当前位置:网站首页>Processing strategy of message queue message loss and repeated message sending
Processing strategy of message queue message loss and repeated message sending
2022-07-07 12:15:00 【Hollis Chuang】
source :https://www.jianshu.com/p/533fc6fc0963
Distributed transactions
What is distributed transaction
Our server has developed from a single machine to a distributed system with multiple machines , Each system needs to communicate with the help of network before , There is no way to use the relatively reliable method call and interprocess communication in the original single machine , At the same time, the network environment is also unstable , This has caused the problem of data synchronization between our multiple machines , This is a typical distributed transaction problem .
In a distributed transaction, the participants in the transaction 、 Servers that support transactions 、 Resource servers and transaction managers are located on different nodes of different distributed systems . Distributed transaction is to ensure the data consistency between different nodes .
Common distributed transaction solutions
1、2PC( Two stage submission ) programme - Strong consistency
2、3PC( Three stage commit ) programme
3、TCC (Try-Confirm-Cancel) Business - Final consistency
4、Saga Business - Final consistency
5、 Local message table - Final consistency
6、MQ Business - Final consistency
Here we focus on using message queues to achieve distributed consistency , For details of the above distributed design schemes, please refer to the reference link at the end of the article
be based on MQ Distributed transactions implemented
Local message table - Final consistency
Producer of message , In addition to maintaining your own business logic , At the same time, you need to maintain a message table . What is recorded in this message table is the information that needs to be synchronized to other services , Of course, this message table , Each message has a status value , To identify whether the message has been successfully processed .
The business logic of sending and placing and the insertion of data in the message table will be completed in one transaction , This avoids Successful business processing + Transaction message sending failed , or Business processing failed + Transaction message sent successfully , This problem .
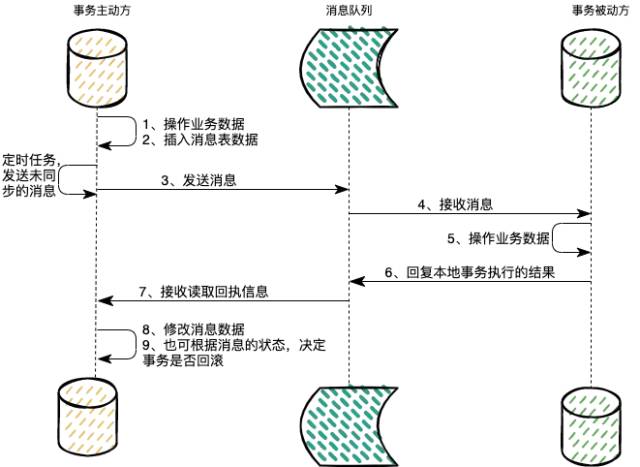
Take a chestnut :
We assume that there are currently two services , Order service , Shopping cart service , Users combine and place orders for several goods in the shopping cart , After that, you need to empty the product information that has just been placed in the shopping cart .
1、 The producer of the message is the order service , Completed their own logic ( Order goods ) And then pass the message through mq Send to other services that need data synchronization , That is, our shopping cart service in chestnuts .
2、 Other services ( Shopping cart service ) Will listen to this queue ;
1、 If you receive this message , And the data synchronization is successful , Of course, this is also a local transaction , Just through mq The manufacturer who replied to the message ( Order service ) The message has been processed , Then the producer can identify that the transaction has ended . If it's a business mistake , The manufacturer who replied to the message , Data rollback is needed .
2、 I haven't heard from you for a long time , This is not going to happen , The sender of the message will have a scheduled task , It will periodically retry sending messages that have not been processed in the message table ;
3、 Producer of message ( Order service ) If you receive a message receipt ;
1、 If successful, modify the message. The message has been processed , That is, the synchronization of this distributed transaction has been completed ;
2、 If the result of the message is execution failure , At the same time, roll back this transaction locally , Identify that the message has been processed ;
3、 If the message is lost , That is, the receipt message is not received , This is unlikely to happen , Sender of message ( Order service ) There will be a regular task , Periodically retry sending messages that have not been processed in the message table , Downstream services need to be idempotent , You may receive multiple repeated messages , If a reply message is lost, a receipt message from the manufacturer is lost , Continue to receive from the manufacturer later mq news , Then reply to the manufacturer's receipt information of the message again , This can always ensure that the sender can successfully receive the receipt , The message producer should also be idempotent when receiving the receipt message .
