponds to non 0 Sparse input , And use 0 and 1 To represent its symbol

The second step is the process of concentration . We used look-ahead and look-aside These two mature techniques look for non 0 Fill in the value of 0 Value position , You can get a dense vector . Because these two steps are asynchronous , We use pipeline design to improve the overall efficiency .
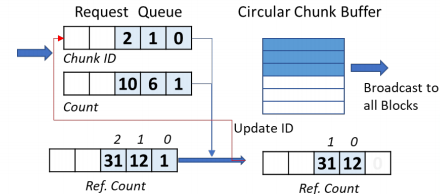
Input Buffer Design
We design the input cache , A ring cache structure is used to reduce the complexity of the whole cache . Because the rows of arithmetic units share the same input , So we use the method of saving counters in the cache and comparing , Judge whether the current data has been read by all operation units . If it has been read , This space can be used to read new data .
Algorithm Evaluation
Later in the experiment , We mainly compare the compression results of our algorithm with unstructured pruning . We can achieve the same or even higher compression ratio , Of course, there will be some loss of accuracy , But relatively small .
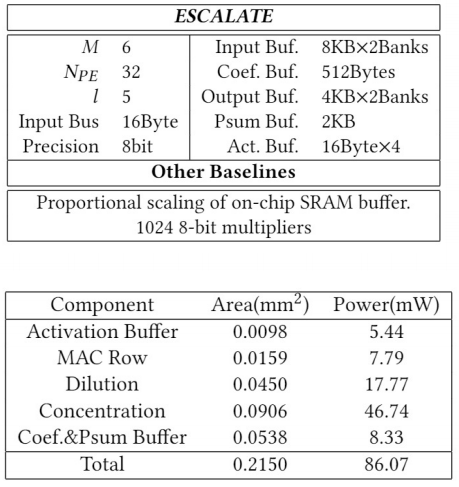
Accelerator evaluation settings
For accelerator design , We compared the performance model with previous accelerator work .
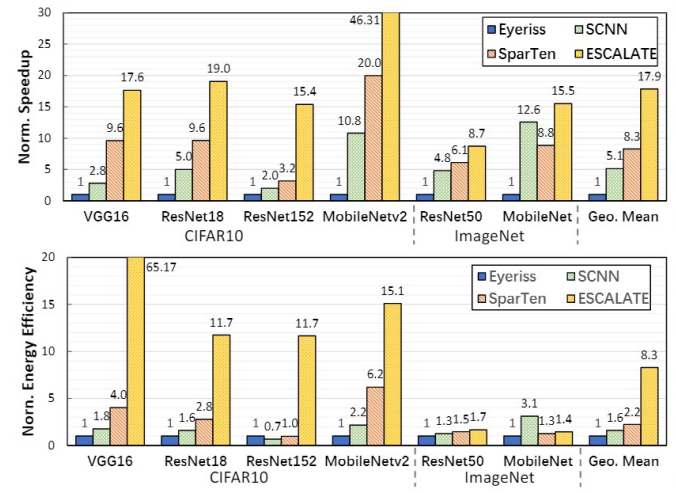
Speedup and Energy Efficiency
We compared acceleration with energy efficiency .
● stay CIFAR10 On , High sparsity enables the accelerator to generate intermediate feature maps in time .
● stay ImageNet On ,CA More cycles are needed to input the linear combination of characteristic graphs to produce an intermediate element , This leads to MAC At rest , Limits acceleration .
● Overall , We compare it with the previous sparse accelerator and unstructured pruning framework , The average can reach one 2—3 Times faster . meanwhile , Our framework can also determine whether to get a higher recognition accuracy or a higher acceleration ratio by adjusting the parameters in the compression process .
carry
Wake up
Thesis title :
PENNI: Pruned Kernel Sharing for Efficient CNN Inference
ESCALATE: Boosting the Efficiency of Sparse CNN Accelerator with Kernel Decomposition
Thesis link :
http://proceedings.mlr.press/v119/li20d.html
https://dl.acm.org/doi/abs/10.1145/3466752.3480043
Click on “ Read the original ”, You can watch this playback
Arrangement : Lin be
author : Li Shiyu
Activity Notice

Remember to pay attention to us ! There is new knowledge every day !
About AI TIME
AI TIME From 2019 year , It aims to carry forward the spirit of scientific speculation , Invite people from all walks of life to the theory of artificial intelligence 、 Explore the essence of algorithm and scenario application , Strengthen the collision of ideas , Link the world AI scholars 、 Industry experts and enthusiasts , I hope in the form of debate , Explore the contradiction between artificial intelligence and human future , Explore the future of artificial intelligence .
so far ,AI TIME Has invited 700 Many speakers at home and abroad , Held more than 300 An event , super 260 10000 people watch .