Here are two very important operations :
1、 The server processing message needs to be idempotent , Both the producer and receiver of the message need to be idempotent ;
2、 To send a message, you need to add a timer to iterate over the unprocessed message , Avoid message loss , The transaction execution is broken .
The advantages and disadvantages of this scheme
advantage :
1、 The reliability of message data is realized at the design level , Do not rely on message oriented middleware , Weakened right mq Feature dependency .
2、 Simple , Easy to implement .
shortcoming :
It mainly needs to be bound with business data , High coupling , Use the same database , It will occupy some resources of the business database .
MQ Business - Final consistency
The following analyzes the transaction support of several message queues
RocketMQ How to handle transactions in
RocketMQ The transaction , It solves the problem of , Make sure to do both local transaction and message , Either they all succeed , Or they all failed . also ,RocketMQ Added a transaction anti query mechanism , To maximize the success rate of transaction execution and data consistency .
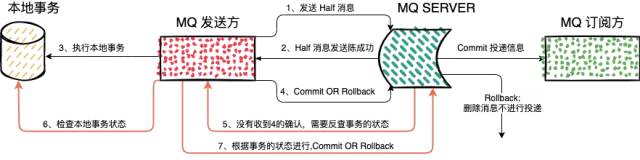
There are mainly two aspects , Normal transaction commit and transaction message compensation
Normal transaction commit
1、 Send a message (half news ), This half The difference between news and ordinary news , In transaction commit Before , For consumers , The news is invisible .
2、MQ SERVER Write information , And return the result of the response ;
3、 according to MQ SERVER The result of the response , Decide whether to execute local transactions , If MQ SERVER Write information and execute local transaction successfully , Otherwise, do not execute ;
4、 According to the status of local transaction execution , Decide whether to... The transaction Commit perhaps Rollback.MQ SERVER received Commit, Then the message will be delivered to the downstream subscription service , Downstream subscription services can synchronize data , If it is Rollback Then the message will be lost ;
If MQ SERVER Have not received Commit perhaps Rollback The news of , In this case, the compensation process is required
Compensation process
1、MQ SERVER If no message is received from the sender Commit perhaps Rollback news , It will launch a query to the message sender, that is, our server , Query the status of the current message ;
2、 The message sender receives the corresponding query request , Query the status of the transaction , Then push the status back to MQ SERVER,MQ SERVER The follow-up process can be .
Dealing with distributed transactions compared to local message tables ,MQ Transaction is to put the logic that should be processed in the local message table into MQ Middle to finish .
Kafka How to handle transactions in
Kafka Transaction resolution in , Ensure that multiple messages sent in one transaction , Either they all succeed , Or they all failed . That is to ensure the atomicity of write operations to multiple partitions .
Through cooperation Kafka The idempotent mechanism of Kafka Of Exactly Once, To satisfy the Read - Handle - write in Applications in this mode . Of course Kafka The transaction in is mainly to deal with this mode .
What is? Read - Handle - write in How about the model ?
Li Ru : In flow calculation , use Kafka As a data source , And save the calculation results to Kafka In this case , Data from Kafka Consume in a theme of , Computing in a computing cluster , Then save the results in Kafka In other topics of . In the process , Ensure that each message is processed only once , Only in this way can we ensure the success of the final result .Kafka The atomicity of the transaction guarantees , Atomicity of reading and writing , If the two don't succeed together , Or we'll fail and roll back together .
Here's an analysis of Kafka How is the transaction of
Its implementation principle and RocketMQ It's about the same thing , Both are based on two-phase commit , It may be more troublesome in implementation
First, let's introduce the business coordinator , To solve the problem of distributed transaction ,Kafka Introduced the role of transaction coordinator , Responsible for coordinating the whole affairs on the server side . This coordinator is not an independent process , It is Broker Part of the process , The coordinator, like the division, ensures its own availability through elections .
Kafka There is also a special topic for logging transactions in the cluster , What is recorded in it is the transaction log . There will be multiple coordinators at the same time , Each coordinator is responsible for managing and using several partitions in the transaction log . In this way, transactions can be executed in parallel , Improve performance .
Let's look at the specific process
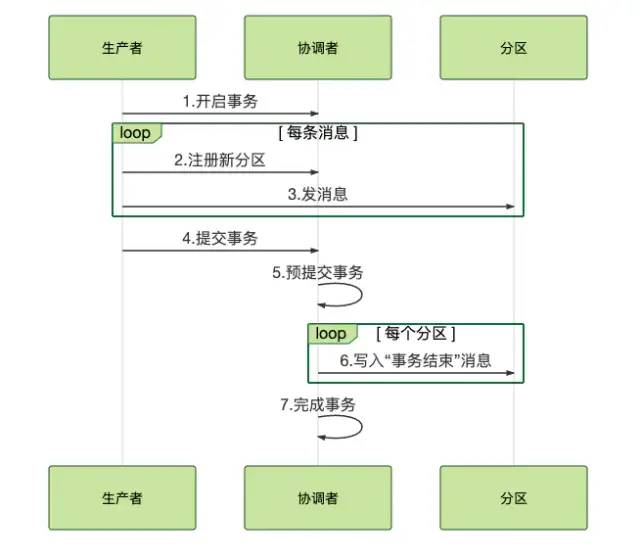
1、 First, when starting a transaction , The producer sends a request to the coordinator to start the transaction , The coordinator records the transaction in the transaction log ID;
2、 Then the producer starts sending transaction messages to the coordinator , However, you need to send a message to inform the coordinator of which topic and partition , After that, the transaction message will be sent normally , These transaction messages are not like RocketMQ Will be saved in a special queue ,Kafka Uncommitted transaction messages are the same as ordinary messages , Just rely on the client for filtering when consuming .
3、 Send message complete , The producer commits or rolls back the transaction to the coordinator according to its execution state ;
Commit of transaction
1、 The coordinator sets the status of the transaction to PrepareCommit, Write to the transaction log ;
2、 The coordinator writes the identification of the end of the transaction in each partition , Then the client can release the previously filtered uncommitted transaction message to the consumer for consumption ;
Rollback of transaction
1、 The coordinator sets the status of the transaction to PrepareAbort, Write to the transaction log ;
2、 The coordinator writes the identification of the transaction rollback in each partition , Then the previously uncommitted transaction message can be discarded ;
Here's a quote 【 Pictures in the message queue master class 】
RabbitMQ The transaction
RabbitMQ The problem solved in transaction is to ensure that the producer's message arrives MQ SERVER, This and others MQ Things are a little different , There is no discussion here .
Message loss prevention
Let's analyze the next message in MQ The stage experienced by the middle flow .

Production stage : Producers produce messages , Send it over the Internet to Broker End .
Storage phase :Broker Get the news , It needs to be dropped , If it is a cluster version MQ You also need to synchronize data to other nodes .
Consumption stage : Consumers are Broker End pull data , Reach the consumer through network transmission .
Prevent message loss during production
Network packet loss 、 Network failure and so on will lead to the loss of messages
RabbitMQ Loss prevention measures in
1、 For perceptible errors , We catch errors , Then re deliver ;
2、 adopt RabbitMQ Transaction resolution in ,RabbitMQ The transaction in solves the problem of message loss in the production stage ;
Before the producer sends the message , adopt channel.txSelect Start a transaction , Then send a message , If the message is delivered server Failure , Perform transaction rollback channel.txRollback, Then resend , If server Received a message , Just commit the business channel.txCommit
However, the performance of using transactions is not good , This is a synchronous operation , After a message is sent, it will block the sender , Waiting for RabbitMQ Server The response of the , Then we can send the next message , The throughput and performance of producer production messages will be greatly reduced .
3、 Use the send confirmation mechanism .
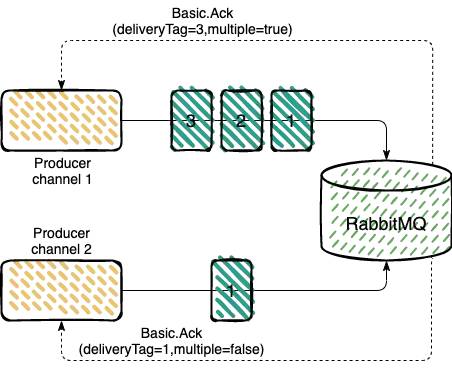
Use the confirmation mechanism , The producer sets the channel to confirm Validation mode , Once the channel enters confirm Pattern , All messages posted on the channel are assigned a unique one ID( from 1 Start ), Once the message is delivered to all matching queues ,RabbitMQ Will send a confirmation (Basic.Ack) To producers ( Unique with message deliveryTag and multiple Parameters ), This makes the producer know that the message has arrived at the destination correctly .
multiple by true It means batch message confirmation , by true When , Indicates that less than or equal to... Is returned deliveryTag The news of id It's all confirmed , by false It means news id Returned for deliveryTag The news of , It has been confirmed that .