I know you.
Looking at
Oh
~

Click on Read the original View playback !
边栏推荐
- [Arduino syntax - structure]
- ctf. Show PHP feature (89~110)
- ClickOnce does not support request execution level 'requireAdministrator'
- [Yu Yue education] Liaoning Vocational College of Architecture Web server application development reference
- Code review concerns
- [understanding of opportunity-39]: Guiguzi - Chapter 5 flying clamp - warning 2: there are six types of praise. Be careful to enjoy praise as fish enjoy bait.
- 基於DVWA的文件上傳漏洞測試
- Paddle框架:PaddleNLP概述【飞桨自然语言处理开发库】
- Hcip---ipv6 experiment
- Alibaba-Canal使用详解(排坑版)_MySQL与ES数据同步
猜你喜欢
servlet(1)
MATLB|实时机会约束决策及其在电力系统中的应用

282. Stone consolidation (interval DP)

500 lines of code to understand the principle of mecached cache client driver
Hcip---ipv6 experiment
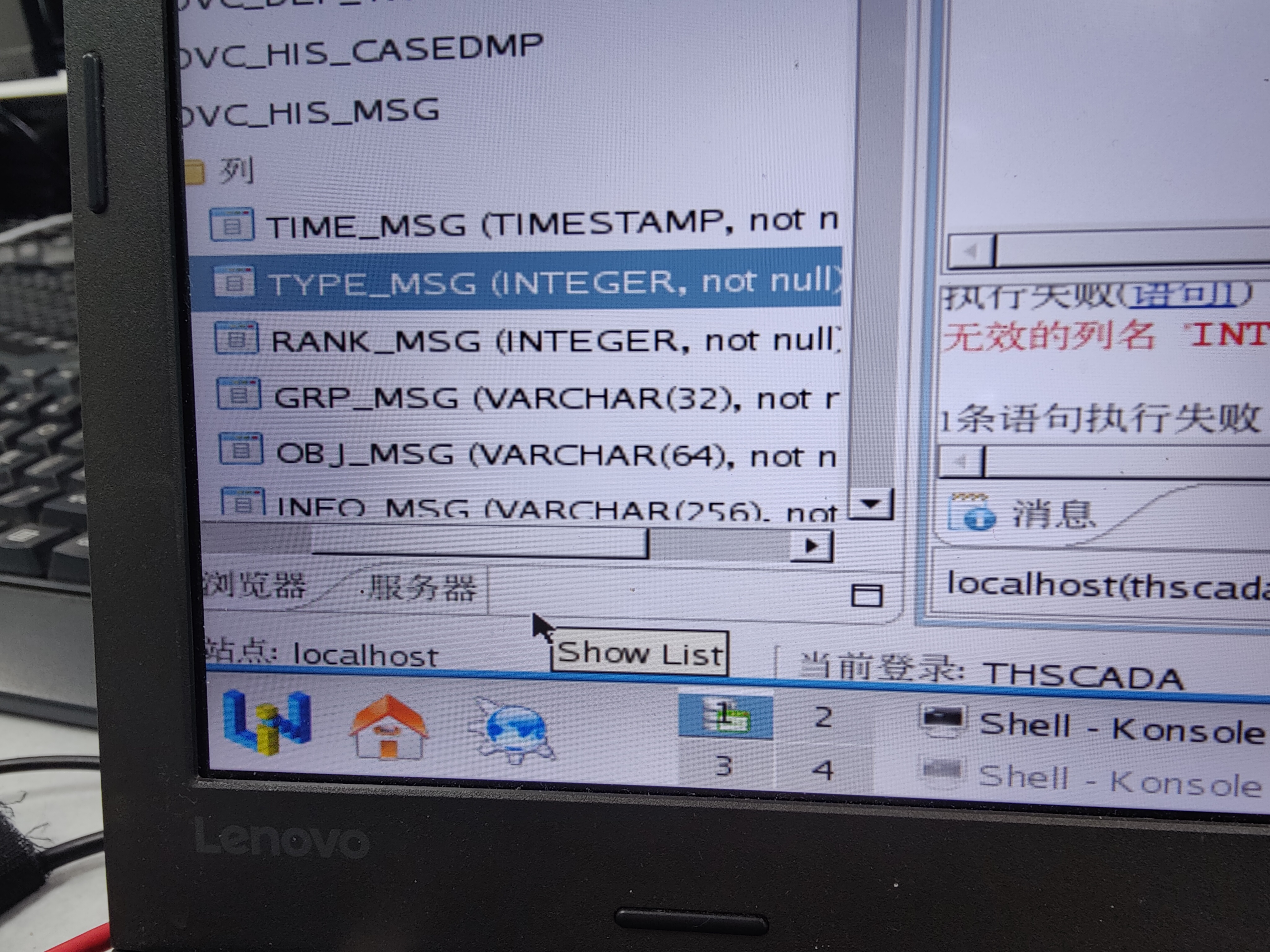
有谁知道 达梦数据库表的列的数据类型 精度怎么修改呀
Pbootcms plug-in automatically collects fake original free plug-ins
Folio.ink 免费、快速、易用的图片分享工具

leetcode刷题_反转字符串中的元音字母

Leetcode study - day 35

随机推荐
[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry
基於DVWA的文件上傳漏洞測試
Ordinary people end up in Global trade, and a new round of structural opportunities emerge
【已解决】如何生成漂亮的静态文档说明页
A glimpse of spir-v
Xunrui CMS plug-in automatically collects fake original free plug-ins
File upload vulnerability test based on DVWA
【Flask】响应、session与Message Flashing
[pat (basic level) practice] - [simple mathematics] 1062 simplest fraction
Force buckle 9 palindromes
A Cooperative Approach to Particle Swarm Optimization
JMeter BeanShell的基本用法 一下语法只能在beanshell中使用
[le plus complet du réseau] | interprétation complète de MySQL explicite
c#网页打开winform exe
Docker compose配置MySQL并实现远程连接
Maya hollowed out modeling
一圖看懂!為什麼學校教了你Coding但還是不會的原因...
Docker compose configures MySQL and realizes remote connection
Leetcode skimming questions_ Sum of squares
LeetCode 322. Change exchange (dynamic planning)