There are three types of confirmation mechanisms
1、 Synchronous confirmation
2、 Batch confirmation
3、 Asynchronous acknowledgment
The efficiency of synchronous mode is very low , Because every message needs to wait for confirmation , To deal with the next ;
The batch confirmation mode is more efficient than the synchronous mode , But there is a fatal flaw , Once the reply fails to confirm , All messages confirming the current batch will be resend , Cause the message to be sent repeatedly ;
Asynchronous mode is a good choice , There will be no blocking problem in synchronous mode , It's also very efficient , It's a good choice .
Kafka Loss prevention measures in
Kafaka Introduced a broker.broker Will confirm the news to producers and consumers , The producer sends a message to broker, If not received broker You can choose to continue sending .
as long as Producer received Broker Confirmation response for , This ensures that messages are not lost during the production phase . Some message queues don't receive a send confirmation response for a long time , Will automatically retry , If you try again and fail again , The user will be informed by return value or exception .
As long as it is handled correctly Broker Confirmation response for , You can avoid the loss of messages .
RocketMQ Loss prevention measures in
Use SYNC How to send messages , wait for broker Processing results
RocketMQ Provides 3 A way to send messages , Namely :
The synchronous :Producer towards broker Send a message , Block the current thread waiting broker Respond to Send results .
Send asynchronously :Producer First of all, build a broker The task of sending messages , Submit the task to the thread pool , When the task is finished , Callback user defined callback function , Execution processing result .
Oneway send out :Oneway Mode is only responsible for sending requests , Do not wait for response ,Producer Only responsible for sending out requests , Instead of processing the response results .
With a transaction ,RocketMQ The transaction , It solves the problem of , Make sure to do both local transaction and message , Either they all succeed , Or they all failed .
Storage phase
In the storage phase, normally , as long as Broker In normal operation , There is no problem of missing messages , But if Broker There's a problem , For example, the process is dead or the server is down , It's still possible to lose information .
RabbitMQ Loss prevention measures in
Prevent message loss during storage , Can be persistent , Prevent abnormal conditions ( restart , close , Downtime )...
RabbitMQ There are three parts to persistence :
Persistence of switches
Persistence of switches , By declaring the queue when durable The parameter is set to true Realized , If you don't set persistence , The information of the switch will be lost .
Queue persistence
Queue persistence , By declaring the queue when durable The parameter is set to true Realized , The persistence of a queue ensures that its metadata will not be lost due to an exception , However, there is no guarantee that the messages stored internally will not be lost .
Message persistence
Message persistence , Specify... At the time of delivery delivery_mode=2(1 It's not persistence ), Message persistence , It needs to cooperate with the persistence of the queue , Only set the persistence of messages , After restart, the queue disappears , Then the message will be lost . So it doesn't make much sense to set message persistence instead of queue persistence .
For persistence , If all messages are set to persist , It will affect the performance of writing , Therefore, you can choose to persist messages that require high reliability .
However, message persistence does not prevent 100% message loss
For example, the data goes down in the process of dropping the disk , The message has not been synchronized to memory in time , This will also lose data , This problem can be solved by introducing the image queue .
The role of the mirror queue : Bring in the image queue , The queue can have been mirrored to other nodes in the cluster Broker On the nodes , If a node in the cluster fails , The queue can automatically switch to another node in the image to ensure service availability .( More details will not be discussed here )
Kafka Loss prevention measures in
The operating system itself has a layer of cache , be called Page Cache, When writing to disk files , The system will write the data stream to the cache first .
Kafka After receiving the message, it will also be stored in the cache (Page Cache) in , After that, the operating system swipes the disk according to its own strategy or through fsync Order to force the disk to be flushed . If the system crashes , stay PageCache The data in will be lost . Which is the corresponding Broker The data in the will be lost .
Handling ideas
1、 Control the campaign partition leader Of Broker. If one Broker Behind the original Leader Too much , So once it becomes new Leader, It will inevitably result in the loss of information .
2、 Control messages can be written to multiple copies before they can be submitted , This avoids the above problems 1.
RocketMQ Loss prevention measures in
1、 Change the disc brushing mode to synchronous disc brushing ;
2、 For multiple nodes Broker, Need to put Broker The cluster is configured to : At least send the message to 2 More than nodes , Then send a confirmation response to the client . So when someone Broker outage , Other Broker Can replace the downtime of Broker, There will be no loss of information .
Consumption stage
The consumption stage is very simple , If lost in network transmission , This message will continue to be pushed to consumers , In the consumption stage, we only need to control the consumption confirmation after the business logic processing is completed .
summary : For the loss of messages , You can also use the idea of local message table , When the message is generated, the message is dropped , Long unprocessed messages , Use timed pushback to queue .
Message repeat
Message in MQ Transfer in , It can be roughly classified into the following three :
1、At most once: One more time . When a message is delivered , It will be delivered at most once . It's not safe , There may be data loss .
2、At least once: At least once . When a message is delivered , It will be delivered at least once . in other words , It's not allowed to lose news , But a small number of duplicate messages are allowed .
3、Exactly once: Exactly Once . When a message is delivered , It will only be delivered once , No loss or repetition is allowed , This is the highest level .
Most message queues satisfy At least once, That is, repeated messages can be allowed to appear .
We consumers need to satisfy idempotency , There are usually the following solutions
1、 Take advantage of the uniqueness of the database
According to the business situation , Select the unique value that can be determined in the business as the unique key of the database , Create a new flow table , Then the execution of business operations and the insertion of flow table data are placed in the same transaction , If the flow table data already exists , Then the execution fails , To ensure idempotency . You can also query the data of the flow table first , No data and then execute the business , Insert flow table data . But be careful , Database read / write delay .
2、 Adding preconditions for updating the database
3、 Bring the only message ID
Each message plus a unique ID, Utilization method 1 By adding a flow table , Use the uniqueness of the database to handle the consumption of duplicate messages .
End
Previous recommendation

How to build a technical team that will bring down the company ?
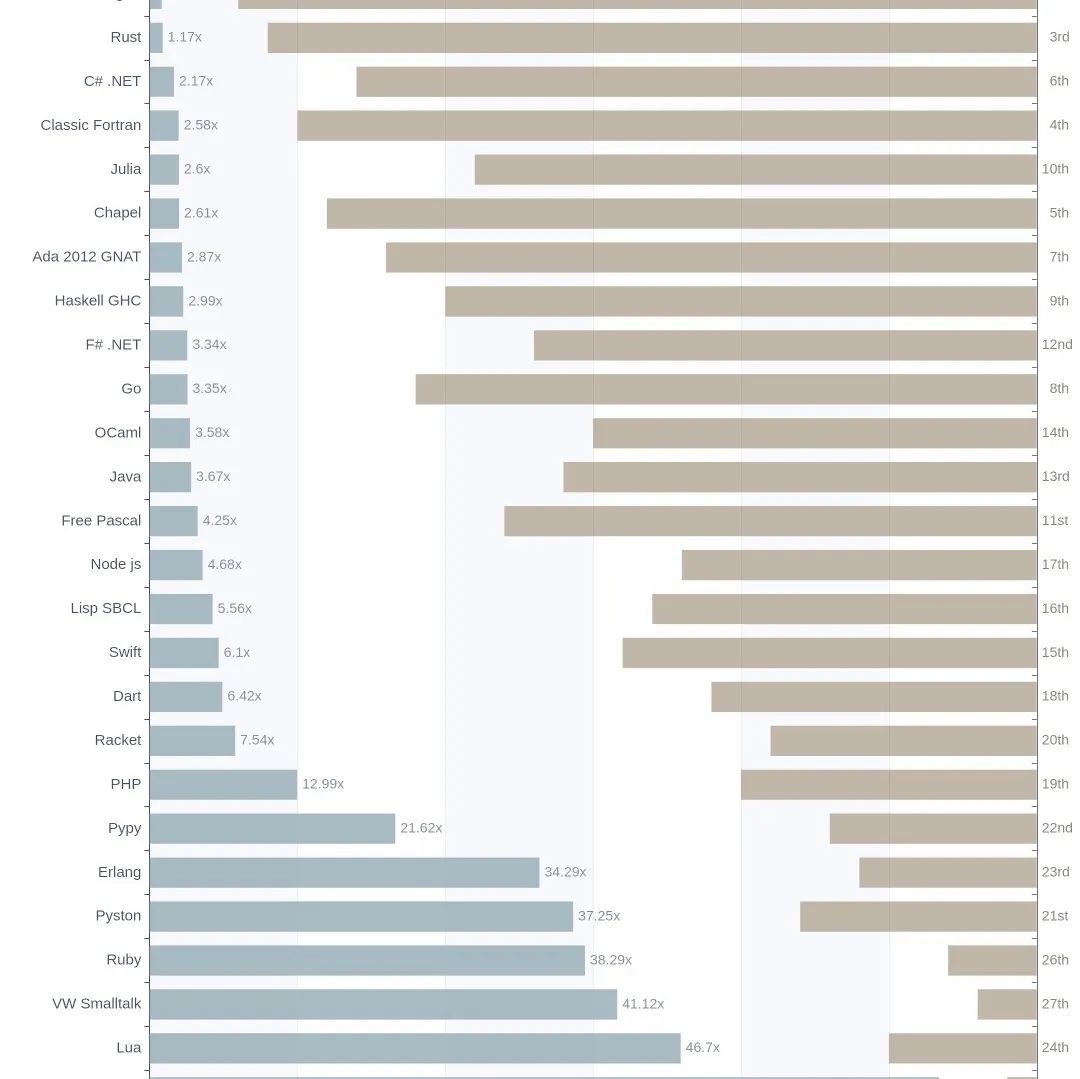
Performance of major mainstream programming languages PK, The results were unexpected

For amount calculation BigDecimal It's safe ? Look at these five pits ~~
There is Tao without skill , It can be done with skill ; No way with skill , Stop at surgery
Welcome to pay attention Java Road official account

Good article , I was watching ️
边栏推荐
- Camera calibration (1): basic principles of monocular camera calibration and Zhang Zhengyou calibration
- Have you ever met flick Oracle CDC, read a table without update operation, and read it repeatedly every ten seconds
- 110. Network security penetration test - [privilege promotion 8] - [windows sqlserver xp_cmdshell stored procedure authorization]
- idea 2021中文乱码
- [extraction des caractéristiques de texture] extraction des caractéristiques de texture de l'image LBP basée sur le mode binaire local de Matlab [y compris le code source de Matlab 1931]
- 108. Network security penetration test - [privilege escalation 6] - [windows kernel overflow privilege escalation]
- 即刻报名|飞桨黑客马拉松第三期盛夏登场,等你挑战
- Introduction and application of smoothstep in unity: optimization of dissolution effect
- Unity map auto match material tool map auto add to shader tool shader match map tool map made by substance painter auto match shader tool
- 112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]
猜你喜欢
idea 2021中文乱码

VSCode的学习使用

wallys/Qualcomm IPQ8072A networking SBC supports dual 10GbE, WiFi 6
![112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]](/img/b6/6dfe9be842204567096d1f4292e8e7.png)
112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]
数据库系统原理与应用教程(011)—— 关系数据库
SwiftUI 4 新功能之掌握 WeatherKit 和 Swift Charts
112.网络安全渗透测试—[权限提升篇10]—[Windows 2003 LPK.DDL劫持提权&msf本地提权]

《通信软件开发与应用》课程结业报告
Unity map auto match material tool map auto add to shader tool shader match map tool map made by substance painter auto match shader tool
Summed up 200 Classic machine learning interview questions (with reference answers)
随机推荐
Zero shot, one shot and few shot
TypeScript 接口继承
The road to success in R & D efficiency of 1000 person Internet companies
What are the top-level domain names? How is it classified?
Up meta - Web3.0 world innovative meta universe financial agreement
[extraction des caractéristiques de texture] extraction des caractéristiques de texture de l'image LBP basée sur le mode binaire local de Matlab [y compris le code source de Matlab 1931]
什么是局域网域名?如何解析?
2022 8th "certification Cup" China University risk management and control ability challenge
从工具升级为解决方案,有赞的新站位指向新价值
Visual Studio 2019 (LocalDB)\MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782版及更低版本
[texture feature extraction] LBP image texture feature extraction based on MATLAB local binary mode [including Matlab source code 1931]
让数字管理好库存
平安证券手机行开户安全吗?
数据库系统原理与应用教程(011)—— 关系数据库
HCIA复习整理
[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]
[full stack plan - programming language C] basic introductory knowledge
Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
数据库系统原理与应用教程(008)—— 数据库相关概念练习题
Improve application security through nonce field of play integrity API